Azure Cosmos DB for PostgreSQL で Azure Data Factory を使用してデータを取り込む方法
適用対象: ![]() Azure Cosmos DB for PostgreSQL (PostgreSQL の Citus データベース拡張機能を利用)
Azure Cosmos DB for PostgreSQL (PostgreSQL の Citus データベース拡張機能を利用)
Azure Data Factory は、クラウドベースの ETL およびデータ統合サービスです。 データ ドリブン ワークフローを作成して、大規模なデータの移動と変換を行うことができます。
Azure Data Factory を使えば、さまざまなデータ ストアからデータを取り込むデータ ドリブン ワークフロー (パイプライン) を作成し、スケジューリングできます。 パイプラインは、オンプレミス、Azure、または他のクラウド プロバイダーで分析とレポートのために実行できます。
Data Factory には、Azure Cosmos DB for PostgreSQL 用のデータ シンクがあります。 データ シンクを使用すると、データ (リレーショナル、NoSQL、データ レイク ファイル) を Azure Cosmos DB for PostgreSQL テーブルに取り込んで、格納、処理、レポート作成を行うことができます。
重要
現時点で、Data Factory は Azure Cosmos DB for PostgreSQL のプライベート エンドポイントをサポートしていません。
リアルタイムの取り込みのための Data Factory
Azure Cosmos DB for PostgreSQL にデータを取り込むために Azure Data Factory を選ぶ主な理由を以下に示します。
- 使いやすい - データ移動を調整および自動化するためのコード不要のビジュアル環境を提供します。
- 強力 - 基になるネットワーク帯域幅の完全な容量を使用し、最大 5 GiB/秒のスループットを実現します。
- 組み込みコネクタ - 90 を超える組み込みコネクタを使用して、すべてのデータ ソースを統合します。
- コスト効率 - オンデマンドでスケーリングする、従量課金制のフル マネージド サーバーレス クラウド サービスをサポートしています。
Data Factory を使用する手順
この記事では、Data Factory ユーザー インターフェイス (UI) を使用してデータ パイプラインを作成します。 このデータ ファクトリのパイプラインでは、Azure Blob Storage からデータベースにデータをコピーします。 ソースおよびシンクとしてサポートされているデータ ストアの一覧については、サポートされているデータ ストアに関する表を参照してください。
Data Factory では、コピー アクティビティを使用して、オンプレミスやクラウド内のデータ ストアから Azure Cosmos DB for PostgreSQL にデータをコピーできます。 Data Factory を初めて使用するユーザー用に、使用を開始する方法に関するクイック ガイドを以下に示します。
Data Factory がプロビジョニングされたら、ご使用のデータ ファクトリに移動し、Azure Data Factory Studio を起動します。 次の画像のように [データ ファクトリ] ホーム ページが表示されます。
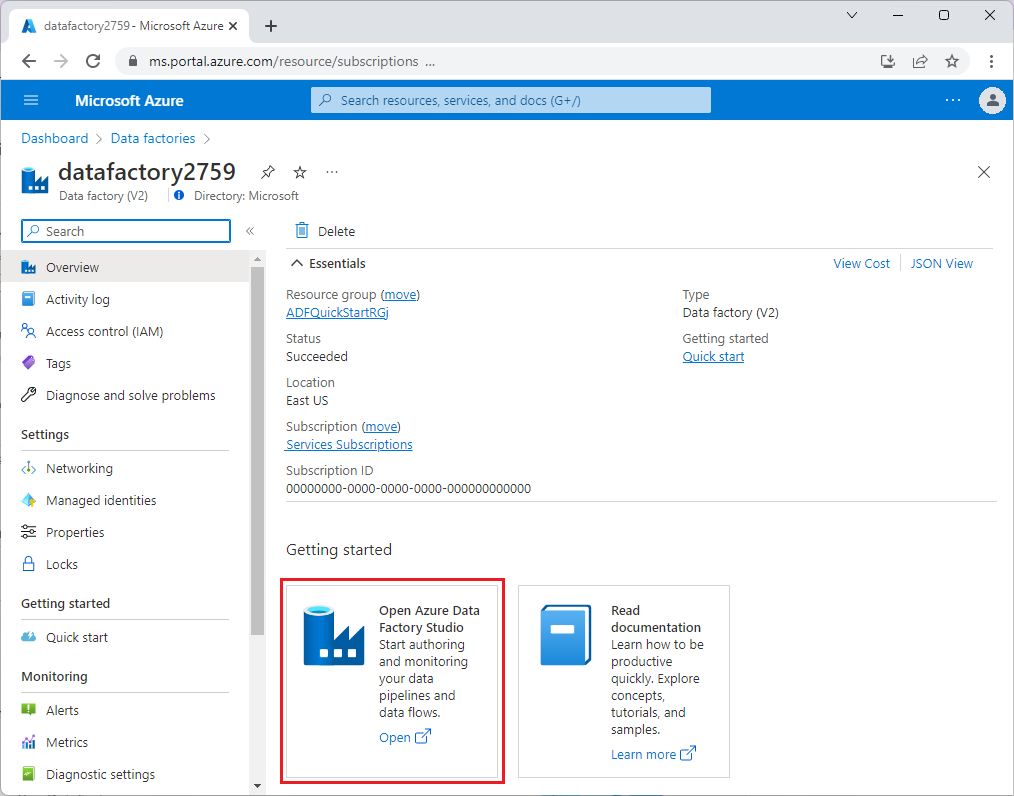
Azure Data Factory Studio のホーム ページで、[統制] を選択します。
![Azure Data Factory の [調整] ページを示すスクリーンショット。](media/howto-ingestion/azure-data-factory-orchestrate.png)
[プロパティ] で、パイプラインの名前を入力します。
[アクティビティ] ツールボックスで [移動と変換] カテゴリを展開し、パイプライン デザイナー画面に [データのコピー] アクティビティをドラッグ アンド ドロップします。 デザイナー ペインの下部にある [全般] タブで、コピー アクティビティの名前を入力します。
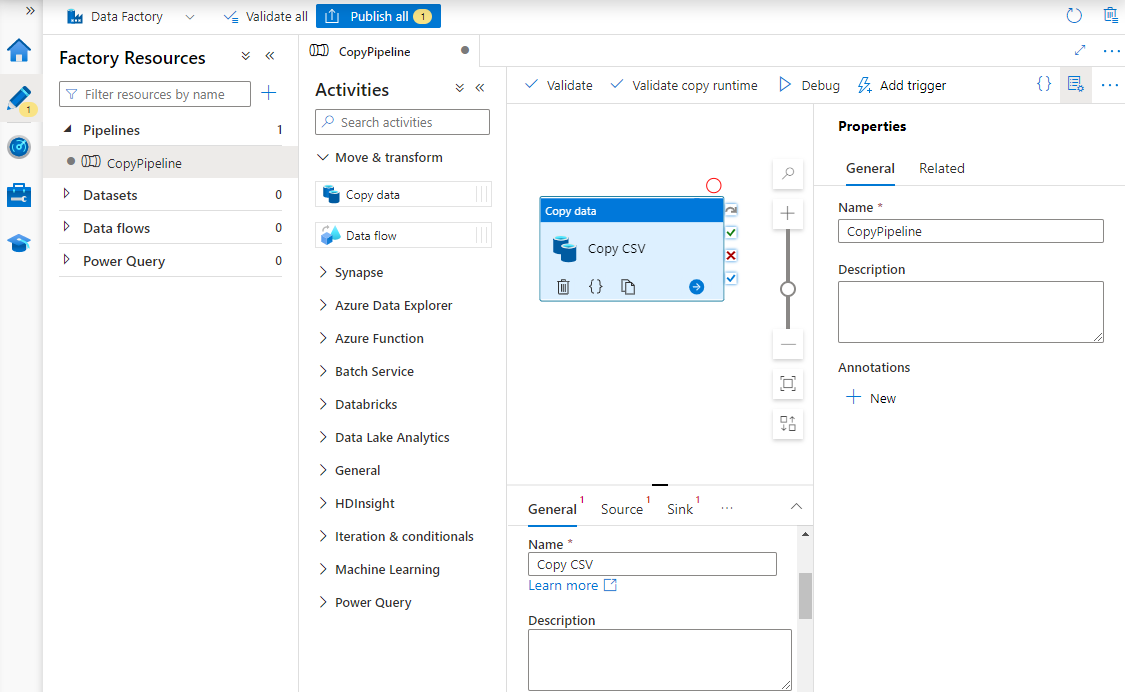
[ソース] を構成します。
[アクティビティ] ページで、[ソース] タブを選択します。[新規] を選択してソース データセットを作成します。
[新しいデータセット] ダイアログ ボックスで [Azure Blob Storage] を選択し、 [続行] をクリックします。
データの形式の種類を選択して、[続行] を選択します。
[プロパティの設定] ページの [リンクされたサービス] で、[新規] を選択します。
[新しいリンクされたサービス] ページで、リンク サービスの名前を入力し、[ストレージ アカウント名] の一覧からストレージ アカウントを選択します。
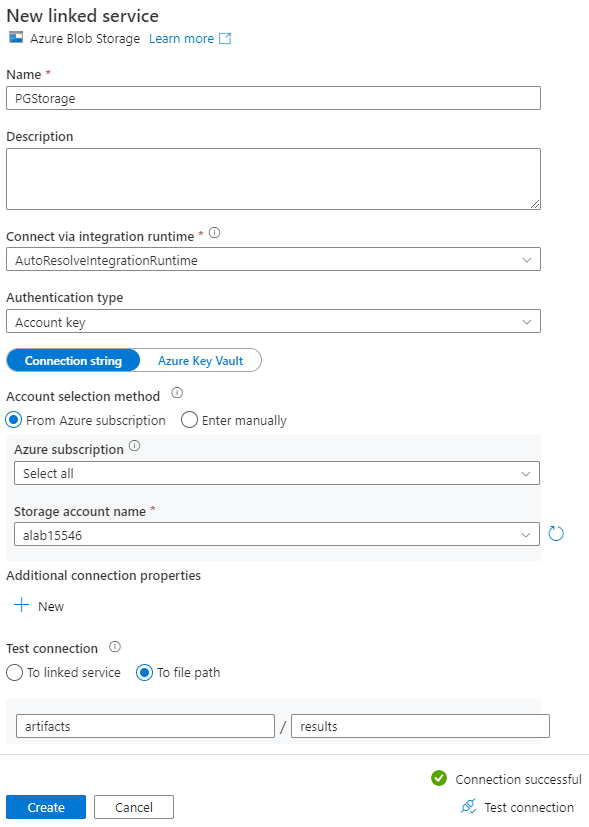
[テスト接続] で、[ファイル パスへ] を選び、接続するコンテナーとディレクトリを入力してから、[接続のテスト] を選択します。
[作成] を選択して構成を保存します。
[プロパティの設定] 画面で、[OK] を選択します。
[シンク] を構成します。
[アクティビティ] ページで、[シンク] タブを選択します。[新規] を選択してシンク データセットを作成します。
[新しいデータセット] ダイアログ ボックスで [Azure Database for PostgreSQL] を選択し、[続行] をクリックします。
[プロパティの設定] ページの [リンクされたサービス] で、[新規] を選択します。
[新しいリンク サービス] ページで、リンク サービスの名前を入力し、[アカウントの選択方法] で [手動で入力] を選択します。
[完全修飾ドメイン名] フィールドに、クラスターのコーディネーター名を入力します。 コーディネーターの名前は、Azure Cosmos DB for PostgreSQL クラスターの [概要] ページからコピーできます。
コーディネーターに直接接続するには、[ポート] フィールドで既定のポート 5432 のままにするか、ポート 6432 に置き換えて、マネージド PgBouncer ポートに接続します。
クラスターのデータベース名を入力し、それに接続するための資格情報を指定します。
[暗号化方法] ドロップダウン リストで、[SSL] を選択します。
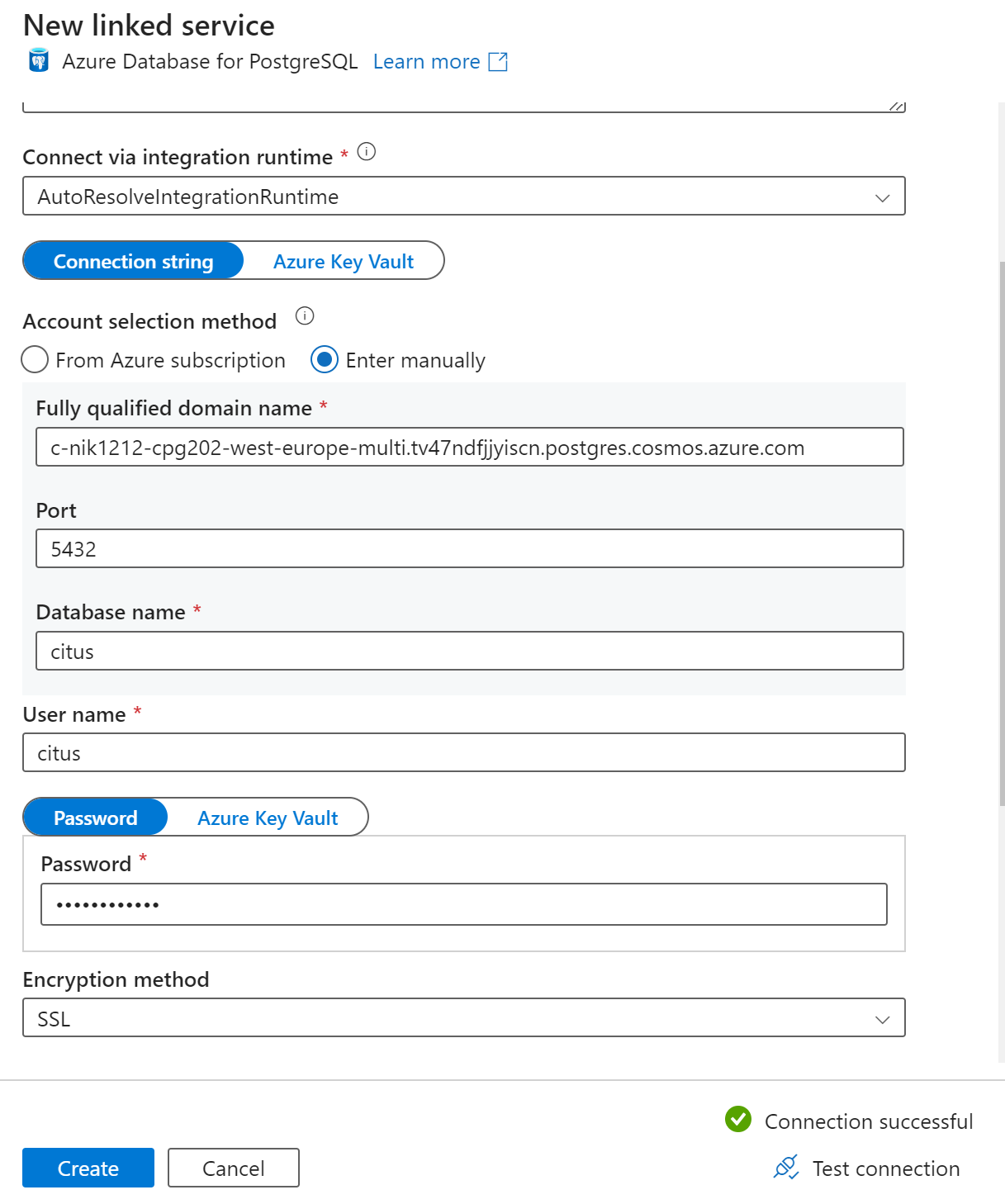
パネルの下部にある [テスト接続] を選択して、シンクの構成を検証します。
[作成] を選択して構成を保存します。
[プロパティの設定] 画面で、[OK] を選択します。
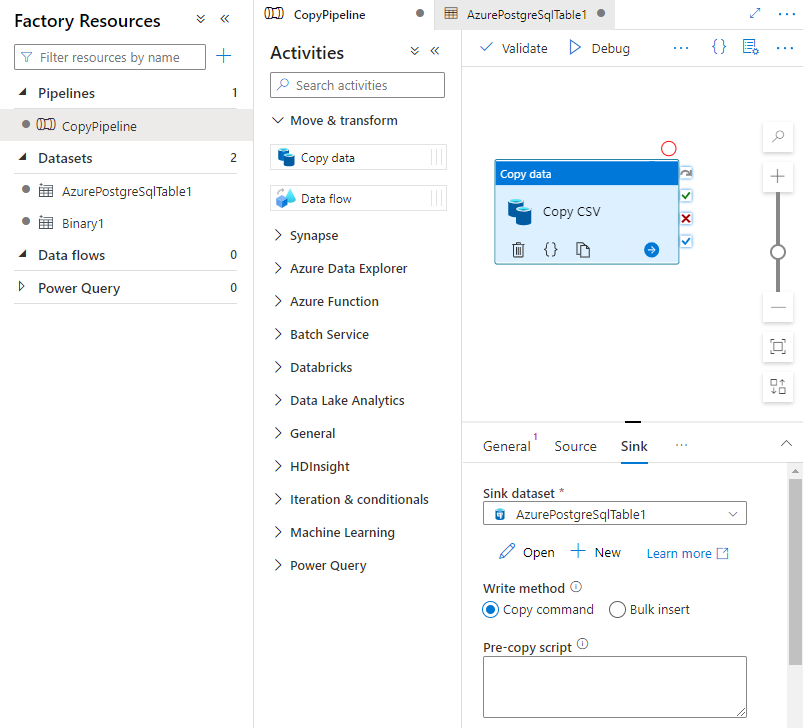
[活動] ページの [シンク] タブで、[シンク データセット] ドロップダウン リストの横にある [開く] を選択し、データを取り込む宛先クラスターのテーブル名を選択します。
[書き込みメソッド] で、[コピー コマンド] を選択します。
キャンバスの上にあるツール バーの [検証する] を選択して、パイプライン設定を検証します。 すべてのエラーを修正し、再検証して、パイプラインが正常に検証されたことを確認します。
ツール バーから [デバッグ] を選択し、パイプラインを実行します。
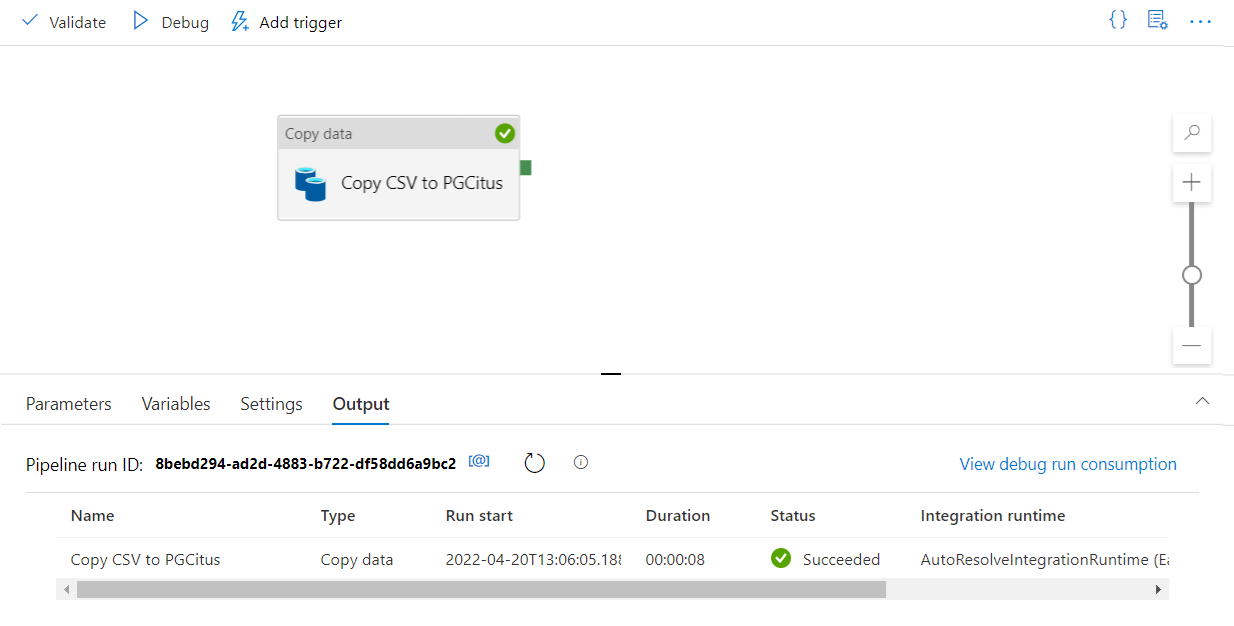
パイプラインを適切に実行できたら、上部のツール バーで [すべて発行] を選択します。 これにより、作成したエンティティ (データセットとパイプライン) が Data Factory に発行されます。
Data Factory でストアド プロシージャを呼び出す
特定のシナリオでは、ストアド プロシージャ/関数を呼び出して、集計されたデータをステージング テーブルから概要テーブルにプッシュできます。 Data Factory では、Azure Cosmos DB for PostgreSQL 用のストアド プロシージャ アクティビティは提供されませんが、回避策として、次のようにルックアップ アクティビティをクエリと共に使用してストアド プロシージャを呼び出すことができます。

次の手順
- Azure Cosmos DB for PostgreSQL を使用して、リアルタイム ダッシュボードを作成する方法について学習します。
- ワークロードを Azure Cosmos DB for PostgreSQL に移動する方法について学習します