Spark コネクタを使用したリアルタイムのビッグ データ分析の高速化
適用対象: ![]() Azure SQL データベース
Azure SQL データベース ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Note
2020 年 9 月現在、このコネクタは積極的に保守されていません。 ただし、SQL Server および Azure SQL 用の Apache Spark コネクタが使用できるようになりました。Python および R のバインディング、データをバルク インサートするための使いやすいインターフェイス、その他多くの機能強化がサポートされています。 このページのコネクタではなく、新しいコネクタを評価して使用することを強くお勧めします。 古いコネクタに関する情報 (このページ) は、アーカイブ目的でのみ保持されます。
Spark コネクタを使用すると、Azure SQL Database、Azure SQL Managed Instance、SQL Server のデータベースを Spark ジョブの入力データ ソースまたは出力データ シンクとして機能させることができます。 ビッグ データ分析の中でリアルタイム トランザクション データを利用でき、アドホック クエリの結果やレポートを保持できます。 組み込みの JDBC コネクタに比べて、このコネクタには、データベースにデータを一括挿入する機能があります。 行単位の挿入に比べ、パフォーマンスを 10 倍から 20 倍も向上させることができます。 Spark コネクタでは、Azure SQL Database と Azure SQL Managed Instance に接続するための Microsoft Entra ID (旧称 Azure Active Directory) による認証がサポートされています。これにより、Microsoft Entra アカウントを使用して、Azure Databricks からデータベースを接続できるようになります。 組み込みの JDBC コネクタと同様のインターフェイスを備えています。 この新しいコネクタを使用するための既存の Spark ジョブの移行は簡単に実行できます。
Note
Microsoft Entra ID の、旧称は Azure Active Directory(Azure AD)です。
Spark コネクタのダウンロードと構築
過去にこのページからリンクされていた古いコネクタの GitHub リポジトリは、積極的に保守されていません。 代わりに、新しいコネクタを評価して使用することを強くお勧めします。
正式にサポートされているバージョン
| コンポーネント | Version |
|---|---|
| Apache Spark | 2.0.2 以降 |
| Scala | 2.10 以降 |
| SQL Server 用 Microsoft JDBC ドライバー | 6.2 以降 |
| Microsoft SQL Server | SQL Server 2008 以降 |
| Azure SQL データベース | サポートされています |
| Azure SQL Managed Instance | サポートされています |
Spark コネクタでは、SQL Server 用の Microsoft JDBC ドライバーを使用して、Spark ワーカー ノードとデータベース間でデータを移動します。
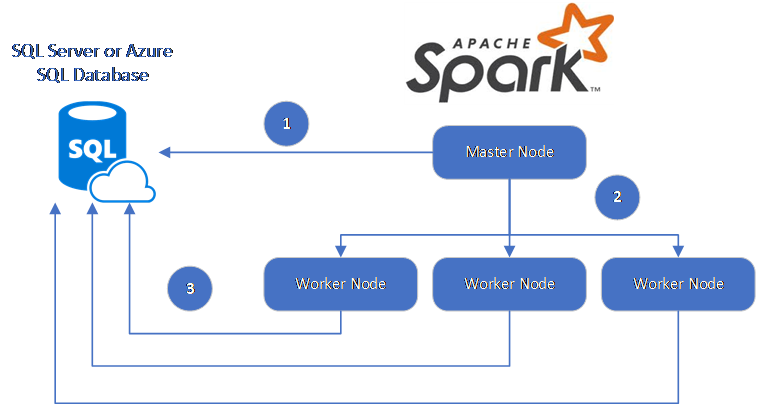
データフローは次のとおりです。
- Spark マスター ノードから SQL Database または SQL Server のデータベースへの接続が行われ、特定のテーブルから、または特定の SQL クエリを使用して、データが読み込まれます。
- Spark のマスター ノードが、変換のためにワーカー ノードにデータを分散します。
- ワーカー ノードから、SQL Database および SQL Server に接続するデータベースへの接続が行われ、データベースにデータが書き込まれます。 ユーザーは、使用する挿入方法 (行単位または一括) を選択できます。
次の図にデータ フローを示します。
Spark コネクタの構築
現在、コネクタ プロジェクトでは Maven を使用します。 依存関係なしにコネクタを構築するには、次のコードを実行します。
- mvn クリーン パッケージ
- releases フォルダーから最新バージョンの JAR をダウンロードします
- SQL Database Spark JAR をインクルードします
Spark コネクタを使用した接続とデータの読み取り
Spark ジョブから SQL Database と SQL Server のデータベースに接続して、データの読み取りまたは書き込みを行うことができます。 SQL Database または SQL Server のデータベースで DML または DDL クエリを実行することもできます。
Azure SQL または SQL Server からデータを読み取る
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
指定した SQL クエリによる Azure SQL または SQL Server からのデータの読み込み
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Azure SQL または SQL Server にデータを書き込む
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Azure SQL または SQL Server で DML クエリまたは DDL クエリを実行する
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Microsoft Entra 認証を使用して Spark から接続する
Microsoft Entra 認証を使用して SQL Database および SQL Managed Instance に接続できます。 Microsoft Entra 認証は、データベース ユーザーの ID を一元管理するために、SQL 認証の代替として使用します。
ActiveDirectoryPassword 認証モードを使用した接続
設定要件
ActiveDirectoryPassword 認証モードを使用している場合は、microsoft-authentication-library-for-java とその依存関係をダウンロードし、Java ビルド パスに含める必要があります。
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
アクセス トークンを使用した接続
設定要件
アクセス トークン ベースの認証モードを使用している場合は、microsoft-authentication-library-for-java とその依存関係をダウンロードし、Java ビルド パスに含める必要があります。
Azure SQL Database または Azure SQL Managed Instance のデータベースへのアクセス トークンを取得する方法については、「Microsoft Entra 認証を使用する」を参照してください。
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
一括挿入を使用したデータの書き込み
従来の JDBC コネクタでは、行単位の挿入を使用してデータベースへのデータの書き込みが行われます。 Spark コネクタでは、一括挿入を使用して Azure SQL または SQL Server にデータを書き込むことができます。 大きなデータ セットを読み込むとき、または列ストア インデックスが使用されているテーブルにデータを読み込むときの書き込みのパフォーマンスが大幅に向上します。
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
次のステップ
Spark コネクタをまだダウンロードしていない場合は、GitHub の azure-sqldb-spark リポジトリからダウンロードし、リポジトリのその他のリソースを調べます。
また、Apache Spark SQL、DataFrames、データセット ガイドと Azure Databricks ドキュメントを確認することもできます。