Azure API Management での生成 AI ゲートウェイ機能の概要
適用対象: すべての API Management レベル
この記事では、Azure OpenAI Service によって提供される機能など、生成 AI API の管理に役立つ Azure API Management の機能を紹介します。 Azure API Management には、インテリジェント アプリを提供する API のセキュリティ、パフォーマンス、信頼性を強化するためのさまざまなポリシー、メトリック、その他の機能が用意されています。 これらの機能は総称して、生成 AI API の "生成 AI (GenAI) ゲートウェイ機能" と呼ばれます。
Note
- この記事では、Azure OpenAI Service によって公開される API を管理する機能に焦点を当てます。 GenAI ゲートウェイ機能の多くは、Azure AI モデル推論 API を通じて利用できる API を含め、他の大規模言語モデル (LLM) API に適用されます。
- 生成 AI ゲートウェイ機能は、API Management の既存の API ゲートウェイの機能であり、別の API ゲートウェイではありません。 API Management の詳細については、Azure API Management の概要に関するページを参照してください。
生成 AI API を管理する際の課題
生成 AI サービスで使用する主なリソースの 1 つは、"トークン" です。 Azure OpenAI Service では、1 分あたりのトークン数 (TPM) で表されるクォータをモデル デプロイに割り当てて、モデル コンシューマー (さまざまなアプリケーション、開発者チーム、社内の部門など) 全体に分配します。
Azure を使用すると、単一のアプリを Azure OpenAI Service に簡単に接続できます。つまり、モデル デプロイのレベルで TPM 制限を直接構成し、API キーを使用して直接接続できます。 ただし、アプリケーション ポートフォリオを拡大し始めると、従量課金制またはプロビジョニングされたスループット ユニット (PTU) インスタンスとしてデプロイされた 1 つまたは複数の Azure OpenAI Service エンドポイントを呼び出す複数のアプリが表示されます。 これにはいくつかの課題が伴います。
- 複数のアプリケーション間でトークンの使用状況をどのように追跡しますか? Azure OpenAI Service モデルを使用する複数のアプリケーションまたはチームに対してクロスチャージを計算できますか?
- 1 つのアプリで TPM クォータ全体が消費され、他のアプリで Azure OpenAI Service モデルを使用するためのオプションがなくならないようにするにはどうすればよいでしょうか?
- どのようにして API キーを複数のアプリケーション間で安全に配布しますか?
- 複数の Azure OpenAI エンドポイント間で負荷をどのように分散しますか? 従量課金インスタンスにフォールバックする前に、PTU のコミット済み容量が確実に使い果たされるようにすることができますか?
この記事の残りの部分では、Azure API Management がこれらの課題の解決にどのように役立つかについて説明します。
Azure OpenAI Service リソースを API としてインポートする
ワンクリック エクスペリエンスを使用して、Azure API Management に Azure OpenAI Service エンドポイントから API をインポートします。 API Management を使用すると、Azure OpenAI API の OpenAPI スキーマが自動的にインポートされてオンボード プロセスが効率化され、マネージド ID を使用して Azure OpenAI エンドポイントへの認証が設定されるため、手動による構成は必要ありません。 同じ使いやすいエクスペリエンスで、トークン制限とトークン メトリックの送信に関するポリシーを事前構成できます。

トークン制限ポリシー
Azure OpenAI Service トークンの使用状況に基づいて API コンシューマーごとの制限を管理および適用するには、Azure OpenAI トークン制限ポリシーを構成します。 このポリシーを使用すると、トークン制限を設定できます。これは、1 分あたりのトークン数 (TPM) で表されます。
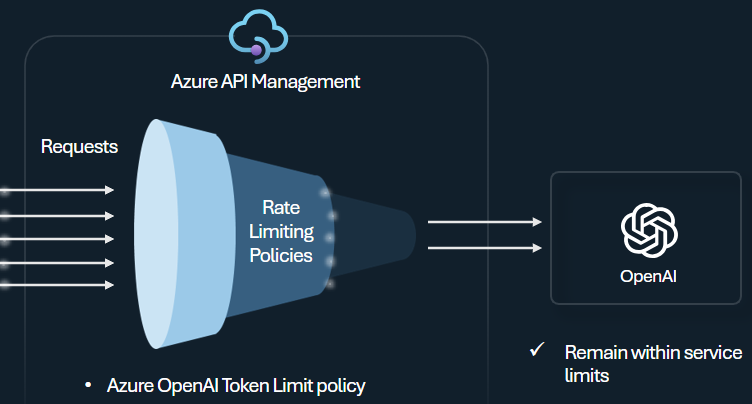
このポリシーにより、サブスクリプション キー、送信元 IP アドレス、ポリシー式で定義された任意のキーなど、任意のカウンター キーにトークン ベースの制限を柔軟に割り当てることができます。 また、Azure API Management 側でプロンプト トークンを事前に計算できるため、プロンプトが制限を既に超えている場合、Azure OpenAI Service バックエンドへの不要な要求が最小限に抑えられます。
次の基本的な例は、TPM 制限をサブスクリプション キーあたり 500 に設定する方法を示しています。
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
ヒント
Azure AI モデル推論 API を介して使用できる LLM API のトークン制限を管理および適用するために、API Management には同等の llm-token-limit ポリシーが用意されています。
トークン メトリックの送信ポリシー
Azure OpenAI トークン メトリックの送信ポリシーは、Azure OpenAI Service API を介した LLM トークンの使用に関するメトリックを Application Insights に送信します。 このポリシーは、複数のアプリケーションまたは API コンシューマー全体での Azure OpenAI Service モデルの使用状況の概要を提供するのに役立ち、 チャージバックのシナリオ、監視、容量計画に役立つ可能性があります。
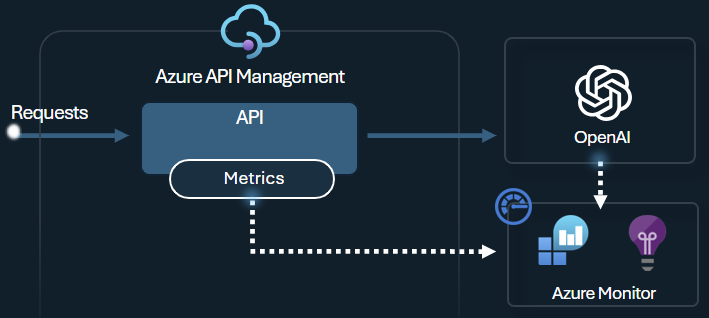
このポリシーは、プロンプト、入力候補、トークンの合計使用量のメトリックをキャプチャし、任意の Application Insights 名前空間に送信します。 さらに、定義済みのディメンションを構成または選択してトークンの使用状況のメトリックを分割できるため、サブスクリプション ID、IP アドレス、または任意のカスタム ディメンションごとにメトリックを分析できます。
たとえば、次のポリシーは、クライアント IP アドレス、API、ユーザーごとに分割されたメトリックを Application Insights に送信します。
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
ヒント
Azure AI モデル推論 API を介して使用できる LLM API のメトリックを送信するために、API Management には同等の llm-emit-token-metric ポリシーが用意されています。
バックエンド ロード バランサーとサーキット ブレーカー
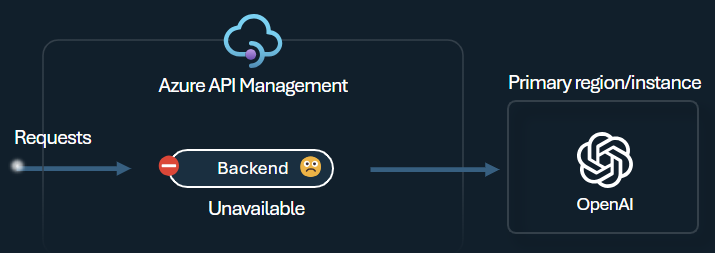
インテリジェント アプリケーションをビルドする際の課題の 1 つは、アプリケーションがバックエンドの障害に対して耐性があり、高い負荷を確実に処理できるようにすることです。 Azure API Management でバックエンドを使用して Azure OpenAI Service エンドポイントを構成すると、エンドポイント間で負荷を分散できます。 また、Azure OpenAI Service バックエンドが応答しない場合に要求の転送を停止するサーキット ブレーカー ルールを定義することもできます。
バックエンド ロード バランサーでは、ラウンドロビン、重み付け、優先度ベースの負荷分散がサポートされており、特定の要件を満たす負荷分散戦略を柔軟に定義できます。 たとえば、ロード バランサーの構成内で優先順位を定義して、特定の Azure OpenAI エンドポイント (特に PTU として購入されたもの) が最適に利用されるようにします。
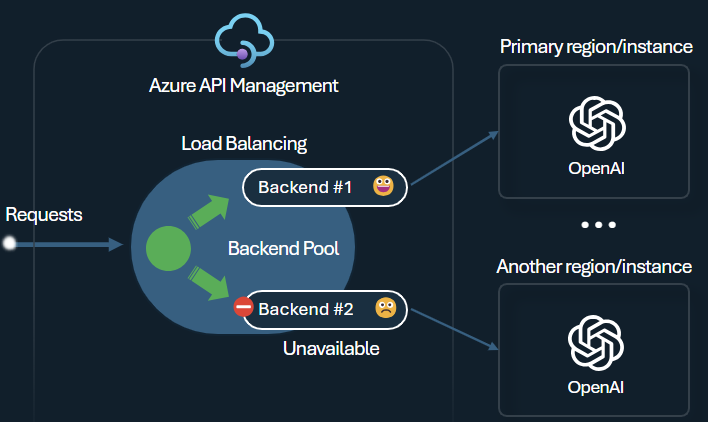
バックエンド サーキット ブレーカーの特徴は、バックエンドによって提供される Retry-After ヘッダーの値が適用する動的なトリップ期間にあります。 これにより、バックエンドの正確でタイムリーな復旧が保証され、優先バックエンドの使用率が最大化されます。
セマンティック キャッシュ ポリシー
類似するプロンプトの入力候補を格納してトークンの使用を最適化するには、Azure OpenAI セマンティック キャッシュ ポリシーを構成します。
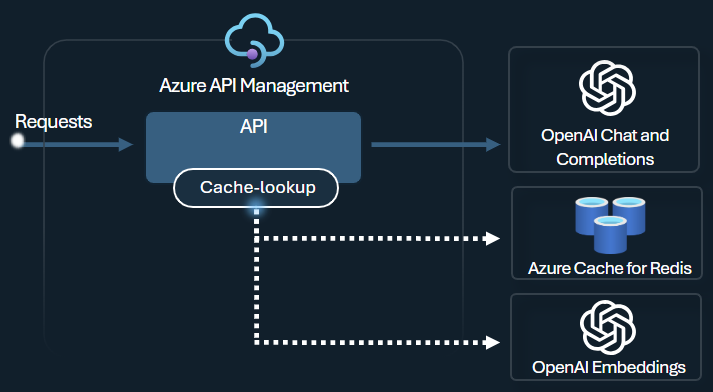
API Management で、Azure Redis Enterprise を使用するか、または RediSearch と互換性があり、Azure API Management にオンボードされている別の外部キャッシュを使用して、セマンティック キャッシュを有効にします。 Azure OpenAI Service Embeddings API を使用すると、azure-openai-semantic-cache-store および azure-openai-semantic-cache-lookup ポリシーによって、意味的に類似したプロンプトの入力候補がキャッシュに格納され、そこから取得されます。 このアプローチにより、入力候補を確実に再利用できるため、トークンの消費量が削減され、応答パフォーマンスが向上します。
ヒント
Azure AI モデル推論 API を介して使用できる LLM API のセマンティック キャッシュを有効にするために、API Management には同等の llm-semantic-cache-store-policy および llm-semantic-cache-lookup-policy ポリシーが用意されています。
ラボとサンプル
- Azure API Management の GenAI ゲートウェイ機能用のラボ
- Azure API Management (APIM) - Azure OpenAI のサンプル (Node.js)
- API Management で Azure OpenAI を使用するための Python サンプル コード
アーキテクチャと設計の考慮事項
- API Management を使用する GenAI ゲートウェイ リファレンス アーキテクチャ
- AI ハブ ゲートウェイ ランディング ゾーン アクセラレータ
- Azure OpenAI リソースを使用したゲートウェイ ソリューションの設計と実装
- 複数の Azure OpenAI デプロイまたはインスタンスの前にゲートウェイを使用する