チュートリアル:Azure VM での SAP HANA データベースのバックアップ
このチュートリアルでは、Azure VM 上で稼働している SAP HANA データベースを Azure Backup Recovery Services コンテナーにバックアップする方法について説明します。 この記事では、以下を行う方法について説明します。
- コンテナーを作成して構成する
- データベースを検出する
- バックアップを構成する
現在サポートされているすべてのシナリオについては、こちらを参照してください。
前提条件
バックアップを構成する前に、必ず、次の操作を行ってください。
- SAP HANA を実行する VM として、同じリージョンおよびサブスクリプションの Recovery Services コンテナーを特定または作成します。
- VM からインターネットへの接続を許可して、Azure に到達できるようにします。以下の「ネットワーク接続を設定する」セクションを参照してください。
- SAP HANA Server VM 名とリソース グループ名とを組み合わせた長さが、Azure Resource Manager (ARM_ VM) の場合は 84 文字、クラシック VM の場合は 77 文字を超えないようにしてください。 この制限は、一部の文字がサービスによって予約されていることに起因します。
- 次の条件を満たすキーが hdbuserstore に存在する必要があります。
- 既定の hdbuserstore に存在する。 既定値は、SAP HANA がインストールされている
<sid>admアカウントです。 - MDC の場合、キーが NAMESERVER の SQL ポートを指すこと。 SDC の場合は、INDEXSERVER の SQL ポートを指す必要があります
- ユーザーを追加したり削除したりするための資格情報があること。
- このキーは、事前登録スクリプトを正常に実行した後に削除できることに注意してください
- 既定の hdbuserstore に存在する。 既定値は、SAP HANA がインストールされている
- また、上記の手順に従ってカスタム キーを作成する代わりに、hdbuserstore の既存の HANA SYSTEM ユーザーのキーを作成することも選択できます。
- HANA がインストールされている仮想マシンで、SAP HANA バックアップ構成スクリプト (事前登録スクリプト) をルート ユーザーとして実行します。 このスクリプトで、バックアップに備えて HANA システムの準備を行い、上記の手順で作成したキーを入力として渡すように求めます。 この入力をパラメーターとしてスクリプトに渡す方法については、「事前登録スクリプトで実行される処理」セクションを参照してください。 ここでは、事前登録スクリプトで実行される処理の詳細についても説明されています。
- HANA セットアップでプライベート エンドポイントが使用されている場合は、 事前登録スクリプトを -sn または --skip-network-checks パラメーターを指定して実行します。
Note
事前登録スクリプトは、RHEL (7.4、7.6、および 7.7) 上で実行されている SAP HANA ワークロードには compat-unixODBC234 をインストールし、RHEL 8.1 には unixODBC をインストールします。 このパッケージは、RHEL for SAP HANA (RHEL 7 Server の場合) の SAP ソリューション用更新サービス (RPM) リポジトリにあります。 Azure Marketplace RHEL イメージの場合、リポジトリは rhui-rhel-sap-hana-for-rhel-7-server-rhui-e4s-rpms になります。
バックアップと復元のスループット パフォーマンスについて
Backint を介して提供される SAP HANA Azure VM のバックアップ (ログおよびログ以外) は、Azure Recovery Services コンテナー (内部で Azure Storage Blob を使用) へのストリームであるため、このストリーミング手法を理解することが重要です。
HANA の Backint コンポーネントは、ディスクに接続された "パイプ" (情報を読み取るためのパイプと書き込むためのパイプ) の役割を果たします。基になるディスクには、データベース ファイルが存在します。それらが Azure Backup サービスによって読み取られて、リモート Azure Storage アカウントである Azure Recovery Services コンテナーに転送されます。 Azure Backup サービスでは、Backint のネイティブ検証チェックとは別に、チェックサムによってストリームが検証されます。 これらの検証によって、Azure Recovery Services コンテナーにあるデータが確かに信頼できるものであり、回復可能であることが確認されます。
ストリームの処理対象になるのは主にディスクであるため、バックアップと復元のパフォーマンスを正確に測定するためには、ディスクの読み取りパフォーマンスとバックアップ データを転送するためのネットワーク パフォーマンスを把握する必要があります。 Azure VM におけるディスクまたはネットワークのスループットとパフォーマンスを深く理解するために、こちらの記事を参照してください。 これらはバックアップと復元のパフォーマンスにも当てはまります。
Azure Backup サービスは、ログ バックアップ以外 (完全、差分、増分など) で最大約 420 MBps を、HANA のログ バックアップで最大 100 MBps を達成しようと試みます。 前述のように、これらの速度は保証されているわけではなく、次の要因に左右されます。
- VM のキャッシュ不使用時の最大ディスク スループット - データまたはログ領域から読み取ります。
- 基になるディスクの種類とそのスループット - データまたはログ領域から読み取ります。
- VM の最大ネットワーク スループット - Recovery Services コンテナーに書き込みます。
- VNET に NVA またはファイアウォールがある場合はそのネットワーク スループット
- Azure NetApp Files にデータまたはログがある場合 - ANF からの読み取りとコンテナーへの書き込みの両方により VM のネットワークが使用されます。
重要
キャッシュ不使用時のディスク スループットが 400 MBps を超えないまでも、それに限りなく近いような小さな VM では、ディスク全体の IOPS がバックアップ サービスによって消費されるおそれがあり、ディスクに対する読み取り/書き込みに関連した SAP HANA の動作に影響を及ぼす可能性があります。 そのようなケースで、バックアップ サービスの消費をスロットル (制限) して上限を超えないようにしたい場合は、次のセクションを参照してください。
バックアップのスループット パフォーマンスを制限する
バックアップ サービスのディスク IOPS 消費をスロットルして上限値を超えないようにしたい場合は、次の手順を実行してください。
"opt/msawb/bin" フォルダーに移動します
"ExtensionSettingsOverrides.JSON" という名前の新しい JSON ファイルを作成します
JSON ファイルに、次のキーと値のペアを追加します。
{ "MaxUsableVMThroughputInMBPS": 120 }ファイルのアクセス許可と所有権を次のように変更します。
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.jsonサービスを再起動する必要はありません。 Azure Backup サービスは、このファイルの記述に従ってスループット パフォーマンスの制限を試みます。
Note
変更が適用されていない場合は、データベースを再起動します。
事前登録スクリプトで実行される処理
事前登録スクリプトでは、次の機能が実行されます。
- ご利用の Linux ディストリビューションに基づいて、スクリプトにより、Azure Backup エージェントに必要なすべてのパッケージがインストールまたは更新されます。
- Azure Backup サーバーと依存サービス (Microsoft Entra ID、Azure Storage など) に対するアウトバウンド ネットワーク接続チェックを実行します。
- 前提条件の 1 つとして指定されているカスタム ユーザー キーまたは SYSTEM ユーザー キーを使用して、HANA システムにログインします。 これは、バックアップ ユーザー (AZUREWLBACKUPHANAUSER) を HANA システムに作成するために使用されます。また、ユーザー キーは、事前登録スクリプトが正常に実行された後で削除できます。 SYSTEM ユーザー キーは削除できないことに注意してください。
- /opt/msawb フォルダーがルート パーティションにあるかどうか、およびルート パーティションのサイズが 2 GB であるかどうかがチェックされ、警告が出されます。 このスクリプトでは、ルート パーティションのサイズを 4 GB に増やすか、または最大 4 GB まで拡張できる領域がある別の場所に /opt/msawb フォルダーを移動するように推奨されます。 サイズが 2 GB のルート パーティションに /opt/msawb フォルダーがある場合、これによってルート パーティションがいっぱいになり、バックアップが失敗する可能性があるので注意してください。
- AZUREWLBACKUPHANAUSER には、次の必要なロールとアクセス許可が割り当てられます。
- MDC の場合: DATABASE ADMIN および BACKUP ADMIN (HANA 2.0 SPS05 以降): 復元中に新しいデータベースを作成します。
- SDC の場合: BACKUP ADMIN: 復元中に新しいデータベースを作成します。
- CATALOG READ: バックアップ カタログを読み取ります。
- SAP_INTERNAL_HANA_SUPPORT いくつかのプライベート テーブルにアクセスします。 HANA 2.0 SPS04 Rev 46 未満の SDC および MDC バージョンでのみ必要となります。 HANA 2.0 SPS04 Rev 46 以上の場合、 必要な情報は HANA チームからの修正プログラムと共にパブリック テーブルから入手しているため、これは必要ありません。
- このスクリプトにより、HANA バックアップ プラグインですべての操作 (データベース クエリ、復元操作、バックアップの構成と実行) を処理するために AZUREWLBACKUPHANAUSER の hdbuserstore にキーが追加されます。
- または、独自のカスタム Backup ユーザーを作成することを選択できます。 このユーザーに、次の必要なロールとアクセス許可が割り当てられていることを確認してください。
- MDC の場合: DATABASE ADMIN および BACKUP ADMIN (HANA 2.0 SPS05 以降): 復元中に新しいデータベースを作成します。
- SDC の場合: BACKUP ADMIN: 復元中に新しいデータベースを作成します。
- CATALOG READ: バックアップ カタログを読み取ります。
- SAP_INTERNAL_HANA_SUPPORT いくつかのプライベート テーブルにアクセスします。 HANA 2.0 SPS04 Rev 46 未満の SDC および MDC バージョンでのみ必要となります。 HANA 2.0 SPS04 Rev 46 以降では、HANA チームからの修正プログラムを使用してパブリック テーブルから必要な情報を取得するようになったため、これは必要ありません。
- 次に、HANA バックアップ プラグインですべての操作 (データベース クエリ、復元操作、構成、バックアップの実行) を処理するために、カスタム Backup ユーザーの hdbuserstore にキーを追加します。 このカスタム Backup ユーザー キーを、パラメーター
-bk CUSTOM_BACKUP_KEY_NAMEまたは-backup-key CUSTOM_BACKUP_KEY_NAMEとしてスクリプトに渡します。 このカスタム バックアップ キーのパスワードの期限切れが、バックアップと復元の失敗につながる可能性があることに注意してください。 - HANA
<sid>admのユーザーが Active Directory (AD) のユーザーである場合、AD に msawb グループを作成し、このグループに<sid>admユーザーを追加します。 次に、登録前スクリプトで<sid>admパラメーターを使って、-ad <SID>_ADM_USER or --ad-user <SID>_ADM_USERが AD ユーザーであることを指定する必要があります。
Note
このスクリプトで受け取るその他のパラメーターを確認するには、bash msawb-plugin-config-com-sap-hana.sh --help コマンドを使用してください。
キーの作成を確認するには、SIDADM 資格情報を使用して HANA コンピューター上で HDBSQL コマンドを実行します。
hdbuserstore list
このコマンド出力には、AZUREWLBACKUPHANAUSER として示されるユーザーと共に {SID}{DBNAME} キーが表示されます。
Note
/usr/sap/{SID}/home/.hdb/ の下に固有の一連の SSFS ファイルがあることを確認してください。 このパスにはフォルダーが 1 つしか存在しません。
事前登録スクリプトの実行を完了するために必要な手順の概要を次に示します。 このフローでは、事前登録スクリプトへの入力パラメーターとして SYSTEM ユーザー キーを提供していることに注意してください。
| 担当者 | ソース | 実行対象 | 説明 |
|---|---|---|---|
<sid>adm (OS) |
HANA OS | チュートリアルを読み、事前登録スクリプトをダウンロードします。 | チュートリアル: Azure VM での SAP HANA データベースのバックアップ 事前登録スクリプトをダウンロードします |
<sid>adm (OS) |
HANA OS | HANA を開始します (HDB start) | セットアップの前に、HANA が稼働していることを確認します。 |
<sid>adm (OS) |
HANA OS | コマンドを実行しますhdbuserstore Set |
hdbuserstore Set SYSTEM <hostname>:3<Instance#>13 SYSTEM <password> 注 IP アドレスまたは FQDN ではなく、ホスト名を必ず使用してください。 |
<sid>adm (OS) |
HANA OS | 次のコマンドを実行します。hdbuserstore List |
結果に次のような既定のストアが含まれているかどうかを確認します。KEY SYSTEM ENV : <hostname>:3<Instance#>13 USER : SYSTEM |
| root (OS) | HANA OS | Azure Backup HANA 事前登録スクリプトを実行します。 | ./msawb-plugin-config-com-sap-hana.sh -a --sid <SID> -n <Instance#> --system-key SYSTEM |
<sid>adm (OS) |
HANA OS | コマンドを実行しますhdbuserstore List |
結果に次のような新しい行が結果に含まれているかどうかを確認します: KEY AZUREWLBACKUPHANAUSER ENV : localhost: 3<Instance#>13 USER: AZUREWLBACKUPHANAUSER |
| Azure 共同作成者 | Azure Portal | Azure Backup サービス、Microsoft Entra ID、および Azure Storage への送信トラフィックを許可するように、NSG、NVA、Azure Firewall などを構成します。 | ネットワーク接続を設定する |
| Azure 共同作成者 | Azure portal | Recovery Services コンテナーを作成するかまたは開いて、HANA バックアップを選択します。 | バックアップするすべてのターゲット HANA VM を検出します。 |
| Azure 共同作成者 | Azure portal | HANA データベースを検出し、バックアップ ポリシーを構成します。 | 例: 週次バックアップ: 毎週日曜日午前 2 時、保持期間は週単位で 12 週間、月単位で 12 か月、年単位で 3 年間 差分または増分: 日曜日を除く毎日 ログ: 15 分ごと、保持期間は 35 日間 |
| Azure 共同作成者 | Azure portal | Recovery Service コンテナー – バックアップ項目 – SAP HANA | バックアップ ジョブ (Azure ワークロード) を確認します。 |
| HANA 管理者 | HANA Studio | Backup Console、Backup カタログ、backup.log、backint.log、および globa.ini を確認します | SYSTEMDB とテナント データベースの両方。 |
事前登録スクリプトが正常に実行されたことを確認したら、接続要件の確認に進み、次に Recovery Services コンテナーからバックアップを構成できます。
Recovery Services コンテナーを作成する
Recovery Services コンテナーは、時間の経過と共に作成される復旧ポイントを格納する管理エンティティであり、バックアップ関連の操作を実行するためのインターフェイスが用意されています。 たとえば、オンデマンドのバックアップの作成、復元の実行、バックアップ ポリシーの作成などの操作です。
Recovery Services コンテナーを作成するには、次の手順に従います。
Azure portal にサインインします。
ビジネス継続性センターを検索し、ビジネス継続性センター ダッシュボードに移動します。

[コンテナー] ペインで、[+コンテナー] を選択します。

[Recovery Services コンテナー]>[続行] の順に選択します。
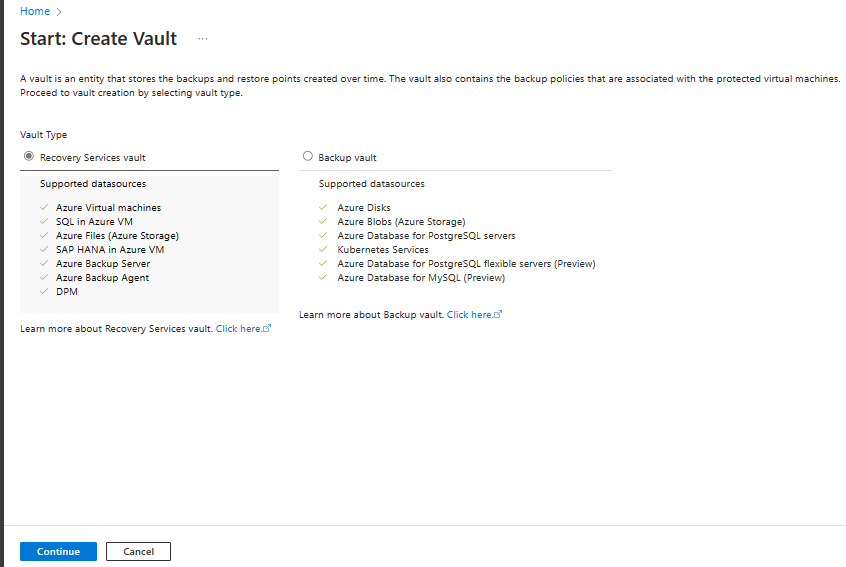
[Recovery Services コンテナー] ペインで、次の値を入力します。
[サブスクリプション] : 使用するサブスクリプションを選択します。 1 つのサブスクリプションのみのメンバーの場合は、その名前が表示されます。 どのサブスクリプションを使用すればよいかがわからない場合は、既定のサブスクリプションを使用してください。 職場または学校アカウントが複数の Azure サブスクリプションに関連付けられている場合に限り、複数の選択肢が存在します。
[リソース グループ] :既存のリソース グループを使用するか、新しいリソース グループを作成します。 サブスクリプションの使用可能なリソース グループの一覧を表示するには、[既存のものを使用] を選択してから、ドロップダウン リストでリソースを選択します。 新しいリソース グループを作成するには、[新規作成] を選択し、名前を入力します。 リソース グループの詳細については、「Azure Resource Manager の概要」を参照してください。
[コンテナー名]: コンテナーを識別するフレンドリ名を入力します。 名前は Azure サブスクリプションに対して一意である必要があります。 2 文字以上で、50 文字以下の名前を指定します。 名前の先頭にはアルファベットを使用する必要があります。また、名前に使用できるのはアルファベット、数字、ハイフンのみです。
[リージョン]: コンテナーの地理的リージョンを選択します。 データ ソースを保護するためのコンテナーを作成するには、コンテナーがデータ ソースと同じリージョン内にある "必要があります"。
重要
データ ソースの場所が不明な場合は、ウィンドウを閉じます。 ポータルの自分のリソースの一覧に移動します。 複数のリージョンにデータ ソースがある場合は、リージョンごとに Recovery Services コンテナーを作成します。 最初の場所にコンテナーを作成してから、別の場所にコンテナーを作成します。 バックアップ データを格納するためにストレージ アカウントを指定する必要はありません。 Recovery Services コンテナーと Azure Backup で自動的に処理されます。
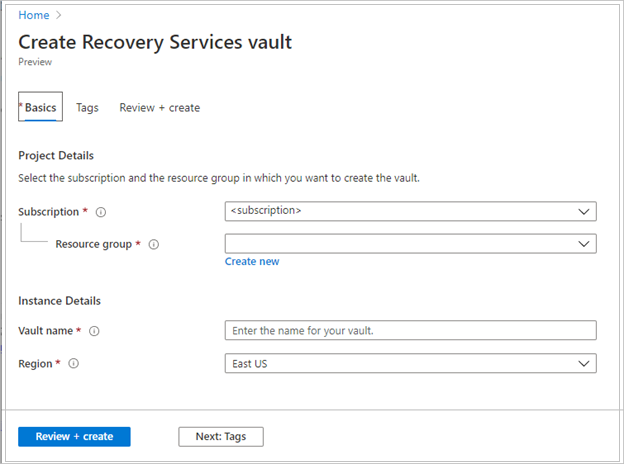
値を指定したら、 [確認と作成] を選択します。
Recovery Services コンテナーの作成を完了するには、[作成] を選択します。
Recovery Services コンテナーの作成に時間がかかることがあります。 右上の [通知] 領域で、状態の通知を監視します。 作成されたコンテナーは、Recovery Services コンテナーのリストに表示されます。 コンテナーが表示されない場合は、[最新の情報に更新] を選択します。


注意
Azure Backup は、作成された復旧ポイントがバックアップ ポリシーに従って、有効期限切れ前に削除されないようにできる不変コンテナーをサポートするようになりました。 また、不変性を元に戻せないようにして、ランサムウェア攻撃や悪意のあるアクターなど、さまざまな脅威からバックアップ データを最大限に保護することができます。 詳細については、こちらを参照してください。
これで、Recovery Services コンテナーが作成されました。
リージョンをまたがる復元を有効にする
Recovery Services コンテナーでは、リージョンをまたがる復元を有効にできます。 リージョンをまたがる復元を有効にする方法に関する記事を参照してください。
リージョンをまたがる復元に関する詳細情報を参照してください。
データベースを検出する
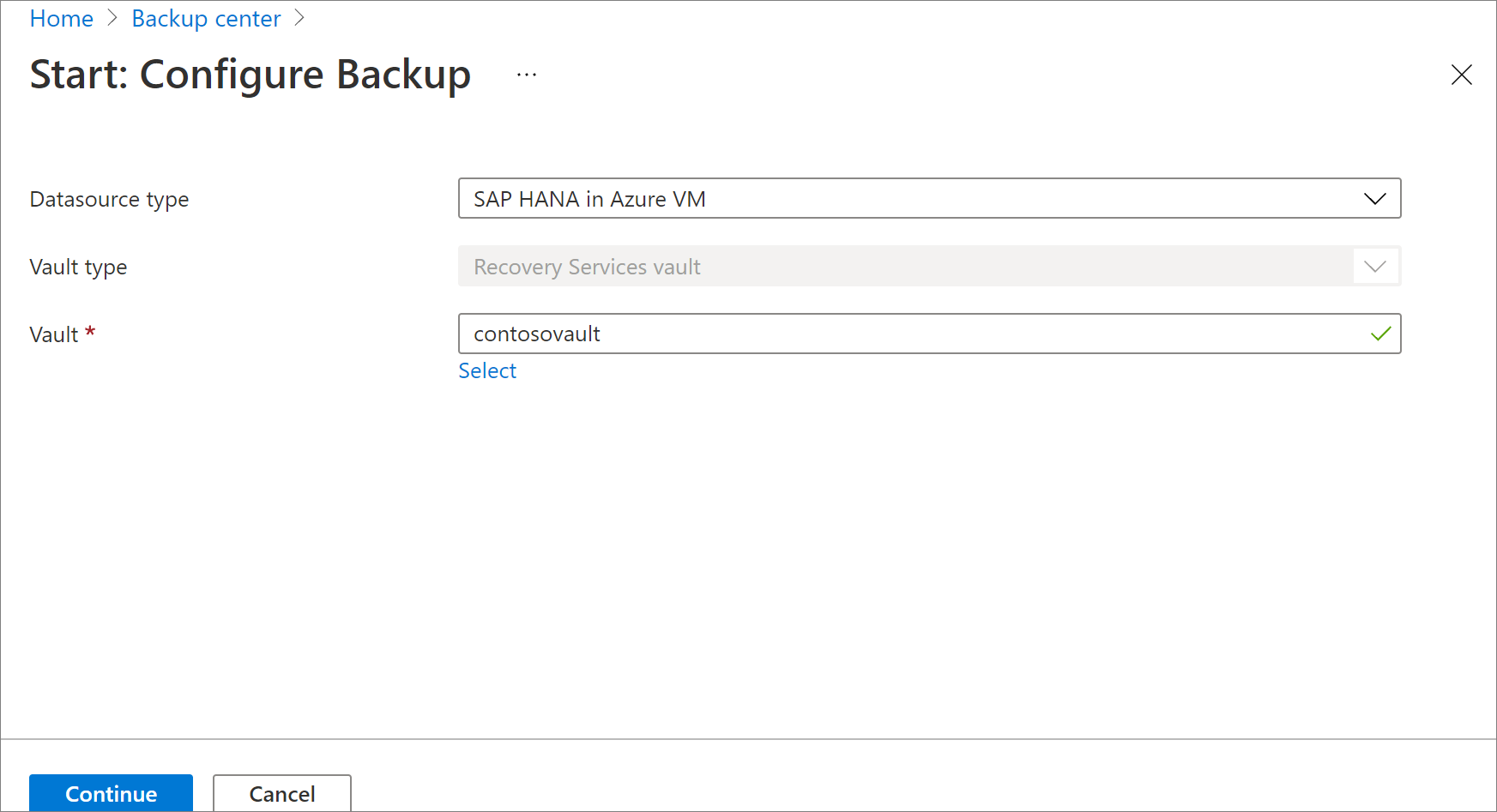
Azure portal で、 [バックアップ センター] に移動し、 [+ バックアップ] をクリックします。
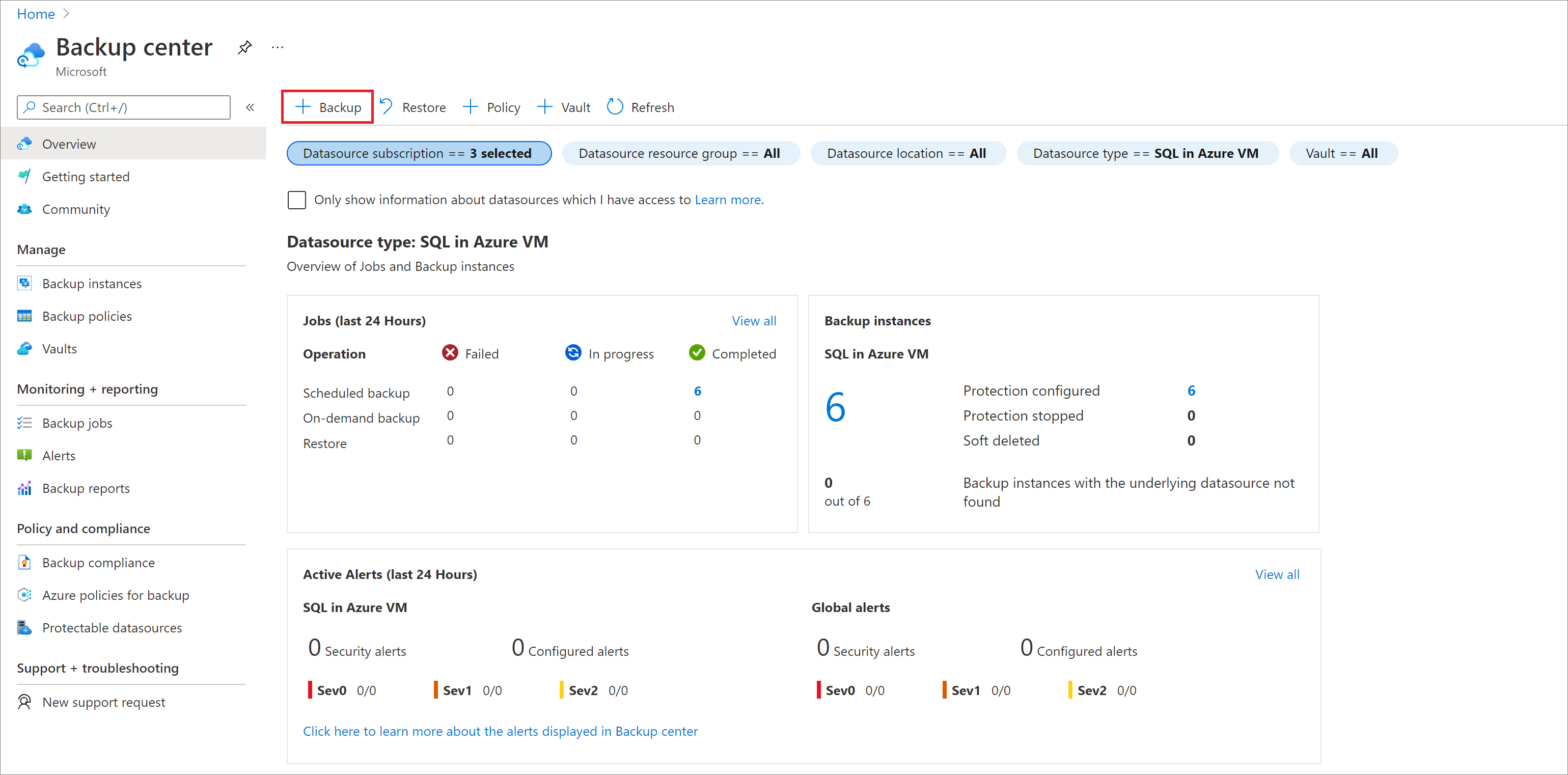
データソースの種類として [Azure VM の SAP HANA] を選び、バックアップに使う Recovery Services コンテナーを選んで、 [続行] をクリックします。
** [検出の開始]** を選択します。 これで、コンテナー リージョン内の保護されていない Linux VM の検出が開始されます。- 検出後、保護されていない VM は、ポータルで名前およびリソース グループ別に一覧表示されます。
- VM が予期したとおりに一覧表示されない場合は、それが既にコンテナーにバックアップされているかどうかを確認してください。
- 複数の VM を同じ名前にすることはできますが、それらは異なるリソース グループに属しています。
![[検出の開始] の選択を示すスクリーンショット。](media/backup-azure-sap-hana-database/hana-discover-databases.png)
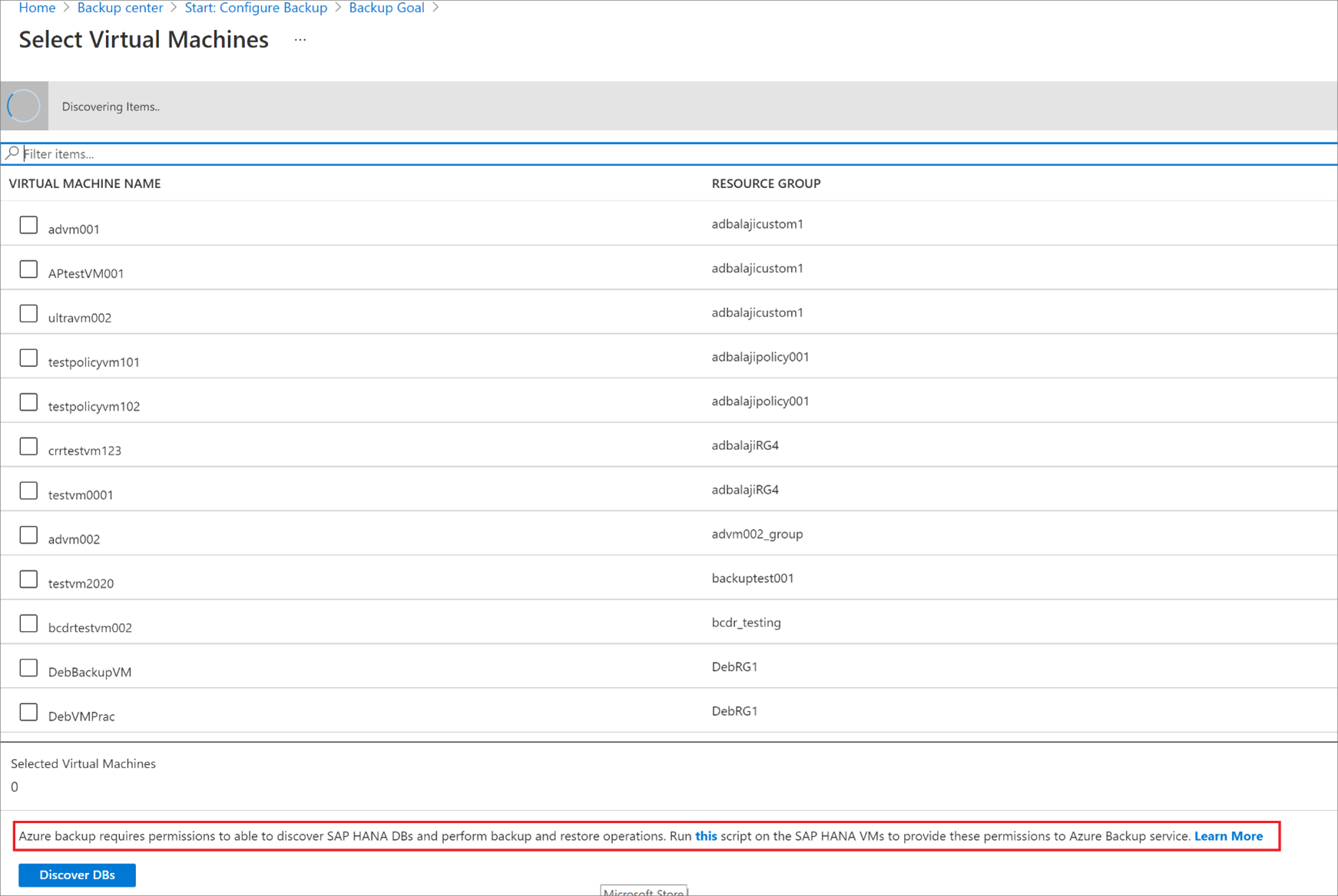
[仮想マシンの選択] で、リンクをクリックして、データベースの検出のために SAP HANA VM へのアクセス許可を Azure Backup サービスに与えるスクリプトをダウンロードします。
バックアップする SAP HANA データベースをホストしている各 VM でスクリプトを実行します。
VM でスクリプトを実行した後、 [仮想マシンの選択] で、VM を選択します。 次に、[データベースを検出] を選択します。
Azure Backup によって、VM 上のすべての SAP HANA データベースが検出されます。 検出中に、Azure Backup によって VM がコンテナーに登録され、VM に拡張機能がインストールされます。 エージェントはデータベースにインストールされません。


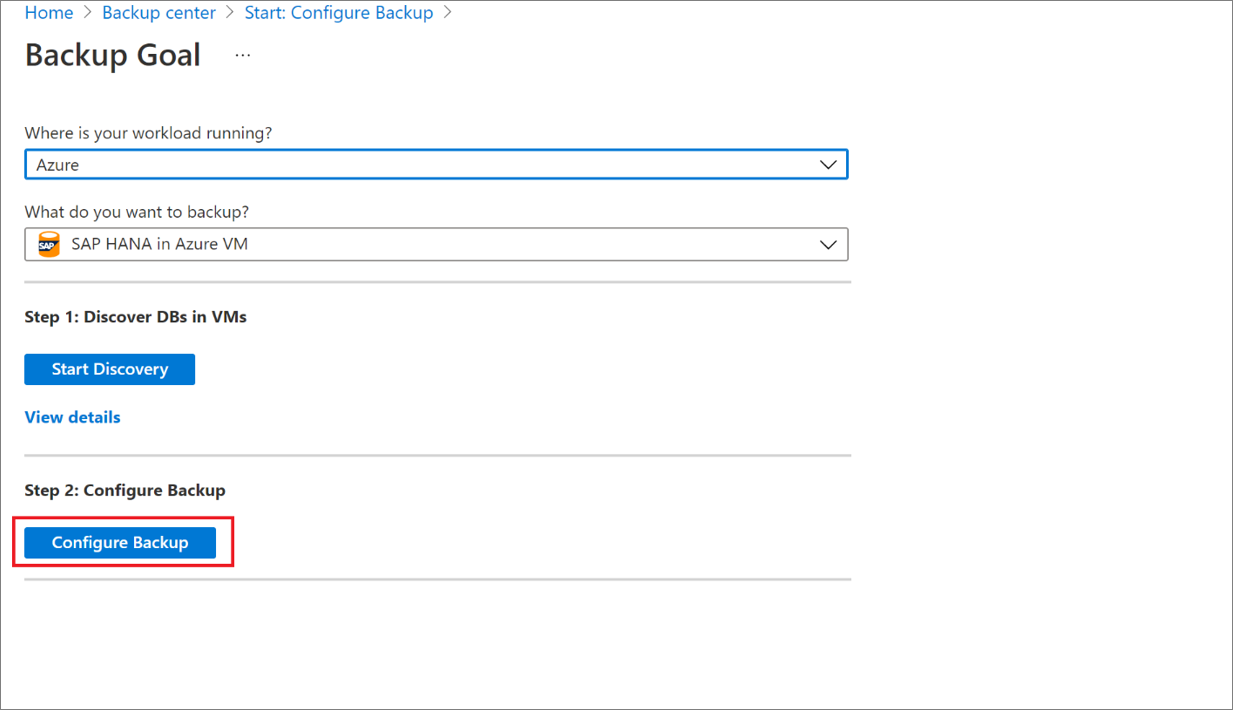
バックアップの構成
ここでバックアップを有効にします。
手順 2 で、 [バックアップの構成] を選択します。
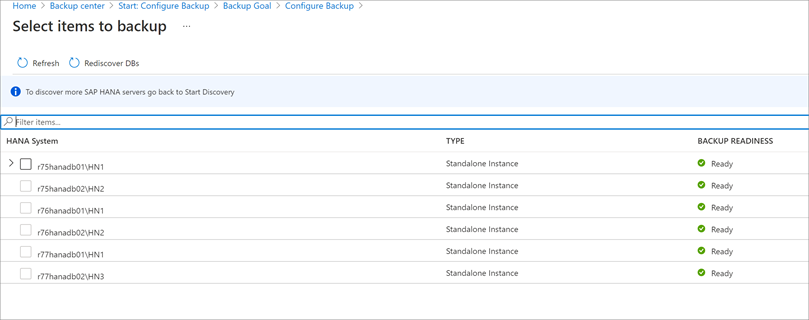
[バックアップする項目の選択] で、保護するデータベースをすべて選択し、[OK] を選びます。
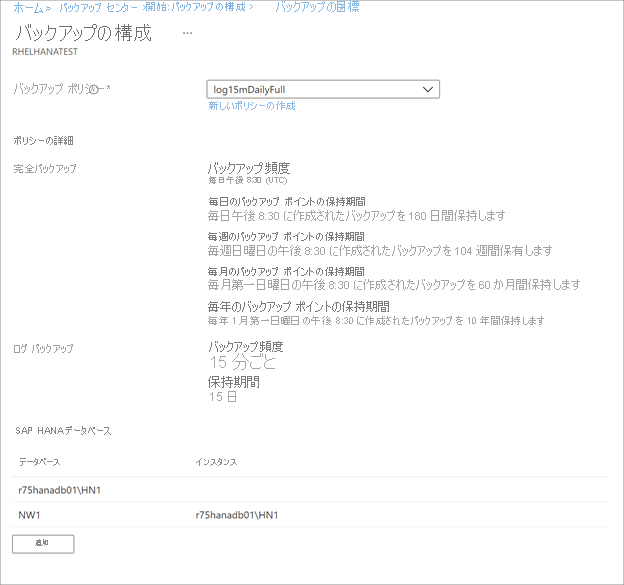
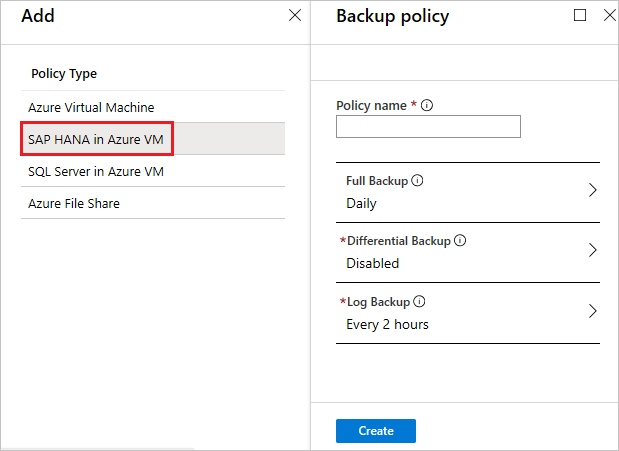
[バックアップ ポリシー]>[バックアップ ポリシーの選択] で、以下の手順に従って、データベースの新しいバックアップ ポリシーを作成します。
ポリシーを作成した後、
** [バックアップ] メニュー** の** [バックアップの有効化]** を選択します。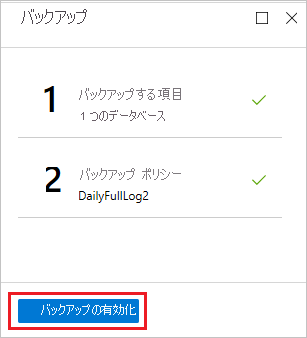

バックアップ ポリシーの作成
バックアップ ポリシーでは、バックアップが取得されるタイミングと、それらが保持される期間を定義します。
- ポリシーはコンテナー レベルで作成されます。
- 複数のコンテナーでは同じバックアップ ポリシーを使用できますが、各コンテナーにバックアップ ポリシーを適用する必要があります。
Note
Azure Backup では、Azure VM で実行されている SAP HANA データベースをバックアップしている場合、夏時間変更に合わせた自動調整は行われません。
必要に応じて手動でポリシーを変更してください。
次のように、ポリシー設定を指定します。
[ポリシー名] に新しいポリシーの名前を入力します。 この場合は、「SAPHANA」と入力します。
[Full Backup policy](完全バックアップのポリシー) で、 [バックアップ頻度] を選択します。 [Daily](毎日) または [毎週] を選択できます。 このチュートリアルでは、 [Daily](毎日) バックアップを選択しています。
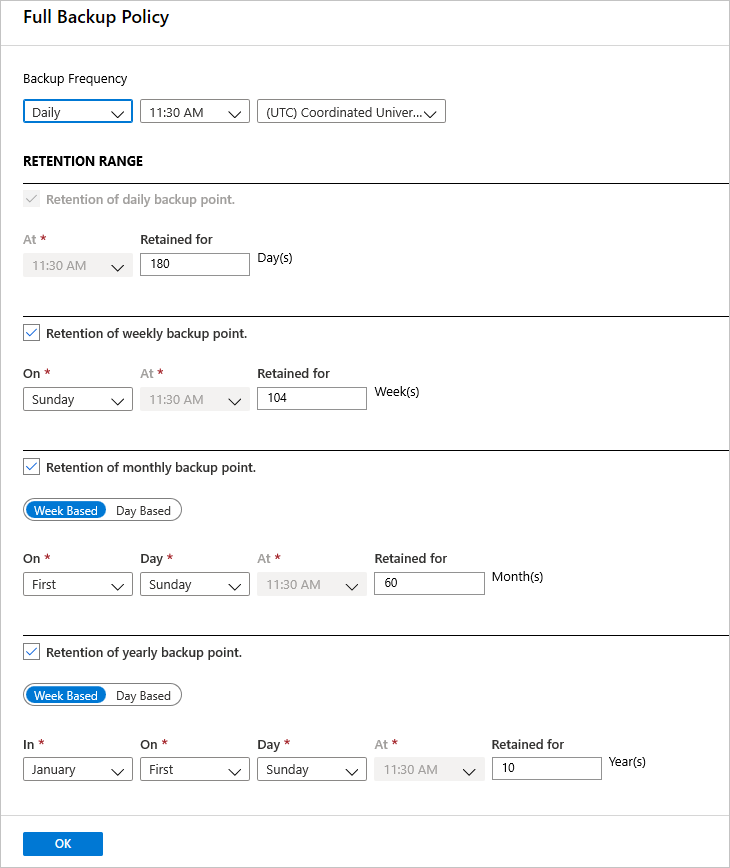
[リテンション期間] で、完全バックアップのリテンション期間の設定を構成します。
- 既定では、すべてのオプションが選択されています。 使用しない保持期間の制限をすべてクリアして、使用するものを設定します。
- あらゆる種類のバックアップ (完全、差分、ログ) の最小保持期間は 7 日間です。
- 復旧ポイントは、そのリテンション期間の範囲に基づいて、リテンション期間に対してタグ付けされます。 たとえば、日次での完全バックアップを選択した場合、日ごとにトリガーされる完全バックアップは 1 回だけです。
- 特定の曜日のバックアップがタグ付けされ、週次でのリテンション期間と設定に基づいて保持されます。
- 月次および年次のリテンション期間の範囲でも、同様の動作になります。
完全バックアップのポリシー メニューで、 [OK] を選択して設定を確定します。
次に、 [差分バックアップ] を選択して、差分ポリシーを追加します。
差分バックアップのポリシーで、 [有効] を選択して頻度とリテンション期間の制御を開きます。 ここでは、毎週日曜日の午前 2:00 に実行され、30 日間保持される差分バックアップを有効にしました。
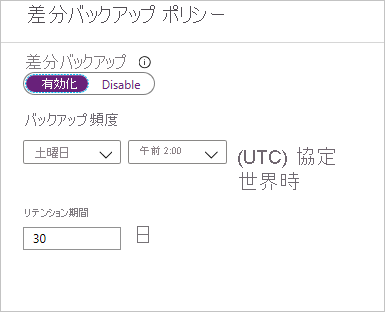
Note
毎日のバックアップとしては、差分バックアップまたは増分バックアップのどちらかを選択できます。両方を選択することはできません。
[増分バックアップ ポリシー] で、 [有効] を選択して頻度と保有期間の制御を開きます。
- 最多で、1 日に 1 回の増分バックアップをトリガーできます。
- 増分バックアップは、最大 180 日間保持できます。 より長いリテンション期間が必要な場合は、完全バックアップを使用する必要があります。
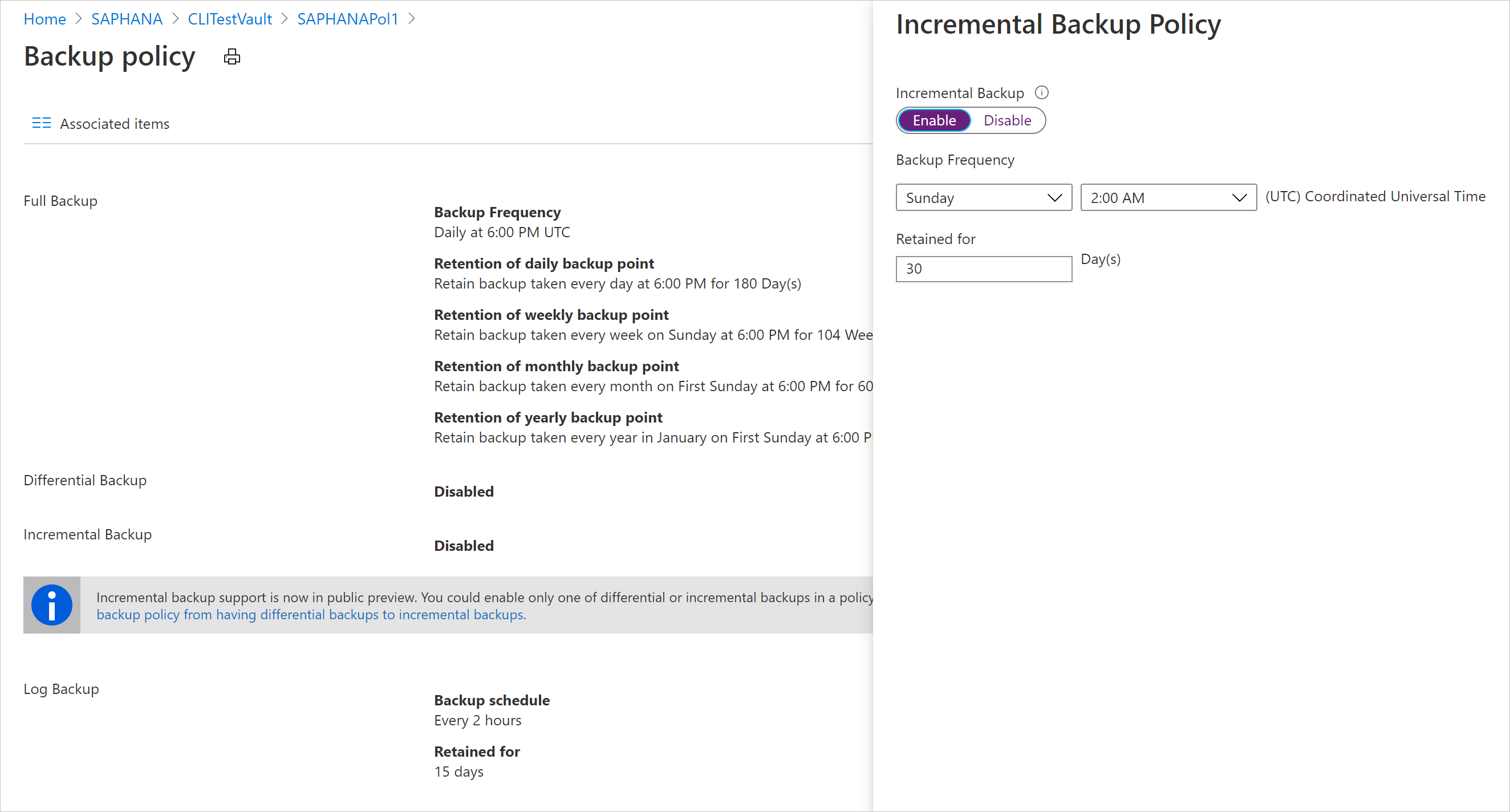
[OK] を選択してポリシーを保存し、 [バックアップ ポリシー] のメイン メニューに戻ります。
[ログ バックアップ] を選択し、トランザクション ログ バックアップ ポリシーを追加します。
- [ログ バックアップ] は既定で [有効] に設定されています。 SAP HANA ではすべてのログ バックアップが管理されるため、これを無効にすることはできません。
- ここでは、バックアップのスケジュールとして 2 時間を設定し、保持期間として 15 日間を設定しています。
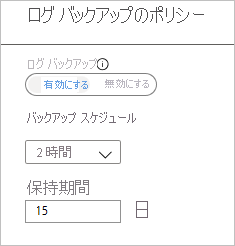
Note
ログ バックアップでは、1 回の完全バックアップが正常に完了した後にのみ、フローが開始されます。
[OK] を選択してポリシーを保存し、 [バックアップ ポリシー] のメイン メニューに戻ります。
バックアップ ポリシーの定義が完了した後、 [OK] を選択します。
これで、SAP HANA データベースのバックアップが正常に構成されました。