Azure NetApp Files のボリューム言語について
Azure NetApp Files ボリューム上のボリューム言語 (クライアント オペレーティング システムのシステム ロケールに似ています) は、NFS および SMB プロトコルを使用する際にサポートされる言語と文字セットを制御します。 Azure NetApp Files は、既定のボリューム言語として C.UTF-8 を使用します。これにより、文字セットに POSIX 準拠の UTF-8 エンコードが提供されます。 C.UTF-8 言語は、0 から 3 バイトのサイズの文字をネイティブでサポートします。これには、基本多言語面 (BMP) 上の世界の言語の大部分 (日本語、ドイツ語、ほとんどのヘブライ語とキリル文字を含む) が含まれています。 BMP の詳細については、「Unicode」を参照してください。
BMP の外部にある文字は、Azure NetApp Files でサポートされる 3 バイトのサイズを超える場合があります。 したがって、複数の文字バイト セットを組み合わせて新しい文字を形成するサロゲート ペア ロジックを使用する必要があります。 たとえば、絵文字記号はこのカテゴリに分類され、UTF-8 が適用されないシナリオ (UTF-16 エンコード、または UTF-8 が適用されない NFSv3 を使用する Windows クライアントなど) での Azure NetApp Files でサポートされます。 NFSv4.x では UTF-8 が適用されます。つまり、NFSv4.x を使用する場合、サロゲート ペア文字は正しく表示されません。
Azure NetApp Files で UTF-8 が適用されている場合、Shift-JIS やあまり一般的ではない CJK 文字などの非標準エンコードも正しく表示されません。
ヒント
文字が適切に変換できない状況 (これにより、ファイルの作成や名前変更またはコピー エラーのシナリオが発生する可能性があります) を回避するために、UTF-8 を使用してテキストを送受信する必要があります。
現在、Azure NetApp Files ではボリューム言語設定を変更できません。 詳細については、「特殊文字セットでのプロトコルの動作」を参照してください。
ベスト プラクティスについては、「文字セットのベスト プラクティス」を参照してください。
Azure NetApp Files の NFS および SMB ボリュームでの文字エンコード
Azure NetApp Files ファイル共有環境では、ファイルおよびフォルダーの名前は一連の文字で表され、エンドユーザーはこれを読み取って解釈します。 これらの文字の表示方法は、クライアントでこれらの文字のエンコードを送受信する方法によって異なります。 たとえば、クライアントが Azure NetApp Files ボリュームにアクセスするときにレガシ American Standard Code for Information Interchange (ASCII) エンコードを送信している場合、ASCII 形式でサポートされている文字のみの表示に制限されます。
たとえば、データの日本語文字は資です。 この文字を ASCII で表すことはできないため、ASCII エンコードを使用するクライアントでは、 資の代わりに "?" が表示されます。
ASCII では、95 の印刷可能文字のみがサポートされ、これらは主に英語に見られる文字です。 これらの文字はそれぞれ 1 バイトを使用します。これは、Azure NetApp Files ボリュームのファイル パスの合計長の計算に組み入れられます。 ファイル名には、日本語からキリル文字や絵文字まで、ASCII で認識されないさまざまな文字が含まれる可能性があるため、これにより、データセットの国際化が制限されます。 国際標準 (ISO/IEC 8859) は、より多くの国際文字をサポートしようとしましたが、限界もありました。 最新のクライアントのほとんどは、何らかの形式の Unicode を使用して文字を送受信します。
Unicode
ASCII および ISO/IEC 8859 エンコードには制限があるため、誰もが自分のデバイスからホーム リージョンの言語を表示できるように Unicode 標準が確立されました。
- Unicode では、ASCII などの古いエンコードとは対照的に、許可されている 1 文字あたりのバイト数 (最大 4 バイト) とファイル パスで許可されている合計バイト数の両方を増やして、100 万を超える文字セットがサポートされています。
- Unicode では、最初の 128 文字を ASCII 用に予約して下位互換性をサポートし、同時に最初の 256 コード ポイントが ISO/IEC 8859 標準と同一であることも保証します。
- Unicode 標準では、文字セットが平面に分割されます。 平面は、連続する 65,536 個のコード ポイントのグループです。 Unicode 標準には、合計で 17 個 (0 から 16) の平面があります。 UTF-16 の制限のために、17 に制限されます。
- 平面 0 は、基本多言語面 (BMP) です。 この平面には、複数の言語で最も一般的に使用される文字が含まれています。
- 現在、Unicode バージョン 15.1 の時点で、文字セットが割り当てられているのは、17 の平面のうち 5 つのみです。
- 平面 1 から 17 は、補助多言語面 (SMP) と呼ばれており、楔形文字や象形文字などの古代の書記体系や特殊な中国語/日本語/韓国語 (CJK) 文字など、使用頻度の低い文字セットが含まれています。
- 文字の長さとパスのサイズを表示する方法、およびシステムに送信されるエンコードを制御する方法については、「さまざまなエンコードへのファイルの変換」を参照してください。
Unicode では、Unicode 変換形式 が標準として使用され、UTF-8 と UTF-16 が 2 つの主要な形式です。
Unicode 平面
Unicode は、平面 0 を基本多言語面 (BMP) として、65,536 文字 (平面内の 256 のコード ポイントと 256 のボックスを掛けた数) の 17 個の平面を利用します。 この平面には、複数の言語で最も一般的に使用される文字が含まれています。 世界の言語と文字セットは 65536 文字を超えるため、一般的に使用頻度の低い文字セットをサポートするには、より多くの平面が必要です。
たとえば、平面 1 (補助多言語面 (SMP)) には、楔形文字やエジプト象形文字などの歴史的文字のほか、オーセージ、ワラング クシティ、アドラム、ワンチョ、トトなども含まれています。 平面 1 には、いくつかの記号と絵文字も含まれています。
平面 2 (補助漢字面 (SIP)) には、中国語/日本語/韓国語 (CJK) 統合漢字が含まれています。 平面 1 および 2 の文字のサイズは、通常、4 バイトです。
次に例を示します。
- 平面 1 の "大きな目の笑っている顔" の絵文字 "😃" のサイズは 4 バイトです。
- 平面 1 のエジプト象形文字 "𓀀" のサイズは、4 バイトです。
- 平面 1 のオーセージ文字 "𐒸" のサイズは、4 バイトです。
- 平面 2 の CJK 文字 "𫝁" のサイズは、4 バイトです。
これらの文字はすべてサイズが 3 バイトを超えるため、適切に動作するには、サロゲート ペアを使用する必要があります。 Azure NetApp Files では、サロゲート ペアがネイティブでサポートされますが、文字の表示は、使用するプロトコル、クライアントのロケール設定、リモート クライアント アクセス アプリケーションの設定によって異なります。
UTF-8
UTF-8 は 8 ビット エンコードを使用し、最大 1,112,064 個のコード ポイント (または文字) を含めることができます。 UTF-8 は、Linux ベースのオペレーティング システムのすべての言語にわたる標準エンコードです。 UTF-8 は 8 ビット エンコードを使用するため、使用できる符号なし整数の最大値は 255 (2^8 – 1) です。これは、そのエンコードのファイル名の最大長でもあります。 UTF-8 はインターネット上の 98% 以上のページで使用されており、圧倒的に最も多く採用されているエンコード標準です。 Web Hypertext Application Technology Working Group (WHATWG) は、UTF-8 を "すべての [テキスト] に必須のエンコード" と見なし、セキュリティ上の理由からブラウザー アプリケーションでは UTF-16 を使用すべきではないと考えています。
UTF-8 形式の文字はそれぞれ 1 から 4 バイトを使用しますが、すべての言語のほぼすべての文字は 1 から 3 バイトを使用します。 次に例を示します。
- ラテン アルファベット文字 "A" (128 個の予約済み ASCII 文字の 1 つ) は 1 バイトを使用します。
- 著作権記号 "©" は 2 バイトを使用します。
- 文字 "ä" は 2 バイト ("a" に 1 バイトとウムラウトに 1 バイト) を使用します。
- データの日本語漢字記号 (資) は 3 バイトを使用します。
- 笑っている顔の絵文字 (😃) は 4 バイトを使用します。
言語ロケールでは、コンピューター標準の UTF-8 (C.UTF-8)、またはよりリージョン固有の形式 (en_US.UTF-8、ja.UTF-8 など) のいずれかを使用できます。Azure NetApp Files にアクセスする場合は可能な限り、Linux クライアントに UTF-8 エンコードを使用する必要があります。 OS X 以降、macOS クライアントでも既定のエンコードに UTF-8 が使用されるようになったため、調整する必要はありません。
Windows クライアントは UTF-16 を使用します。 ほとんどの場合、この設定は OS ロケールの既定値のままにしておく必要がありますが、新しいクライアントでは、チェックボックスを介して UTF-8 文字のベータ サポートが提供されます。 Windows のターミナル クライアントは、必要に応じて PowerShell または CMD で UTF-8 を使用するように調整することもできます。 詳細については、特殊文字セットでのデュアル プロトコルの動作に関するセクションを参照してください。
UTF-16
UTF-16 は 16 ビット エンコードを使用し、Unicode の 1,112,064 個のすべてのコード ポイントをエンコードできます。 UTF-16 のエンコードでは、それぞれ 2 バイトのサイズの 1 つまたは 2 つの 16 ビット コード単位を使用できます。 UTF-16 のすべての文字は 2 バイトまたは 4 バイトのサイズを使用します。 4 バイトを使用する UTF-16 の文字は、2 つの別々の 2 バイト文字を組み合わせて新しい文字を作成するサロゲート ペアを利用します。 これらの補助文字は、標準の BMP 平面の外部にあり、他の多言語平面のいずれかに分類されます。
UTF-16 は、Windows オペレーティング システムと、API、Java、JavaScript で使用されます。 ASCII 形式との下位互換性がサポートされていないため、Web 上で普及することはありませんでした。 インターネット上で UTF-16 が占める割合は、全ページの約 0.002% にすぎません。 Web Hypertext Application Technology Working Group (WHATWG) は、UTF-8 を "すべてのテキストに必須のエンコード" と見なし、ブラウザーのセキュリティ上、アプリケーションでは UTF-16 を使用しないことを推奨しています。
Azure NetApp Files では、サロゲート ペアを含め、ほとんどの UTF-16 文字がサポートされています。 文字がサポートされていない場合、Windows クライアントは、"指定したファイル名が無効であるか長すぎます" というエラーを報告します。
リモート クライアント上での文字セットの処理
Azure NetApp Files ボリュームをマウントするクライアントへのリモート接続 (NFS マウントにアクセスするための Linux クライアントへの SSH 接続など) は、特定のボリューム言語エンコードを送受信するように構成できます。 リモート接続ユーティリティを介してクライアントに送信される言語エンコードは、文字セットの作成方法と表示方法を制御します。 その結果、別のリモート接続とは異なる言語エンコードを使用するリモート接続 (2 つの異なる PuTTY ウィンドウなど) では、Azure NetApp Files ボリューム内のファイル名とフォルダー名を一覧表示するときに、文字について異なる結果が表示される可能性があります。 ほとんどの場合、これによって不一致 (ラテン語と英語の文字など) が生じることはありませんが、絵文字などの特殊文字の場合、結果が異なる場合があります。
たとえば、C.UTF-8 がボリューム言語であるため、リモート接続に UTF-8 のエンコードを使用すると、Azure NetApp Files ボリューム内の文字に対して予測可能な結果が表示されます。 "データ" の日本語文字 (資) の表示は、端末から送信されるエンコードによって異なります。
PuTTY での文字エンコード
PuTTY ウィンドウで UTF-8 (Windows の変換設定内にあります) を使用すると、文字は Azure NetApp Files の NFSv3 マウント ボリュームに対して適切に表されます。
![[PuTTY の再構成] ウィンドウのスクリーンショット。](media/understand-volume-languages/putty-utf-8.png#lightbox)
PuTTY ウィンドウで ISO-8859-1:1998 (Latin-1、西ヨーロッパ) などの異なるエンコードが使用されている場合、ファイル名が同じであっても、同じ文字が異なって表示されます。

既定では、PuTTY に CJK エンコードは含まれません。 これらの言語セットを PuTTY に追加するために使用できるパッチがあります。
Bastion での文字エンコード
Microsoft Azure では、Azure の仮想マシン (VM) へのリモート接続に Bastion を使用することを推奨しています。 Bastion を使用する場合、送受信される言語エンコードは構成で公開されませんが、標準の UTF-8 エンコードを利用します。 その結果、UTF-8 を使用する PuTTY で表示されるほとんどの文字セットは、使用されているプロトコルで文字セットがサポートされていれば、Bastion でも表示されるはずです。

ヒント
TeraTerm などの他の SSH ターミナルを使用できます。 TeraTerm は、CJK エンコードや Shift-JIS などの非標準エンコードを含め、幅広い範囲の文字セットを既定でサポートします。
特殊文字セットでのプロトコルの動作
Azure NetApp Files ボリュームは UTF-8 エンコードを使用し、3 バイトを超えない文字をネイティブでサポートします。 ASCII および UTF-8 セット内のすべての文字は、1 から 3 バイトの範囲に収まるため、正しく表示されます。 次に例を示します。
- ラテン アルファベット文字 "A" (128 個の予約済み ASCII 文字の 1 つ) は 1 バイトを使用します。
- 著作権記号 © は 2 バイトを使用します。
- 文字 "ä" は 2 バイト ("a" に 1 バイトとウムラウトに 1 バイト) を使用します。
- データの日本語漢字記号 (資) は 3 バイトを使用します。
Azure NetApp Files では、クライアントのエンコードとプロトコル バージョンでサポートされている場合、サロゲート ペア ロジックを使用して 3 バイトを超える一部の文字 (絵文字など) もサポートされます。 プロトコルの動作の詳細については、次のセクションを参照してください。
SMB の動作
SMB ボリュームでは、Azure NetApp Files は、SMB クライアントからアクセスできるディレクトリ内のファイルまたはディレクトリに対して 2 つの名前 (元の長い名前と 8.3 形式の名前) を作成して保持します。
Azure NetApp Files での SMB のファイル名
ファイル名またはディレクトリ名が許可されている文字バイト数を超えているか、サポートされていない文字を使用している場合、Azure NetApp Files は次のように 8.3 形式の名前を生成します。
- 元のファイルまたはディレクトリの名前を切り詰めます。
- 切り詰められた後に一意でなくなったファイル名またはディレクトリ名にチルダ (~) と数字 (1 から 5) を追加します。 一意でない名前を持つファイルが 5 つ以上ある場合、Azure NetApp Files は元の名前とは関係のない一意の名前を作成します。 ファイルの場合、Azure NetApp Files では、ファイル名拡張子が 3 文字に切り詰められます。
たとえば、NFS クライアントで、specifications.html という名前のファイルが作成されると、Azure NetApp Files では、8.3 形式に従ってファイル名 specif~1.htm が作成されます。 その名前が既に存在する場合、Azure NetApp Files はファイル名の末尾に別の番号を使用します。 たとえば、この後、NFS クライアントで specifications\_new.html という名前の別のファイルが作成されると、specifications\_new.html の 8.3 形式は specif~2.htm となります。
Azure NetApp Files での SMB の特殊文字
Azure NetApp Files ボリュームで SMB を使用する場合、サロゲート ペアがサポートされるため、ファイルおよびフォルダーの名前に 3 バイトを超える文字 (絵文字を含む) を使用できます。 既定の UTF-16 エンコードで英語を使用する場合に、Windows クライアントから作成されたフォルダーに含まれる BMP 外部の文字が Windows Explorer でどのように表示されるかを次に示します。
Note
Windows Explorer の既定のフォントは、Segoe UI です。 フォントを変更すると、一部の文字のクライアントでの表示方法に影響を与える可能性があります。

クライアントでの文字の表示方法は、システム フォントと、言語およびロケールの設定によって異なります。 一般に、BMP に分類される文字は、エンコードが UTF-8 または UTF-16 のいずれであるかに関係なく、すべてのプロトコルでサポートされます。
CMD または PowerShell のいずれかを使用する場合、文字セットの表示は、フォントの設定によって異なることがあります。 これらのユーティリティでは、既定で、フォントの選択肢が制限されています。 CMD では、既定のフォントとして Consolas を使用します。
一部のコンソールでは、Segoe UI や、特殊文字を適切にレンダリングするその他のフォントがネイティブにサポートされていないため、使用されるフォントによってはファイル名が期待どおりに表示されない場合があります。
この問題は、より堅牢なフォント サポートを提供する PowerShell ISE を使用すると、Windows クライアントで解決できます。 たとえば、PowerShell ISE を Segoe UI に設定すると、サポートされている文字を含むファイル名が適切に表示されます。

ただし、PowerShell ISE は、共有の管理用ではなく、スクリプト用に設計されています。 新しい Windows バージョンでは、フォントとエンコード値の制御に使用できる Windows ターミナルが提供されます。
Note
chcp コマンドを使用して、ターミナルのエンコードを表示します。 コード ページの完全な一覧については、「コード ページ識別子」を参照してください。

デュアル プロトコル (NFS と SMB の両方) に対してボリュームが有効になっている場合、動作が異なる可能性があります。 詳細については、特殊文字セットでのデュアル プロトコルの動作に関するセクションを参照してください。
NFS の動作
NFS が特殊文字をどのように表示するかは、使用する NFS のバージョン、クライアントのロケール設定、インストールされているフォント、使用中のリモート接続クライアントの設定によって異なります。 たとえば、Bastion を使用して Ubuntu クライアントにアクセスすると、同じ VM 上の異なるロケールに設定された PuTTY クライアントとは異なる方法で文字表示が処理されます。 以降の NFS の例は、Ubuntu VM の次のロケール設定に依存します。
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3 の動作
NFSv3 では、ファイルやフォルダーに UTF エンコードは適用されません。 ほとんどの場合、特殊文字セットに問題はありません。 ただし、使用されている接続クライアントは、文字の送受信方法に影響を与える可能性があります。 たとえば、Azure 接続クライアント Bastion のフォルダー名に、BMP の外部にある Unicode 文字を使用すると、クライアントのエンコードのしくみが原因で予期しない動作が発生する可能性があります。
次のスクリーンショットでは、Bastion は、NFSv3 でディレクトリに名前を付けるときに、ブラウザーの外部から CLI プロンプトに値をコピーして貼り付けることができません。 NFSv3Bastion𓀀𫝁😃𐒸 の値をコピーして貼り付けようとすると、入力内で特殊文字が引用符として表示されます。

コピー/貼り付けコマンドは NFSv3 で許可されますが、文字は数値として作成されるため、表示に影響します。
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
この表示は、コピーして貼り付けるときにテキスト値を送信するために Bastion で使用されるエンコードによるものです。
PuTTY を使用して、NFSv3 で同じ文字を含むフォルダーを作成する場合、Bastion を使用してフォルダーを作成したときとフォルダー名が異なります。 絵文字は、(インストールされているフォントとロケール設定により) 期待どおりに表示されますが、その他の文字 (オーセージの "𐒸" など) は表示されません。

PuTTY ウィンドウからは、文字が正しく表示されます。

NFSv4.x の動作
NFSv4.x では、RFC-8881 国際化仕様に従って、ファイル名とフォルダー名に UTF-8 エンコードが適用されます。
その結果、特殊文字が UTF-8 以外のエンコードで送信された場合、NFSv4.x ではその値が許可されない可能性があります。
場合によっては、基本多言語面 (BMP) の外部にある文字を使用したコマンドが許可される可能性がありますが、作成後に値が表示されない可能性があります。
たとえば、文字 "𓀀𫝁😃𐒸" (補助多言語面 (SMP) と補助漢字面 (SIP) の文字) を含むフォルダー名で mkdir を発行すると、NFSv4.x では成功するように見えます。 ls コマンドを実行すると、フォルダーは表示されません。
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
フォルダーはボリューム内に存在しています。 その非表示ディレクトリ名への変更は PuTTY クライアントから行われ、そのディレクトリ内にファイルを作成できます。
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
PuTTY の stat コマンドは、フォルダーが存在していることも確認します。
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
フォルダーの存在が確認されても、クライアントは正式には表示内でフォルダーを "見る" ことができないため、ワイルドカード コマンドは機能しません。
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 は、UTF-8 エンコードに依存しない文字を検出すると、クライアントにエラーを送信します。
たとえば、NFSv4.1 で PuTTY を使用して作成したのと同じディレクトリに、Bastion を使用してアクセスしようとすると、結果は次のようになります。
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL は、RFC-8881 で説明されています。
このフォルダーには PuTTY からアクセスできるので (エンコードが送受信されるため)、名前を指定すればコピーできます。 そのフォルダーを NFSv4.1 Azure NetApp Files ボリュームから NFSv3 Azure NetApp Files ボリュームにコピーすると、フォルダー名が表示されます。
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Shift-JIS などの UTF-8 以外の形式にファイルを変換しようとした場合も (` iconv`` を使用)、同じ NFS4ERR\_INVAL エラーが発生することがあります。
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
詳細については、「さまざまなエンコードへのファイルの変換」を参照してください。
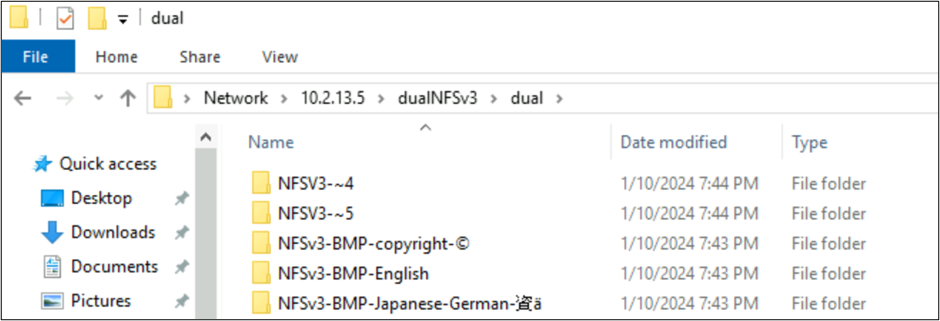
デュアル プロトコルの動作
Azure NetApp Files を使用すると、デュアル プロトコル アクセスを介して NFS と SMB の両方からボリュームにアクセスできます。 NFS (UTF-8) と SMB (UTF-16) で使用される言語エンコードには大きな違いがあるため、文字セット、ファイルとフォルダーの名前、パスの長さは、プロトコル間で動作が大きく異なる場合があります。
NFS で作成されたファイルとフォルダーを SMB から表示する
Azure NetApp Files をデュアル プロトコル アクセス (SMB および NFS) に使用する場合、UTF-16 でサポートされていない文字セットが、NFS 経由で UTF-8 を使用して作成されたファイル名に使用される可能性があります。 このようなシナリオでは、SMB でアクセスしたファイルにサポートされていない文字が含まれている場合、SMB では 8.3 の短いファイル名規則を使用して名前が切り詰められます。
NFSv3 で作成されたファイルと SMB の文字セットでの動作
NFSv3 では、UTF-8 エンコードは適用されません。 NFSv3 を使用する場合、非標準の言語エンコード (Shift-JIS など) を使用する文字は Azure NetApp Files で機能します。
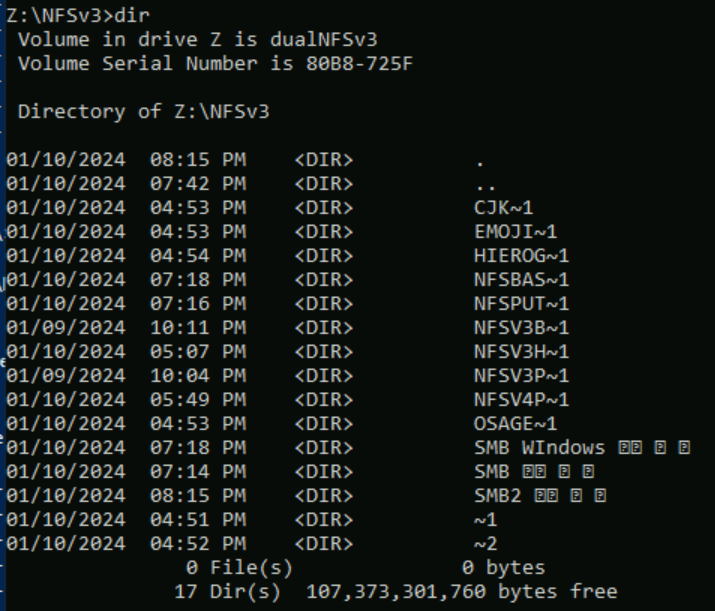
次の例では、Unicode のさまざまな平面の異なる文字セットを使用する一連のフォルダー名が、NFSv3 を使用して Azure NetApp Files ボリュームに作成されています。 NFSv3 から表示すると、これらは正しく表示されます。
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Windows SMB からは、BMP で見つかった文字を含むフォルダーは正しく表示されますが、その平面の外部にある文字は、UTF-8/UTF-16 変換にそれらの文字との互換性がないため、8.3 名前形式で表示されます。
NFSv4.1 で作成されたファイルと SMB の文字セットでの動作
前の例では、NFSv4 Putty 𓀀𫝁😃𐒸 という名前のフォルダーが NFSv4.1 の Azure NetApp Files ボリューム上に作成されましたが、NFSv4.1 を使用して表示することはできませんでした。 ただし、SMB を使用すると表示できます。 NFS クライアントから作成された文字セットがサポートされておらず、UTF-8/UTF-16 変換に、異なる Unicode 平面の文字との互換性がないため、SMB では、名前が、サポートされている 8.3 形式に切り詰められます。
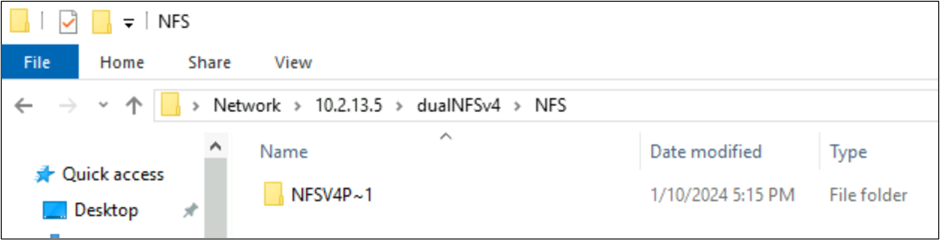
フォルダー名に BMP にある標準の UTF-8 文字 (英語など) が使用されている場合、SMB は名前を適切に変換します。
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
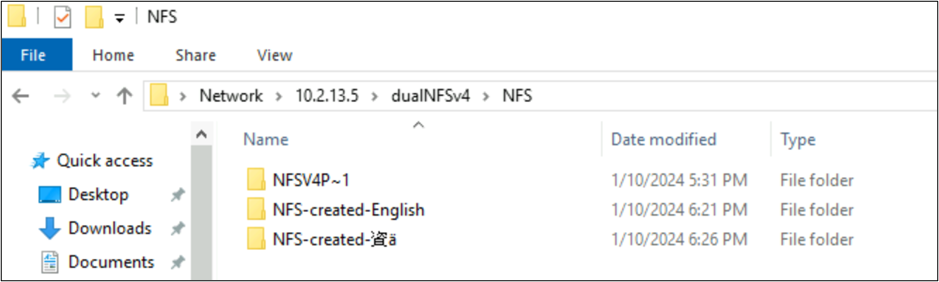
NFS 上の SMB で作成されたファイルとフォルダー
Windows クライアントは、SMB 共有へのアクセスに使用される主な種類のクライアントです。 これらのクライアントは、既定で UTF-16 エンコードを使用します。 一部の UTF-8 エンコード文字は、リージョン設定で有効にすると Windows でサポートできます。
![[リージョン設定] ウィンドウのスクリーンショット。](media/understand-volume-languages/region-settings.png)
ファイルまたはフォルダーを Azure NetApp Files の SMB 共有上に作成すると、文字セットは UTF-16 としてエンコードされます。 その結果、UTF-8 エンコードを使用するクライアント (Linux ベースの NFS クライアントなど) は、一部の文字セット、特に基本多言語面 (BMP) の外部にある文字を適切に変換できない場合があります。
サポートされていない文字の動作
このようなシナリオでは、SMB を使用して作成された、サポートされていない文字を含むファイルに NFS クライアントがアクセスすると、名前は、その文字の Unicode 値を表す一連の数値として表示されます。
たとえば、次のフォルダーは、BMP の外部にある文字を使用して Windows Explorer で作成されました。
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
NFSv3 で、SMB で作成されたフォルダーは、次のように表示されます。
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
NFSv4.1 で、SMB で作成されたフォルダーは、次のように表示されます。
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
サポートされている文字の動作
文字が BMP に含まれている場合、SMB プロトコルと NFS プロトコル、およびそれらのバージョンの間に問題はありません。
たとえば、複数の言語 (英語、ドイツ語、キリル語、ルーン文字) 間で、BMP で見つかった文字を含む Azure NetApp Files ボリューム上で SMB を使用して作成されたフォルダー名は、すべてのプロトコルとバージョン間で正常に表示されます。
SMB での名前の表示方法を次に示します。
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
NFSv3 からの名前の表示方法を次に示します。
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
NFSv4.1 からの名前の表示方法を次に示します。
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
さまざまなエンコードへのファイルの変換
ファイル システム オブジェクトで言語エンコードを使用する部分は、ファイルおよびフォルダーの名前だけではありません。 ファイルの内容 (テキスト ファイル内の特殊文字など) も関係する場合があります。 たとえば、互換性のない形式の特殊文字でファイルを保存しようとすると、エラー メッセージが表示される可能性があります。 次の場合、カタカナ文字は ANSI エンコードに存在しないため、これらの文字を含むファイルは ANSI で保存することはできません。
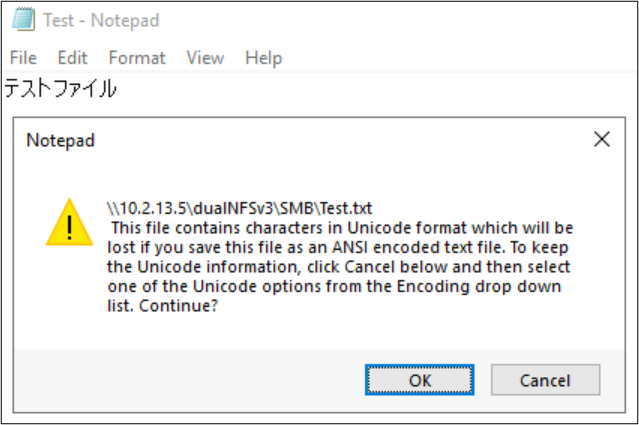
このファイルを ANSI 形式で保存すると、カタカナ文字は疑問符に変換されます。
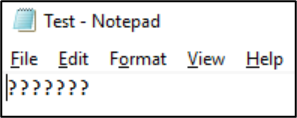
ファイルのエンコードは、NAS クライアントから表示できます。 Windows クライアントでは、メモ帳やメモ帳++ などのアプリケーションを使用して、ファイルのエンコードを表示できます。 Linux 用 Windows サブシステム (WSL) または Git がクライアントにインストールされている場合、file コマンドを使用できます。
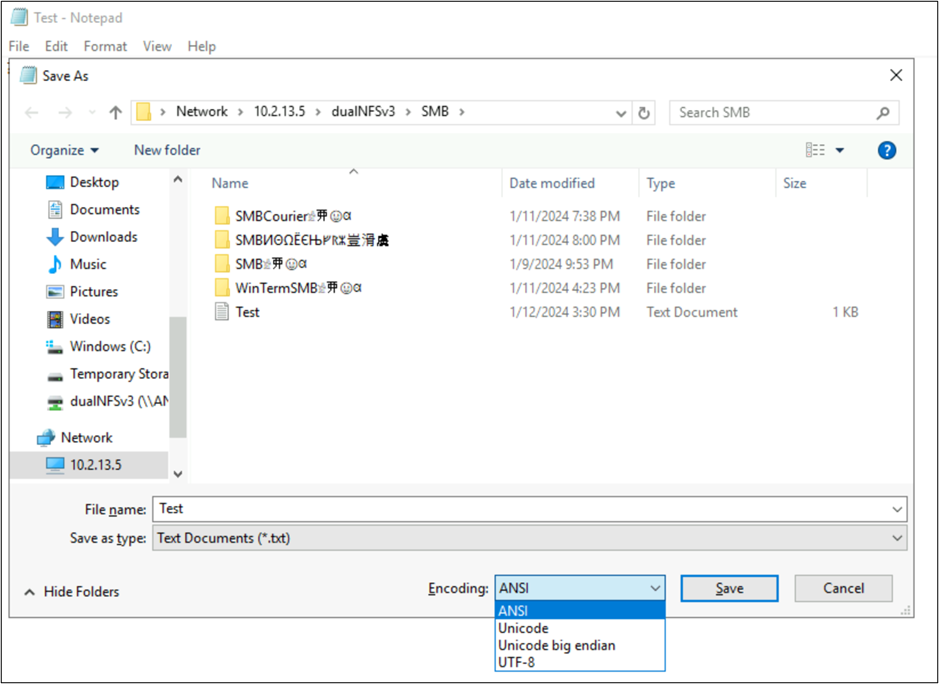
これらのアプリケーションでは、別の種類のエンコードとして保存すると、ファイルのエンコードを変更することもできます。 さらに、PowerShell を使用すると、Get-Content および Set-Content コマンドレットを使用してファイルのエンコードを変換できます。
たとえば、ファイル utf8-text.txt は UTF-8 としてエンコードされ、BMP の外部にある文字が含まれています。 UTF-8 が使用されているため、文字は正しく表示されます。
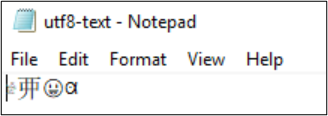
エンコードを UTF-32 に変換すると、文字は正しく表示されません。
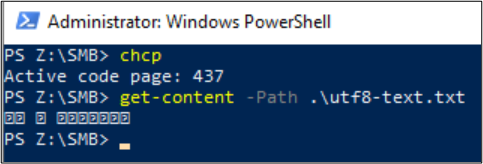
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt

Get-Content を使用して、ファイルの内容を表示することもできます。 PowerShell では既定で UTF-16 エンコード (コード ページ 437) が使用され、コンソールのフォントの選択が制限されるため、特殊文字を含む UTF-8 形式のファイルを正しく表示することはできません。
Linux クライアントでは、file コマンドを使用してファイルのエンコードを表示できます。 デュアルプロトコル環境では、SMB を使用してファイルが作成されている場合、NFS を使用する Linux クライアントでファイルのエンコードを確認できます。
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
Linux クライアントでは、iconv コマンドを使用してファイルのエンコードを変換できます。 サポートされているエンコード形式の一覧を表示するには、iconv -l を使用します。
たとえば、UTF-8 でエンコードされたファイルを UTF-16 に変換できます。
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
ファイル名またはファイルの内容の文字セットが、変換先のエンコードでサポートされていない場合、変換は許可されません。 たとえば、Shift-JIS では、ファイルの内容の文字をサポートできません。
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
ファイルにエンコードでサポートされている文字が含まれている場合、変換は成功します。 たとえば、ファイルにカタカナ文字 "テキストファイル" が含まれている場合、NFS での Shift-JIS 変換は成功します。 ここで使用されている NFS クライアントは、ロケール設定により Shift-JIS を理解していないため、エンコードは "unknown-8bit" と表示されます。
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Azure NetApp Files ボリュームでは UTF-8 互換の書式設定のみがサポートされているため、カタカナ文字は読み取り不可能な形式に変換されます。
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
NFSv4.x を使用する場合、NFSv4.x で UTF-8 エンコードが適用される場合でも、互換性のない文字がファイルの内容に存在する場合は変換が許可されます。 次の例では、Azure NetApp Files ボリューム上にあり、UTF-8 でエンコードされ、カタカナ文字を含むファイルの内容が適切に表示されます。
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
ただし、これを変換すると、ファイル内の文字は、エンコードに互換性がないために正しく表示されません。
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
ファイル名に、UTF-8 でサポートされていない文字が含まれている場合、プロトコル バージョンで UTF-8 が適用されるため、変換は、NFSv3 では成功しますが、NFSv4.x では失敗します。
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
文字セットのベスト プラクティス
Azure NetApp Files ボリュームで、特殊文字または標準の基本多言語面 (BMP) の外部にある文字を使用する場合は、次のベスト プラクティスを考慮する必要があります。
- Azure NetApp Files ボリュームでは、UTF-8 ボリューム言語が使用されるため、一貫性のある結果を得るために、NFS クライアントのファイル エンコードでも UTF-8 エンコードを使用する必要があります。
- ファイル名の文字セット、またはファイルの内容に含まれる文字セットは、適切な表示と機能のために UTF-8 互換である必要があります。
- SMB は UTF-16 文字エンコードを使用するため、デュアルプロトコル ボリュームの NFS では、BMP の外部にある文字が正しく表示されない可能性があります。 ファイルの内容での特殊文字の使用は、可能な限り最小限に抑えます。
- 特に NFSv4.1 またはデュアルプロトコル ボリュームを使用する場合、BMP の外部にある特殊文字をファイル名に使用しないようにします。
- 単一のファイル プロトコル (SMB のみまたは NFS のみ) を使用する場合、BMP にない文字セットについては、UTF-8 エンコードを使用して Azure NetApp Files で文字を表示できるようにする必要があります。 ただし、デュアルプロトコル ボリュームは、ほとんどの場合、これらの文字セットに対応できません。
- Azure NetApp Files ボリュームでは、非標準エンコード (Shift-JIS など) はサポートされていません。
- Azure NetApp Files ボリュームでは、サロゲート ペア文字 (絵文字など) がサポートされています。