クラウド監視サービス レベルの目標
この記事は、クラウド監視ガイドのシリーズの一部です。
以下のセクションでは、サービス レベル目標の基本的な原則と、それらを実装して適用する方法について説明します。
概要
サービス レベル目標 (SLO) とは、主要な顧客中心のサービス レベル指標 (SLI) に対して設定された測定可能な目標です。 これらは、ビジネスまたはインフラストラクチャ ワークロードの顧客のエクスペリエンスを測定し、ビジネス サービスの提供者が、正式に交渉されたサービス レベル アグリーメント (SLA) またはすべての当事者間の非公式な合意内で行われた約束を守っているどうかを判断します。
お客様はサービス ブローカーとして、Microsoft の Azure サービスに関するサービス レベル アグリーメントで定義されているサービスの信頼性に対する Microsoft の積極的な取り組みを信頼しています。 これにより、お客様は総合的監視、ネットワーク接続、セキュリティとコンプライアンスなどのサービス チェーン内の自分の責任に集中できます。
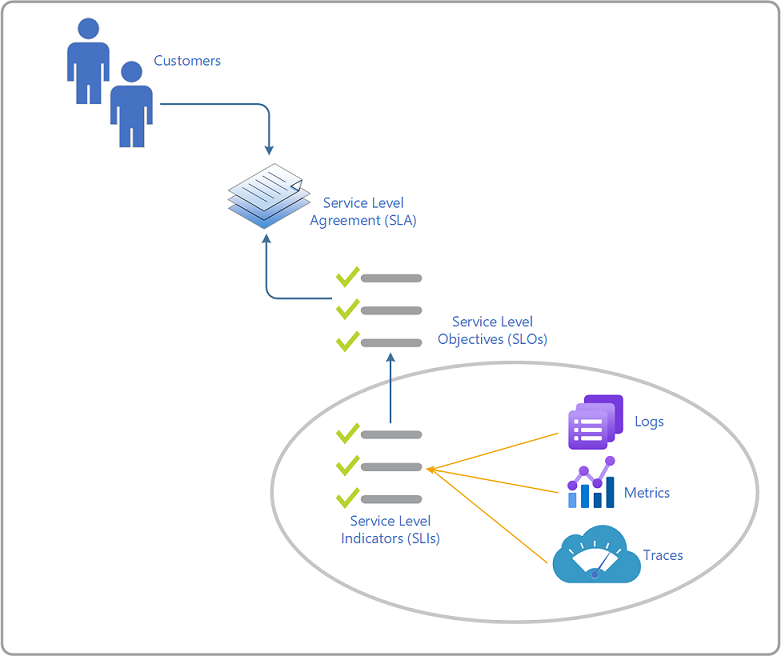
用語
以下に、これらの各用語の定義と簡単な説明を示します。 これらの定義は、Google の SRE ハンドブックから引用されています。
| 用語 | 説明 |
|---|---|
| サービス レベル アグリーメント (SLA) | 通常はサービス プロバイダーと顧客の間の拘束力のあるコミットメントです。 契約には通常、SLO ターゲットが未達成だった場合の結果が含まれます。 サービスの具体的な側面には、サービス プロバイダーとサービス利用者との間で合意される品質、可用性、責任があります。 |
| Monitoring | サービスとシステムに関する定量的でリアルタイムなデータの収集の実践。 |
| Metrics | 関連するサービスの動作を測定し、サービス レベル指標 (SLI) へと集計できます。これらは、処理、集計されて、サービスの現在の動作状態を測定し、その動作を定量化します。 SLI は、サービスの現在の正常性を示す主要なリアルタイム指標です。 |
| ログ | コードから始まり、コード パスの個々の実行、または個別のイベントに関する情報を報告します。 この情報を使用して、トラブルシューティングに役立て、SLI/SLO によって測定されるカスタマー エクスペリエンスとサービスの信頼性に影響を与える根本原因の問題の特定に取り組みます。 |
| サービス レベル目標 (SLO) | サービス レベルの目標値であり、サービス レベル指標 (SLI) によって測定され、サービスのパフォーマンスがどれだけ良いかに関する期待値を設定します。 SLO は特に、エンド ツー エンドのカスタマー エクスペリエンスを追跡します。 良好な SLO を確立するには、通常は、まず求められているエクスペリエンスを定義し、次にサービス コードをインストルメント化して、そのエクスペリエンスを測定 (関連する SLI を収集) し、どれだけ顧客の期待に応えられているかいないかの目標を設定します。 |
| サービス レベル指標 (SLI) | サービスの品質または信頼性を定量化するメトリックです。 少なくとも 4 つ の一般的な SLI (可用性、待機時間、スループット、エラー率) が評価されます。 |
| 可用性 | 一般に、測定可能または観測可能なシステムが動作および機能している時間の割合を意味します。 可用性は、エクスペリエンスの継続性についての顧客向けの目標値として測定します。これは 1 つ以上の信頼性の問題 (および、構成変更や適用される更新などに関連するその他の障害モード) の影響を受けます。 |
| エラー予算 | SLO に関する残りのバッファーの割合。 エラー予算は、DevOps と IT がサービスの信頼性とイノベーションのペースとのバランスを取るために使用するツールです。 |
SLO の目的
SLO は、クラウド ワークロードの開発と運用において、次のような多くの重要な目的を果たします。
- 準リアルタイム (NRT): 顧客が経験しているとおりの、サービスの正常性に関する NRT ビューを提供します。
- 通知時間の短縮 (TTN): 顧客に対するサービスの問題の自動通知を推進し、通知時間 (TTN) を大幅に短縮します。
- 顧客への主要なシグナル: デプロイ操作の主要なシグナルとして機能し、問題が発生した場合に自動ロールバックを起動することで、起こり得る問題にさらされる顧客を少なくします。
- 変更の検証: 変更によって期待されるカスタマー エクスペリエンスの向上が達成されたことの検証を提供します。
- 優先順位の決定: 機能を構築するか信頼性に取り組むかをチームが理解できるように支援します。
- サービスの正常性の分析情報: サービスの正常性に関する客観的で顧客中心のディスカッションを可能にします。
- 分析時間の短縮: 原因となったサービスに焦点を当てることで、顧客の問題の軽減と根本原因分析 (RCA) を迅速化します。
- アーキテクチャ依存関係: サービスに依存関係が生じる場合に、アーキテクチャに関する決定への重要な入力情報として機能します。
- 信頼の構築: 正常性の測定に関する共通の理解を提供し、チーム間の信頼を構築します。
- 透明性の提供: Microsoft がビジネスの運営に使用しているものと同じ SLI をお客様に公開し、お客様が自身のビジネスを運営できるようにします。
- 1 つのウィンドウ ガラス: サービスとその依存関係を横長の 1 つのウィンドウ ガラスで見渡せるようにし、サイロを解体します。
SLO を使用してエンジニアリング プロセスを推進することで、DevOps と IT 部門が、Azure で構築または移行するアプリケーションまたはインフラストラクチャ サービスの "正常性" を早期に把握できます。 これを利用して、これらのサービスの信頼性に関して行う必要がある、人間と自動化の両方による決定を促進できます。 エンジニアリング手法におけるこの変革は、近い将来それらのサービスの信頼性に重大な影響を与えます。
SLO を定義する方法は?
SLO の目的は、顧客の観点から品質を正確に測定する、明確なシグナルを得ることです。 各サービス チームは、サービス コンシューマーの経験に従って、サービスの最も重要で測定可能なメトリックの許容範囲を定義する、少数のサービス レベルの目標 (SLO) を作成します。 SLO は、サービスによって生成されるメトリックに関して定義される数値目標です。 この目標に関連するメトリックを監視して、サービスが正常かどうかを判断できます。
たとえば、社内の時間追跡 Web ベース アプリケーションに関する SLO の簡略化された例としては "直近 5 分間の要求が 99 パーセンタイルで 1000 ミリ秒未満で処理されている" などがあります。
このメトリックは、サービス レベル指標 (SLI) と呼ばれる時系列データの集計です。 SLI がどこに収集されるかが重要です。 上記の例において、顧客が API を使用してサービスとやり取りする場合、システムの待機時間と要求の処理時間の測定が正確な SLI です。 しかし、顧客が Web ポータルを使用してサービスを操作する場合、要求の合計処理時間には Web ページの JavaScript のパフォーマンスも含める必要があります。
サービスの所有者が最も重要視すべきなのは、以下の判断です。
- どのシナリオが、顧客の観点から見てサービスの正常性の重要な指標であるか。
- どこに SLI を収集することで、それらを可能な限りカスタマー エクスペリエンスに近づけることができるか。
- これらの SLI に対応する SLO は何か?
SLO は、達成を促すような段階的なアプローチで定義することも、企業が直接規定することもできます。 サービスによって定義された SLO を使用して、それらをどのように構築するかに関するアーキテクチャ上の決定を行います。 そのため、どのシナリオを測定するか、およびどの期間にわたってそれらを測定するかを慎重に選択することが重要です。 まとめとして、SLO は次の値で構成されます。
- SLI。 たとえば、ロード バランサーによって測定される、十分に高速な要求のサイズは 400 ミリ秒未満です。
- 期間。 メトリックが測定される期間。
- 目標。 たとえば、特定の期間中に満たすと期待される要求の合計に対する高速な要求の目標パーセンテージ (90% など) です。
SLO の種類
業界全体では、次の 2 種類の SLO が存在します。
サービス中心の SLO - これらの SLO は、チームが時間の経過と共にサービスの品質を徐々に向上させるために定義する戦術的な目標です。 これらは、エンジニアリングのマイルストーンの中の達成できる実用的な目標となるように設計します。 たとえば、サービスが現在 99.7% の可用性を達成している場合、チームは次の四半期に 99.9% の可用性を達成するという目標を設定できます。
顧客中心の SLO - これらの SLO は、理想的な将来の状態または目標を定義します。 この時点で、顧客の期待に完全に応えているので、品質へのさらなる投資は不要と思えるでしょう。
たとえば、運用されているビジネスまたはインフラストラクチャのサービスが 99.99% の可用性を達成することを顧客が期待していて、そのサービスが現在 99.8% の可用性しか達成していない場合、顧客中心の SLO は変わらず 99.99% です。
適切な SLO を定義するには時間がかかります。 最初の手順は、顧客と話し合い、ユーザーがサービスから求めるものを理解して、少数の指標を選び出して、それを文書化することです。 顧客がサービスをどのように使用するかに関するシナリオと許容度、および顧客の事業運営を成功させるためにサービスが何を提供する必要があるかを確認します。 これは一般的に反復的なエクスペリエンスであり、期待される内容としては、"どのような条件のもとでも収益源への一切の影響なしで 100% の可用性を望む" という声から、顧客セグメント間で大きく変動する期待に対応する、といったものまで、さまざまです。
サービス (またはサービス インスタンス) の正常性のみに注目する監視アプローチは、スペクトルの両端でカスタマー エクスペリエンスの問題を見落としがちになります。サービスの正常性は、常にカスタマー エクスペリエンスの品質と関連するとは限りません。 これの原因は、Azure PaaS サービスと SaaS サービスの間には、これらの Azure サービスの構成、リソースがデプロイされる方法と場所 (つまり、どのリージョンにデプロイされるか)、複雑性をさらに増加させるカスタム コード/ロジックの追加など、異なる動作特性が存在することです。
SLO を定義する際には、お使いのクラウド プロバイダーは SLA における依存物であることを覚えておくことが重要です。 その各サービスに対して指定されたサービス レベル アグリーメントを考慮します。 Azure については、「オンライン サービスのサービス レベル アグリーメント (SLA)」を参照してください
SLI を定義する方法
SLI 仕様は、待機時間や可用性など、サービスの特定の信頼性要素に関するユーザーの期待を公式に述べたものです。
最初は、測定と収集に適したメトリックを選択するというシンプルな形で始め、重要でないメトリックを多く収集して複雑にしすぎないようにします。 定義する SLI がカスタマー エクスペリエンスと直接関連するようにしてください。 これが、ユーザーの観点を理解して、わずかな数の指標から始めることが重要な理由です。
サービスに何らかの形でリソース (メモリや CPU など) の制約がある場合、その飽和状態も優れた SLI になる可能性があります。 ただし、飽和状態はユーザー エクスペリエンスの低下に直接対応するわけではないため、SLO として使用するべきではありません (サービスでメモリ使用率が高くても、ユーザーは影響を受けない可能性があります)。
作成する指標は 3 つを超えないことをお勧めします。 指標が 3 つを超えても、重要な価値が加わることはめったにありません。 多くの場合、指標の数が過剰であることは、主要な指標の症状を含めていることを意味している可能性があります。 トラフィックと飽和状態は、それら 3 つの主要指標への補足とするべきです。これらはサービスの負荷を表し、他のサービス指標の解釈に役立つからです。
SLO を実装する方法
最も重要な SLI は、顧客の観点からのサービスへの影響を最も明確に表すものです。 多くのサービスにおいて、これには待機時間、スループット、エラー率、可用性が含まれます。 サービスにカスタマー エクスペリエンスに影響する何か特別な考慮事項がある場合は、それらの分野の SLI も測定する必要があります。 たとえば、メッセージング サービスのエンド ツー エンドの処理待機時間はカスタマー エクスペリエンスの直接的な指標であり、SLI の対象とするべきです。
SLO の例
人事部は、社内の時間追跡 Web ベース アプリケーションを現代化し、それを IT 企業の支援を受けて Azure クラウドでホストしたいと考えています。 引き続きそのサービスを組織内のすべてのユーザーが利用できるようにしたいため、以下を必要としています。
- 時間の経過に伴う使用状況レポートとサービスを使用しているユーザーの数。
- 可用性、パフォーマンス、セキュリティ、コンプライアンス (サービス保証) などの定期的な稼働状況の監視。
- サービスの毎月のコストなどのコスト。
- サイバーセキュリティ (ゼロ トラスト セキュリティ戦略に従ってリソースとデータへのアクセスを制御するという観点で)。
上に示したこれらの例からわかるように、SLO/SLI のカテゴリと例は、サービスの設計の早い段階で定義する必要があります。 これは、これまで作成してきたオンプレミスのサービスと何ら異なることはありません。
SLO 表/SLI カテゴリ
以下の例は、すべてを含む一覧というわけではありません。 信頼性と保守容易性の SLO が何十年にもわたってシステムの品質証明となってきましたが、サイバーセキュリティ、品質とユーザー エクスペリエンス、コストに関する測定値を含む SLO も定義できます。
サービス
サービスまたはシステムの典型的な高レベル測定値は、通常、サービス契約で成文化されます。 大多数の現代的な契約では、可用性を主要な SLO として測定し、主要なワークロード項目または運用単位 (認証トークン、メールボックス、ストレージ アカウントなど) に基づく単純なダウンタイム測定を使用します。
| カテゴリ | 説明 | 例 |
|---|---|---|
| 可用性 | 単純なダウンタイム、またはメンテナンスの平均間隔または操作の可用性 (MTBM/(MTBM+MDT)) | 1 か月で 99.99% |
| 容量 | 十分な、最大限の、または最適なビジネスおよびサービスのパフォーマンス、スループット、ストレージ、人員、帯域幅、要求、リソース、サービス関数を確保します。 トリガーとして機能する労働力と時間の制限を含みます。 | 使用率の % (CPU、ストレージ、メモリ、待機時間、スループット、スケーリング) |
| セキュリティ | ビジネス、資産、データに損害を与える可能性がある、または与えている実際の脅威と脆弱性 (内部および外部)。 | HAFNIUM 脅威の検出 |
| コンプライアンス | 更新プログラム、サービス レベル、コンプライアンス強化、必要な構成の誤差 | すべての資産で更新プログラム提供が 99.5% |
| 継続性 | 大規模な災害や外部イベントが発生しても存続し、そこから復旧できる。 | 時間 (再構成) |
| Quality of Service (QoS) | 時間の経過に伴うユーザーの実際のエクスペリエンスの特性。 | Teams の通話の品質 - 受信パケットの損失 <2% |
[信頼性]
従来の SLO である信頼性が示すのは、障害とフェールオーバーに対する、システム、サービス、リソース、またはコンポーネントの経時的な信頼性、耐久性、品質の度合いであり、稼働時間や可用性の向上を目的として障害に対処するために適用される管理上の取り組み (冗長性の組み込みやコンテンツ配信ネットワークの追加など) も含まれます。 また、SLO の測定に使用されるデータの精度、忠実性、整合性、信頼性も意味する場合があります。 これは、温度ストレスなど、指定の条件下でシステムが意図した機能を実行するという、従来の "確率" を意味する場合があります。 回復力には、スケーリング、クール ダウン、負荷分散、復旧、想定外の要求、強いストレス下でのパフォーマンスの低下などの適応力を提供する組み込みの設計要素や機能、さらに、より大規模な災害での継続性のための設計 (通常は個別の SLO) も含まれます。
| カテゴリ | 説明 | 例 |
|---|---|---|
| 失敗率 | 総稼働時間に対する失敗の数 | 973 時間中 5 件の失敗では .00514 |
| 平均故障間隔 (MTBF) | MTBF は失敗率の逆です | 194.6 時間 |
保守容易性
インシデントや問題の管理などの IT サービス マネジメント プロセスのサポート SLO を信頼性 SLO と組み合わせることで、可用性を測定できます。
| カテゴリ | 説明 | 例 |
|---|---|---|
| サービス インシデントのパフォーマンス | カテゴリ、製品、または優先度ごと。 | インシデント ライフサイクルの各フェーズの時間とコストの測定値。 |
| セキュリティ インシデントのパフォーマンス | カテゴリ、製品、または優先度ごと。 | インシデント ライフサイクルの各フェーズの時間とコストの測定値。 |
| コンポーネントの平均修復時間 (MTTR) | イベント検出から復元または修復まで。 | |
| メンテナンスの平均間隔 (MTBM) | 通常の運用作業が発生する予防アクションを含む、すべてのメンテナンス アクションの時間間隔の中間値または平均値。 | 「メンテナンス遅延時間」を参照 |
| メンテナンス遅延時間 (MDT) | 検出から復旧までの合計時間 (輸送や管理の遅延を含む)。 | 注文、出荷、取り付けを含む、ハードウェアを交換する時間。 |
カスタマー エクスペリエンス
| カテゴリ | 説明 | 例 |
|---|---|---|
| スループット | 時間の経過に伴った、システムにかかるワークロードまたは運用上の負荷の量、割合、または速度。 | 単位時間あたりのトランザクション。 |
| エラー率 | 全体のエラーの数を示すパーセンテージ。 | セキュリティ イベントの % |
| 待機時間 | 入力から出力までの、プロセス中における作業の移行の、またはアプリケーションからユーザーへの時間または遅延の測定値。 | 平均秒数。 |
その他
| カテゴリ | 説明 | 例 |
|---|---|---|
| コスト | サービス、コンポーネント、または時間ごとに費用、課金、請求書を評価します。 | 資本経費や運営費用 |
| 対象範囲 | 管理 (コンプライアンス) のもとにあるコンポーネント、システム、サービスの割合 | コンプライアンス |
| フィードの信頼性 | ハートビートの障害、コネクタ、変更など。 | ミッション クリティカルな企業データの変更を追跡する。 |
| 生産性 | 生産性をもってタスクを実行できるかどうか | 労働力、従業員別の時間、アナリストの生産性。 |
考慮事項
アクセス権を確認する。 組織内のマネージャーや他のペルソナに、Azure Monitor 内で、または他の Azure サービス (特に Azure SaaS と PaaS) から利用できる視覚化へのアクセス権が付与されていることを確認し、重複が起きないようにします。
監視の対象範囲または "すべての資産の可視性" を確保する。 エージェント、出力されたログ、テーブル、管理してセキュリティで保護する必要があるすべての資産に対するクエリを確保し、対象範囲における "死角" またはギャップを特定して、SLO を現実性のあるものにします。
適切な利用者の前の正しいデータを取得します。 SLO と SLI の利用者が、基になるデータを解釈して、データから得た情報を使用して信頼を構築し、決定を導くことができるようにします。
無理のない約束をする。 SLO を "目標値" として設定する場合、特にコスト管理が重要な場合は、実際のシステム パフォーマンスが過剰だったり期待以下だったりしないようにするか、目標値を調整して顧客の期待にかなうようにします。
予期しない外部イベントを考慮する。 天候、停電、災害など、自分で制御できないイベントを考慮して、継続性の計画とリスク評価を策定します。
変更を考慮する。 サービスに対する変更や、技術的な信頼性、スループット、品質、保守容易性に対する変更 (サポート スタッフの削減など) を、SLO で考慮するようにします。
バランスの取れた SLO セットを提供する。 サービスまたはシステム上のバランスの取れた、または "360 度" の視点を提供し、信頼性に重点を置く、さまざまな SLO を確保します。