データ レイクとは
データ レイクは、大量のデータを未加工のネイティブ形式で保持するストレージ リポジトリです。 データ レイク ストアは、サイズをテラバイト級およびペタバイト級のデータにスケーリングできるように最適化されています。 データは通常、複数の多様なソースから取得されるため、データには構造化データ、半構造化データ、または非構造化データが含まれる場合があります。 データ レイクを使用すると、それらすべてを、変換されていない元の状態で格納できます。 この方法は、データを取り込むときに変換と処理を行う、従来のデータ ウェアハウスとは異なります。
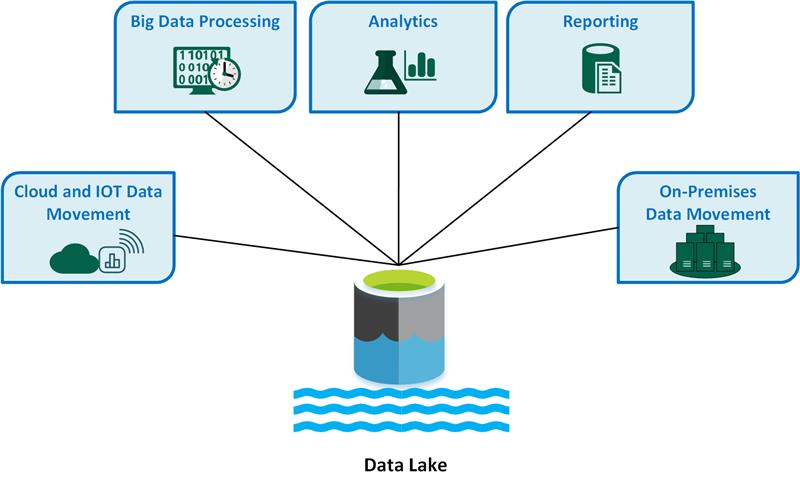
データ レイクの主なユース ケースは次のとおりです。
- クラウドとモノのインターネット (IoT) のデータ移動。
- ビッグ データの処理。
- 分析。
- レポート作成。
- オンプレミスのデータ移動。
データ レイクの次の利点を考慮してください。
データ レイクでは、データが未加工の形式で格納されるため、データは削除されません。 この機能は、特にビッグ データ環境で有用です。ビッグ データ環境では、データからどのような分析情報が得られるかを前もって知ることができないからです。
ユーザーは、データを探索したり、独自のクエリを作成したりできます。
データ レイクは、従来の Extract/Transform/Load (ETL) ツールよりも高速な場合があります。
データ レイクは、非構造化および半構造化データを格納できるため、データ ウェアハウスよりも柔軟性が高くなります。
完全なデータ レイク ソリューションは、ストレージと処理の両方で構成されます。 データ レイク ストレージは、フォールト トレランス、無限のスケーラビリティ、さまざまな形状やサイズのデータの高スループット取り込みを実現するように設計されています。 データ レイク処理には、これらの目標を組み込み、データ レイクに大規模に格納されたデータを操作できる 1 つ以上の処理エンジンが必要です。
データ レイクを使用する必要がある場合
データ探索、データ分析、機械学習には、データ レイクを使用することをお勧めします。
データ レイクは、データ ウェアハウスのデータ ソースとして機能することもできます。 この方法を使用すると、データ レイクで生データを取り込み、構造化されたクエリ可能な形式に変換することができます。 この変換では通常、Extract/Transform/Load (ELT) パイプラインが使用されます。このパイプラインでは、データが取り込まれ、その場で変換されます。 リレーショナル ソース データは、ETL プロセスを介してデータ ウェアハウスに直接送信され、データ レイクをスキップする場合があります。
イベント ストリーミングや IoT のシナリオでデータ レイク ストアを使用できます。データ レイクは、変換やスキーマ定義を使用せずに、大量のリレーショナル データと非リレーショナル データを永続化できるためです。 データ レイクは、短い待機時間で小規模な書き込みを大量に処理でき、大量のスループットに合わせて最適化されています。
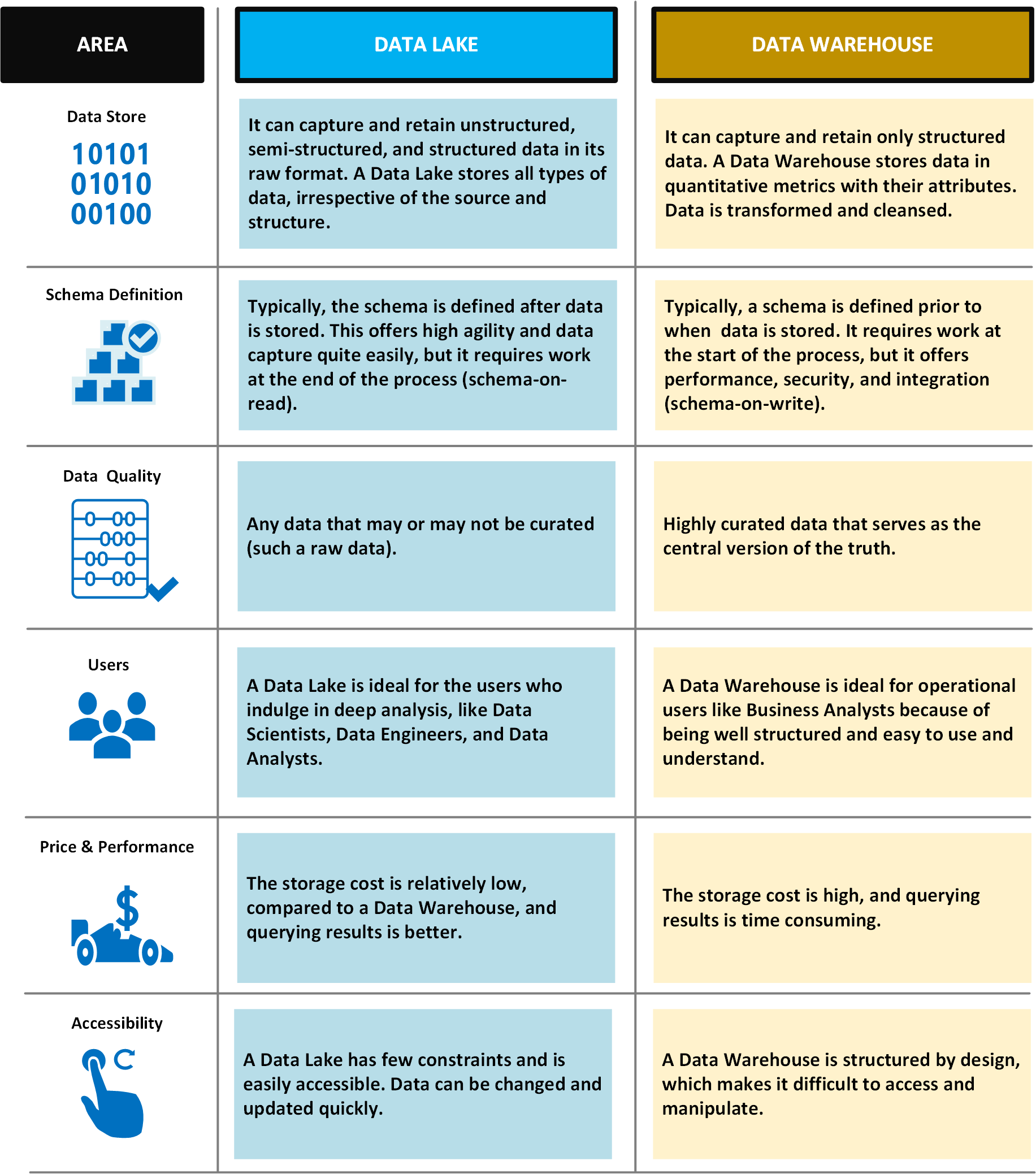
次の表は、データ レイクとデータ ウェアハウスを比較したものです。
課題
大量のデータ: 膨大な量の生データや非構造化データの管理は複雑で多くのリソースを必要とする場合があるため、堅牢なインフラストラクチャとツールが必要です。
潜在的なボトルネック: 特にデータ量が多く、データの種類が多様な場合、データ処理によって遅延や非効率が生じる可能性があります。
データ破損のリスク: 不適切なデータ検証と監視により、データ破損のリスクが生じ、データ レイクの整合性が損なわれる可能性があります。
品質管理の問題: データ ソースと形式が多様であるため、適切なデータ品質を確保することは困難です。 厳格なデータ ガバナンス プラクティスを実装する必要があります。
パフォーマンスの問題: データ レイクが拡大するにつれてクエリのパフォーマンスが低下する可能性があるため、ストレージ戦略と処理戦略を最適化する必要があります。
テクノロジの選択
Azure 上に包括的なデータ レイク ソリューションを構築する際は、次のテクノロジを考慮してください。
Azure Data Lake Storage は、Azure Blob Storage とデータ レイク機能を組み合わせたものであり、Apache Hadoop と互換性のあるアクセス、階層型名前空間の機能、および効率的なビッグ データ分析のためのセキュリティ強化を利用できます。
Azure Databricks は、データの処理、格納、分析、収益化に使用できる統合プラットフォームです。 ETL プロセス、ダッシュボード、セキュリティ、データ探索、機械学習、生成 AI がサポートされています。
Azure Synapse Analytics は、ビジネス インテリジェンスと機械学習に関わる目下のニーズに合わせてデータの取り込み、探索、準備、管理、提供を行うために使用できる統合サービスです。 Azure データ レイクと深く統合されているため、大規模なデータセットのクエリと分析を効率的に実行できます。
Azure Data Factory は、データドリブン型のワークフローを作成してからデータの移動と変換を調整し自動化するために使用できる、クラウドベースのデータ統合サービスです。
Microsoft Fabric は、データ エンジニアリング、データ サイエンス、データ ウェアハウス、リアルタイム分析、ビジネス インテリジェンスを 1 つのソリューションに統合する包括的なデータ プラットフォームです。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Avijit Prasad | クラウド コンサルタント
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
- OneLake とは
- Data Lake Storage の概要
- Azure Data Lake Analytics のドキュメント
- トレーニング: Data Lake Storage の概要
- Hadoop と Azure Data Lake Storage の統合
- Data Lake Storage と Blob Storage への接続
- Azure Data Factory を使用して Data Lake Storage にデータを読み込む