Retrieval-Augmented 生成 (RAG) ソリューションの前の手順では、ドキュメントをチャンクに分割し、チャンクをエンリッチしました。 この手順では、これらのチャンクと、ベクター検索を実行する予定のメタデータ フィールドの埋め込みを生成します。
この記事はシリーズの一部です。 の概要をお読みください。
埋め込みは、テキストなどのオブジェクトの数学的表現です。 ニューラル ネットワークのトレーニング中は、オブジェクトの多くの表現が作成されます。 各表現には、ネットワーク内の他のオブジェクトへの接続があります。 埋め込みは、オブジェクトのセマンティックな意味をキャプチャするため重要です。
1 つのオブジェクトの表現は、他のオブジェクトの表現に接続されているため、オブジェクトを数学的に比較できます。 次の例は、埋め込みによってセマンティックな意味と相互の関係をキャプチャする方法を示しています。
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
埋め込みは、類似性と距離の概念を使用して相互に比較されます。 次のグリッドは、埋め込みの比較を示しています。

RAG ソリューションでは、多くの場合、チャンクと同じ埋め込みモデルを使用してユーザー クエリを埋め込みます。 次に、データベースで関連するベクターを検索して、最も意味的に関連するチャンクを返します。 関連するチャンクの元のテキストは、グラウンド データとして言語モデルに渡されます。
手記
ベクトルは、数学的比較を可能にする方法でテキストのセマンティックな意味を表します。 ベクトル間の数学的近接性がセマンティック関連性を正確に反映するように、チャンクをクリーンアップする必要があります。
埋め込みモデルの重要性
選択した埋め込みモデルは、ベクター検索結果の関連性に大きく影響する可能性があります。 埋め込みモデルのボキャブラリを考慮する必要があります。 すべての埋め込みモデルは、特定のボキャブラリでトレーニングされます。 たとえば、BERT モデルの のボキャブラリ サイズは約 30,000 語です。
埋め込みモデルのボキャブラリは、ボキャブラリにない単語を独自の方法で処理するため、重要です。 単語がモデルのボキャブラリにない場合でも、その単語のベクトルが計算されます。 これを行うために、多くのモデルは単語をサブワードに分割します。 サブワードを個別のトークンとして扱うか、サブワードのベクトルを集計して単一の埋め込みを作成します。
たとえば、ヒスタミン

これらのサブワードの意味は、ヒスタミン
埋め込みモデルを選択する
ユース ケースに適した埋め込みモデルを決定します。 埋め込みモデルを選択するときに、埋め込みモデルのボキャブラリとデータの単語の重複を考慮してください。

まず、ドメイン固有のコンテンツがあるかどうかを判断します。 たとえば、ドキュメントはユース ケース、組織、業界に固有ですか? ドメインの特定性を判断する良い方法は、インターネット上のコンテンツでエンティティとキーワードを見つけることができるかどうかを確認することです。 可能であれば、一般的な埋め込みモデルも可能です。
一般的なコンテンツまたはドメイン固有でないコンテンツ
一般的な埋め込みモデルを選択する場合は、Hugging Face ランキングから開始します。 up-to-date 埋め込みモデルのランク付けを取得します。 モデルがデータでどのように機能するかを評価し、上位のモデルから始めます。
ドメイン固有のコンテンツ
ドメイン固有のコンテンツの場合は、ドメイン固有のモデルを使用できるかどうかを判断します。 たとえば、データが生体医学領域にある可能性があるため、BioGPT モデル使用できます。 この言語モデルは、バイオメディカル文献の大規模なコレクションに事前トレーニングされています。 これは、バイオメディカル テキスト マイニングと生成に使用できます。 ドメイン固有のモデルが使用可能な場合は、これらのモデルがデータとどのように連携するかを評価します。
ドメイン固有のモデルがない場合、またはドメイン固有のモデルが適切に動作しない場合は、ドメイン固有のボキャブラリを使用して一般的な埋め込みモデルを微調整できます。
大事な
選択したモデルについては、ライセンスがニーズに合っていることを確認し、モデルが必要な言語サポートを提供していることを確認する必要があります。
埋め込みモデルを評価する
埋め込みモデルを評価するには、埋め込みを視覚化し、質問ベクトルとチャンク ベクトル間の距離を評価します。
埋め込みを視覚化する
t-SNE などのライブラリを使用して、チャンクのベクトルと質問を X-Y グラフにプロットできます。 その後、チャンクが互いにどの程度離れているか、質問から離れているかを判断できます。 次のグラフは、プロットされたチャンク ベクトルを示しています。 互いに近い 2 つの矢印は、2 つのチャンク ベクトルを表します。 もう 1 つの矢印は質問ベクトルを表します。 この視覚化を使用して、質問がチャンクからどのくらい離れているかを理解できます。
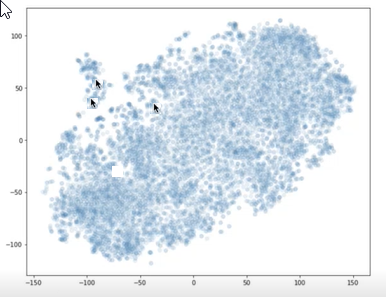
2 つの矢印は互いに近いプロット ポイントを指し、もう 1 つの矢印は他の 2 つから遠く離れたプロット ポイントを示しています。
埋め込み距離を計算する
プログラムによる方法を使用して、埋め込みモデルが質問やチャンクとどの程度うまく機能するかを評価できます。 質問ベクトルとチャンク ベクトルの間の距離を計算します。 ユークリッド距離またはマンハッタン距離を使用できます。
埋め込み経済学
埋め込みモデルを選択する場合は、パフォーマンスとコストのトレードオフをナビゲートする必要があります。 通常、大規模な埋め込みモデルでは、データセットのベンチマークのパフォーマンスが向上します。 ただし、パフォーマンスが向上するとコストが増加します。 大きなベクターでは、ベクター データベース内に必要な領域が増えます。 また、埋め込みを比較するために必要な計算リソースと時間も増えます。 通常、小さな埋め込みモデルでは、同じベンチマークでパフォーマンスが低下します。 ベクター データベースに必要な領域が少なくなり、埋め込みを比較するためのコンピューティングと時間が短縮されます。
システムを設計するときは、ストレージ、コンピューティング、パフォーマンスの要件に関する埋め込みのコストを考慮する必要があります。 実験を通じてモデルのパフォーマンスを検証する必要があります。 公開されているベンチマークは主に学術的なデータセットであり、ビジネス データやユース ケースには直接適用されない場合があります。 要件に応じて、コストよりもパフォーマンスを優先したり、十分なパフォーマンスのトレードオフを受け入れてコストを削減したりできます。
次の手順
関連リソース
- Azure OpenAI Service の埋め込みについて
- チュートリアル: Azure OpenAI サービスの埋め込みとドキュメント検索の を調べる