プロビジョニングされたスループット (RU/秒) のスケーリングに関するベスト プラクティス
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
この記事では、データベースまたはコンテナー (コレクション、テーブル、またはグラフ) のスループット (RU/秒) をスケーリングするためのベスト プラクティスと戦略について説明します。 この概念は、あらゆる Azure Cosmos DB API のすべてのリソースの、プロビジョニングされた手動の RU/秒または自動スケーリングの最大の RU/秒のいずれかを増やす場合に適用されます。
前提条件
- Azure Cosmos DB でのパーティション分割とスケーリングを初めて行う場合は、最初に「Azure Cosmos DB でのパーティション分割と水平スケーリング」の記事を読むことをお勧めします。
- 429 例外が原因で RU/秒のスケーリングを計画する場合は、「Azure Cosmos DB の要求率が大きすぎる (429) 例外を診断してトラブルシューティングする」のガイダンスを参照してください。 RU/秒を増やす前に、問題の根本原因と、RU/秒を増やすことが適切な解決策であるかどうかを特定してください。
RU/秒のスケーリングの背景
データベースまたはコンテナーの RU/秒を増やす要求を送信すると、要求された RU/秒と現在の物理パーティションのレイアウトに応じて、スケールアップ操作は瞬時または非同期 (通常は 4 ~ 6 時間) で実行されます。
- インスタント スケールアップ
- 要求された RU/秒を現在の物理パーティションのレイアウトでサポートできる場合、Azure Cosmos DB ではパーティションを分割したり新規に追加したりする必要はありません。
- その結果、操作はすぐに完了し、対象の RU/秒を使用できます。
- 非同期スケールアップ
- 要求された RU/秒が、物理パーティションのレイアウトでサポートできる RU/秒よりも高い場合、Azure Cosmos DB では既存の物理パーティションが分割されます。 この動作は、要求された RU/秒をサポートするために必要な最小の数のパーティションがリソースに付与されるまで行われます。
- その結果、操作の完了に時間がかかる場合があります (通常は 4 ~ 6 時間)。 各物理パーティションでは、最大 10,000 RU/秒のスループット (すべての API に適用されます) と 50 GB のストレージ (ストレージが 30 GB の Cassandra を除くすべての API に適用されます) をサポートできます。
Note
非同期スケールアップ操作の進行中に、手動リージョン フェールオーバー操作または新しいリージョンの追加/削除を実行すると、スループット スケールアップ操作は一時停止されます。 フェールオーバーまたはリージョンの追加/削除操作が完了すると、自動的に再開されます。
- インスタント スケールダウン
- スケールダウン操作の場合、Azure Cosmos DB ではパーティションを分割したり新規に追加したりする必要はありません。
- その結果、操作はすぐに完了し、対象の RU/s を使用できます。
- この操作の主な結果として、物理パーティションあたりの RU が減少します。
パーティションのレイアウトを変更せずに RU/秒をスケールアップする方法
手順 1: 現在の物理パーティションの数を調べる。
[分析情報]>[スループット]>[PartitionKeyRangeID ごとの正規化された RU 消費量 (%)] に移動します。 PartitionKeyRangeId の個別の数をカウントします。
![[PartitionKeyRangeID ごとの正規化された RU 消費量 (%)] グラフ の PartitionKeyRangeId の個別の数をカウントする](media/scaling-provisioned-throughput-best-practices/number-of-physical-partitions.png)
Note
グラフには最大 50 の PartitionKeyRangeId だけが表示されます。 リソースでの数が 50 を超える場合は、Azure Cosmos DB REST API を使用して、パーティションの総数をカウントできます。
各 PartitionKeyRangeId は 1 つの物理パーティションにマップされ、指定可能なハッシュ値の範囲のデータを保持するように割り当てられます。
Azure Cosmos DB では水平スケーリングを有効にするために、パーティション キーに基づいて論理パーティションと物理パーティション全体にデータを分散します。 データが書き込まれるとき、Azure Cosmos DB ではパーティション キー値のハッシュを使用して、データが格納される論理パーティションと物理パーティションが決定されます。
手順 2: 既定の最大スループットを計算する
Azure Cosmos DB をトリガーしてパーティションを分割することなくスケーリングできる最大の RU/秒は、Current number of physical partitions * 10,000 RU/s と等しくなります。 この値は、Azure Cosmos DB リソース プロバイダーから取得できます。 データベースまたはコンテナーのスループット設定オブジェクトに対して GET 要求を実行し、instantMaximumThroughput プロパティを取得します。 この値は、ポータルのデータベースまたはコンテナーの [スケーリングと設定] ページでも使用できます。
例
5 つの物理パーティションと 30,000 RU/秒の手動プロビジョニングされたスループットを持つコンテナーがあるとします。 RU/秒を 5 * 10,000 RU/秒 = 50,000 RU/秒に瞬時に増やすことができます。 同様に、自動スケーリングの最大 RU/秒が 30,000 RU/秒のコンテナー (3000 から 30,000 RU/秒の間でスケーリングする) がある場合は、最大 RU/秒を即座に 50,000 RU/秒に増やす (5000 から 50,000 RU/秒の間でスケーリングする) ことができます。
ヒント
要求率が大きすぎる例外 (429) に応答して RU/秒をスケールアップする場合は、まず現在の物理パーティションのレイアウトでサポートされている最も高い RU/秒まで RU/秒を増やし、新しい RU/秒で十分かどうか評価してからさらに増やすことをお勧めします。
非同期スケーリング中に均等なデータ分散を確実に行う方法
バックグラウンド
現在の物理パーティション数 * 10,000 RU/秒を超えて RU/秒を増やすと、Azure Cosmos DB では、新しいパーティション数 = ROUNDUP(requested RU/s / 10,000 RU/s) になるまで既存のパーティションを分割します。 分割中、親パーティションは 2 つの子パーティションに分割されます。
たとえば、3 つの物理パーティションを持つコンテナーがあり、手動プロビジョニングされたスループットが 30,000 RU/秒だとします。 スループットを 45,000 RU/秒に増やした場合、Azure Cosmos DB では既存の物理パーティションの 2 つを分割して、合計で ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 つの物理パーティションが作成されます。
Note
分割中でも、アプリケーションによるデータの取り込みとクエリは常に行われる可能性があります。 Azure Cosmos DB クライアント SDK とサービスによって、このシナリオが自動的に処理され、要求は正しい物理パーティションに確実にルーティングされるため、追加のユーザー操作は必要ありません。
ストレージと要求ボリュームに関して非常に均等に分散されたワークロードがある場合 (通常は /id などの高カーディナリティ フィールドによるパーティション分割によって実現されます)、スケールアップ時にすべてのパーティションが均等に分割されるように RU/秒を設定することをお勧めします。
その理由を確認するために、2 つの物理パーティションを持つコンテナー、20,000 RU/秒、80 GB のデータという例を見てみましょう。
カーディナリティの高い適切なパーティション キーを選択した結果、データは両方の物理パーティションでほぼ均等に分散されます。 各物理パーティションには、キースペースの約 50% が割り当てられます。これは可能なハッシュ値の合計範囲として定義されます。
さらに、Azure Cosmos DB では、すべての物理パーティションに RU/秒が均等に分散されます。 その結果、各物理パーティションには、10,000 RU/秒と、合計データの 50% (40 GB) が指定されます。 次の図は、現在の状態を示しています。

次に、RU/秒を 20,000 RU/秒から 30,000 RU/秒に増やすとします。
単に RU/秒を 30,000 RU/秒に増やした場合、分割されるパーティションは 1 つのみです。 分割後は次のようになります。
- データの 50% を含む 1 つのパーティション (このパーティションは分割されていません)
- それぞれデータの 25% を含む 2 つのパーティション (これらは分割された親から生成される子パーティションです)
Azure Cosmos DB では、すべての物理パーティションに RU/秒が均等に分散されるため、各物理パーティションは引き続き 10,000 RU/秒を受け取ります。 ところが、現在はストレージと要求の分散に偏りが生じています。
次の図では、パーティション 3 と 4 (パーティション 2 の子パーティション) がそれぞれ 10,000 RU/秒で 20 GB のデータに対する要求を処理しているのに対し、パーティション 1 は 10,000 RU/秒で 2 倍の量のデータ (40 GB) に対する要求を処理します。

ストレージの均等な分散を維持するために、最初に RU/秒をスケールアップして、すべてのパーティションが分割されるようにします。 その後、RU/秒を目的の状態に下げることができます。
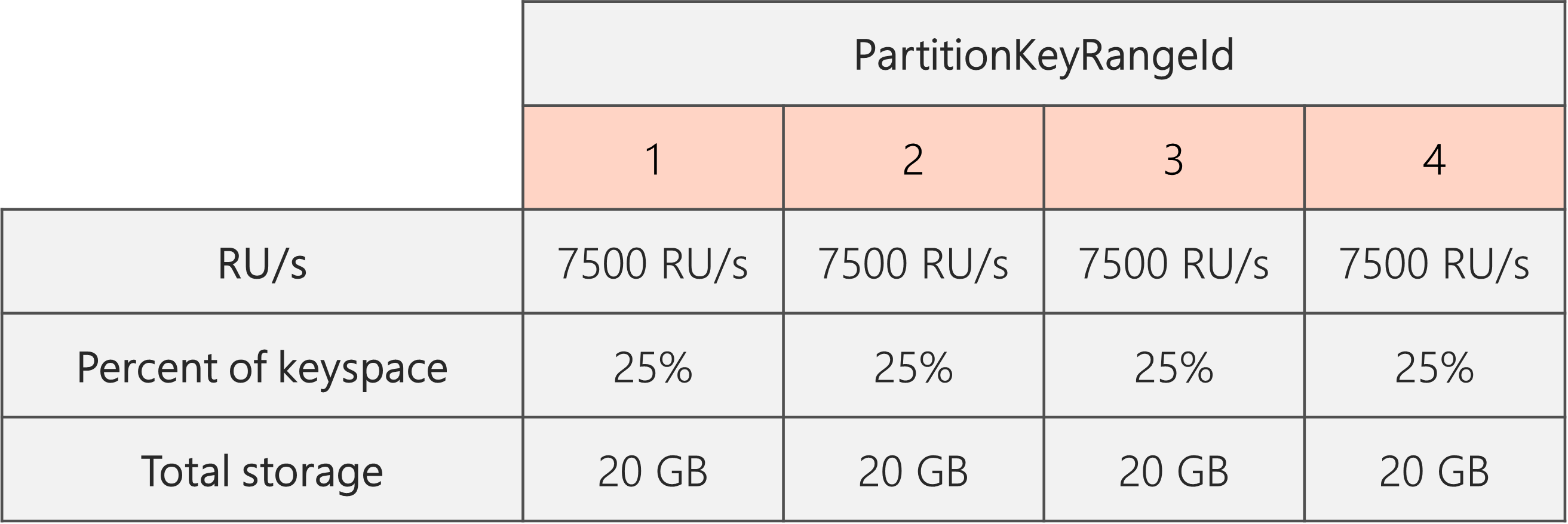
したがって、2 つの物理パーティションから始める場合、パーティションが分割後に均等になるようにするために、結局 4 つの物理パーティションになるように RU/秒を設定する必要があります。 これを実現するには、まず 4 * 10,000 RU/秒 (パーティションあたり) = 40,000 RU/秒に RU/秒を設定します。 その後、分割が完了したら、RU/秒を 30,000 RU/秒に下げることができます。
その結果、次の図に示すように、各物理パーティションでは 30,000 RU/秒 / 4 = 7500 RU/秒で 20 GB のデータに対する要求が処理されます。 全体として、パーティション間でストレージと要求の均等な分散が維持されます。
一般的な数式
手順 1: すべてのパーティションが均等に分割されるように RU/秒を増やす
一般に、物理パーティションの最初の数が P で、設定目標の RU/秒が S の場合:
RU/秒を 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))) に増やします。 これにより、すべてのパーティションを均等に分割するために必要な値に最も近い RU/秒が得られます。
Note
データベースまたはコンテナーの RU/秒を増やすと、将来下げることができる最小の RU/秒に影響する可能性があります。 通常、最小の RU/秒は MAX(400 RU/秒, 現在のストレージ (GB) * 1 RU/秒, これまでにプロビジョニングされた最大の RU/秒 / 100) に等しくなります。 たとえば、これまでにスケーリングした最大の RU/秒が 100,000 RU/秒の場合、将来設定できる最も低い RU/秒は 1000 RU/秒です。 詳細は、最小の RU/秒に関する記事を参照してください。
手順 2: RU/秒を目的の RU/秒に下げる
たとえば、5 つの物理パーティションで 50,000 RU/秒を処理し、150,000 RU/秒にスケーリングするとします。 最初に 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200,000 RU/秒を設定し、次に 150,000 RU/秒に下げる必要があります。
200,000 RU/秒にスケールアップした場合、今後設定できる手動による最小の RU/秒は 2000 RU/秒です。 設定できる最も低い自動スケーリングの最大 RU/秒は 20,000 RU/秒です (2000 から 20,000 RU/秒の範囲でスケーリング)。 目標の RU/秒は 150,000 RU/秒であるため、この最小 RU/秒の影響は受けません。
大規模なデータ インジェストのために RU/秒を最適化する方法
Azure Cosmos DB に大量のデータを移行または取り込む予定の場合は、事前に取り込む予定のデータの合計量を格納するために必要な物理パーティションが Azure Cosmos DB によって事前にプロビジョニングされるようにコンテナーの RU/秒を設定することが推奨されます。 そうしないと、インジェスト中に Azure Cosmos DB でパーティションを分割する必要が生じ、データ インジェストにかかる時間が増える可能性があります。
Azure Cosmos DB ではコンテナーの作成時に、開始 RU/秒のヒューリスティック式を使用して、開始する物理パーティションの数を計算する、という事実を利用できます。
手順 1: パーティション キーの選択を確認する
要求ボリュームとストレージが移行後に均等に分散されるようにするために、パーティション キーを選択するためのベスト プラクティスに従います。
手順 2: 必要な物理パーティションの数を計算する
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
各物理パーティションには、最大 50 GB のストレージ (Cassandra 用 API は 30 GB) を保持できます。 Target data per physical partition in GB に選択する必要がある値は、物理パーティションにどれだけいっぱいに詰め込むかと、移行後にストレージがどれだけ増大すると予想するかによって異なります。
たとえば、ストレージが増大し続ける可能性がある場合、値を 30 GB に設定できます。 ストレージを均等に分散する適切なパーティション キーを選択した場合、各パーティションは最大 60% (50 GB のうち 30 GB) となります。 将来データが書き込まれるとき、既存の物理パーティション セットに格納でき、物理パーティションをすぐに追加することをサービスに要求する必要はありません。
これに対し、移行後にストレージが大幅には拡大しないと思われる場合は、もっと大きい値 (45 GB など) を設定できます。 つまり、各パーティションは最大 90% (50 GB のうち 45 GB) となります。 これにより、データが分散される物理パーティションの数が最小限に抑えられます。つまり、プロビジョニングされた RU/秒の合計のうち、各物理パーティションで受け取る割合を増やすことができます。
手順 3: すべてのパーティションの開始する RU/ 秒の数値を計算する
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition。
物理パーティションごとに任意の数のターゲット RU/ 秒を指定した例から始めましょう。
Initial throughput per physical partition= 自動スケーリングまたは共有スループット データベースを使用する場合は物理パーティションごとに 10,000 RU/秒Initial throughput per physical partition= 手動スループットを使用する場合は物理パーティションごとに 6000 RU/秒
例
たとえば、取り込む予定のデータが 1 TB (1000 GB) で、手動スループットを使用するとします。 Azure Cosmos DB の各物理パーティションの容量は 50 GB です。 将来の増大のための余地を見越して、パーティションを 80% (40 GB) まで詰め込むと仮定します。
つまり、1 TB のデータの場合は、1000 GB / 40 GB = 25 個の物理パーティションが必要になります。 25 個の物理パーティションが得られるようにするには、手動スループットを使用する場合、最初に 25 * 6000 RU/秒 = 150,000 RU/秒をプロビジョニングします。 次に、コンテナーが作成された後、インジェストを高速化するために、インジェストが開始される前に RU/秒を 250,000 RU/秒に増やします (既に物理パーティションが 25 個存在するため即座に実行されます)。 これにより、各パーティションで最大 10,000 RU/秒を受け取ることができます。
自動スケーリング スループットまたは共有スループット データベースを使用している場合、25 個の物理パーティションを取得するには、最初に 25 * 10,000 RU/秒 = 250,000 RU/秒をプロビジョニングします。 25 個の物理パーティションでサポートできる最大の RU/秒に既に達しているため、インジェストの前にプロビジョニングされた RU/秒を増やすことはありません。
理論的には、250,000 RU/s で、1 TB のデータがある場合、1 kb のドキュメントの書き込みに 10 RU が必要だと仮定すると、インジェストは理論的に、1000 GB * (1,000,000 kb / 1 GB) * (1 ドキュメント/ 1 kb) * (10 RU/ドキュメント) * (1 秒 / 250,000 RU) * (1 時間 / 3600 秒) = 11.1 時間で完了できます。
この計算は、インジェストを実行するクライアントでスループットを完全に飽和状態にでき、すべての物理パーティションに書き込みを分散できると仮定した推定値です。 ベスト プラクティスとして、クライアント側でデータを "シャッフル" する方法をお勧めします。 これにより、1 秒ごとに、クライアントは多数の個別の論理的な (したがって物理的な) パーティションに書き込めるようになります。
移行が完了したら、必要に応じて RU/秒を下げるか自動スケーリングを有効にすることができます。
次の手順
- データベースまたはコンテナーの正規化された RU/秒の消費を監視する。
- 要求率が大きすぎる (429) 例外を診断してトラブルシューティングする。
- データベースまたはコンテナーの自動スケーリングを有効にする。