読み取り専用レプリカを使用して読み取り専用クエリ ワークロードをオフロードする
適用対象: ![]() Azure SQL データベース
Azure SQL データベース ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
高可用性アーキテクチャの一部として、Premium と Business Critical のサービス レベルの各単一データベースまたはエラスティック プール データベースは、1 つのプライマリ読み取り/書き込みレプリカと 1 つ以上のセカンダリ読み取り専用レプリカを使って、自動的にプロビジョニングされます。 セカンダリ レプリカは、プライマリ レプリカと同じコンピューティング サイズでプロビジョニングされます。 "読み取りスケールアウト" 機能では、読み取り/書き込みレプリカ上で実行する代わりに、読み取り専用レプリカのいずれか 1 つのコンピューティング能力を使用して読み取り専用ワークロードをオフロードできます。 これにより、読み取り専用のワークロードを読み取り/書き込みワークロードから分離でき、パフォーマンスに影響が及ぶことがありません。 この機能は、分析などの論理的に分離された読み取り専用ワークロードを含むアプリケーション向けです。 Premium および Business Critical サービス レベルでは、余分なコストをかけることなく、この追加の処理能力を使用してパフォーマンス上のメリットをアプリケーションで得ることが可能です。
セカンダリ レプリカを少なくとも 1 つ追加していれば、Hyperscale サービス レベルでも読み取りスケールアウト機能を利用できます。 Hyperscale セカンダリ名前付きレプリカを使用すると、独立実行できるスケーリング、アクセスの分離、ワークロードの分離、さまざまな読み取りスケールアウト シナリオのサポート、その他のベネフィットが提供されます。 読み取り専用ワークロードのロードバランシングに、単一のセカンダリ HA レプリカで利用できる以上のリソースが必要な場合は、複数のセカンダリ HA レプリカを使用できます。
Basic、Standard、および General Purpose サービス レベルの高可用性アーキテクチャには、レプリカは一切含まれていません。 "読み取りスケールアウト" 機能は、これらのサービス レベルでは使用できません。 ただし、Azure SQL Database を使用するとき、geo レプリカからこれらのサービス レベルでも同様の機能を提供できます。 Azure SQL Managed Instance とフェールオーバー グループを使用するとき、フェールオーバー グループの読み取り専用リスナーからは、同様の機能をそれぞれ提供できます。
次の図に、Premium および Business Critical のデータベースとマネージド インスタンスの機能を図示します。
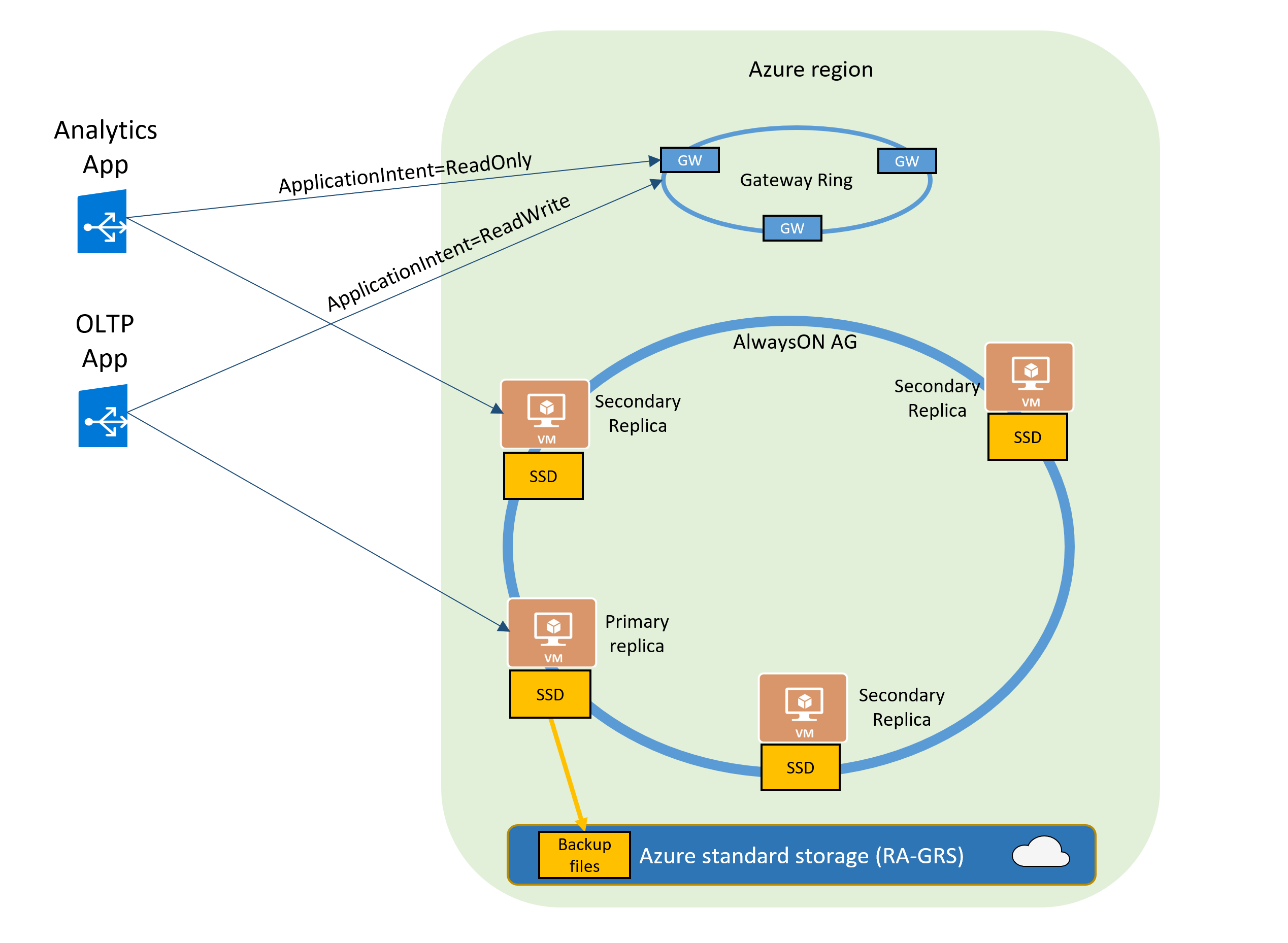
新しい Premium、Business Critical、および Hyperscale データベースでは、"読み取りスケールアウト" 機能は既定で有効になっています。
Note
Business Critical サービス レベルの SQL Managed Instance と、最低 1 つのセカンダリ レプリカが存在する Hyperscale データベースでは、読み取りスケールアウトが常に有効になっています。
お使いの SQL 接続文字列が ApplicationIntent=ReadOnly で構成されている場合、アプリケーションは、そのデータベースまたはマネージド インスタンスの読み取り専用レプリカにリダイレクトされます。 ApplicationIntent プロパティの使用方法の詳細については、「アプリケーションの目的を指定する」をご覧ください。
Azure SQL Database についてのみ、SQL 接続文字列の ApplicationIntent の設定に関係なく、アプリケーションがプライマリ レプリカに確実に接続されるようにする場合は、データベースを作成するとき、またはその構成を変更するときに、読み取りスケールアウトを明示的に無効にする必要があります。 たとえば、Standard または General Purpose レベルから Premium または Business Critical にデータベースをアップグレードして、すべての接続を引き続きプライマリ レプリカに誘導するためには、読み取りスケールアウトを無効にします。無効にする詳しい方法は「読み取りスケールアウトの有効化と無効化」セクションをご覧ください。
Note
読み取り専用レプリカでは、クエリ ストア、SQL Profiler の各機能はサポートされていません。
データの一貫性
プライマリ レプリカで行われたデータの変更は、レプリカの種類に応じて同期的または非同期的に読み取り専用レプリカに保持されます。 ただし、すべてのレプリカの種類で、読み取り専用レプリカからの読み取りは、プライマリに関して常に非同期です。 読み取り専用レプリカに接続されたセッション内では、読み取りが、常にトランザクション整合性が確保された状態となります。 データ伝達の待ち時間は変動するため、レプリカが異なれば、返されるデータの時点も、プライマリや他のレプリカと比べてわずかに異なる場合があります。 読み取り専用レプリカが利用不可となった後、セッションが再接続した場合、その接続先となるレプリカは、元のレプリカとは異なる時点のものである可能性があります。 同様に、アプリケーションがプライマリで読み取り/書き込みセッションを使用してデータを変更し、読み取り専用レプリカで読み取り専用セッションを使用してすぐに読み取る場合、最新の変更がすぐに表示されない可能性があります。
プライマリ レプリカと読み取り専用レプリカとの間における標準的なデータ伝達の待ち時間は、数十ミリ秒から 10 ミリ秒未満の範囲で変わります。 ただしデータ伝達の待ち時間に関して、決まった上限というものはありません。 レプリカにおけるリソース使用率の高さなどの条件によって、待ち時間が大幅に延びる場合もあります。 複数セッションにわたるデータ整合性の保証が要求されるアプリケーションや、コミットされたデータの即時読み取りが要求されるアプリケーションでは、プライマリ レプリカを使用する必要があります。
Note
データ伝達の待ち時間には、セカンダリ レプリカへのログ レコードの送信と保持 (該当する場合) に必要な時間が含まれます。 また、これらのログ レコードをデータ ページに再実行 (適用) するために必要な時間も含まれます。 データの一貫性を確保するために、トランザクション コミットのログ レコードが適用されるまで変更内容は表示されません。 ワークロードでより大きなトランザクションを使う場合、実際のデータ伝達の待ち時間は長くなります。
データ伝達の待ち時間を監視するには、「読み取り専用レプリカの監視とトラブルシューティング」を参照してください。
読み取り専用レプリカに接続する
データベースの読み取りスケールアウトを有効にすると、クライアントによって提供された接続文字列の ApplicationIntent オプションにより、接続が書き込みレプリカと読み取り専用レプリカのどちらにルーティングされるかが指定されます。 具体的には、ApplicationIntent 値が ReadWrite (既定値) の場合、接続は読み取り/書き込みレプリカにリダイレクトされます。 これは、接続文字列に ApplicationIntent が含まれていない場合の動作と同じです。 ApplicationIntent 値が ReadOnly の場合、接続は読み取り専用レプリカにルーティングされます。
たとえば、次の接続文字列はクライアントを読み取り専用レプリカに接続します (山かっこ内の項目は環境内の適切な値に置き換え、山かっこは削除します)。
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<password>;Trusted_Connection=False; Encrypt=True;
SQL Server Management Studio (SSMS) を使用して読み取り専用レプリカに接続するには、[オプション] を選択します
![SSMS の [オプション] ボタンを示すスクリーンショット。](media/read-scale-out/ssms-options-screen.png?view=azuresql)
[追加の接続パラメーター] を選択し、「ApplicationIntent=ReadOnly」と入力して [接続] を選択します
![SSMS の [追加接続パラメーター] を示すスクリーンショット。](media/read-scale-out/ssms-additional-connection-parameters-screen.png?view=azuresql)
次の接続文字列はどちらもクライアントを読み取り/書き込みレプリカに接続します (山かっこ内の項目は環境内の適切な値に置き換え、山かっこは削除します)。
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadWrite;User ID=<myLogin>;Password=<password>;Trusted_Connection=False; Encrypt=True;
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;User ID=<myLogin>;Password=<password>;Trusted_Connection=False; Encrypt=True;
接続先が読み取り専用レプリカであることを確認する
データベースのコンテキストで次のクエリを実行することにより、読み取り専用レプリカに接続しているかどうかを確認することができます。 読み取り専用レプリカに接続している場合は、READ_ONLY が返されます。
SELECT DATABASEPROPERTYEX(DB_NAME(), 'Updateability');
Note
Premium および Business Critical サービス レベルでは、任意の時点で読み取り専用レプリカのいずれか 1 つのみにアクセスできます。 Hyperscale では、複数の読み取り専用レプリカがサポートされています。
読み取り専用レプリカの監視とトラブルシューティング
読み取り専用レプリカに接続されている場合、動的管理ビュー (DMV) にレプリカの状態が反映され、監視とトラブルシューティングの目的ためにこれにクエリを実行できます。 データベース エンジンには、さまざまな監視データを表示するための複数のビューが用意されています。
次のビューは、レプリカの監視とトラブルシューティングによく使用されます。
| 名前 | 目的 |
|---|---|
| sys.dm_db_resource_stats | 過去 1 時間のリソース使用率のメトリックが提供されます (サービス目標の制限に対する CPU、データ IO、ログ書き込みの使用率など)。 |
| sys.dm_os_wait_stats | データベース エンジン インスタンスの待機統計の集計が提供されます。 |
| sys.dm_database_replica_states | レプリカの正常性状態と同期の統計情報が提供されます。 再実行キューのサイズと再実行率は、読み取り専用レプリカにおけるデータ伝達の待ち時間のインジケーターとして機能します。 |
| sys.dm_os_performance_counters | データベース エンジンのパフォーマンス カウンターが提供されます。 |
| sys.dm_exec_query_stats | 実行回数、CPU 使用時間など、クエリごとの実行統計が提供されます。 |
| sys.dm_exec_query_plan() | キャッシュされたクエリ プランが提供されます。 |
| sys.dm_exec_sql_text() | キャッシュされたクエリ プランのクエリ テキストが提供されます。 |
| sys.dm_exec_query_profiles | クエリの実行中のリアルタイムでのクエリの進行状況が提供されます。 |
| sys.dm_exec_query_plan_stats() | クエリのランタイム統計を含む最後の既知の実際の実行プランが提供されます。 |
| sys.dm_io_virtual_file_stats() | すべてのデータベース ファイルのストレージ IOPS、スループット、および待機時間の統計が提供されます。 |
Note
論理 master データベース内の sys.resource_stats および sys.elastic_pool_resource_stats DMV からは、プライマリ レプリカのリソース使用率のデータが返されます。
拡張イベントを使用して読み取り専用レプリカを監視する
読み取り専用レプリカに接続されているとき、拡張イベント セッションを作成することはできません。 ただし、Azure SQL Database および Azure SQL Managed Instance では、プライマリ レプリカで作成および変更されたデータベーススコープの拡張イベント セッションの定義が読み取り専用レプリカ (geo レプリカを含む) にレプリケートされ、読み取り専用レプリカでのイベントがキャプチャされます。
プライマリ レプリカからのセッション定義に基づく読み取り専用レプリカの拡張イベント セッションである Azure SQL Database は、プライマリ レプリカのセッションに関係なく開始および停止することができます。
Azure SQL Managed Instance で読み取り専用レプリカでトレースを開始するには、読み取り専用レプリカでトレースを開始する前に、まずプライマリ レプリカでトレースを開始する必要があります。 プライマリ レプリカで最初にトレースを開始しない場合は、読み取り専用レプリカでトレースを開始しようとすると、次のエラーが表示されます。
メッセージ 3906、レベル 16、状態 2、行 1 データベースが読み取り専用であるため、データベース "master" を更新できませんでした。
最初にプライマリ レプリカでトレースを開始した後、読み取り専用レプリカで、プライマリ レプリカでトレースを停止できます。
読み取り専用レプリカでイベント セッションをドロップするには、次の手順に従います。
- SSMS オブジェクト エクスプローラーまたはクエリ ウィンドウを読み取り専用レプリカに接続します。
- オブジェクト エクスプローラーのセッション コンテキスト メニューで [セッションの停止] を選択するか、クエリ ウィンドウで
ALTER EVENT SESSION [session-name-here] ON DATABASE STATE = STOP;を実行して、読み取り専用レプリカのセッションを停止します。 - オブジェクト エクスプローラーまたはクエリ ウィンドウをプライマリ レプリカに接続します。
- セッション コンテキスト メニューで [削除] を選択するか、または
DROP EVENT SESSION [session-name-here] ON DATABASE;を実行して、プライマリ レプリカのセッションをドロップします。
読み取り専用レプリカでのトランザクション分離レベル
読み取り専用レプリカのトランザクションでは、セッションのトランザクション分離レベルや、クエリ ヒントに関係なく、スナップショット トランザクション分離レベルが常に使用されます。 スナップショット分離では、行のバージョン管理を使用して、リーダーがライターをブロックするブロック シナリオが回避されます。
まれに、スナップショット分離トランザクションで、別の同時実行トランザクションで変更されたオブジェクト メタデータへのアクセスが行われる場合、エラー 3961、"データベース '%.*ls' でスナップショット分離トランザクションが失敗しました。ステートメントからアクセスされるオブジェクトが、このトランザクションの開始後に別の同時実行トランザクションの DDL ステートメントで変更されました。 メタデータはバージョン管理されないため、この操作は許可されません。 メタデータに対する同時更新は、スナップショット分離と組み合わせると一貫性を損なう結果になる可能性があります。" というメッセージが表示される場合があります。
読み取り専用レプリカでの実行時間の長いクエリ
読み取り専用レプリカでクエリを実行する場合、クエリで参照するオブジェクトのメタデータ (テーブル、インデックス、統計情報など) にアクセスする必要があります。稀なケースですが、クエリによって読み取り専用レプリカにあるオブジェクトにロックがかかっているときに、プライマリ レプリカでそのオブジェクトのメタデータに変更を加えるということが起こった場合は、そのクエリにより、プライマリ レプリカから読み取り専用レプリカに変更を適用する処理をブロックできます。 このようなクエリを長時間実行すると、読み取り専用レプリカのプライマリ レプリカとの同期が大きく外れる場合があります。 この場合、フェールオーバーが発生すると、フェールオーバー先になり得るレプリカ (Premium および Business Critical サービス レベルのセカンダリ レプリカ、Hyperscale HA レプリカ、すべての geo レプリカ) でデータベースの復旧が遅くなり、通常予期するよりもダウンタイムが長くなります。
読み取り専用レプリカで時間のかかるクエリを実行することにより、直接、間接にこのようなブロックが発生すると、過度のデータ遅延とデータベースの可用性への潜在的影響を避けるために、クエリが自動終了する場合があります。 このセッションでは、エラー 1219 "優先度の高い DDL 操作により、セッションが切断されました" またはエラー 3947 "セカンダリ コンピューティングが再実行をキャッチアップできなかったため、トランザクションが中止されました。 トランザクションを再試行してください」が表示されます。
Note
読み取り専用レプリカに対してクエリを実行したときに、エラー 3961、1219 または 3947 が発生した場合は、クエリを再試行してください。 あるいは、時間のかかるクエリをセカンダリ レプリカで実行している間、プライマリ レプリカでオブジェクトのメタデータを変更する操作 (スキーマの変更、インデックスのメンテナンス、統計情報の更新など) を避けてください。
ヒント
Premium および Business Critical サービス レベルでは、読み取り専用レプリカに接続されている場合、sys.dm_database_replica_states DMV の redo_queue_size および redo_rate 列を使用してデータ同期処理を監視でき、これは読み取り専用レプリカにおけるデータ伝達の待ち時間のインジケーターとして機能します。
SQL Database の読み取りスケールアウトを有効または無効にする
SQL Managed Instance の場合、読み取りスケールアウトは、Business Critical サービス レベルでは自動的に有効になり、General Purpose サービス レベルでは使用できません。 読み取りスケールアウトを無効にして再び有効にすることはできません。
SQL Database の場合、Premium、Business Critical、Hyperscale のサービス レベルでは、読み取りスケールアウトは既定で有効になります。 Basic、Standard、または General Purpose サービス レベルで読み取りスケールアウトを有効にすることはできません。 セカンダリ レプリカを 1 つも設定していない Hyperscale データベースでは、読み取りスケールアウトは自動的に無効になります。
Azure SQL Database の単一データベースとプールされたデータベースの場合、Premium または Business Critical サービス レベルの読み取りスケールアウトは、Azure portal と Azure PowerShell を使って、無効にしてもう一度有効にすることができます。 SQL Managed Instance では、読み取りスケールアウトを無効にできないため、これらのオプションは使用できません。
Note
単一データベースとエラスティック プール データベースでは、読み取りスケールアウトを無効にする機能は、下位互換性を維持するために提供されています。 Business Critical マネージド インスタンスでは、読み取りスケールアウトを無効にすることはできません。
Azure portal
Azure SQL Database の場合は、[設定] の下にある [コンピューティングとストレージ] データベース ペインで読み取りスケールアウト設定を管理できます。 Azure SQL Managed Instance では、Azure portal を使って読み取りスケールアウトを有効または無効にすることはできません。
PowerShell
重要
PowerShell Azure Resource Manager モジュールは引き続きサポートされますが、今後の開発はすべて Az.Sql モジュールを対象に行われます。 Azure Resource Manager モジュールのバグ修正は、少なくとも 2020 年 12 月までは引き続き受け取ることができます。 Az モジュールと Azure Resource Manager モジュールのコマンドの引数は実質的に同じです。 その互換性の詳細については、「新しい Azure PowerShell Az モジュールの概要」を参照してください。
Azure PowerShell で読み取りスケールアウトを管理するには、2016 年 12 月以降のリリースの Azure PowerShell が必要です。 最新の PowerShell リリースについては、Azure PowerShell に関するページを参照してください。
Azure SQL Database では、Azure PowerShell で Set-AzSqlDatabase コマンドレットを呼び出し、-ReadScale パラメーターに目的の値 (Enabled または Disabled) を渡すことで、読み取りスケールアウトを無効にし、再び有効にできます。 SQL Managed Instance の読み取りスケールアウトを無効にすることはできません。
既存のデータベースの読み取りスケールアウトを無効にするには (山かっこ内の項目を自分の環境用の適切な値に置き換え、山かっこを削除してください):
Set-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Disabled
新しいデータベースの読み取りスケールアウトを無効にするには (山かっこ内の項目を自分の環境用の適切な値に置き換え、山かっこを削除してください):
New-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Disabled -Edition Premium
既存のデータベースの読み取りスケールアウトを再び有効にするには (山かっこ内の項目を自分の環境用の適切な値に置き換え、山かっこを削除してください):
Set-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Enabled
REST API
読み取りスケールアウトが無効なデータベースを作成する、または既存のデータベースの設定を変更するには、次の方法を使用して、以下の要求の例に示すように readScale プロパティを Enabled または Disabled に設定します。
Method: PUT
URL: https://management.azure.com/subscriptions/{SubscriptionId}/resourceGroups/{GroupName}/providers/Microsoft.Sql/servers/{ServerName}/databases/{DatabaseName}?api-version= 2014-04-01-preview
Body: {
"properties": {
"readScale":"Disabled"
}
}
詳細については、「データベース - 作成または更新」を参照してください。
読み取り専用レプリカで tempdb データベースを使用する
プライマリ レプリカでの tempdb データベースは読み取り専用レプリカにはレプリケートされません。 各レプリカには、レプリカの作成時に作成された独自の tempdb データベースがあります。 これにより、tempdb が更新可能となり、クエリの実行時に変更できるようになります。 読み取り専用ワークロードで tempdb オブジェクトを使用する必要がある場合、これらのオブジェクトは、読み取り専用レプリカに接続した状態で、そのワークロードの一部として作成するべきです。
geo レプリケートされたデータベースで読み取りスケールアウトを使用する
geo レプリケーションしたセカンダリ データベースには、プライマリ データベースと同一の High Availability アーキテクチャが存在します。 読み取りスケールアウトが有効な、geo レプリケートされたセカンダリ データベースに接続している場合、ApplicationIntent=ReadOnly が設定されたセッションは、プライマリ書き込み可能データベース上でルーティングされるのと同じ方法で、高可用性レプリカの 1 つにルーティングされます。 ApplicationIntent=ReadOnly が設定されていないセッションは、geo レプリケートされたセカンダリのプライマリ レプリカ (これも読み取り専用) にルーティングされます。
この方法により、geo レプリカを作成することで、読み取り書き込み用プライマリ データベースに、複数の読み取り専用レプリカを追加できます。 geo レプリカを 1 つ追加すると、1 組の新たな読み取り専用レプリカが追加されます。 geo レプリカは、プライマリ データベースのリージョンを含め任意の Azure リージョンに作成できます。
Note
geo レプリケーションしたセカンダリ データベースのレプリカ間には、自動ラウンドロビンなどの負荷分散ルーティングの仕組みはありません。ただし、2 つ以上の HA レプリカが存在する Hyperscale geo レプリカは例外です。 この場合、読み取り専用を意図したセッションは、geo レプリカのすべての HA レプリカに分散します。
読み取り専用レプリカでの機能のサポート
読み取り専用レプリカでの一部の機能の動作の一覧を次に示します。
- 読み取り専用レプリカでの監査は自動的に有効になります。 ストレージ フォルダーの階層、名前付け規則、ログ形式の詳細については、「SQL Database 監査ログの形式」を参照してください。
- Query Performance Insight は、クエリ ストアのデータに依存しており、現在、読み取り専用レプリカでのアクティビティは追跡されません。 Query Performance Insight では、読み取り専用レプリカで実行されるクエリは表示されません。
- 自動チューニングに関する文書で詳細に説明されているように、自動チューニングはクエリ ストアに依存しています。 自動チューニングは、プライマリ レプリカで実行されているワークロードに対してのみ機能します。
次のステップ
- SQL Database Hyperscale オファリングの情報については、Hyperscale サービス レベルに関する記事を参照してください。