チュートリアル: 自動検証テスト
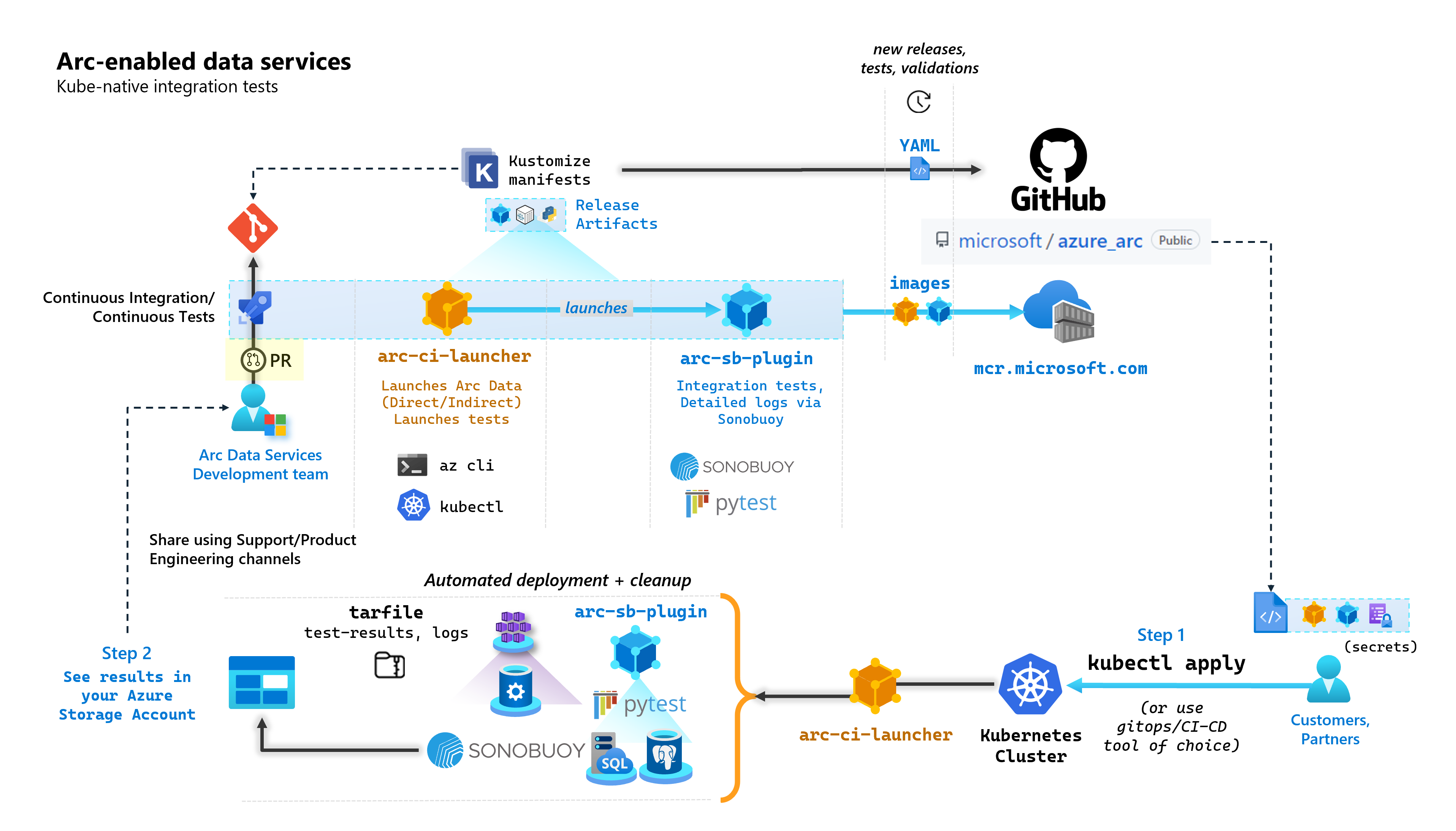
Arc 対応データ サービスを構築する各コミットの一環として、Microsoft はエンド ツー エンドテストを実行する自動 CI/CD パイプラインを実行します。 これらのテストは、コア製品 (データ コントローラー、Azure Arc 対応 SQL Managed Instance、PostgreSQL サーバー) と共に管理される 2 つのコンテナーを介して調整されます。 これらのコンテナーは次のとおりです。
arc-ci-launcher: 直接および間接接続モードの両方のデプロイ依存関係 (CLI 拡張機能など) と製品デプロイ コード (Azure CLI を使用) が含まれています。 Kubernetes がデータ コントローラーにオンボードされると、コンテナーでは Sonobuoy を利用した並列統合テストがトリガーされます。arc-sb-plugin: 単純なスモーク テスト (デプロイ、削除)、複雑な高可用性シナリオ、カオス テスト (リソースの削除) など、Pytest ベースのエンドツーエンド統合テストを含む Sonobuoy プラグイン。
これらのテスト コンテナーは、お客様とパートナーが、任意の場所で実行されている独自の Kubernetes クラスターで Arc 対応データ サービスの検証テストを実行して、次の検証を行うために一般公開されています。
- Kubernetes ディストリビューション、バージョン
- ホスト ディストリビューション、バージョン
- ストレージ (
StorageClass/CSI)、ネットワーク (LoadBalancer、DNS など) - その他の Kubernetes またはインフラストラクチャ固有のセットアップ
文書化されていないディストリビューションで Arc 対応 Data Services を実行する予定のお客様は、これらの検証テストを正常に実行して、サポートされていると見なされる必要があります。 さらに、パートナーはこのアプローチを使用して、ソリューションが Arc 対応 Data Services に準拠していることを認定できます。「Azure Arc 対応データ サービス Kubernetes 検証」を参照してください。
次の図は、この大まかなプロセスの概要を示しています。
このチュートリアルでは、以下の内容を学習します。
kubectlを使ってarc-ci-launcherをデプロイする- Azure Blob Storage アカウントで検証テストの結果を確認する
前提条件
資格情報:
test.env.tmplファイルには必要な資格情報が含まれており、それは Azure Arc 接続クラスターと直接接続されたデータ コントローラーのオンボードに必要な既存の前提条件の組み合わせです。 このファイルのセットアップについては、サンプルを使用して以下で説明します。cluster-adminアクセス権を持つテスト済み Kubernetes クラスターへの kubeconfig ファイル (現時点では接続クラスターのオンボードに必要)
クライアント ツール:
kubectlインストール済み - 最小バージョン (メジャー:"1"、マイナー:"21")gitコマンド ライン インターフェイス (または UI ベースの代替)
Kubernetes マニフェストの準備
ランチャーは、Kustomize マニフェストとして、microsoft/azure_arc リポジトリの一部として使用できるようになります。Kustomize が kubectl に組み込まれているので、追加のツールは必要ありません。
- 次のように、リポジトリをローカルでクローンします。
git clone https://github.com/microsoft/azure_arc.git
azure_arc/arc_data_services/test/launcherに移動して、次のフォルダー構造を確認します。
├── base <- Comon base for all Kubernetes Clusters
│ ├── configs
│ │ └── .test.env.tmpl <- To be converted into .test.env with credentials for a Kubernetes Secret
│ ├── kustomization.yaml <- Defines the generated resources as part of the launcher
│ └── launcher.yaml <- Defines the Kubernetes resources that make up the launcher
└── overlays <- Overlays for specific Kubernetes Clusters
├── aks
│ ├── configs
│ │ └── patch.json.tmpl <- To be converted into patch.json, patch for Data Controller control.json
│ └── kustomization.yaml
├── kubeadm
│ ├── configs
│ │ └── patch.json.tmpl
│ └── kustomization.yaml
└── openshift
├── configs
│ └── patch.json.tmpl
├── kustomization.yaml
└── scc.yaml
このチュートリアルでは、AKS の手順に注目しますが、上記のオーバーレイ構造を拡張して、追加の Kubernetes ディストリビューションを含めることができます。
デプロイする準備が整ったマニフェストでは、次の情報が表されます。
├── base
│ ├── configs
│ │ ├── .test.env <- Config 1: For Kubernetes secret, see sample below
│ │ └── .test.env.tmpl
│ ├── kustomization.yaml
│ └── launcher.yaml
└── overlays
└── aks
├── configs
│ ├── patch.json.tmpl
│ └── patch.json <- Config 2: For control.json patching, see sample below
└── kustomization.yam
特定の環境での実行用にランチャーをローカライズするために生成する必要がある 2 つのファイルがあります。 これらの各ファイルは、上記の各テンプレート (*.tmpl) ファイルをコピー貼り付けして入力することで生成できます。
.test.env:.test.env.tmplから入力するpatch.json:patch.json.tmplから入力する
ヒント
.test.env は、ランチャーの動作を駆動する環境変数の 1 つのセットです。 特定の環境を考慮して生成すると、ランチャーの動作の再現性が確保されます。
Config 1: .test.env
.test.env.tmpl を基に生成された .test.env ファイルの入力されたサンプルは、以下のインライン コメントで共有されています。
重要
以下の export VAR="value" 構文は、コンピューターからソース環境変数に対してローカルに実行されることを意図したものではなく、ランチャー用に用意されています。 ランチャーによって、Kustomize の secretGenerator が使用され、この .test.env ファイルがそのまま Kubernetes secret としてマウントされます (Kustomize でファイルを受け取り、base64 でファイル全体のコンテンツをエンコードし、Kubernetes シークレットに変換されます)。 初期化中、ランチャーでは bash の source コマンドが実行されます。これにより、環境変数がマウントされた .test.env ファイルからランチャーの環境にインポートされます。
つまり、.test.env.tmpl のコピー貼り付けと編集を行って .test.env を作成した後、生成されたファイルは次のサンプルのようになります。 .test.env ファイルを入力するプロセスは、オペレーティング システムとターミナル全体で同じです。
ヒント
再現性を明確にするために追加の説明が必要な環境変数がいくつかあります。 これらは see detailed explanation below [X] でコメントされます。
ヒント
以下の .test.env の例は直接モード用であることに注意してください。 ARC_DATASERVICES_EXTENSION_VERSION_TAG など、これらの変数の一部は間接モードには適用されません。 わかりやすくするために、直接モード変数を念頭に置いて .test.env ファイルを設定することをお勧めします。CONNECTIVITY_MODE=indirect を切り替えると、ランチャーでは直接モード固有の設定が無視され、リストのサブセットが使用されます。
つまり、直接モード向けに計画することで、間接モード変数を満たすことができます。
.test.env の完成したサンプル:
# ======================================
# Arc Data Services deployment version =
# ======================================
# Controller deployment mode: direct, indirect
# For 'direct', the launcher will also onboard the Kubernetes Cluster to Azure Arc
# For 'indirect', the launcher will skip Azure Arc and extension onboarding, and proceed directly to Data Controller deployment - see `patch.json` file
export CONNECTIVITY_MODE="direct"
# The launcher supports deployment of both GA/pre-GA trains - see detailed explanation below [1]
export ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN="stable"
export ARC_DATASERVICES_EXTENSION_VERSION_TAG="1.11.0"
# Image version
export DOCKER_IMAGE_POLICY="Always"
export DOCKER_REGISTRY="mcr.microsoft.com"
export DOCKER_REPOSITORY="arcdata"
export DOCKER_TAG="v1.11.0_2022-09-13"
# "arcdata" Azure CLI extension version override - see detailed explanation below [2]
export ARC_DATASERVICES_WHL_OVERRIDE=""
# ================
# ARM parameters =
# ================
# Custom Location Resource Provider Azure AD Object ID - this is a single, unique value per Azure AD tenant - see detailed explanation below [3]
export CUSTOM_LOCATION_OID="..."
# A pre-rexisting Resource Group is used if found with the same name. Otherwise, launcher will attempt to create a Resource Group
# with the name specified, using the Service Principal specified below (which will require `Owner/Contributor` at the Subscription level to work)
export LOCATION="eastus"
export RESOURCE_GROUP_NAME="..."
# A Service Principal with "sufficient" privileges - see detailed explanation below [4]
export SPN_CLIENT_ID="..."
export SPN_CLIENT_SECRET="..."
export SPN_TENANT_ID="..."
export SUBSCRIPTION_ID="..."
# Optional: certain integration tests test upload to Log Analytics workspace:
# https://learn.microsoft.com/azure/azure-arc/data/upload-logs
export WORKSPACE_ID="..."
export WORKSPACE_SHARED_KEY="..."
# ====================================
# Data Controller deployment profile =
# ====================================
# Samples for AKS
# To see full list of CONTROLLER_PROFILE, run: az arcdata dc config list
export CONTROLLER_PROFILE="azure-arc-aks-default-storage"
# azure, aws, gcp, onpremises, alibaba, other
export DEPLOYMENT_INFRASTRUCTURE="azure"
# The StorageClass used for PVCs created during the tests
export KUBERNETES_STORAGECLASS="default"
# ==============================
# Launcher specific parameters =
# ==============================
# Log/test result upload from launcher container, via SAS URL - see detailed explanation below [5]
export LOGS_STORAGE_ACCOUNT="<your-storage-account>"
export LOGS_STORAGE_ACCOUNT_SAS="?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=..."
export LOGS_STORAGE_CONTAINER="arc-ci-launcher-1662513182"
# Test behavior parameters
# The test suites to execute - space seperated array,
# Use these default values that run short smoke tests, further elaborate test suites will be added in upcoming releases
export SQL_HA_TEST_REPLICA_COUNT="3"
export TESTS_DIRECT="direct-crud direct-hydration controldb"
export TESTS_INDIRECT="billing controldb kube-rbac"
export TEST_REPEAT_COUNT="1"
export TEST_TYPE="ci"
# Control launcher behavior by setting to '1':
#
# - SKIP_PRECLEAN: Skips initial cleanup
# - SKIP_SETUP: Skips Arc Data deployment
# - SKIP_TEST: Skips sonobuoy tests
# - SKIP_POSTCLEAN: Skips final cleanup
# - SKIP_UPLOAD: Skips log upload
#
# See detailed explanation below [6]
export SKIP_PRECLEAN="0"
export SKIP_SETUP="0"
export SKIP_TEST="0"
export SKIP_POSTCLEAN="0"
export SKIP_UPLOAD="0"
重要
Windows マシンで構成ファイルの生成を実行する場合、arc-ci-launcher は Linux コンテナーとして実行されるため、行末シーケンスを CRLF (Windows) から LF (Linux) に変換する必要があります。 行を CRLF で終えたままにすると、arc-ci-launcher コンテナー起動時に /launcher/config/.test.env: $'\r': command not found などのエラーが発生する可能性があります。たとえば、次のように VSCode (ウィンドウの右下) を使用して変更を実行します。

特定の変数の詳細な説明
1. ARC_DATASERVICES_EXTENSION_* - 拡張機能のバージョンとトレーニング
必須: これは、
directモードのデプロイに必要です。
ランチャーでは、GA および GA より前のリリースの両方をデプロイできます。
リリース トレーニング (ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN) マッピングの拡張バージョンは、ここから取得します。
- GA:
stable- バージョン ログ - GA 前:
preview- プレリリース テスト
2. ARC_DATASERVICES_WHL_OVERRIDE - Azure CLI 以前のバージョンのダウンロード URL
省略可能: 事前にパッケージ化された既定値を使用するには、
.test.envでこの値を空のままにします。
ランチャー イメージは、各コンテナー イメージ リリース時に最新の arcdata CLI バージョンで事前にパッケージ化されています。 ただし、以前のリリースとアップグレード テストを使用するには、事前にパッケージ化されたバージョンをオーバーライドするために、ランチャーに Azure CLI BLOB URL のダウンロード リンクを提供することが必要な場合があります。たとえば、ランチャーにバージョン 1.4.3 をインストールするように指示するには、次のように入力します。
export ARC_DATASERVICES_WHL_OVERRIDE="https://azurearcdatacli.blob.core.windows.net/cli-extensions/arcdata-1.4.3-py2.py3-none-any.whl"
BLOB URL マッピングへの CLI バージョンについては、こちらを参照してください。
3. CUSTOM_LOCATION_OID - 特定の Microsoft Entra テナントからのカスタム場所オブジェクト ID
必須: これは、接続クラスターのカスタムの場所の作成に必要です。
「クラスターでカスタムの場所を有効にする」から引用した次の手順では、お使いの Microsoft Entra テナントの一意のカスタム場所オブジェクト ID を取得します。
お使いの Microsoft Entra テナントの CUSTOM_LOCATION_OID を取得するには、2 つの方法があります。
Azure CLI の使用:
az ad sp show --id bc313c14-388c-4e7d-a58e-70017303ee3b --query objectId -o tsv # 51dfe1e8-70c6-4de... <--- This is for Microsoft's own tenant - do not use, the value for your tenant will be different, use that instead to align with the Service Principal for launcher.
Azure portal の使用 - お使いの Microsoft Entra ブレードに移動し、
Custom Locations RPを見つけてください。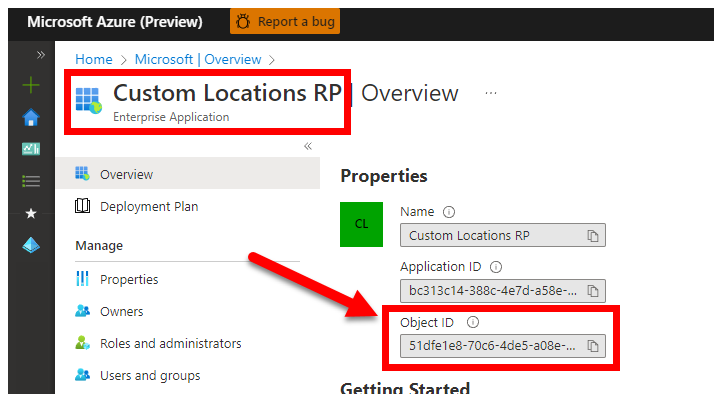
4. SPN_CLIENT_* - サービス プリンシパルの資格情報
必須: これは、直接モードのデプロイに必要です。
ランチャーでは、これらの資格情報を使用して Azure にログインします。
検証テストは、非運用またはテスト環境の Kubernetes クラスターと Azure サブスクリプションで実行することが意図されており、Kubernetes とインフラストラクチャのセットアップの機能検証に重点が置かれています。 したがって、起動を実行するために必要な手動の手順の数々を回避するには、リソース グループ (またはサブスクリプション) レベルで Owner を持つ SPN_CLIENT_ID/SECRET を指定することをお勧めします。これによりリソース グループに複数のリソースが作成され、デプロイの一部として作成された複数のマネージド ID に対してアクセス許可が割り当てられます (これらのロールの割り当てには、サービス プリンシパルに Owner が必要になります)。
5. LOGS_STORAGE_ACCOUNT_SAS - Blob Storage アカウント SAS URL
推奨: これを空のままにすると、テスト結果とログは取得されません。
Kubernetes では停止または完了したポッドからのファイルのコピーを (まだ) 許可していないため、ランチャーには結果をアップロードするための永続的な場所 (Azure Blob Storage) が必要です。こちらを参照してください。 ランチャーは、アカウント スコープの SAS URL (コンテナーまたは BLOB スコープではなく) を使用して Azure Blob Storage への接続を実現します。時間制限付きアクセス定義を持つ署名付き URL については、「Shared Access Signature (SAS) を使用して Azure Storage リソースへの制限付きアクセスを許可する」を参照してください。
- 存在しない場合、既存のストレージ アカウント (
LOGS_STORAGE_ACCOUNT) に新しいストレージ コンテナーを作成する (名前はLOGS_STORAGE_CONTAINERに基づく) - 新しい一意の名前の BLOB を作成する (テスト ログ tar ファイル)
手順は、「Shared Access Signatures (SAS) を使用して Azure Storage リソースへの制限付きアクセスを許可する」に基づいています。
ヒント
SAS URL はストレージ アカウント キーとは異なり、SAS URL は次のように書式設定されます。
?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=...
SAS URL を生成するには、いくつかの方法があります。 次の例は、ポータルを示しています。
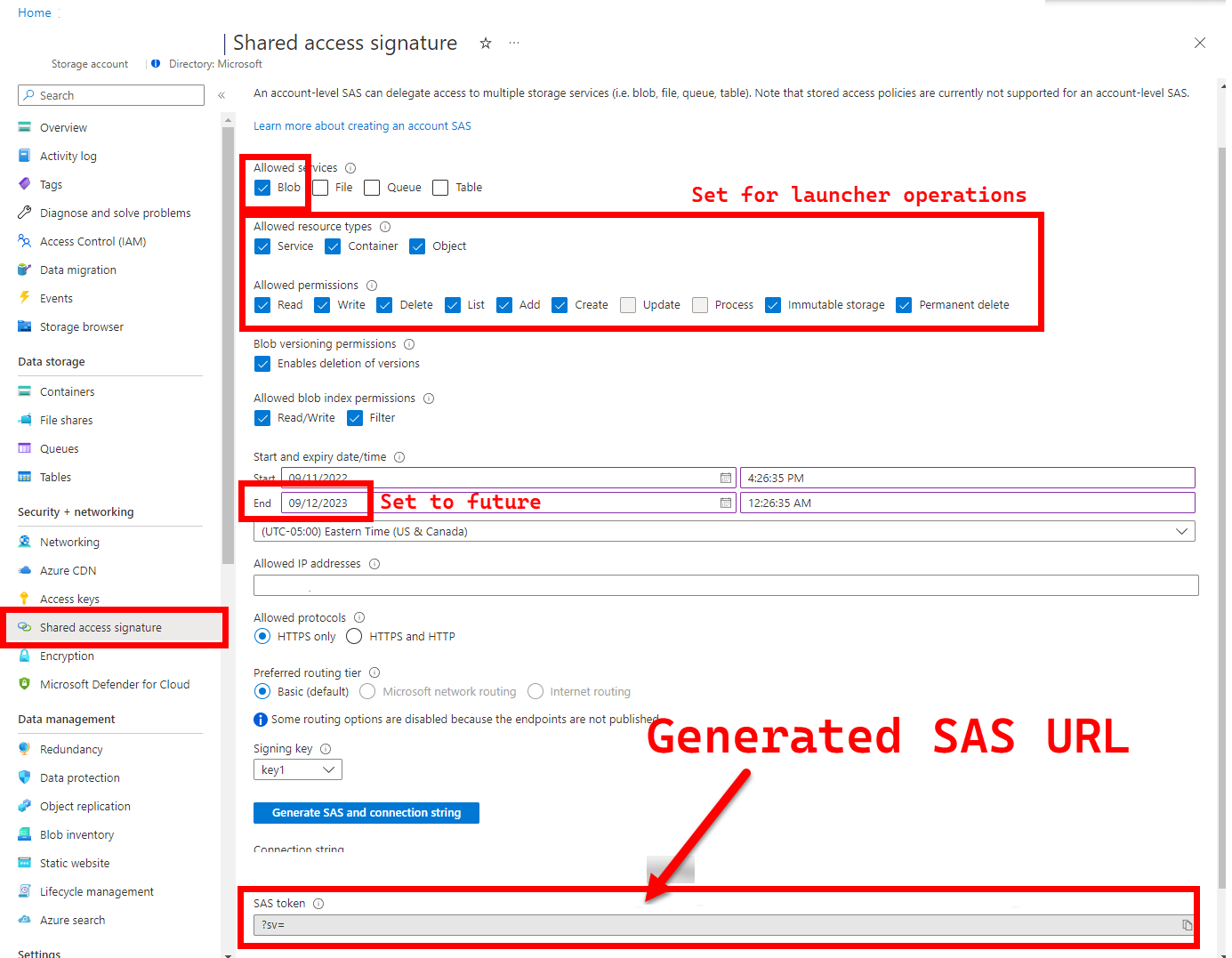
代わりに Azure CLI を使用する場合は、az storage account generate-sas を参照してください。
6. SKIP_* - 特定のステージをスキップしてランチャーの動作を制御する
省略可能: すべてのステージを実行するには、
.test.envでこの値を空のままにします (0または空白と同等)
ランチャーでは、特定のステージを実行してスキップするために SKIP_* 変数が公開されます。たとえば、"クリーンアップのみ" 実行を実行します。
ランチャーは、各実行の開始時と終了時の両方でクリーンアップするように設計されていますが、起動やテストの失敗によって残余リソースが残る可能性があります。 "クリーンアップのみ" モードでランチャーを実行するには、.test.env で変数を次のように設定します。
export SKIP_PRECLEAN="0" # Run cleanup
export SKIP_SETUP="1" # Do not setup Arc-enabled Data Services
export SKIP_TEST="1" # Do not run integration tests
export SKIP_POSTCLEAN="1" # POSTCLEAN is identical to PRECLEAN, although idempotent, not needed here
export SKIP_UPLOAD="1" # Do not upload logs from this run
上記の設定は、すべての Arc および Arc Data Services リソースをクリーンアップし、ログをデプロイ、テスト、アップロードしないようにランチャーに指示します。
Config 2: patch.json
patch.json.tmpl を基に生成された patch.json ファイルの入力されたサンプルは、以下で共有されています。
spec.docker.registry, repository, imageTagは、上記の.test.envの値と同じである必要があることに注意してください
patch.json の完成したサンプル:
{
"patch": [
{
"op": "add",
"path": "spec.docker",
"value": {
"registry": "mcr.microsoft.com",
"repository": "arcdata",
"imageTag": "v1.11.0_2022-09-13",
"imagePullPolicy": "Always"
}
},
{
"op": "add",
"path": "spec.storage.data.className",
"value": "default"
},
{
"op": "add",
"path": "spec.storage.logs.className",
"value": "default"
}
]
}
ランチャーのデプロイ
Arc やその他の使用される Kubernetes リソースに対して破壊的なアクションを実行するため、非運用またはテスト クラスターにランチャーをデプロイすることをお勧めします。
imageTag 仕様
ランチャーは Kubernetes マニフェスト内で Job として定義されており、ランチャーのイメージを見つける場所を Kubernetes に指示する必要があります。 base/kustomization.yaml で設定されます。
images:
- name: arc-ci-launcher
newName: mcr.microsoft.com/arcdata/arc-ci-launcher
newTag: v1.11.0_2022-09-13
ヒント
要約すると、この時点では、3 つの場所で imageTag を指定しました。明確にするために、ここでそれぞれの使用方法について説明します。 通常 - 特定のリリースをテストする場合、3 つの値はすべて同じになります (特定のリリースに合わせて)。
| # | ファイル名 | 変数名 | なぜですか? | 使用元? |
|---|---|---|---|---|
| 1 | .test.env |
DOCKER_TAG |
拡張機能のインストールの一部としてのブートストラップ イメージのソーシング | ランチャーの az k8s-extension create |
| 2 | patch.json |
value.imageTag |
データ コントローラー イメージのソーシング | ランチャーの az arcdata dc create |
| 3 | kustomization.yaml |
images.newTag |
ランチャーのイメージのソーシング | ランチャーの kubectl apply |
kubectl apply
マニフェストが適切に設定されていることを検証するには、--dry-run=client でクライアント側の検証を試みます。これは、ランチャー用に作成する Kubernetes リソースを出力します。
kubectl apply -k arc_data_services/test/launcher/overlays/aks --dry-run=client
# namespace/arc-ci-launcher created (dry run)
# serviceaccount/arc-ci-launcher created (dry run)
# clusterrolebinding.rbac.authorization.k8s.io/arc-ci-launcher created (dry run)
# secret/test-env-fdgfm8gtb5 created (dry run) <- Created from Config 1: `patch.json`
# configmap/control-patch-2hhhgk847m created (dry run) <- Created from Config 2: `.test.env`
# job.batch/arc-ci-launcher created (dry run)
ランチャーとログ末尾をデプロイするには、次を実行します。
kubectl apply -k arc_data_services/test/launcher/overlays/aks
kubectl wait --for=condition=Ready --timeout=360s pod -l job-name=arc-ci-launcher -n arc-ci-launcher
kubectl logs job/arc-ci-launcher -n arc-ci-launcher --follow
この時点で、ランチャーが起動し、次の情報が表示されます。
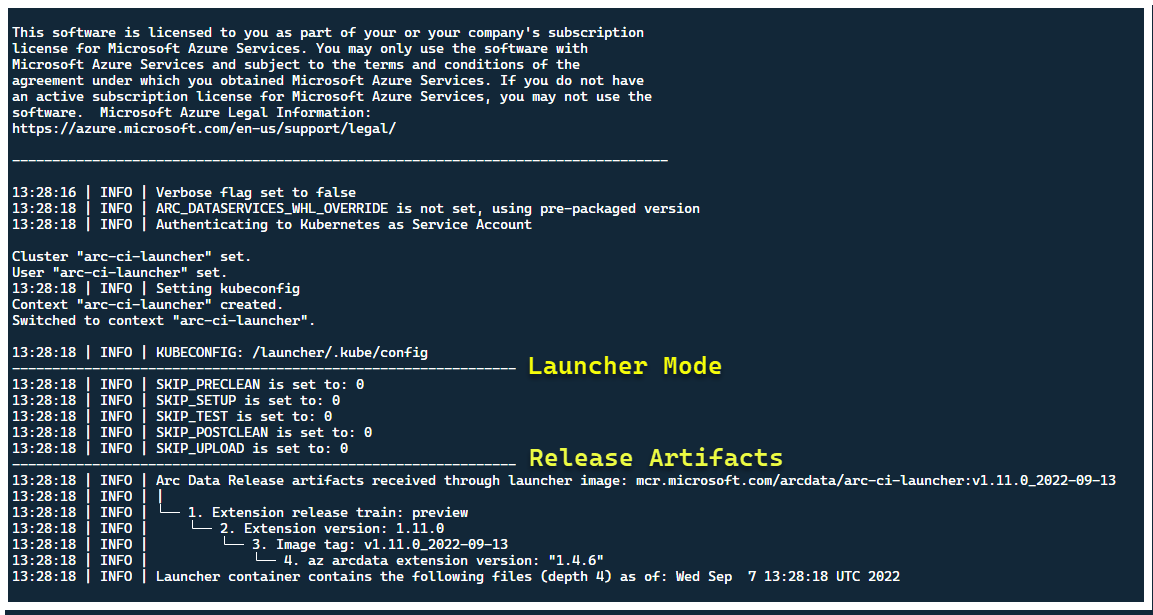
ランチャーは、既存の Arc リソースがないクラスターに配置することをお勧めしますが、ランチャーには、既存の Arc および Arc Data Services の CRD と ARM リソースを検出するための事前検証が含まれており、新しいリリースをデプロイする前に、ベスト エフォート ベースでクリーンアップを試みます (提供されたサービス プリンシパル資格情報を使用)。
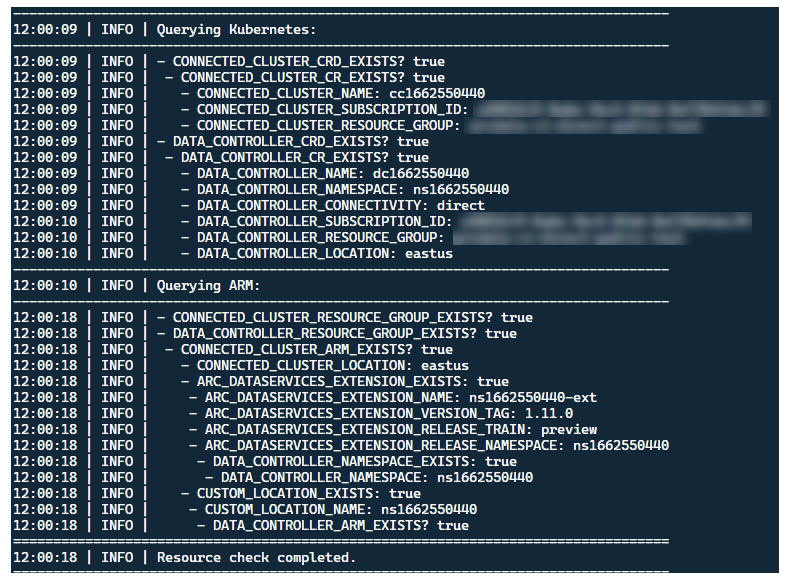
起動前にクラスターをできるだけ既存の状態に近づけるために、この同じメタデータ検出とクリーンアップ プロセスは、ランチャーの終了時にも実行されます。
ランチャーによって実行される手順
大まかに、ランチャーでは次の一連の手順が実行されます。
ポッド マウントされたサービス アカウントを使用して Kubernetes API に対する認証を行う
シークレット マウントされたサービス プリンシパルを使用して ARM API に対する認証を行う
CRD メタデータ スキャンを実行して既存の Arc および Arc Data Services カスタム リソースを検出する
Kubernetes の既存のカスタム リソースと、Azure 内の後続のリソースをクリーンアップする。 クラスター内に存在するリソースと比較して
.test.envの資格情報が一致しない場合は、終了します。Arc クラスター名、データ コントローラー、カスタムの場所または名前空間のタイムスタンプに基づいて、一意の環境変数セットを生成します。 環境変数を出力し、機密性の高い値 (サービス プリンシパル パスワードなど) を難読化します。
a. 直接モードの場合 - クラスターを Azure Arc にオンボードし、コントローラーをデプロイする。
b. 間接モードの場合: データ コントローラーをデプロイする
データ コントローラーが
Readyになったら、一連の Azure CLI (az arcdata dc debug) ログを生成し、ベースラインとして、setup-completeとラベル付けしてローカルに格納します。.test.envのTESTS_DIRECT/INDIRECT環境変数を使用して、スペース区切りの配列 (TESTS_(IN)DIRECT) に基づいて並列化された Sonobuoy テスト実行のセットを起動します。 これらの実行は、Pytest 検証テストを含むarc-sb-pluginポッドを使用して、新しいsonobuoy名前空間で実行されます。Sonobuoy アグリゲーターによって、
arc-sb-pluginテスト実行ごとにjunitテスト結果とログが蓄積され、ランチャー ポッドにエクスポートされます。テストの終了コードを返し、別のデバッグ ログのセットを生成し (Azure CLI と
sonobuoy)、test-completeとしてラベル付けしてローカルに格納します。手順 3 と類似の CRD メタデータ スキャンを実行して既存の Arc および Arc Data Services カスタム リソースを検出します。 次に、すべての Arc および Arc データ リソースをデプロイと逆の順序で破棄し、CRD、Role または ClusterRoles、PV または PVC なども破棄します。
指定された SAS トークン
LOGS_STORAGE_ACCOUNT_SASを使用して、LOGS_STORAGE_CONTAINERに基づいて名前が付けられた新しいストレージ アカウントコンテナーを既存のストレージ アカウントLOGS_STORAGE_ACCOUNTに作成しようと試みます。 ストレージ アカウント コンテナーが既に存在する場合は、それを使用します。 すべてのローカル テスト結果とログを tarball としてこのストレージ コンテナーにアップロードします (以下を参照)。終了します。
テスト スイートごとに実行されるテスト
27 のテスト スイートで、それぞれ個別の機能をテストする、約 375 個の固有の統合テストを利用できます。
| スイート番号 | テスト スイート名 | テストの説明 |
|---|---|---|
| 1 | ad-connector |
Active Directory コネクタ (AD コネクタ) のデプロイと更新をテストします。 |
| 2 | billing |
さまざまな Business Critical ライセンスの種類のテストは、課金のアップロードに使用されるコントローラーのリソース テーブルに反映されます。 |
| 3 | ci-billing |
billing と似ていますが、CPU またはメモリの組み合わせが多くなります。 |
| 4 | ci-sqlinstance |
マルチレプリカの作成、更新、GP -> BC の更新、バックアップ検証、SQL Server エージェントの長期テスト。 |
| 5 | controldb |
テスト コントロール データベース - SQL ビルド バージョンの SA シークレット チェック、システム ログイン検証、監査の作成、サニティ チェック。 |
| 6 | dc-export |
間接モードの課金と使用状況のアップロード。 |
| 7 | direct-crud |
ARM 呼び出しを使用して SQL インスタンスを作成し、Kubernetes と ARM の両方で検証します。 |
| 8 | direct-fog |
複数の SQL インスタンスを作成し、ARM 呼び出しを使用してそれらの間にフェールオーバー グループを作成します。 |
| 9 | direct-hydration |
Kubernetes API を使用して SQL インスタンスを作成し、ARM でのプレゼンスを検証します。 |
| 10 | direct-upload |
ダイレクト モードでの課金のアップロードを検証する |
| 11 | kube-rbac |
Arc Data Services に対する Kubernetes Service アカウントのアクセス許可が、最小特権の期待値と一致することを確認します。 |
| 12 | nonroot |
コンテナーが非ルート ユーザーとして実行されるようにする |
| 13 | postgres |
さまざまな Postgres の作成、スケーリング、バックアップまたは復元テストを完了します。 |
| 14 | release-sanitychecks |
SQL Server ビルド バージョンなど、月単位のリリースを確認するサニティ チェック。 |
| 15 | sqlinstance |
迅速な検証用の ci-sqlinstance の短いバージョン。 |
| 16 | sqlinstance-ad |
Active Directory コネクタを使用した SQL インスタンスの作成をテストします。 |
| 17 | sqlinstance-credentialrotation |
General Purpose と Business Critical の両方について、自動資格情報ローテーションをテストします。 |
| 18 | sqlinstance-ha |
ポッドの再起動、強制フェールオーバー、中断など、さまざまな高可用性ストレス テスト。 |
| 19 | sqlinstance-tde |
さまざまな Transparent Data Encryption (TDE) テスト。 |
| 20 | telemetry-elasticsearch |
Elasticsearch へのログ インジェストを検証します。 |
| 21 | telemetry-grafana |
Grafana に到達可能であることを検証します。 |
| 22 | telemetry-influxdb |
InfluxDB へのメトリック インジェストを検証します。 |
| 23 | telemetry-kafka |
SSL、シングルまたはマルチブローカーのセットアップを使用した Kafka のさまざまなテスト。 |
| 24 | telemetry-monitorstack |
Fluentbit や Collectd などの監視コンポーネントが機能していることをテストします。 |
| 25 | telemetry-telemetryrouter |
Open Telemetry をテストします。 |
| 26 | telemetry-webhook |
有効および無効な呼び出しで Data Services Webhook をテストします。 |
| 27 | upgrade-arcdata |
SQL インスタンスの完全なスイート (GP、BC 2 レプリカ、BC 3 レプリカ、Active Directory を使用) をアップグレードし、先月のリリースから最新のビルドにアップグレードします。 |
例として、sqlinstance-ha に次のテストが実行されます。
test_critical_configmaps_present: SQL インスタンスに ConfigMaps と関連フィールドが存在することを確認します。test_suspended_system_dbs_auto_heal_by_orchestrator:masterとmsdbが何らかの方法で中断されているかどうかを確認します (この場合はユーザー)。 Orchestrator メンテナンス調整で自動修復されます。test_suspended_user_db_does_not_auto_heal_by_orchestrator: ユーザー データベースがユーザーによって意図的に中断された場合、Orchestrator メンテナンス調整によって自動的に修復されないようにします。test_delete_active_orchestrator_twice_and_delete_primary_pod: オーケストレーター ポッドを複数回削除し、その後にプライマリ レプリカを削除し、すべてのレプリカが同期されていることを確認します。 2 つのレプリカに対するフェールオーバー時間の予想が緩和されています。test_delete_primary_pod: プライマリ レプリカを削除し、すべてのレプリカが同期されていることを確認します。 2 つのレプリカに対するフェールオーバー時間の予想が緩和されています。test_delete_primary_and_orchestrator_pod: プライマリ レプリカとオーケストレーター ポッドを削除し、すべてのレプリカが同期されていることを確認します。test_delete_primary_and_controller: プライマリ レプリカとデータ コントローラー ポッドを削除し、プライマリ エンドポイントにアクセスでき、新しいプライマリ レプリカが同期されていることを確認します。 2 つのレプリカに対するフェールオーバー時間の予想が緩和されています。test_delete_one_secondary_pod: セカンダリ レプリカとデータ コントローラー ポッドを削除し、すべてのレプリカが同期されていることを確認します。test_delete_two_secondaries_pods: セカンダリ レプリカとデータ コントローラー ポッドを削除し、すべてのレプリカが同期されていることを確認します。test_delete_controller_orchestrator_secondary_replica_pods:test_failaway: AG フェールオーバーを現在のプライマリから強制的に解除し、新しいプライマリが古いプライマリと同じではないことを確認します。 すべてのレプリカが同期されていることを確認します。test_update_while_rebooting_all_non_primary_replicas: テスト コントローラー駆動型の更新は、さまざまな混乱した状況にもかかわらず、再試行による回復性があります。
注意
特定のテストでは、アカウントと DNS エントリの作成の ad テスト用のドメイン コントローラーへの特権アクセスなど、特定のハードウェアが必要になる場合があります。これは、arc-ci-launcher を使用しようとしているすべての環境では使用できない場合があります。
テスト結果の確認
ランチャーによってアップロードされたサンプル ストレージ コンテナーとファイル:
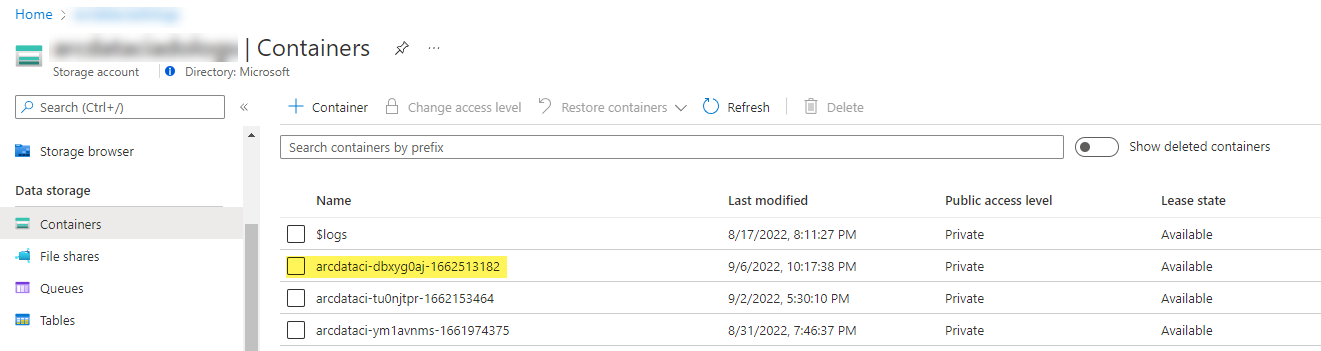
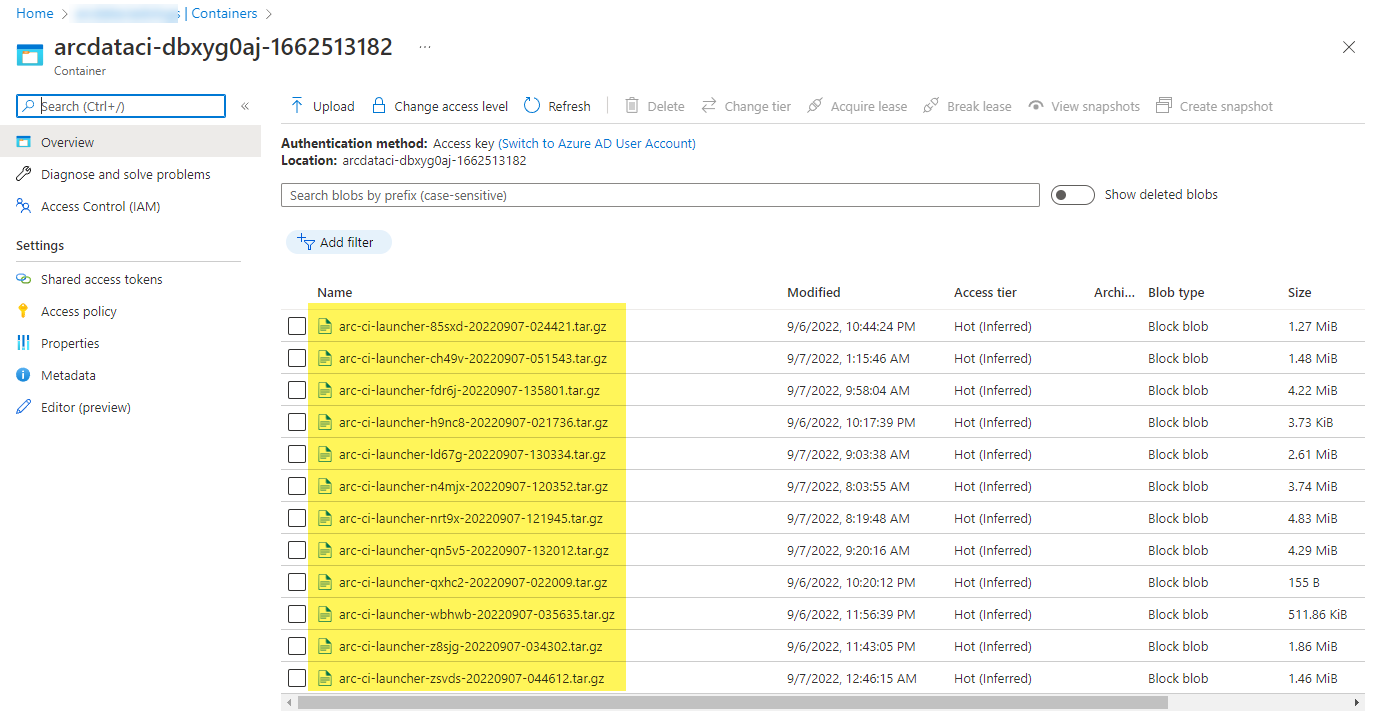
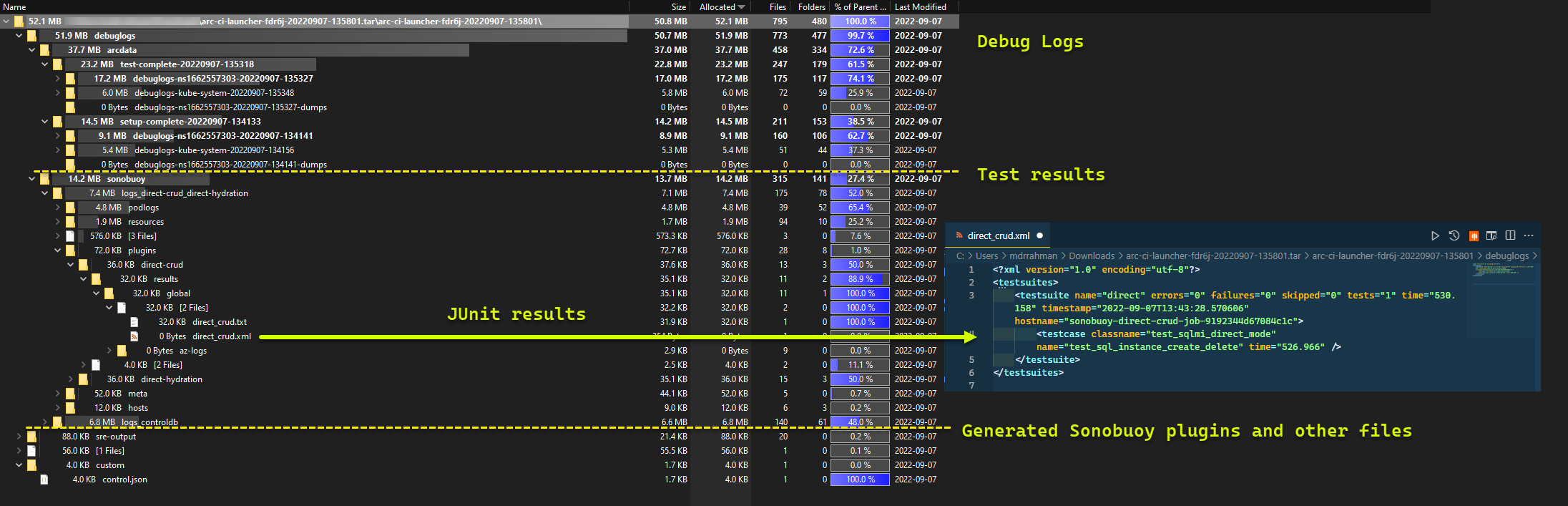
および実行から生成されたテスト結果:
リソースをクリーンアップする
ランチャーを削除するには、次のコマンドを実行します。
kubectl delete -k arc_data_services/test/launcher/overlays/aks
これにより、ランチャーの一部としてデプロイされたリソース マニフェストがクリーンアップされます。