Azure Data Factory または Synapse Analytics で Hadoop Streaming アクティビティを使用してデータを変換する
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory または Synapse Analytics パイプラインの HDInsight Streaming アクティビティでは、独自のまたはオンデマンドの HDInsight クラスターで Hadoop Streaming プログラムを実行します。 この記事は、データ変換とサポートされる変換アクティビティの概要を説明する、 データ変換アクティビティ に関する記事に基づいています。
詳細については、この記事を読む前に、Azure Data Factory と Synapse Analytics の概要に関する記事を参照し、データ変換のチュートリアルを実行してください。
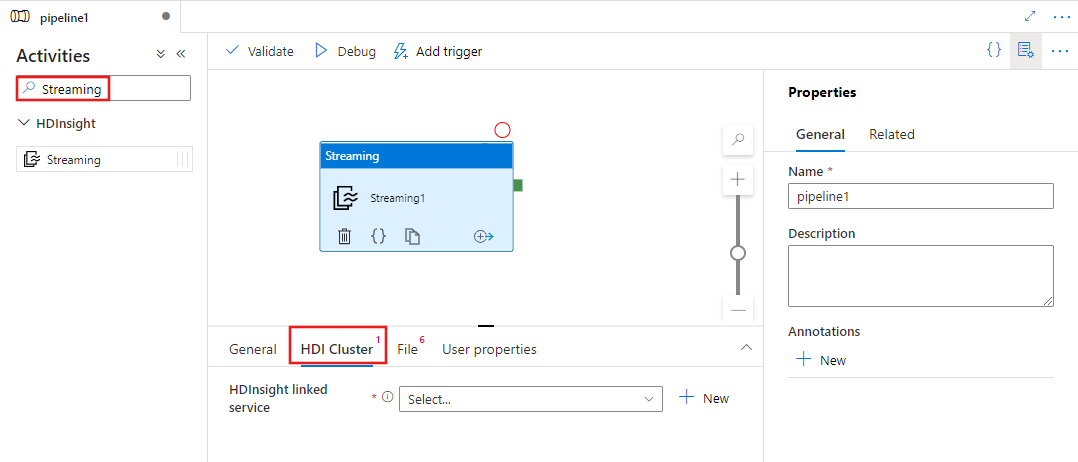
UI で HDInsight Streaming アクティビティをパイプラインに追加する
HDInsight Streaming アクティビティをパイプラインに使用するには、次の手順を実行します。
パイプライン アクティビティ ペインで Streaming を検索し、Streaming アクティビティをパイプライン キャンバスにドラッグします。
まだ選択されていない場合は、キャンバスで新しい Streaming アクティビティを選択します。
HDI Cluster タブを選択して、Streaming アクティビティの実行に使用する HDInsight クラスターへのリンク サービスを選択または新規作成します。
[ファイル] タブを選択してストリーミング ジョブのマッパーとレクサーの名前を指定し、ジョブのマッパー、レクサー、入力、および出力ファイルを実行する Azure Storage アカウントへの新しいリンクされたサービスを選択または作成します。 また、デバッグ設定、引数、ジョブに渡すパラメータなど、詳細な設定を行うことができます。
![ストリーミング アクティビティの [ファイル] タブの UI を示しています。](media/transform-data-using-hadoop-streaming/streaming-script-configuration.png)
JSON のサンプル
{
"name": "Streaming Activity",
"description": "Description",
"type": "HDInsightStreaming",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mapper": "MyMapper.exe",
"reducer": "MyReducer.exe",
"combiner": "MyCombiner.exe",
"fileLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"filePaths": [
"<containername>/example/apps/MyMapper.exe",
"<containername>/example/apps/MyReducer.exe",
"<containername>/example/apps/MyCombiner.exe"
],
"input": "wasb://<containername>@<accountname>.blob.core.windows.net/example/input/MapperInput.txt",
"output": "wasb://<containername>@<accountname>.blob.core.windows.net/example/output/ReducerOutput.txt",
"commandEnvironment": [
"CmdEnvVarName=CmdEnvVarValue"
],
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
構文の詳細
| プロパティ | 内容 | 必須 |
|---|---|---|
| name | アクティビティの名前 | はい |
| description | アクティビティの用途を説明するテキストです。 | いいえ |
| type | Hadoop Streaming アクティビティの場合、アクティビティの種類は HDInsightStreaming です。 | はい |
| linkedServiceName | リンクされたサービスとして登録されている HDInsight クラスターへの参照。 このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。 | はい |
| mapper | mapper 実行可能ファイルの名前を指定します。 | はい |
| reducer | reducer 実行可能ファイルの名前を指定します。 | はい |
| combiner | combiner 実行可能ファイルの名前を指定します。 | いいえ |
| fileLinkedService | 実行されるマッパー、コンバイナー、レジューサの各プログラムを格納するために使用される Azure Storage のリンクされたサービスへの参照。 ここでは Azure Blob Storage および ADLS Gen2 にリンクされたサービスのみがサポートされています。 このリンクされたサービスを指定していない場合は、HDInsight のリンクされたサービスで定義されている Azure Storage のリンクされたサービスが使用されます。 | いいえ |
| filePath | fileLinkedService によって参照される、Azure Storage に格納された マッパー、コンバイナー、レジューサ の各プログラムのパスの配列を指定します。 パスの大文字と小文字は区別されます。 | はい |
| input | マッパーの入力ファイルの WASB パスを指定します。 | はい |
| output | レジューサの出力ファイルの WASB パスを指定します。 | はい |
| getDebugInfo | HDInsight クラスターで使用されている Azure Storage または scriptLinkedService で指定された Azure Storage にログ ファイルがコピーされるタイミングを指定します。 使用できる値は以下の通りです。None、Always、または Failure。 既定値:[なし] : | いいえ |
| 引数 | Hadoop ジョブの引数の配列を指定します。 引数はコマンド ライン引数として各タスクに渡されます。 | いいえ |
| defines | Hive スクリプト内で参照するキーと値のペアとしてパラメーターを指定します。 | いいえ |
関連するコンテンツ
別の手段でデータを変換する方法を説明している次の記事を参照してください。