Azure Data Explorer を使用して事業継続とディザスター リカバリー ソリューションを作成する
この記事では、さまざまな Azure リージョンに Azure Data Explorer のリソース、管理、インジェストをレプリケートすることによって、Azure リージョンの停止に備える方法について詳しく説明します。 Azure Event Hubs を使用したデータ インジェストの例が示されています。 また、さまざまなアーキテクチャ構成のコストの最適化についても説明されています。 アーキテクチャに関する考慮事項とリカバリー ソリューションの詳細については、事業継続の概要に関するページを参照してください。
データを保護するために Azure リージョンの停止に備える
Azure Data Explorer では、Azure リージョン全体の停止に対する自動保護はサポートされていません。 この停止は、地震などの自然災害時に発生する可能性があります。 ディザスター リカバリー状況に対処するためのソリューションが必要な場合は、次の手順を行って事業継続を確保します。 これらの手順では、ペアになっている 2 つの Azure リージョンにクラスター、管理、およびデータ インジェストをレプリケートします。
- ペアになっている Azure リージョンに複数の独立したクラスターを作成します。
- 新しいテーブルの作成や各クラスターでのユーザー ロールの管理など、すべての管理アクティビティをレプリケートします。
- 各クラスターにデータを並列で取り込みます。
複数の独立したクラスターを作成する
複数のリージョンに Azure Data Explorer クラスターを複数作成します。 これらのクラスターのうち少なくとも 2 つが、ペアになっている Azure リージョンに作成されていることを確認します。
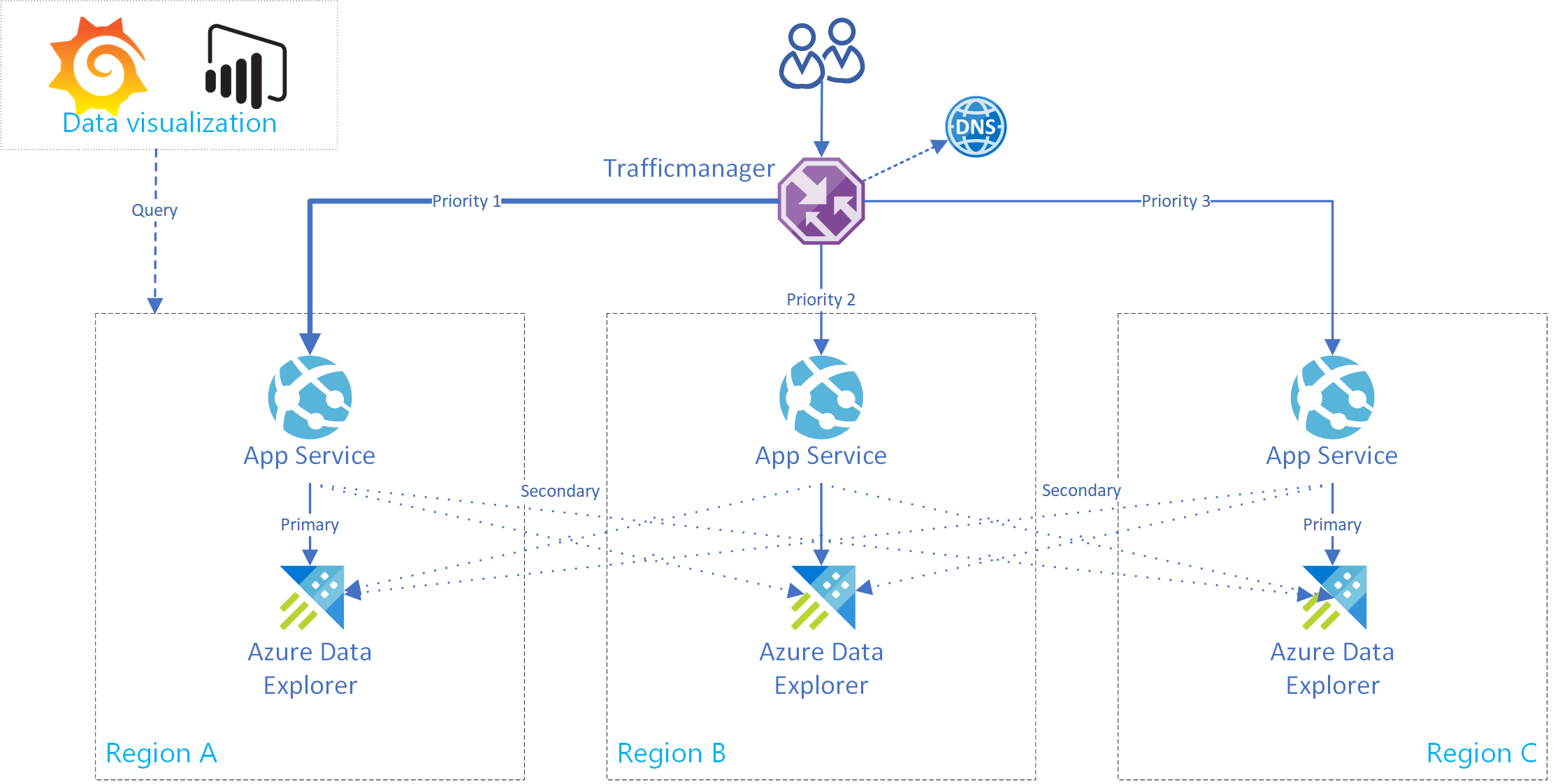
次の図は、3 つの異なるリージョンにあるレプリカの 3 つのクラスターを示しています。

管理アクティビティをレプリケートする
すべてのレプリカのクラスター構成が同じになるように、管理アクティビティをレプリケートします。
各レプリカで以下の同じものを作成します。
- データベース: Azure portal、または SDK のいずれかを使用して、新しいデータベースを作成できます。
- テーブル
- マッピング
- ポリシー
各レプリカの 認証と承認を管理します。
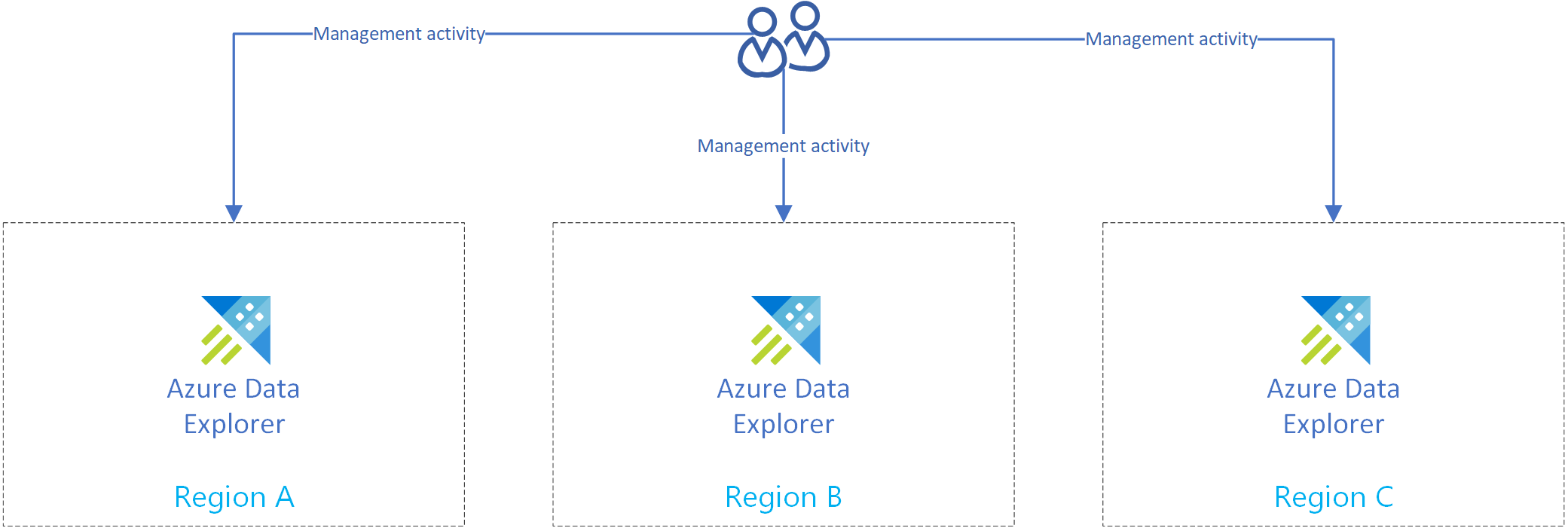
Event Hub インジェストを使用したディザスター リカバリー ソリューション
データを保護するために Azure リージョンの停止に備える作業が完了すると、データと管理が複数のリージョンに分散されます。 1 つのリージョンで機能が停止した場合、Azure Data Explorer で他のレプリカを使用できます。
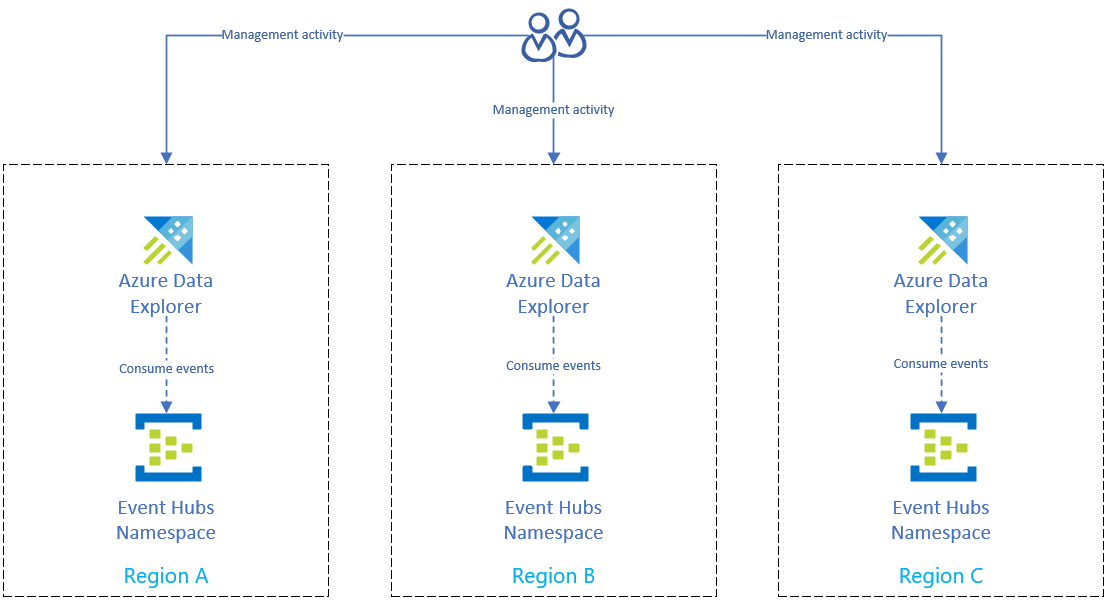
Event Hub を使用してインジェストを設定する
Azure Event Hubs から各リージョンの Azure Data Explorer クラスターにデータを取り込むには、まず、各リージョンに Azure Event Hubs のセットアップをレプリケートします。 次に、各リージョンの Azure Data Explorer レプリカを構成して、対応する Event Hubs からデータを取り込みます。
Note
Azure Event Hubs、IoT Hub、ストレージを介したインジェストは堅牢です。 クラスターが一定期間使用できない場合は、後でキャッチ アップされ、保留中のメッセージまたは BLOB が挿入されます。 このプロセスは、チェックポイント処理に依存します。
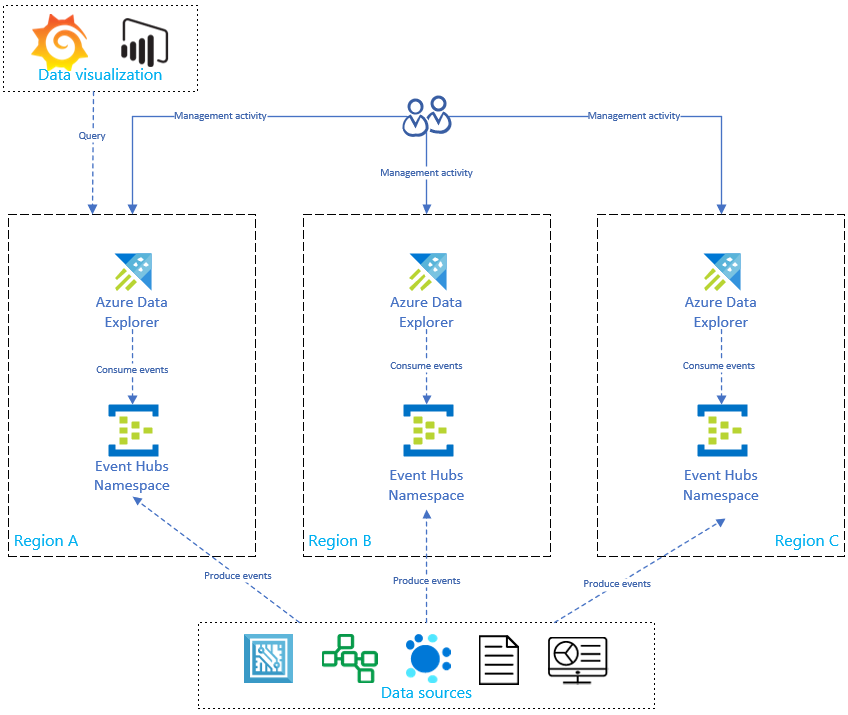
下図に示すように、データ ソースにより、すべてのリージョンの Event Hubs に対するイベントが生成され、各 Azure Data Explorer レプリカによってイベントが使用されます。 Power BI、Grafana、SDK を利用した WebApps などのデータ視覚化コンポーネントによって、いずれかのレプリカに対してクエリを実行することができます。
コストを最適化する
これで、次の方法のいくつかを使用してレプリカを最適化できるようになりました。
オンデマンド データ復旧構成を作成する
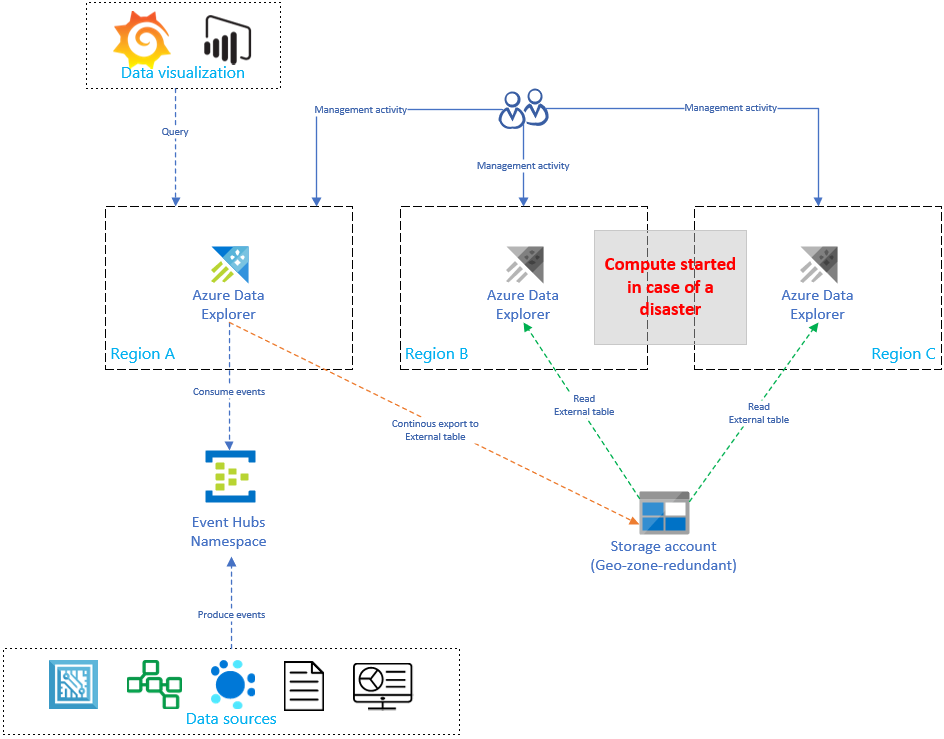
Azure Data Explorer の設定をレプリケートして更新すると、レプリカの数に比例してコストが増加します。 コストを最適化する場合、時間、フェールオーバー、およびコストのバランスを取るためのアーキテクチャ バリアントを実装できます。 オンデマンド データ復旧構成では、パッシブな Azure Data Explorer レプリカを導入することによって、コストの最適化が実装されています。 これらのレプリカは、プライマリ リージョン (たとえば、リージョン A) で災害が発生した場合にのみ有効になります。 リージョン B および C のレプリカは毎日 24 時間アクティブである必要がなく、コストが大幅に削減されます。 しかし、ほとんどの場合、これらのレプリカのパフォーマンスはプライマリ クラスターほど良好ではありません。 詳細については、「オンデマンド データ復旧の構成」を参照してください。
下図では、1 つのクラスターによってのみ、Event Hub からデータが取り込まれています。 リージョン A のプライマリ クラスターによって、ストレージ アカウントへのすべてのデータの継続的データ エクスポートが行われます。 セカンダリ レプリカからは、外部テーブルを使用してデータにアクセスすることができます。
レプリカを起動および停止する
次のいずれかの方法を使用して、セカンダリ レプリカを起動および停止することができます。
Azure portal の [概要] タブにある [停止] ボタン。 詳細については、「クラスターを停止して再起動する」を参照してください。
Azure CLI:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>"
高可用性アプリケーション サービスを実装する
Azure App Service BCDR クライアントを作成する
このセクションでは、1 つのプライマリと複数のセカンダリ Azure Data Explorer クラスターへの接続をサポートする Azure App Service を作成する方法を示します。 下図は、Azure App Service の設定を示しています。
ヒント
同じサービス内のレプリカ間に複数の接続を確立すると、可用性が向上します。 この設定は、リージョンの停止以外の場合でも役立ちます。
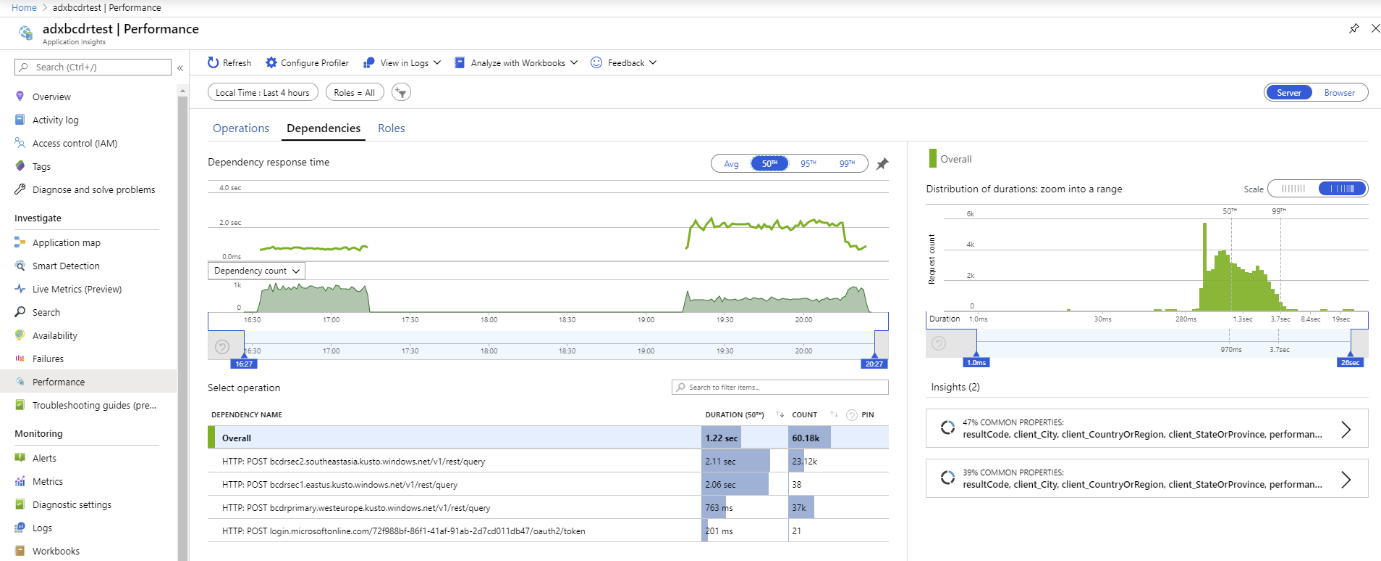
App Service ではこの定型コードを使用します。 マルチクラスター クライアントを実装するために、AdxBcdrClient クラスが作成されています。 このクライアントを使用して実行される各クエリは、最初にプライマリ クラスターに送信されます。 エラーが発生した場合、クエリはセカンダリ レプリカに送信されます。
カスタムの Application Insights メトリックを使用して、パフォーマンスを測定し、プライマリおよびセカンダリ クラスターへの分散を要求します。
Azure App Service BCDR クライアントをテストする
複数の Azure Data Explorer レプリカを使用してテストを行いました。 プライマリおよびセカンダリ クラスターの停止をシミュレートした後、App Service BCDR クライアントが意図したとおりに動作していることがわかります。
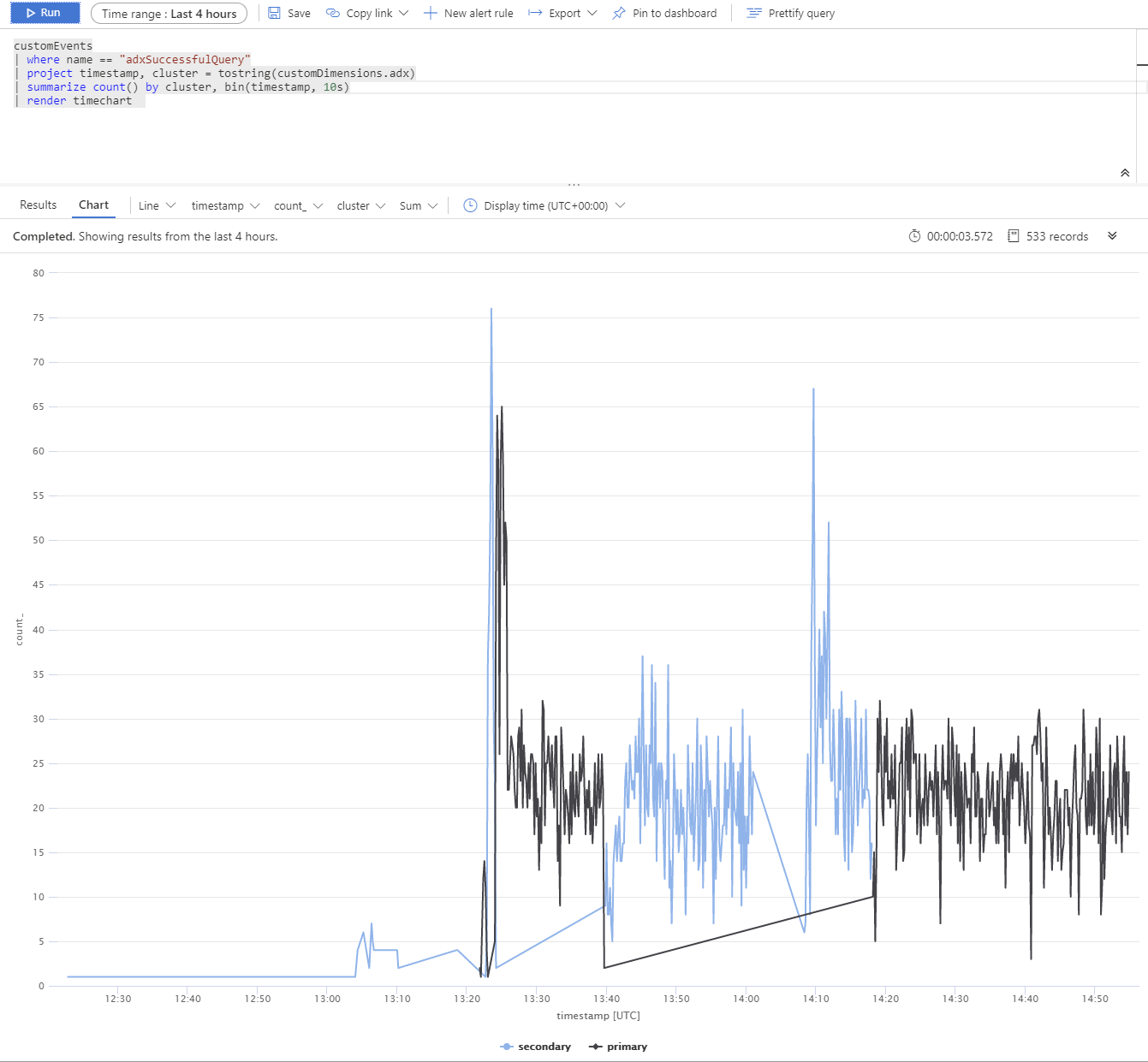
Azure Data Explorer クラスターは、西ヨーロッパ (2xD14v2 プライマリ)、東南アジア、および米国東部 (2xD11v2) に分散されています。
Note
応答時間が長くなるのは、SKU が異なり、クエリが世界にまたがって実行されるためです。
動的または静的ルーティングを実行する
要求の動的または静的ルーティングでは、Azure Traffic Manager のルーティング方法を使用します。 Azure Traffic Manager は、App Service トラフィックを分散させることができる、DNS ベースのトラフィック ロード バランサーです。 このトラフィックは世界中の Azure リージョンにまたがるサービスに対して最適化され、同時に高可用性と応答性が提供されます。
Azure Front Door ベースのルーティングを使用することもできます。 これら 2 つの方法の比較については、「Azure のアプリケーション配信スイートでの負荷分散」を参照してください。
アクティブ/アクティブ構成でコストを最適化する
ディザスター リカバリーにアクティブ/アクティブ構成を使用すると、コストが直線的に増加します。 コストには、ノード、ストレージ、マークアップ、および帯域幅の追加のネットワーク コストが含まれます。
最適化された自動スケーリングを使用してコストを最適化する
最適化された自動スケーリング機能を使用して、セカンダリ クラスターの水平スケーリングを構成します。 これらは、インジェストの負荷を処理できるように、ディメンション化する必要があります。 プライマリ クラスターに到達できなくなると、セカンダリ クラスターによって、より多くのトラフィックが取得され、構成に応じてスケーリングされます。
この例で最適化された自動スケーリングを使用することで、すべてのレプリカで同じ水平および垂直スケーリングを行う場合と比べ、約 50% のコストが節約されました。