この記事では、開発チームでメトリックを使用してボトルネックを発見し、分散システムのパフォーマンスを向上させた方法について説明します。 この記事は、サンプル アプリケーションに対して行われた実際のロード テストに基づいています。
この記事はシリーズの一部です。 最初のパートはこちらからお読みください。
シナリオ:Azure Functions を使用してイベントのストリームを処理します。

このシナリオでは、ドローンのグループが位置データをリアルタイムで Azure IoT Hub に送信します。 関数アプリはイベントを受信し、データを GeoJSON 形式に変換し、変換されたデータを Azure Cosmos DB に書き込みます。 Azure Cosmos DB は地理空間データをネイティブでサポートしており、効率的な空間クエリのために Azure Cosmos DB コレクションにインデックスを付けることができます。 たとえば、クライアント アプリケーションは、特定の地点から 1 km 以内のすべてのドローンを照会したり、特定のエリア内のすべてのドローンを検索したりできます。
これらの処理要件は単純なので、本格的なストリーム処理エンジンは必要ありません。 特に、処理ではストリームの結合、データの集計、または時間ウィンドウをまたいだ処理は行いません。 これらの要件を踏まえると、Azure Functions がメッセージの処理に適しています。 非常に高い書き込みスループットをサポートするように Azure Cosmos DB を拡張することもできます。
スループットの監視
このシナリオは、パフォーマンスに関する興味深い課題を示します。 デバイスごとのデータ レートはわかっていますが、デバイスの数は変動する場合があります。 このビジネス シナリオでは、待機時間の要件は特に厳しくありません。 報告されるドローンの位置は 1 分以内の精度で十分です。 ただし、時間が経っても関数アプリの処理が平均取り込み速度より遅れてはなりません。
IoT Hub はメッセージをログ ストリームに格納します。 受信メッセージはストリームの末尾に追加されます。 ストリームのリーダー (この場合、関数アプリ) は、それがストリームをトラバースする独自の速度を制御します。 このように読み取りパスと書き込みパスを分離することで、IoT Hub は非常に効率的になりますが、それは低速なリーダーが遅れをとる可能性があることも意味します。 この状態を検出するために、開発チームはメッセージの遅延を測定するためのカスタム メトリックを追加しました。 このメトリックは、メッセージが IoT Hub に到着してから、関数が処理のためにメッセージを受信するまでの時間差を記録します。
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
TrackMetric メソッドはカスタム メトリックを Application Insights に書き込みます。 Azure Function 内での TrackMetric の使用については、C# 関数でのカスタム テレメトリに関するページを参照してください。
メッセージの分量に対して関数の処理が遅れていない場合、このメトリックは低く安定した状態にとどまるはずです。 多少の待機時間は避けられないため、値がゼロになることはありません。 しかし、関数の処理が遅れている場合、キューに入っている時間と処理時間の差が広がり始めます。
テスト 1:ベースライン
最初のロード テストでは、すぐに問題が発生しました。関数アプリは終始、Azure Cosmos DB から HTTP 429 エラーを受信しましたが、これは Azure Cosmos DB が書き込み要求の帯域幅を調整していたことを示します。
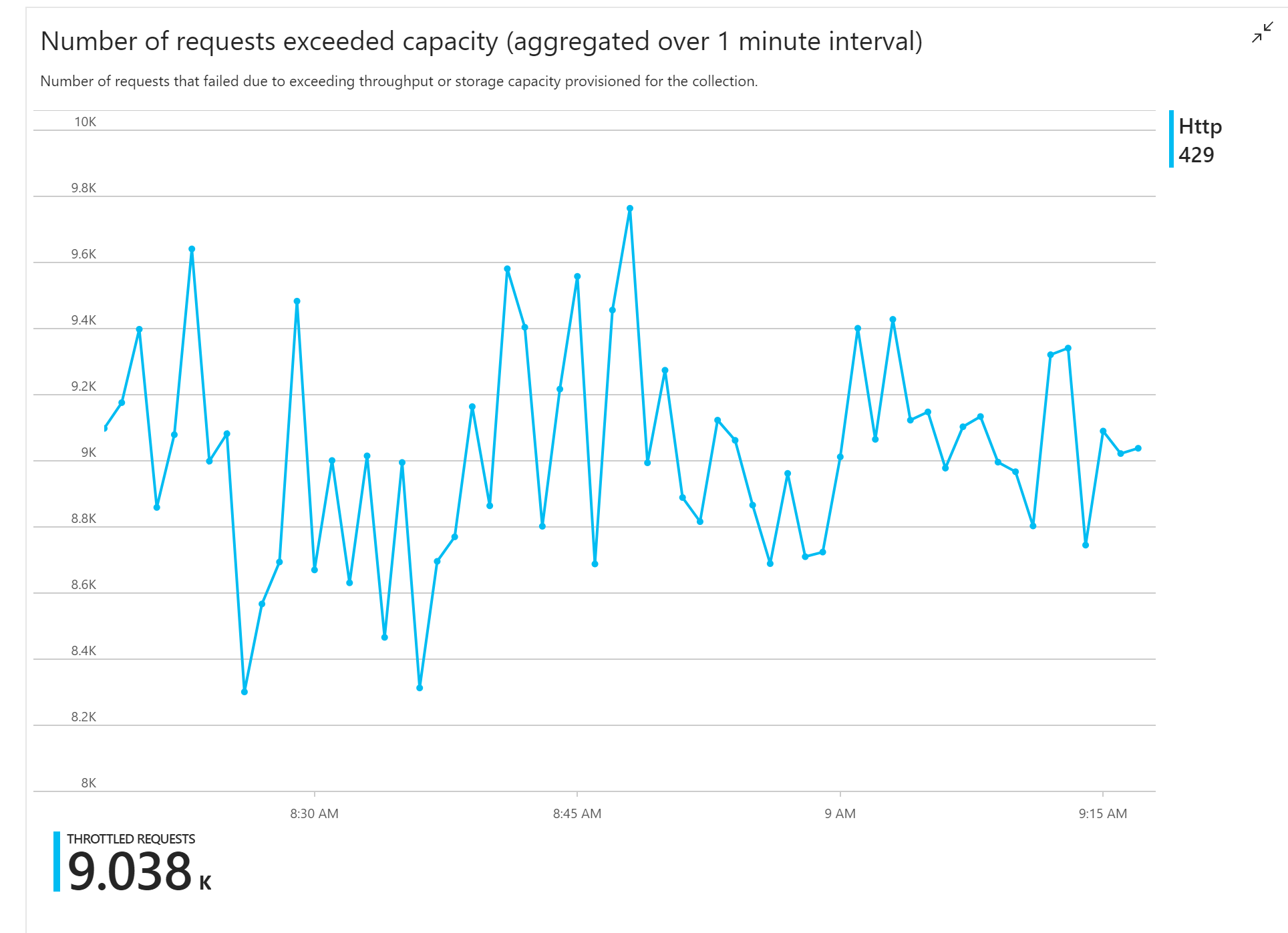
対応として、チームはコレクションに割り当てる RU の数を増やして Azure Cosmos DB をスケーリングしましたが、エラーは続きました。 これは不思議に思われました。なぜなら、"封筒の裏の計算" は、書き込み要求の分量に対して Azure Cosmos DB が遅れずに処理をこなすことに何の問題もないはずと示していたからです。
その日の遅くに、開発者の 1 人がチームに次のメールを送信しました。
Azure Cosmos DB のウォーム パスに注目しました。 1 つ理解できないことがあります。 パーティション キーは deliveryId ですが、deliveryId を Azure Cosmos DB に送信していません。 何かを見落としているのでしょうか?
それが手掛かりでした。 パーティション ヒート マップを見ると、すべてのドキュメントが同じパーティションに位置していることがわかりました。
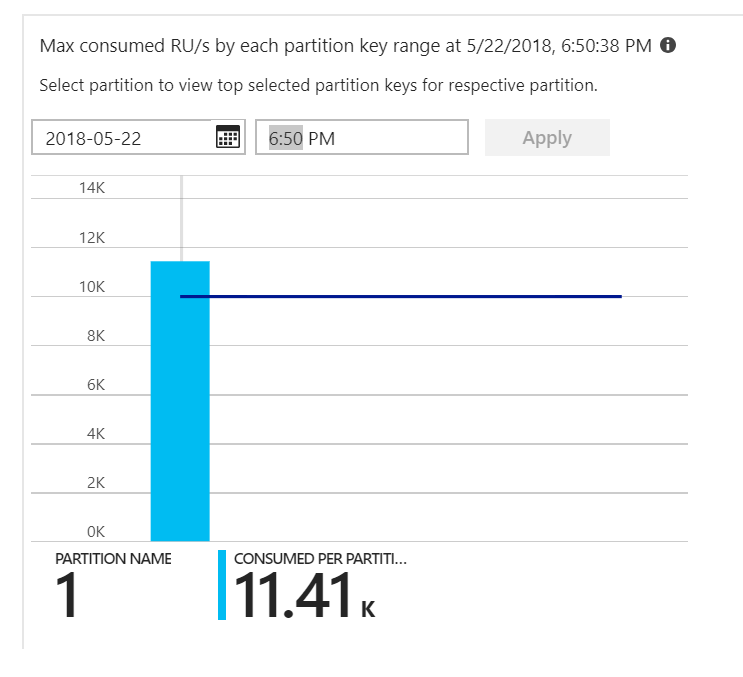
ヒート マップに期待しているのは、すべてのパーティションにわたっての均等な分布です。 この場合、すべてのドキュメントが同じパーティションに書き込まれていたため、RU を追加しても効果がなかったのです。 問題はコードのバグであることが判明しました。 Azure Cosmos DB コレクションにはパーティション キーがありましたが、Azure Functions は実際にはパーティション キーをドキュメントに含めていませんでした。 パーティション ヒート マップの詳細については、「パーティション全体のスループットの分散を決める」を参照してください。
テスト 2:パーティション分割の問題を修正する
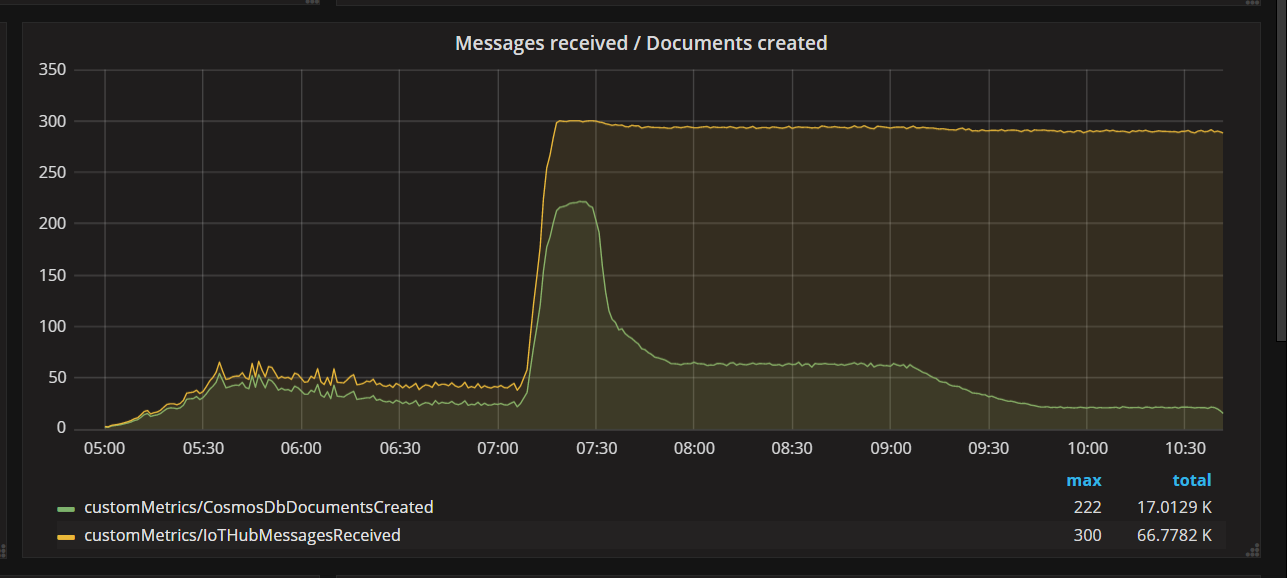
チームがコードの修正をデプロイしてテストを再実行すると、Azure Cosmos DB は帯域幅調整をしなくなりました。 しばらくは何の問題もないように思われました。 しかし、ある一定の負荷で、テレメトリは、想定よりも少ないドキュメントにしか関数が書き込んでいないことを示しました。 次のグラフは、IoT Hub から受信したメッセージと Azure Cosmos DB に書き込まれたドキュメントを示しています。 黄色の線はバッチあたりのメッセージ受信数、緑色はバッチあたりのドキュメント書き込み数です。 これらは比例しているべきです。 そうはならず、07:30 のあたりで、バッチあたりのデータベース書き込み操作の数が著しく低下します。
次のグラフは、メッセージがデバイスから IoT Hub に到着してから、関数アプリがそのメッセージを処理するまでの待機時間を示しています。 同じ時点で遅延が劇的に増加し、横ばいになり、減少しているのがわかります。
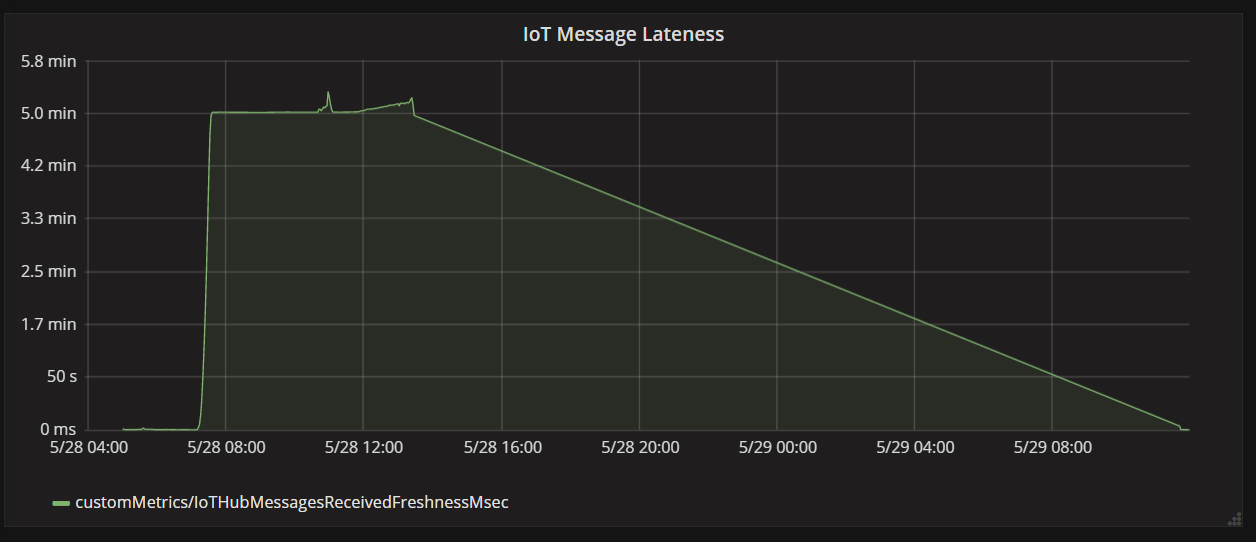
値が 5 分でピークに達した後、ゼロにまで下がるのは、5 分を超えて遅れているメッセージを関数アプリが破棄するからです。
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
グラフではこれを、遅延メトリックが低下してゼロに戻る時点として確認できます。 その間、関数がメッセージを破棄していたため、データが失われています。
何が起きていたのでしょうか? この特定のロード テストでは、Azure Cosmos DB コレクションに RU のスペアがあったため、ボトルネックの箇所はデータベースではありませんでした。 むしろ、問題はメッセージ処理ループにありました。 簡単に言えば、メッセージの受信量に追いつくのに十分な速さで関数がドキュメントを書き込んでいませんでした。 時間が経てば経つほど、遅れは深刻になりました。
テスト 3:並列書き込み
メッセージを処理する時間がボトルネックである場合、1 つの解決策は、より多くのメッセージを並列で処理することです。 このシナリオでは:
- IoT Hub パーティションの数を増やします。 各 IoT Hub パーティションには一度に 1 つの関数インスタンスが割り当てられるため、パーティションの数に対して直線的にスループットがスケーリングすることが期待されます。
- 関数内でドキュメントの書き込みを並列化します。
2 番目のオプションを検討するために、チームは並列書き込みをサポートするように関数を修正しました。 関数の元のバージョンでは、Azure Cosmos DB の出力バインドを使用していました。 最適化されたバージョンは、Azure Cosmos DB クライアントを直接呼び出して、Task.WhenAll を使用して並列で書き込みを実行します。
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
このアプローチでは競合状態の可能性があることに注意してください。 同じドローンからの 2 つのメッセージが、メッセージの同じバッチでたまたま到着したとします。 それらを並列で書き込むと、早いほうのメッセージが遅いほうのメッセージを上書きする可能性があります。 この特定のシナリオでは、メッセージが時々失われることをアプリケーションは許容できます。 ドローンは 5 秒ごとに新しい位置データを送信するので、Azure Cosmos DB 内のデータは継続的に更新されます。 ただし、他のシナリオでは、メッセージを厳密に順序どおりに処理することが重要な場合があります。
このコード変更をデプロイした後、アプリケーションは、32 のパーティションがある IoT Hub を使用して、2500 要求/秒を超える速度で取り込みを実行できました。
クライアント側の考慮事項
サーバー側での積極的な並列処理により、全体的なクライアント エクスペリエンスが低下する場合があります。 Azure Cosmos DB コンテナーに割り当てられているスループットを飽和させるために必要なクライアント側のコンピューティング リソースを大幅に削減する、Azure Cosmos DB のバルク エグゼキューター ライブラリ (この実装には示されていません) を使用することを検討してください。 一括インポート API を使用してデータを書き込むシングルスレッド アプリケーションは、クライアント マシンの CPU を飽和状態にしながらデータを並列に書き込むマルチスレッド アプリケーションと比較して、約 10 倍の書き込みスループットを実現します。
まとめ
このシナリオでは、次のボトルネックが特定されました。
- ホット書き込みパーティション。書き込み中のドキュメントにパーティション キーの値がないことが原因。
- IoT Hub パーティションごとの直列でのドキュメント書き込み。
これらの問題を診断するため、開発チームは次のメトリックを利用しました。
- Azure Cosmos DB の帯域幅調整された要求数。
- パーティション ヒートマップ — パーティションあたりの最大消費 RU 数。
- メッセージ受信数とドキュメント作成数の比率。
- メッセージの遅延。
次のステップ
パフォーマンスのアンチパターンを確認します