Azure Data Explorer 料金計算ツール
Azure Data Explorer には、クラスターのコストを見積もるために料金計算ツールが用意されています。 見積もりは、推定データ インジェストやエンジン ワークロードなどの仕様に基づいています。 構成を変更すると、価格見積もりも変更されるため、構成の選択によるコストへの影響を把握できます。
この記事では、電卓の各コンポーネントについて説明し、クラスターの構成方法に関するより適切な決定を行う際に役立つヒントを提供します。
しくみ
クラスターのリージョン、環境、推定データ インジェストを設定します。 次に、次の各コンポーネントで自動選択または手動で選択された仕様に基づいて、毎月のコストが計算されます。
- [Engine instances](エンジン インスタンス)
- データ管理インスタンス
- ストレージとトランザクション
- ネットワーク
- Azure Data Explorer マークアップ
フォームの下部に、個々のコンポーネントの見積もりが一緒に追加され、毎月の合計見積もりが作成されます。 構成を変更すると、コンポーネントの見積もりと合計更新が行われます。
作業の開始
- 料金計算ツールに移動します。
- [見積もり] というタイトルのタブが表示されるまで、ページ下にスクロールします。
- Azure データ エクスプローラーがタブに表示されることを確認します。そうでない場合は、次の操作を行います。
- ページの上部までスクロールします。
- 検索ボックスに、「Azure Data Explorer」と入力します。
- Azure データ エクスプローラーウィジェットを選択します。
- 構成を開始します。
この記事のセクションは、電卓のコンポーネントに対応し、知っておくべきことを強調します。
リージョンと環境
クラスターに対して選択するリージョンと環境は、各コンポーネントのコストに影響します。 これは、異なるリージョンと環境でまったく同じサービスや容量が提供されないためです。
クラスターの目的の Region を選択します。
リージョンの決定ガイドを使用して、適切なリージョンを見つけます。 選択は、次のような要件によって異なります。
クラスターの Environment を選択します。
運用 クラスターには、エンジンとデータ管理用の 2 つ以上のノードが含まれており、Azure Data Explorer SLA の下で動作します。
開発/テスト クラスターはコストが最も低いオプションであり、サービス評価、POC の実施、シナリオ検証に最適です。 サイズは制限されており、1 つのノードを超えて拡張することはできません。 これらのクラスターに対する Azure Data Explorer マークアップ料金や製品 SLA はありません。
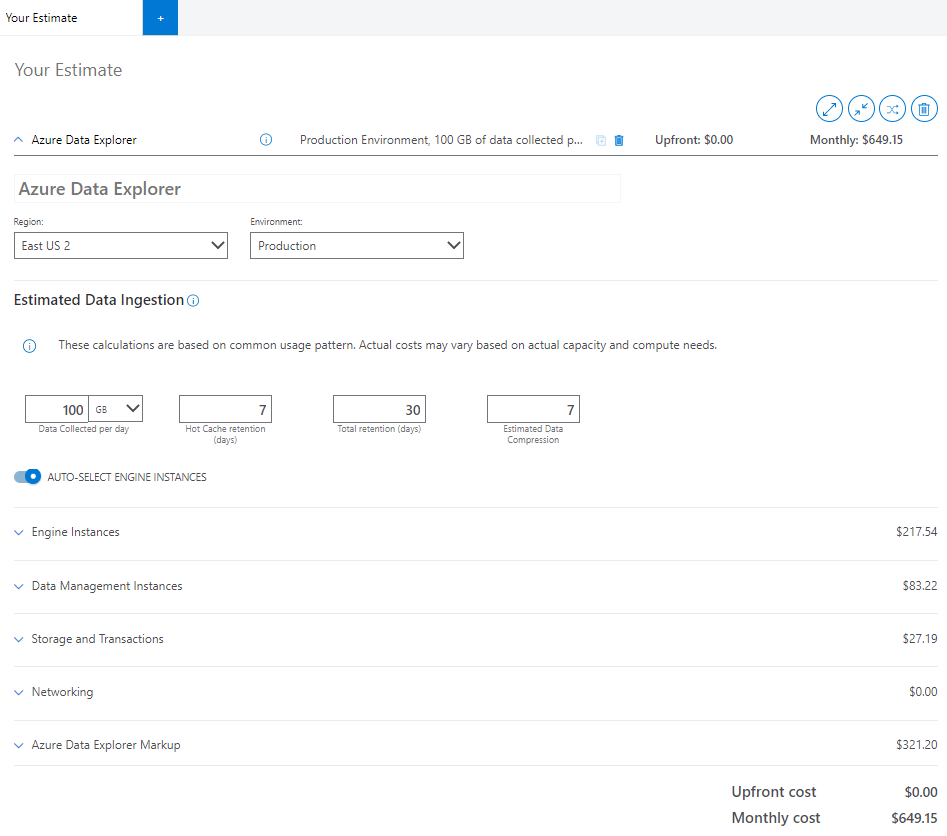
推定データ インジェスト
電卓の「 Estimated Data Ingestion 」セクションで提供される情報は、クラスターのすべてのコンポーネントの価格に影響します。
電卓で、次のフィールドの見積もりを入力します。
1 日あたりの収集データ (GB/TB): Azure Data Explorer クラスターに圧縮せずに毎日取り込む予定のデータ。 この見積もりは、取り込まれるファイルの数と平均サイズに基づいて計算します。 メッセージを使用してデータをストリーミングする場合は、1 つのメッセージの平均サイズと、取り込んでいるメッセージの数を確認します。
ホット キャッシュリテンション期間 (日): 高速クエリ アクセスのためにデータがキャッシュに格納される期間。 キャッシュ ポリシーに従ってエンジン サービスのローカル SSD にキャッシュされたデータ。 クエリ のパフォーマンス要件によって、必要なコンピューティング ノードとローカル SSD ストレージの量が決まります。
合計リテンション期間 (日): データが格納され、クエリに使用できる期間。 保持期間の後、データは自動的に削除されます。 コンプライアンスまたはその他の規制要件に基づいて、データ保持期間を選択します。 ホット ウィンドウ機能を適用して、時間枠に基づいてデータをウォーム化し、クエリを高速化します。
推定データ圧縮: 圧縮されていないデータ サイズと圧縮サイズの比率。 データ圧縮は、値とその構造のカーディナリティによって異なります。 たとえば、構造化列に取り込まれたログ データの圧縮率は、動的列または GUID と比較して高くなります。 取り込まれたデータはすべて、既定で圧縮されます。
エンジン インスタンスの自動選択
残りのコンポーネントを個別に構成する場合は、 AUTO-SELECT ENGINE INSTANCES をオフにします。 オンにすると、インジェスト入力に基づいて最適な SKU が選択されます。
[Engine instances](エンジン インスタンス)
エンジン インスタンスは、インデックス作成、ローカル SSD でのデータのキャッシュ、マネージド ディスクとしての Premium Storage、およびクエリの提供を担当します。 エンジン サービスには、少なくとも 2 つのコンピューティング インスタンスが必要です。
ワークロード オプション
エンジンの Workload オプションを次に示します。
- すべて: 指定した入力に基づいて最適な SKU を自動的に選択します
- コンピューティング最適化 SKU:
- 高いコアとホット キャッシュの比率を提供します
- 高いクエリ レートに適しています
- 低遅延 I/O 用のローカル SSD
- ストレージ最適化 SKU:
- エンジン ノードあたり 1 TB から 4 TB の大容量ストレージ オプションを提供
- 大きなデータ サイズのキャッシュを必要とするワークロードに適しています
- 一部の SKU では、Premium マネージド ディスク ストレージは、ホット データ ストレージ用のローカル SSD ではなくエンジン ノードに接続されます
Engine インスタンスの見積もりを取得するには:
- workload オプションから選択。 エンジン Instance はそれに応じて調整されます。
AUTO-SELECT ENGINE INSTANCES をオフにした場合は、特定のエンジン Instance および VM シリーズを選択します。 - エンジンを実行する時間数、日数、または月数を指定します。
- (省略可能) 保存オプション プランを選択します。
Premium マネージド ディスク コンポーネントは、選択した SKU に基づいています。
Note
すべての VM シリーズ が各リージョンで提供されるわけではありません。 選択したリージョンに一覧表示されていない SKU を探している場合は、別のリージョンを選択します。
データ管理インスタンス
データ管理 (DM) サービスは、Azure Blob Storage、Event Hubs、IoT Hub、Azure Data Factory、Azure Stream Analytics、Kafka などの他のサービスなどのマネージド データ パイプラインからのデータ インジェストを担当します。 このサービスには、エンジン インスタンスのサイズに基づいて自動的に構成および管理される、少なくとも 2 つのコンピューティング インスタンスが必要です。
データ管理 インスタンスの見積もりを取得するには:
- インスタンスを実行する時間数、日数、または月数を指定します。
- (省略可能) 保存オプション プランを選択します。
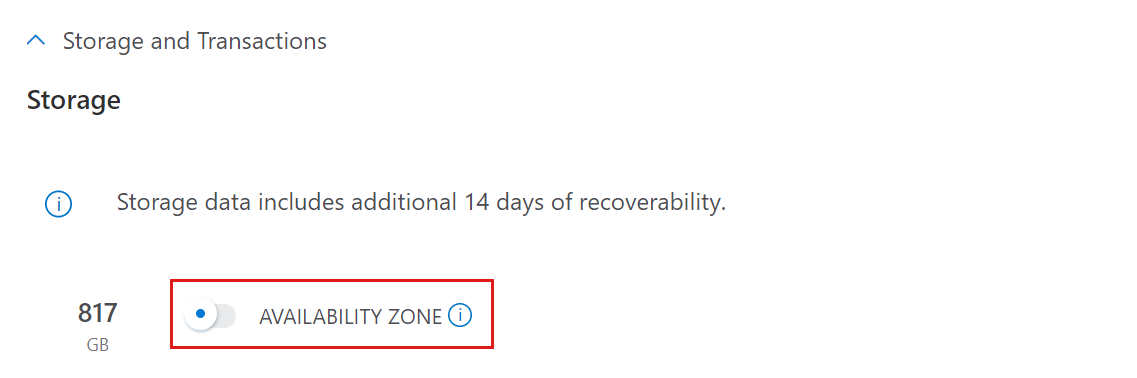
ストレージとトランザクション
ストレージ コンポーネントは、すべてのデータが圧縮されて格納され、Standard LRS または Standard ZRS として課金される永続的なレイヤーです。 ストレージは、収集されたデータの量、合計保有日数、および推定データ圧縮に基づいて計算されます。
Storage とトランザクションの見積もりを取得するには:
- 利用可能ゾーンのサポートが必要な場合はAVAILABILITY ZONEを有効にします。 有効にすると、ストレージは ZRS としてデプロイされます。 それ以外の場合、ストレージは LRS としてデプロイされます。
ネットワーク
このコンポーネントは、 bandwidth サービスを使用して構成されます。
帯域幅サービスの見積もりを取得するには:
- ページの上部までスクロールする
- 検索ボックスに「bandwidth」と入力します。
- 帯域幅製品ウィジェットを選択する
- 見積もりの帯域幅コンポーネントまで下にスクロールします
- データ転送の種類を選択する
- ソース リージョンを選択する
- 宛先リージョンを選択する
- 送信データの推定量を GB 単位で入力します
Note
リージョン間のコストを回避し、待機時間を短縮するために、ログが生成されるのと同じリージョンを選択します。 同じリージョンにデプロイされた Azure サービス間のデータ転送コストは発生しません。
Azure Data Explorer マークアップ
Azure Data Explorer マークアップは、データ インジェストとエンジン クラスターで提供される Premium サポート オプションに対して課金されます。 これは、クラスター内のエンジン vCPU の数に基づいて課金され、開発クラスターには課金されません。 コストは、エンジン インスタンス コンポーネントで構成された時間、日、または月数に基づいて変わります。 必要に応じて、 Savings オプション プランを選択します。 詳細については、「 Azure Data Explorer の価格 - FAQ」を参照してください。
サポート
サポート プランを選択します。
開発者: 非運用環境で Azure Data Explorer を構成する場合、または試用版と評価用にこのオプションを選択します。 詳細については、「 Azure サポート: 開発者 」ページを参照してください。
Standard: ビジネス クリティカルな依存関係を最小限に抑える必要がある場合に Azure Data Explorer を構成するときに、このオプションを選択します。 詳細については、「 Azure サポート: Standard 」ページを参照してください。
Professional Direct: Azure Data Explorer のビジネス クリティカルな使用率が大幅に必要な場合は、このオプションを選択します。 詳細については、「 Azure サポート: Professional Direct 」ページを参照してください。
見積もりの対処方法
- 見積もりを Excel にエクスポートする
- 将来の参照のために見積もりを保存する
- 見積もりを共有する - サインインが必要です