Azure Data Explorer の Event Hubs データ接続を作成する
Azure Data Explorer では、ビッグ データ ストリーミング プラットフォームとイベント インジェストのサービスである Event Hubs からのインジェストを行うことができます。 Event Hubs は、1 秒あたり数百万件のイベントをほぼリアルタイムで処理できます。
この記事では、イベント ハブに接続してデータを Azure Data Explorer に取り込みます。 Event Hubs からの取り込みの概要については、「Azure Event Hubs データ接続」を参照してください。
Kusto SDK を使用して接続を作成する方法については、「SDK を使用して Event Hubs データ接続を作成するを参照してください。
以前の SDK バージョンに基づくサンプル コードについては、アーカイブ記事を参照してください。
イベント ハブ データ接続を作成する
このセクションでは、イベント ハブと Azure Data Explorer テーブルとの間の接続を確立します。 この接続が存在する間は、データがイベント ハブからターゲットのテーブルに送信されます。 イベント ハブが別のリソースまたはサブスクリプションに移動した場合は、接続を更新または再作成する必要があります。
前提条件
- Microsoft アカウントまたは Microsoft Entra ユーザー ID。 Azure サブスクリプションは不要です。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- ストリーミング インジェストは、Azure Data Explorer クラスターで 構成する必要があります。
データを取得する
左側のメニューから Query を選択します。
データを取り込むデータベースを右クリックします。 データの取得を選択します。
![データベースを右クリックし、[オプションの取得] ダイアログが開いている [クエリ] タブのスクリーンショット。](media/get-data-event-hubs/get-data.png)
![データベースを右クリックし、[オプションの取得] ダイアログが開いている [クエリ] タブのスクリーンショット。](media/get-data-event-hubs/get-data.png#lightbox)
ソース
[データの取り込み] ウィンドウで [ソース] タブが選択されます。
使用可能な一覧からデータ ソースを選択します。 この例では Event Hubs からデータを取り込みます。
![[ソース] タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-file/select-data-source.png#lightbox)
構成
ターゲット データベースとテーブルを選択します。 新しいテーブルにデータを取り込む場合は、[+ 新しいテーブル] を選択し、テーブル名を入力します。
Note
テーブル名には、スペース、英数字、ハイフン、アンダースコアを含め、最大 1024 文字を使用できます。 特殊文字はサポートされていません。
![Azure Data Explorer で Event Hubs のデータ ソースを構成するためのフィールドを含む [構成] タブのスクリーンショット。](media/get-data-event-hubs/configure-tab.png)
以下のフィールドを設定します。
設定 フィールドの説明 サブスクリプション イベントハブ リソースが配置されているサブスクリプション ID。 イベント ハブの名前空間 名前空間を識別する名前。 イベント ハブ 必要なイベント ハブ コンシューマー グループ イベントで定義されたコンシューマー グループ データ接続名 データ接続を識別する名前。 高度なフィルター 圧縮 イベント ハブ メッセージ ペイロードの圧縮の種類。 イベント システム プロパティ イベント ハブのシステム プロパティ。 イベント メッセージごとに複数のレコードがある場合、システム プロパティは最初のものに追加されます。 システム プロパティを追加する場合は、テーブル スキーマとマッピングを作成または更新して、選択したプロパティを含めます。 イベント取得の開始日 データ接続は、 Event 取得の開始日後に作成された既存の Event Hubs イベントを取得します。 取得できるのは、Event Hubs のリテンション期間によって保持されるイベントのみです。 Event 取得の開始日が指定されていない場合、既定の時刻はデータ接続が作成される時刻です。 [次へ] を選択します
![Azure Data Explorer で Event Hubs のデータ ソースを構成するためのフィールドを含む [構成] タブのスクリーンショット。](media/get-data-event-hubs/configure-tab.png#lightbox)
検査
[検査] タブが開き、データのプレビューが表示されます。
インジェスト プロセスを完了するには、[完了] を選択します。

必要に応じて、次の操作を行います。
プレビュー ウィンドウに表示されるデータが完全でない場合は、必要なすべてのデータ フィールドを含むテーブルを作成するために、さらにデータが必要になることがあります。 次のコマンドを使用して、イベント ハブから新しいデータをフェッチします。
新しいデータの破棄とフェッチ: 表示されたデータを破棄し、新しいイベントを検索します。
Fetch more data (さらにデータをフェッチする) :既に見つかったイベントに加えて、さらにイベントを検索します。
注意
データのプレビューを表示するには、イベント ハブがイベントを送信している必要があります。
[コマンド ビューアー] を選択し、入力から生成される自動コマンドを表示してコピーします。
[スキーマ定義ファイル] ドロップダウンを使用して、スキーマを推論する元のファイルを変更します。
ドロップダウンから必要な形式を選択して、自動的に推論されるデータの形式を変更します。 インジェストについては、Azure Data Explorer でサポートされている Data 形式を参照してください。
データ型に基づく [詳細] オプションを確認します。
列の編集
Note
- 表形式 (CSV、TSV、PSV) では、列を 2 回マップすることはできません。 既存の列にマップするには、最初に新しい列を削除します。
- 既存の列の型を変更することはできません。 異なる形式の列にマップしようとすると、空の列になってしまう場合があります。
テーブルに加えることができる変更は、次のパラメーターによって異なります。
- テーブルの種類が新規かまたは既存か
- マッピングの種類が新規かまたは既存か
| テーブルの種類です。 | マッピングの種類 | 使用可能な調整 |
|---|---|---|
| 新しいテーブル | 新しいマッピング | 列の名前変更、データ型の変更、データ ソースの変更、マッピング変換、列の追加、列の削除 |
| 既存のテーブル | 新しいマッピング | 新しい列の追加 (その後、データ型の変更、名前変更、更新が可能) |
| 既存のテーブル | 既存のマッピング | なし |

マッピング変換
一部のデータ形式マッピング (Parquet、JSON、Avro) では、簡単な取り込み時の変換がサポートされています。 マッピング変換を適用するには、[列の編集] ウィンドウで列を作成または更新します。
マッピング変換は、データ型が int または long であるソースを使用して、string または datetime 型の列に対して実行できます。 サポートされているマッピング変換は次のとおりです。
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
データ型に基づく [詳細] オプション
表形式 (CSV、TSV、PSV):
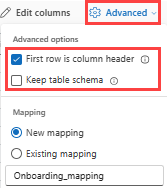
テーブル形式を 既存のテーブルに取り込む場合、 Advanced>Keep 現在のテーブル スキーマを選択できます。 表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれるとは限りません。 このオプションをオンにすると、マッピングは順番に行われ、テーブル スキーマは同じままになります。 このオプションをオフにすると、データ構造に関係なく、受信するデータに対して新しい列が作成されます。
最初の行を列名として使用するには、[詳細]>[最初の行を列ヘッダーにする] を選択します。
JSON:
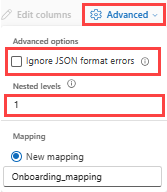
JSON データの列分割を指定するには、[詳細]>[入れ子のレベル] を 1 から 100 までで選択します。
Advanced>Ignore データ形式エラーを選択した場合、データは JSON 形式で取り込まれます。 このチェック ボックスをオフのままにすると、データは multijson 形式で取り込まれます。
まとめ
[データ準備] ウィンドウでは、データ インジェストが正常に終了した場合、3 つのステップすべてに緑色のチェックマークが表示されます。 各ステップで使用されたコマンドを表示したり、取り込まれたデータのクエリ、視覚化、削除を行うカードを選択したりできます。



イベント ハブ データ接続を削除する
関連するコンテンツ
- イベント ハブ サンプル メッセージ アプリを使用して接続を確認する
- Web UI でデータに対してクエリを実行する