ユーザー エクスペリエンスを設計する
この記事の対象: SDK v4
テキスト、ボタン、画像、カルーセルまたはリスト形式で表示されるリッチ カードなど、さまざまな機能を備えたボットを作成できます。 ただし、Facebook、Slack などの各チャネルは、最終的にメッセージング クライアントが機能をレンダリングする方法を制御します。 ある機能が複数のチャンネルでサポートされていても、その機能をレンダリングする方法は、チャンネルごとに若干異なる可能性があります。 チャンネルがネイティブにサポートしていない機能がメッセージに含まれている場合、チャンネルはメッセージのコンテンツをテキストや静的な画像としてダウンレンダリングしようとする場合があり、クライアント上でのメッセージの外観に大きな影響を及ぼす可能性があります。 チャンネルが特定の機能をまったくサポートしない場合もあります。 たとえば、GroupMe クライアントでは入力インジケーターを表示できません。
リッチ ユーザー コントロール
リッチ ユーザー コントロールは、ボタン、画像、カルーセル、メニューなど、ボットがユーザーに提供する一般的な UI コントロールで、ユーザーはこのコントロールを使って選択肢や意図を伝えます。 ボットは UI コントロールのコレクションを使用してアプリを模倣したり、アプリ内に埋め込まれた状態で実行したりすることもできます。 アプリや Web サイトに埋め込まれているボットは、そのボットをホストしているアプリの機能を使用して、すべての UI コントロールを仮想的に表すことができます。
アプリケーションや Web サイトの開発者たちは、ユーザーがアプリケーションを操作できるように UI コントロールを活用してきました。 これらと同じ UI コントロールは、ボットでも有効です。 たとえば、単純な選択肢をユーザーに表示するには、ボタンが便利です。 [ホテル] というラベルの付いたボタンを選択してユーザーが 「ホテル」 と通信できるようにすれば、ユーザーに 「ホテル」と入力することを強いるよりも簡単かつ迅速です。たとえばモバイル デバイスでは、多くの場合、文字を入力するよりも項目を選択することのほうが好まれます。
カード
カードを使用すると、さまざまなビジュアル、オーディオ、選択可能なメッセージをユーザーに提示できるため、会話フローのサポートに役立ちます。 固定された項目セットからユーザーが選択する必要がある場合は、カードのカルーセルを表示できます。そのカードそれぞれに、画像、テキストの説明、および 1 つの選択ボタンが含まれています。 1 つの項目に対して一連の選択肢がある場合は、小さな 1 つの画像とボタンのコレクションを表示し、選択できるさまざまなオプションを示すことができます。 あるテーマについてさらに詳しい情報が求められた場合は、 カードによって、オーディオまたは動画出力を使った詳細情報や、ショッピングの明細を示す領収書を提供できます。 カードには、ユーザーとボットの間の会話を支援する非常に広範な用途があります。 使用するカードの種類は、アプリケーションのニーズによって決まります。 カードとそのアクション、および推奨されるいくつかの用途を詳しく見ていきましょう。
Azure AI Bot Service のカードはプログラミング可能なオブジェクトで、さまざまなチャネルで認識されるリッチ ユーザー コントロールの標準化されたコレクションが格納されています。 次の表は、使用可能なカードの一覧です。また、各種カードの用途のベスト プラクティスも提案しています。
| カード タイプ | 例 | 説明 |
|---|---|---|
| AdaptiveCard | 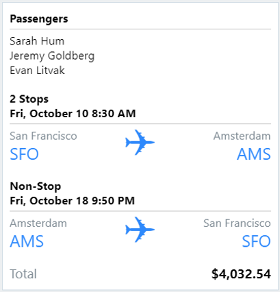
|
JSON オブジェクトとしてレンダリングされるオープン カード交換形式。 通常はクロスチャネルのカード展開に使用されます。 カードは各ホスト チャネルの外患に適合します。 |
| AnimationCard | 
|
アニメーション GIF または短い動画を再生できるカード。 |
| AudioCard | 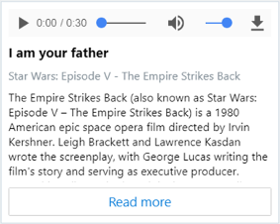
|
オーディオ ファイルを再生できるカード。 |
| HeroCard | 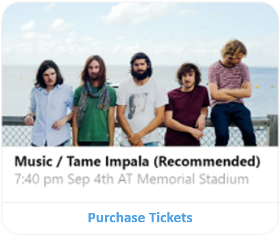
|
1 つの大きな画像、1 つまたは複数のボタン、およびテキストが含まれるカード。 通常は、ユーザーへの選択肢をビジュアルで強調表示するときに使用されます。 |
| ThumbnailCard | 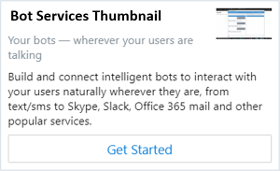
|
1 つのサムネイル画像、1 つまたは複数のボタン、およびテキストが含まれるカード。 通常は、ユーザーの選択肢を表すボタンをビジュアルで強調表示するときに使用されます。 |
| ReceiptCard | 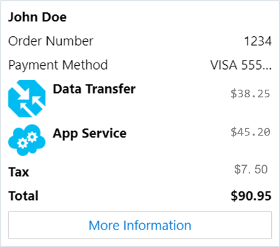
|
ボットからユーザーに領収書を提供できるようにするカード。 通常は、領収書に含める項目の一覧、税金と合計の情報、およびその他のテキストが含まれます。 |
| SignInCard | 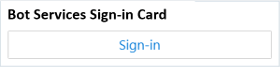
|
ユーザーがサインインできるようにするカード。 通常、テキストと、ユーザーが使用するとサインイン プロセスを開始できる 1 つ以上のボタンが含まれています。 |
| SuggestedAction | 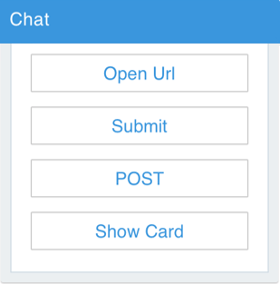
|
ユーザーの選択肢を表す一連のカード アクションをユーザーに示します。 提示されたアクションのいずれかが選択されると、ボタンは消えます。 |
| VideoCard | 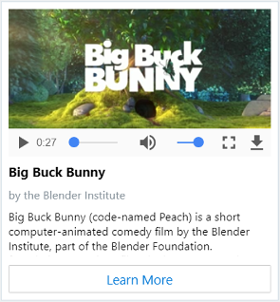
|
動画を再生できるカード。 通常は、URL を開いて、使用可能な動画をストリーミングするときに使用されます。 |
| CardCarousel | 
|
水平方向にスクロール可能なカード コレクション。これにより、一連の選択肢をユーザーが容易に表示できます。 |
カードを使用すると、ボットを一度設計するだけで、さまざまなチャネルで動作させることができます。 ただし、一部の種類のカードについては、一部のチャネルでは、まだ完全にはサポートされていません。
ボットにカードを追加する手順の詳細については、「リッチ カード メディアの添付ファイルの追加」と「メッセージへの推奨されるアクションの追加」を参照してください。
サンプル コードについては、Bot Framework サンプル リポジトリの次のサンプル ボットを参照してください。
サンプル 名前 説明 6 カードの使用 すべてのカード型の使用方法を示します。 7 アダプティブ カード アダプティブ カードの使用方法を示します。 8 推奨されるアクション 提示されたアクションの使用を示します。 15 Attachments ユーザー指定の添付ファイルを受け入れる方法を示します。
ボットを設計するときは、一般的な UI 要素を、十分にスマートではないという理由で反射的に無視してはいけません。 会話のユーザー エクスペリエンスで説明したように、ボットは、ユーザーの問題をできるだけ迅速かつ簡単に、そして効果的に解決するよう設計する必要があります。 まず、自然言語の理解を組み込むという誘惑を退けましょう。これは不要なことが多く、無意味な複雑さが増します。
ヒント
最初は、ボットがユーザーの問題を解決できるようにする最小限の UI コントロールを使用します。そして、そのコントロールでは不十分なときに、後から他の要素を追加します。
テキストと自然言語の理解
ボットはユーザーからのテキスト入力を受け入れ、正規表現の一致、または自然言語の理解 API を使って、その入力の解析を試みることができます。 自然言語の理解が適切なソリューションであるかどうかは、ユーザー入力の種類によります。
場合によっては、ボットがユーザーに特定の質問をすることがあります。 たとえば、ボットから "お名前は何ですか" と聞かれたユーザーは、"John" と名前だけ答えることも、"私の名前は John です" と文章で答えることもあります。
具体的な質問をすると、ボットに返されることが想定される妥当な答えの範囲が狭くなり、応答の解析および理解に必要なロジックの複雑さが減ります。 たとえば、"ご気分はいかがですか?" という自由回答式の大まかな質問について考えてみましょう。 このような質問に対して想定される答えの順列が多数であることを考えると、これを解釈する作業は複雑です。
これに対し、"痛みを感じますか? はい/いいえ"、"どこに痛みを感じますか? 胸/頭/腕/脚" といった具体的な質問ならば、自然言語の理解を実装しなくてもボットが解析および解釈できる、より具体的な応答を引き出すことができますす。
ヒント
自然言語の理解機能がなくても応答を解析できるよう、できる限り具体的な質問を行ってください。 これによりボットが簡素化され、ボットがユーザーの意図を解釈する可能性が大きくなります。
また、ユーザーが特定のコマンドをタイプ入力する場合もあります。 たとえば、開発者が仮想マシンを管理できるようにする DevOps ボットは、"/STOP VM XYZ"、"/START VM XYZ" など、特定のコマンドを受け入れるように設計されていることがあります。 このような特定のコマンドを受け入れるようにボットを設計すると、優れたユーザー エクスペリエンスを実現できます。構文が学習しやすく、コマンドごとに期待される結果が明確であるためです。 また、正規表現を使用してユーザー入力を容易に解析できるため、ボットには自然言語の解釈機能は必要ありません。
ヒント
ユーザーに対して特定のコマンドを要求するようにボットを設計すると、多くの場合、優れたユーザー エクスペリエンスを実現でき、自然言語の理解機能も不要になります。
ナレッジ ベース ボットまたは 質問と回答 ボットの場合は、ユーザーが一般的な質問を行う場合があります。 たとえば、何千ものドキュメントの内容に基づいて質問に答えることができるボットを想像してみてください。 Azure AI services と Azure Search は両方とも、この種類のシナリオ専用に設計されたテクノロジです。 詳細については、「ナレッジ ボットを設計する」と「言語理解」を参照してください。
ヒント
データベース、Web ページ、またはドキュメントからの構造化データまたは非構造化データに基づいて質問に答えるボットを設計する場合は、自然言語の理解によって問題の解決を試みるのではなく、このシナリオに対応するように特別に設計されたテクノロジを使用することを検討してください。
また別のシナリオでは、ユーザーが自然言語に基づいた単純な要求をタイプ入力することがあります。 たとえば、ユーザーが "ペパロニ ピザが食べたい" または "自宅から 3 マイル以内に、営業中のベジタリアン レストランはありますか?" と入力する場合があります。 自然言語の理解 API は、このようなシナリオに最適です。
この API を使用すると、お使いのボットでユーザーのテキストの主要コンポーネントを抽出して、ユーザーの意図を特定できます。 ボットに自然言語の理解機能を実装する場合は、ユーザーが入力すると思われる詳細レベルに合った現実的な期待値を設定します。
ヒント
自然言語モデルを構築するときは、ユーザーが最初のクエリで、必要な情報すべてを入力することを想定しないでください。 必要な情報を具体的に要求するようにボットを設計してください。ボットが必要に応じて質問を行うことで、ユーザーがそういった情報を入力するよう誘導するのです。
音声
ボットでは音声入出力を使用して、ユーザーとやり取りできます。 キーボードやモニターがないデバイスに対応するようにボットが設計されている場合、ユーザーとやり取りするには音声を使うしかありません。
リッチ ユーザー コントロール、テキスト、自然言語、および音声のどれを選択するか
人がジェスチャ、声、記号を組み合わせて互いにコミュニケーションを取り合うように、ボットとユーザーのやり取りには、リッチ ユーザー コントロール、テキスト (自然言語を含む場合があります)、および音声の組み合わせを使用できます。 これらのコミュニケーション方法は一緒に使用できるため、特にどれか 1 つを選択する必要はありません。
たとえば、レシピを提供する "料理ボット" があるとします。このボットでは、動画の再生や一連の画像を表示して手順を提供し、必要な作業について説明します。 レシピを実行しながら、レシピのページをめくるのを好むユーザーもいれば、音声でボットに質問したいユーザーもいるでしょう。 また、音声ではなく、デバイス画面をタッチしてボットを操作したい人もいるかもしれません。 ボットを設計するときは、サポートしようとしている特定のユース ケースを考慮して、ボットとのやり取りでユーザーが好みそうな方法に対応した UX 要素を組み込みます。