この参照アーキテクチャは、データ ストリームの取り込み、データ処理、およびバックエンド データベースへの結果の書き込みを行う サーバーレスなイベント ドリブン アーキテクチャを示しています。
アーキテクチャ
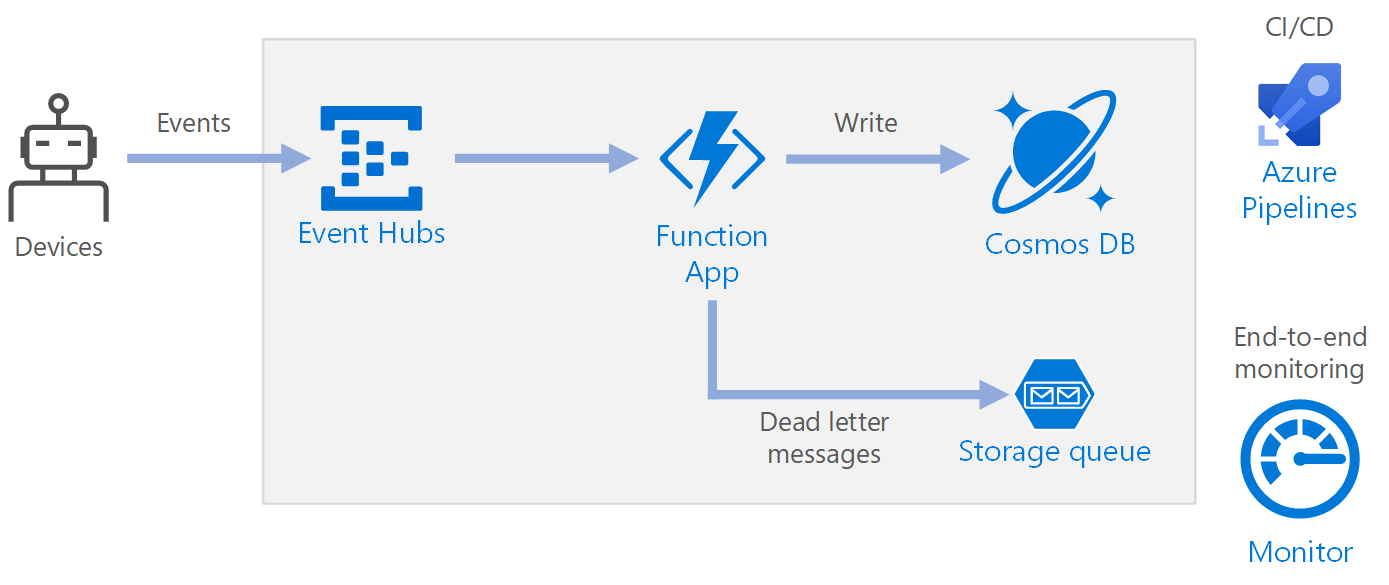
ワークフロー
- イベントが Azure Event Hubs に到達します。
- 関数アプリがトリガーされて、イベントが処理されます。
- イベントが Azure Cosmos DB データベースに保存されます。
- 関数アプリでイベントを正常に保存できなかった場合、イベントはストレージ キューに保存され、後で処理されます。
Components
Event Hubs は、データ ストリームを取り込みます。 Event Hubs は、高スループットのデータ ストリーミング シナリオ用に設計されています。
注意
モノのインターネット (IoT) のシナリオでは、 Azure IoT Hubを使用することをお勧めします。 IoT Hub には、Azure Event Hubs API と互換性がある組み込みのエンドポイントが含まれているため、このアーキテクチャではどちらのサービスも使用できます。その際、バックエンド処理に大きな変更は必要ありません。 詳細については、「IoT デバイスを Azure に接続する:IoT Hub と Event Hubs」を参照してください。
Function App。 Azure Functions はサーバーレス コンピューティングの 1 つのオプションです。 ひとまとまりのコード ("関数") がトリガーによって呼び出されるイベント ドリブン モデルが使用されます。 このアーキテクチャでは、イベントが Event Hubs に到達したとき、そのイベントを処理し、結果をストレージに書き込む関数がトリガーされます。
Function App は、Event Hubs からの個々のレコードを処理するのに適しています。 ストリーム処理がさらに複雑なシナリオでは、 Azure Databricks を使用した Apache Spark、または Azure Stream Analyticsを使用することをご検討ください。
Azure Cosmos DB Azure Cosmos DB は、サーバーレスの使用量ベース モードで使用できるマルチモデルのデータベース サービスです。 このシナリオでは、 Azure Cosmos DB for NoSQL を使用して、イベント処理関数によって JSON レコードが格納されます。
Queue Storage。 Queue Storage は、配信不能メッセージに使用されます。 イベントの処理中にエラーが発生した場合、後で処理できるように、この関数によりイベント データが配信不能キューに格納されます。 詳細については、この記事の「回復性」のセクション (後述) を参照してください。
Azure Monitor。 Monitor は、ソリューションにデプロイされた Azure サービスに関するパフォーマンス メトリックを収集します。 ダッシュボードでこれらを視覚化することで、ソリューションの正常性を把握できます。
Azure Pipelines。 Pipelines は、アプリケーションをビルド、テスト、デプロイする継続的インテグレーション (CI) および継続的デリバリー (CD) サービスです。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
可用性
ここに示したデプロイは単一の Azure リージョンに存在します。 ディザスター リカバリーでより回復性に優れたアプローチを実現するには、さまざまなサービスで地理的分散機能を利用します。
- Event Hubs。 プライマリ (アクティブ) 名前空間とセカンダリ (パッシブ) 名前空間の 2 つの Event Hubs 名前空間を作成します。 メッセージは、セカンダリ名前空間にフェールオーバーしない限り、アクティブな名前空間に自動的にルーティングされます。 詳細については、「Azure Event Hubs geo ディザスター リカバリー」を参照してください。
- Function App。 セカンダリ Event Hubs 名前空間からの読み取りを待っている 2 つ目の関数アプリをデプロイします。 この関数により、配信不能キュー用にセカンダリ ストレージ アカウントへの書き込みが行われます。
- Azure Cosmos DB。 Azure Cosmos DB では 複数の書き込みリージョンがサポートされています。これにより、Azure Cosmos DB アカウントに追加した任意のリージョンに書き込むことができます。 複数の書き込みを有効にしなくても、プライマリ書き込みリージョンには引き続きフェールオーバーできます。 フェールオーバーは、Azure Cosmos DB クライアント SDK と Azure Functions のバインディングによって自動的に処理されるため、アプリケーション構成設定を更新する必要はありません。
- Azure Storage。 配信不能キューに RA-GRS ストレージを使用します。 これにより、別のリージョンに読み取り専用レプリカが作成されます。 プライマリ リージョンが利用不可になると、現在キューにある項目を読み取ることができます。 さらに、セカンダリ リージョンに別のストレージ アカウントをプロビジョニングします。これには、フェールオーバー後に関数が書き込むことができます。
スケーラビリティ
Event Hubs
Event Hubs のスループット容量は、 スループット ユニット で測定されます。 自動インフレを有効にすると、イベント ハブを自動スケーリングできます。自動インフレでは、トラフィックに基づいて、スループット ユニットが構成済みの最大値まで自動的にスケーリングされます。
関数アプリの Event Hubs トリガー は、イベント ハブ内のパーティション数に従ってスケーリングされます。 各パーティションには、関数インスタンスが 1 つずつ割り当てられます。 スループットを最大化するには、イベントは 1 つずつではなくバッチで受信します。
Azure Cosmos DB
Azure Cosmos DB は、2 つの異なる容量モードで使用できます。
- サーバーレスは、トラフィックが断続的または予測不可能で、平均対ピークのトラフィック比率が低いワークロード用です。
- プロビジョニングされたスループットは、予測可能なパフォーマンスが必要な持続したトラフィックのワークロード用です。
ワークロードを確実にスケーラブルにするには、Azure Cosmos DB コンテナーを作成するときに、適切な パーティション キー を選択することが重要です。 適切なパーティション キーの特徴をいくつか次に示します。
- キー値のスペースが大きい。
- キー値ごとに読み取り/書き込みが均等に分散され、ホット キーが発生しない。
- 単一のキー値で格納される最大データが、物理パーティションの最大サイズ (20 GB) を超えない。
- ドキュメントのパーティション キーが変更されない。 既存のドキュメントでパーティション キーを更新することはできません。
この参照アーキテクチャのシナリオでは、関数に格納されるドキュメントは、データを送信するデバイスごとに 1 つだけです。 この関数により、 upsert 操作が使用されて、最新のデバイスの状態でドキュメントが継続的に更新されます。 このシナリオでは、書き込みがキーの間で均等に分散されるため、パーティション キーにはデバイス ID が適しています。また、キー値ごと 1 つのドキュメントが存在するため、各パーティションのサイズは厳密にバインドされています。 パーティション キーの詳細については、「Azure Cosmos DB でのパーティション分割とスケーリング」を参照してください。
回復性
Functions と共に Event Hubs トリガーを使用する場合、お使いの処理ループ内で例外がキャッチされます。 ハンドルされない例外が発生すると、Functions ランタイムではメッセージの再試行は行われません。 処理できないメッセージは、配信不能キューに配置されます。 そのメッセージは、帯域外のプロセスを使用して調べられ、是正措置が決定されます。
次のコードでは、どのようにインジェスト関数で例外をキャッチし、未処理のメッセージが配信不能キューに書き込まれるかを示しています。
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
また、このコード例では、例外が Application Insights にログ記録されます。 パーティション キーとシーケンス番号を使用すると、配信不能メッセージをログの例外に関連付けることができます。
配信不能キューのメッセージには、エラーのコンテキストを把握するのに十分な情報が記載されているはずです。 この例の DeadLetterMessage クラスには、例外メッセージ、元のイベント本体データ、および逆シリアル化されたイベント メッセージ (使用可能な場合) が含まれています。
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
Azure Monitor を使用して、イベント ハブを監視します。 入力があるのに出力がない場合は、メッセージが処理されていないことを意味します。 その場合は、 Log Analytics に移動し、例外またはその他のエラーを探します。
DevOps
可能であれば、コードとしてのインフラストラクチャ (IaC) を使用します。 IaC では、 Azure Resource Manager のような宣言型のアプローチで、インフラストラクチャ、アプリケーション、ストレージ リソースを管理します。 これは、継続的インテグレーション/継続的デリバリー (CI/CD) ソリューションとして DevOps を使用してデプロイを自動化する際に役立ちます。 テンプレートがバージョン管理され、リリース パイプラインの一部として含まれている必要があります。
テンプレートを作成するときは、ワークロードごとにリソースを整理して分離する方法として、リソースをグループ化します。 ワークロードは一般的に、単一のサーバーレス アプリケーションまたは 1 つの仮想ネットワークと見なされます。 ワークロードの分離の目的は、リソースをチームに関連付けることによって、DevOps チームがそれらのリソースのあらゆる側面を個別に管理し、CI/CD を実行できるようにすることです。
サービスをデプロイしたら、それらを監視する必要があります。 Application Insights を使用して、開発者がパフォーマンスを監視し、問題を検出できるようにすることを検討してください。
障害復旧
ここに示したデプロイは単一の Azure リージョンに存在します。 ディザスター リカバリーでより回復性に優れたアプローチを実現するには、さまざまなサービスで地理的分散機能を利用します。
Event Hubs。 プライマリ (アクティブ) 名前空間とセカンダリ (パッシブ) 名前空間の 2 つの Event Hubs 名前空間を作成します。 メッセージは、セカンダリ名前空間にフェールオーバーしない限り、アクティブな名前空間に自動的にルーティングされます。 詳細については、「Azure Event Hubs geo ディザスター リカバリー」を参照してください。
Function App。 セカンダリ Event Hubs 名前空間からの読み取りを待っている 2 つ目の関数アプリをデプロイします。 この関数により、配信不能キュー用にセカンダリ ストレージ アカウントへの書き込みが行われます。
Azure Cosmos DB Azure Cosmos DB では 複数の書き込みリージョンがサポートされています。これにより、Azure Cosmos DB アカウントに追加した任意のリージョンに書き込むことができます。 複数の書き込みを有効にしなくても、プライマリ書き込みリージョンには引き続きフェールオーバーできます。 フェールオーバーは、Azure Cosmos DB クライアント SDK と Azure Functions のバインディングによって自動的に処理されるため、アプリケーション構成設定を更新する必要はありません。
Azure Storage。 配信不能キューに RA-GRS ストレージを使用します。 これにより、別のリージョンに読み取り専用レプリカが作成されます。 プライマリ リージョンが利用不可になると、現在キューにある項目を読み取ることができます。 さらに、セカンダリ リージョンに別のストレージ アカウントをプロビジョニングします。これには、フェールオーバー後に関数が書き込むことができます。
コストの最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、 コスト最適化の柱の概要に関する記事をご覧ください。
コストを見積もるには、 Azure 料金計算ツール を使用します。 Azure Functions と Azure Cosmos DB に関するその他の考慮事項を次に示します。
Azure Functions
Azure Functions では、次の 2 つのホスティング モデルがサポートされています。
- 従量課金プラン。 コードの実行時にコンピューティング能力が自動的に割り当てられます。
- App Service プラン。 一連の仮想マシン (VM) がお使いのコードに対して割り当てられます。 App Service プランで定義されるのは VM の数とサイズです。
このアーキテクチャでは、Event Hubs に到達するイベントごとに、そのイベントを処理する関数がトリガーされます。 従量課金プラン では使用したコンピューティング リソースにしか支払いが発生しないため、コストの観点から、こちらのプランを使用することをお勧めします。
Azure Cosmos DB
Azure Cosmos DB では、データベースに対して行った操作と、データに使用されるストレージに対して課金されます。
- データベース操作。 データベース操作に対する課金方法は、お使いの Azure Cosmos DB アカウントの種類によって異なります。
- サーバーレス モードでは、Azure Cosmos DB アカウントでリソースを作成するときに、スループットをプロビジョニングする必要はありません。 請求期間が終了すると、データベース操作で使用した 要求ユニット の量に対して課金されます。
- プロビジョニングされたスループット モードでは、1 秒あたりの 要求ユニット数 (RU/s) で必要なスループットを指定し、特定の時間の最大のプロビジョニングされたスループットについて 1 時間単位で課金されます。 注: プロビジョニング済みスループット モデルでは、コンテナーまたはデータベース専用にリソースが割り当てられるので、ワークロードを何も実行しない場合でも、プロビジョニングしたスループットの料金が発生します。
- ストレージ。 対象となる 1 時間にデータおよびインデックスで使用したストレージの合計量 (GB) に対して固定料金が請求されます。
この参照アーキテクチャでは、関数に格納されるドキュメントは、データを送信するデバイスごとに 1 つだけです。 関数は、upsert 操作を使用して、最新のデバイスの状態でドキュメントを継続的に更新します。これはストレージ使用の点でコスト効率に優れています。 詳細については、 Azure Cosmos DB の価格モデルに関するページを参照してください。
ワークロード コストをすばやく見積もるには、 Azure Cosmos DB 容量計算ツール を使用します。
このシナリオのデプロイ
 このアーキテクチャの参照実装は、 GitHub で入手できます。
このアーキテクチャの参照実装は、 GitHub で入手できます。
次のステップ
- Azure Functions の概要
- Azure Cosmos DB へようこそ
- Azure Queue Storage とは
- Azure Monitor の概要
- Azure Pipelines のドキュメント