Azure Data Factory および Azure Synapse Analytics での区切りテキスト形式
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
区切りテキスト ファイルの解析または区切りテキスト形式へのデータの書き込みを行う場合は、この記事に従ってください。
区切りテキスト形式は次のコネクタでサポートされています。
- Amazon S3
- Amazon S3 互換ストレージ
- Azure BLOB
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- ファイル システム
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。 このセクションでは、区切りテキスト データセットでサポートされるプロパティの一覧を示します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、DelimitedText に設定する必要があります。 | はい |
| location | ファイルの場所の設定。 ファイル ベースの各コネクタには、固有の場所の種類と location でサポートされるプロパティがあります。 |
はい |
| columnDelimiter | ファイル内の列を区切るために使用する文字。 既定値はコンマ , です。 列区切り記号が区切り記号なしを意味する空の文字列として定義されている場合は、行全体が 1 つの列と見なされます。現時点では、空の文字列の列区切り記号はマッピング データ フローについてのみサポートされており、Copy アクティビティではサポートされていません。 |
いいえ |
| rowDelimiter | Copy アクティビティでは、ファイルの行を区切るために使用される1文字または「\r\n」を指します。 読み取り時の既定値は、以下のいずれかの値です:「\r\n」, 「\r」, 「\n」;書き込み時は:「\r\n」。 「\r\n」は、コピーコマンドでのみサポートされています。 マッピングデータフローの場合、ファイル内の行を区切るために使用される1文字または2文字です。 読み取り時の既定値は以下のいずれかの値です:「\r\n」, 「\r」,「\n」; 書き込み時は:「\n」。 行区切り記号を区切り記号なし (空の文字列) に設定するときは、列区切り記号も区切り記号なし (空の文字列) に設定する必要があります。これは、コンテンツ全体を 1 つの値として扱うことを意味します。 現時点では、空の文字列の行区切り記号はマッピング データ フローについてのみサポートされており、コピー アクティビティではサポートされていません。 |
いいえ |
| quoteChar | 列区切り記号が含まれる場合に列の値を引用符で囲むための 1 文字です。 既定値は二重引用符 " です。 quoteChar が空の文字列として定義されているときは、引用符がなく、列の値が引用符で囲まれないことを意味し、列区切り記号とそれ自体をエスケープするには escapeChar が使われます。 |
いいえ |
| escapeChar | 引用符で囲まれた値の内部の引用符をエスケープするための 1 文字です。 既定値はバックスラッシュ (円記号) \ です。 escapeChar が空の文字列として定義されているときは、quoteChar も空の文字列として設定する必要があり、その場合は、すべての列の値に区切り記号が含まれないことを確認します。 |
いいえ |
| firstRowAsHeader | 1 行目を列の名前が含まれるヘッダー行として扱うかどうか、またはヘッダー行にするかどうかを指定します。 使用できる値は true と false (既定値) です。 firstRowAsHeader が false の場合、UI データ プレビューと検索アクティビティ出力によって Prop_{n} (0 から開始) という列名が自動生成されることに注意してください。コピー アクティビティでは、ソースからシンクへの明示的なマッピングが必要であり、序数 (1 から始まる) とマッピング データ フロー リストによって列が検索され、名前が Column_{n} (1 から始まる) の列が検索されます。 |
いいえ |
| nullValue | null 値の文字列表現を指定します。 既定値は空の文字列です。 |
いいえ |
| encodingName | テスト ファイルの読み取り/書き込みに使用するエンコードの種類です。 許可される値は次のとおりです。"UTF-8"、"UTF-8 without BOM"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"US-ASCII"、"UTF-7"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB2312"、"GB18030"、"JOHAB"、"SHIFT-JIS"、"CP875"、"CP866"、"IBM00858"、"IBM037"、"IBM273"、"IBM437"、"IBM500"、"IBM737"、"IBM775"、"IBM850"、"IBM852"、"IBM855"、"IBM857"、"IBM860"、"IBM861"、"IBM863"、"IBM864"、"IBM865"、"IBM869"、"IBM870"、"IBM01140"、"IBM01141"、"IBM01142"、"IBM01143"、"IBM01144"、"IBM01145"、"IBM01146"、"IBM01147"、"IBM01148"、"IBM01149"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-3"、"ISO-8859-4"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"ISO-8859-13"、"ISO-8859-15"、"WINDOWS-874"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255"、"WINDOWS-1256"、"WINDOWS-1257"、"WINDOWS-1258"。 マッピング データ フローでは UTF-7 エンコードはサポートされないことに注意してください。 メモ マッピング データ フローでは、バイト オーダー マーク (BOM) を使用した UTF-8 エンコードはサポートされていません。 |
いいえ |
| compressionCodec | テキスト ファイルの読み取り/書き込みに使用される圧縮コーデックです。 使用できる値は、bzip2、gzip、deflate、ZipDeflate、TarGzip、Tar、snappy、または lz4 です。 既定では圧縮されません。 現在、Copy アクティビティでは "snappy" と "lz4" がサポートされておらず、マッピング データ フローでは "ZipDeflate"、"TarGzip"、"Tar" がサポートされていないことに注意してください。 コピー アクティビティを使用して ZipDeflate/TarGzip/Tar ファイルを圧縮解除し、ファイルベースのシンク データ ストアに書き込む場合、ファイルは既定で <path specified in dataset>/<folder named as source compressed file>/ フォルダーに解凍されることに注意してください。圧縮ファイル名をフォルダー構造として保持するかどうかを制御するには、コピー アクティビティのソースに対して preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder を使用します。 |
いいえ |
| compressionLevel | 圧縮率です。 使用できる値は、Optimal または Fastest です。 - Fastest: 圧縮操作は可能な限り短時間で完了しますが、圧縮後のファイルが最適に圧縮されていない場合があります。 - Optimal:圧縮操作で最適に圧縮されますが、操作が完了するまでに時間がかかる場合があります。 詳細については、 圧縮レベル に関するトピックをご覧ください。 |
いいえ |
Azure Blob Storage の区切りテキスト データセットの例を次に示します。
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、区切りテキストのソースとシンクでサポートされるプロパティの一覧を示します。
ソースとしての区切りテキスト
Copy アクティビティの *source* セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは DelimitedTextSource に設定する必要があります。 | はい |
| formatSettings | プロパティのグループ。 後の区切りテキストの読み取り設定に関する表をご覧ください。 | いいえ |
| storeSettings | データ ストアからデータを読み取る方法を指定するプロパティのグループ。 ファイル ベースの各コネクタには、storeSettings に、固有のサポートされる読み取り設定があります。 |
いいえ |
formatSettings でサポートされている区切りテキストの読み取り設定:
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | formatSettings の type は、DelimitedTextReadSetting に設定する必要があります。 | はい |
| skipLineCount | 入力ファイルからのデータ読み取り時にスキップする空でない行数を示します。 skipLineCount と firstRowAsHeader の両方が指定されている場合、行が最初にスキップされ、次に、入力ファイルからヘッダー情報が読まれます。 |
いいえ |
| compressionProperties | 特定の圧縮コーデックのデータを圧縮解除する方法のプロパティ グループ。 | いいえ |
| preserveZipFileNameAsFolder (" compressionProperties>type の下に ZipDeflateReadSettings として") |
ZipDeflate で入力データセットが圧縮構成されている場合に適用されます。 コピー時にソースの ZIP ファイル名をフォルダー構造として保持するかどうかを指定します。 - true (既定) に設定した場合、サービスにより解凍されたファイルが <path specified in dataset>/<folder named as source zip file>/ に書き込まれます。- false に設定した場合、サービスにより解凍されたファイルが <path specified in dataset> に直接書き込まれます。 競合または予期しない動作を避けるために、異なるソース ZIP ファイルに重複したファイル名がないことを確認します。 |
いいえ |
| preserveCompressionFileNameAsFolder (" compressionProperties>type の下に TarGZipReadSettings または TarReadSettings として") |
TarGzip/Tar で入力データセットが圧縮構成されている場合に適用されます。 コピー時にソースの圧縮ファイル名をフォルダー構造として保持するかどうかを指定します。 - true (既定) に設定した場合、サービスにより圧縮解除されたファイルが <path specified in dataset>/<folder named as source compressed file>/ に書き込みます。 - false に設定した場合、サービスにより圧縮解除されたファイルが <path specified in dataset> に直接書き込まれます。 競合または予期しない動作を避けるために、異なるソース ファイルに重複したファイル名がないことを確認します。 |
いいえ |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
シンクとしての区切りテキスト
Copy アクティビティの *sink* セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは DelimitedTextSink に設定する必要があります。 | はい |
| formatSettings | プロパティのグループ。 後の区切りテキストの書き込み設定に関する表をご覧ください。 | いいえ |
| storeSettings | データ ストアにデータを書き込む方法を指定するプロパティのグループ。 ファイル ベースの各コネクタには、storeSettings に、固有のサポートされる書き込み設定があります。 |
いいえ |
formatSettings でサポートされている区切りテキストの書き込み設定:
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | formatSettings の type は、DelimitedTextWriteSetting に設定する必要があります。 | はい |
| fileExtension | 出力ファイルの名前に使用するファイル拡張子 (.csv、.txt など)。 出力の DelimitedText データセットで fileName が指定されていない場合、指定する必要があります。 ファイル名が出力データセット内で構成されている場合は、シンク ファイル名として使用され、ファイル拡張子の設定は無視されます。 |
出力データセットでファイル名が指定されていない場合、はい |
| maxRowsPerFile | データをフォルダーに書き込むとき、複数のファイルに書き込み、ファイルあたりの最大行を指定することを選択できます。 | No |
| fileNamePrefix | maxRowsPerFile が構成されている場合に使用されます。データを複数のファイルに書き込むとき、ファイル名のプレフィックスを指定します。結果的に <fileNamePrefix>_00000.<fileExtension> のパターンになります。 指定されていない場合、ファイル名プレフィックスは自動生成されます。 このプロパティは、ソースがファイルベース ストアかパーティション オプション対応データ ストアの場合、適用されません。 |
いいえ |
Mapping Data Flow のプロパティ
マッピング データ フローでは、Azure Blob Storage、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、SFTP のデータ ストアで区切りテキスト形式に対する読み取りと書き込みを実行できます。また、Amazon S3 で区切りテキスト形式を読み取ることができます。
インライン データセット
マッピング データ フローでは、ソースとシンクを定義するためのオプションとして "インライン データセット" がサポートされます。 インライン区切りデータセットは、ソース変換やシンク変換の内部で直接定義され、定義されたデータフローの外部では共有されません。 これは、データセットのプロパティをデータ フロー内で直接パラメーター化するのに役立ち、共有された ADF データセットに比べてパフォーマンスが向上するという利点があります。
多数のソース フォルダーとファイルを読み取っている場合は、[プロジェクション | スキーマ オプション] ダイアログ内で [ユーザー プロジェクション スキーマ] オプションを設定することによって、データ フロー ファイル検出のパフォーマンスを向上させることができます。 このオプションにより、ADF の既定のスキーマ自動検出が無効になり、ファイル検出のパフォーマンスが大幅に向上します。 このオプションを設定する前に、ADF にプロジェクションのための既存のスキーマが割り当てられるように、必ずプロジェクションをインポートしてください。 このオプションは、スキーマ ドリフトでは機能しません。
ソース プロパティ
次の表に、区切りテキスト ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| ワイルド カードのパス | ワイルドカードのパスに一致するすべてのファイルが処理されます。 データセットで設定されているフォルダーとファイル パスはオーバーライドされます。 | no | String[] | wildcardPaths |
| パーティションのルート パス | パーティション分割されたファイル データについては、パーティション フォルダーを列として読み取るためにパーティションのルート パスを入力できます | no | String | partitionRootPath |
| ファイルの一覧 | 処理するファイルを一覧表示しているテキスト ファイルをソースが指しているかどうか | no | true または false |
fileList |
| 複数行 | ソース ファイルに複数行の行が含まれているか。 複数行の値は引用符で囲む必要があります。 | no true または false |
multiLineRow | |
| ファイル名を格納する列 | ソース ファイル名とパスを使用して新しい列を作成します | no | String | rowUrlColumn |
| 完了後 | 処理後にファイルを削除または移動します。 ファイル パスはコンテナー ルートから始まります | no | 削除: true または false 移動: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 最終更新日時でフィルター処理 | 最後に変更された日時に基づいてファイルをフィルター処理する場合に選択 | no | Timestamp | modifiedAfter modifiedBefore |
| [Allow no files found](ファイルの未検出を許可) | true の場合、ファイルが見つからない場合でもエラーはスローされない | no | true または false |
ignoreNoFilesFound |
| [最大列数] | 既定値は 20480 です。 列番号が 20480 を超える場合にこの値をカスタマイズする | X | 整数型 | maxColumns |
注意
ファイルの一覧に対するデータ フロー ソースのサポートは、ファイル内の 1024 エントリに制限されています。 さらに多くのファイルを含めるには、ファイル リストにワイルドカードを使用します。
ソースの例
次の図は、マッピング データ フローにおける区切りテキスト ソースの構成例です。
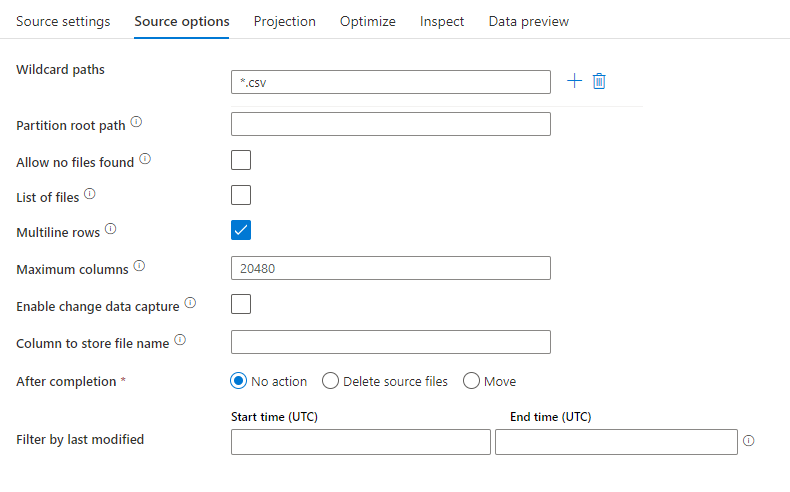
関連付けられているデータ フロー スクリプトは次のとおりです。
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
注意
データ フロー ソースでは、Hadoop ファイル システムでサポートされている Linux グロビングの限られたセットがサポートされます
シンクのプロパティ
次の表に、区切りテキスト シンクでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [設定] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| フォルダーのクリア | 書き込みの前に宛先フォルダーがクリアされるかどうか | no | true または false |
truncate |
| ファイル名のオプション | 書き込まれたデータの名前付け形式です。 既定では、part-#####-tid-<guid> という形式で、パーティションごとに 1 ファイルです |
いいえ | パターン: String パーティションあたり: String[] 列データでファイルに名前を付ける: String 1 つのファイルに出力する: ['<fileName>'] 列データでフォルダーに名前を付ける: String |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| すべてを引用符で囲む | すべての値を引用符で囲みます | no | true または false |
quoteAll |
| ヘッダー | 出力ファイルに顧客ヘッダーを追加する | いいえ | [<string array>] |
header |
シンクの例
次の図は、マッピング データ フローにおける区切りテキスト シンクの構成例です。
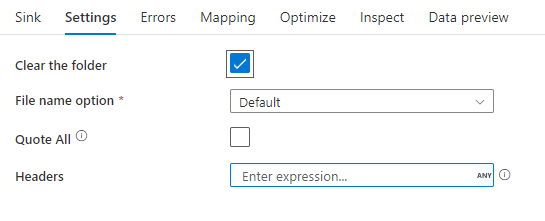
関連付けられているデータ フロー スクリプトは次のとおりです。
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
関連するコネクタと形式
区切られたテキスト形式に関連する一般的なコネクタと形式をいくつか次に示します。