プライベート エンドポイントを使用して Azure Blob Storage から SQL データベースに安全にデータをコピーする
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、Azure Data Factory ユーザー インターフェイス (UI) を使用してデータ ファクトリを作成します。 このデータ ファクトリのパイプラインでは、Azure Data Factory マネージド仮想ネットワークのプライベート エンドポイントを使用して、Azure Blob Storage から Azure SQL データベースに安全にデータをコピーします (どちらも、選択したネットワークへのアクセスのみを許可します)。 このチュートリアルの構成パターンは、ファイルベースのデータ ストアからリレーショナル データ ストアへのコピーに適用されます。 ソースおよびシンクとしてサポートされているデータ ストアの一覧については、「サポートされるデータ ストアと形式」の表を参照してください。 プライベート エンドポイント機能は Azure Data Factory のすべてのサービス レベルで使用できるので、それらを利用するために特定のサービス レベルは必要ありません。 価格とサービス レベルについて詳しくは、Azure Data Factory の価格のページをご覧ください。
Note
Data Factory を初めて使用する場合は、「Azure Data Factory の概要」を参照してください。
このチュートリアルでは、次の手順を実行します。
- データ ファクトリを作成します。
- コピー アクティビティを含むパイプラインを作成します。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料の Azure アカウントを作成してください。
- Azure ストレージ アカウント。 Blob Storage を "ソース" データ ストアとして使用します。 ストレージ アカウントがない場合の作成手順については、Azure のストレージ アカウントの作成に関するページを参照してください。 ストレージ アカウントで、選択したネットワーク からのアクセスのみが許可されていることを確認します。
- Azure SQL データベース。 データベースを "シンク" データ ストアとして使用します。 Azure SQL データベースがない場合の作成手順については、SQL データベースの作成に関するページを参照してください。 SQL Database アカウントで、選択したネットワーク からのアクセスのみが許可されていることを確認します。
BLOB と SQL テーブルを作成する
ここからは、次の手順を実行して、チュートリアル用の Blob Storage と SQL データベースを準備します。
ソース BLOB を作成する
メモ帳を開きます。 次のテキストをコピーし、emp.txt ファイルとしてディスクに保存します。
FirstName,LastName John,Doe Jane,DoeBlob Storage に adftutorial という名前のコンテナーを作成します。 このコンテナーに input という名前のフォルダーを作成します。 次に、input フォルダーに emp.txt ファイルをアップロードします。 Azure Portal を使用するか、または Azure Storage Explorer などのツールを使用して、これらのタスクを実行します。
シンク SQL テーブルを作成する
次の SQL スクリプトを使用して、dbo.emp テーブルを SQL データベースに作成します。
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Data Factory の作成
この手順では、データ ファクトリを作成するほか、Data Factory UI を起動してそのデータ ファクトリにパイプラインを作成します。
Microsoft Edge または Google Chrome を開きます。 現在、Data Factory UI をサポートしている Web ブラウザーは Microsoft Edge と Google Chrome のみです。
左側のメニューで、 [リソースの作成]>[分析]>[Data Factory] の順に選択します。
[新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialDataFactory」と入力します。
Azure データ ファクトリの名前は グローバルに一意にする必要があります。 データ ファクトリの名前の値に関するエラー メッセージが表示された場合は、別の名前を入力してください(yournameADFTutorialDataFactory など)。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関するページを参照してください。
データ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] で、次の手順のいずれかを行います。
- [Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
- [新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
[バージョン] で、 [V2] を選択します。
[場所] で、データ ファクトリの場所を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリによって使用されるデータ ストア (Azure Storage、SQL Database など) やコンピューティング (Azure HDInsight など) は、他のリージョンに存在していてもかまいません。
[作成] を選択します
作成が完了すると、その旨が通知センターに表示されます。 [リソースに移動] を選択して、 [Data Factory] ページに移動します。
[開く] を [Open Azure Data Factory Studio] タイルで選択して、別のタブで Azure Data Factory UI を起動します。
Data Factory マネージド仮想ネットワークに Azure 統合ランタイムを作成する
この手順では、Azure 統合ランタイムを作成し、Data Factory マネージド仮想ネットワークを有効にします。
Data Factory ポータルで、 [管理] に移動し、 [新規] を選択して新しい Azure 統合ランタイムを作成します。
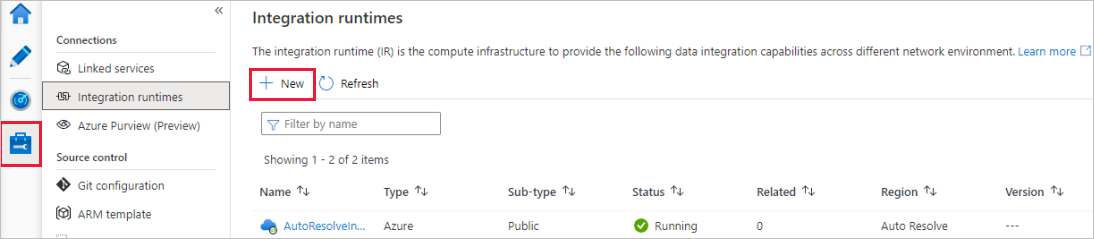
[Integration runtime setup](統合ランタイムのセットアップ) ページで、必要な機能に基づいて作成する統合ランタイムを選択します。 このチュートリアルでは、 [Azure、セルフホステッド] を選択し、 [続行] をクリックします。
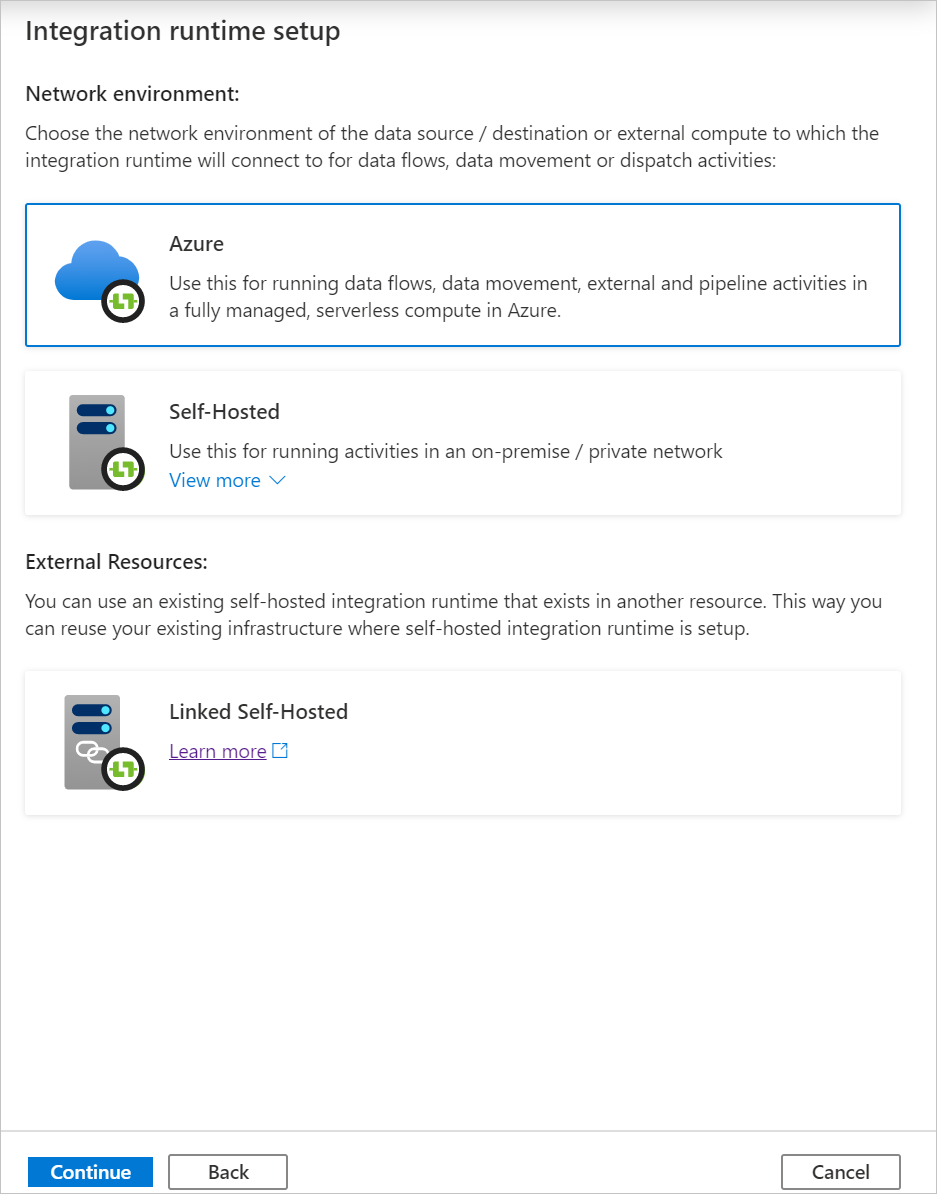
[Azure] を選択し、 [続行] をクリックして、Azure Integration ランタイムを作成します。
[仮想ネットワークの構成 (プレビュー)] で、 [有効化] を選択します。
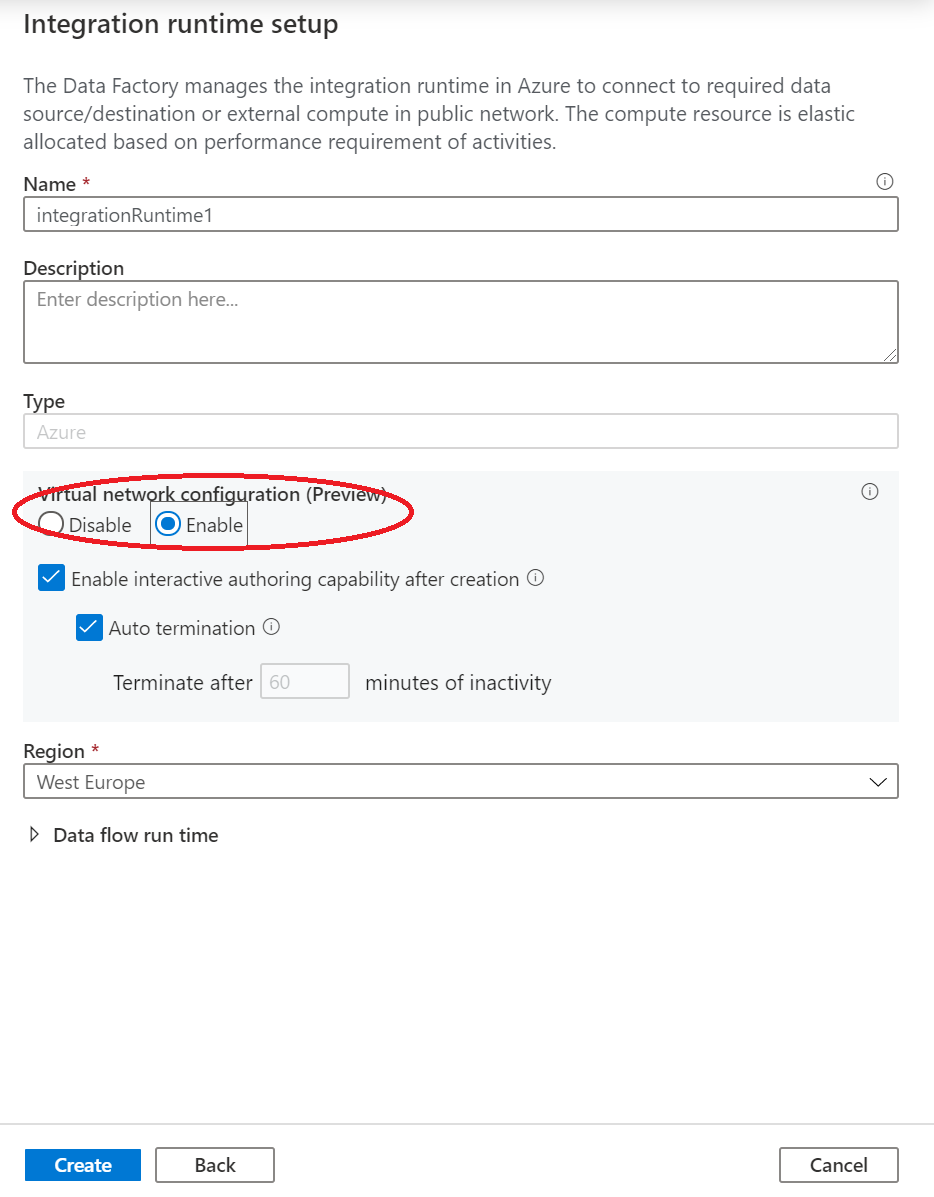
[作成] を選択します
パイプラインを作成する
この手順では、コピー アクティビティが含まれたパイプラインをデータ ファクトリに作成します。 コピー アクティビティによって、Blob Storage から SQL Database にデータがコピーされます。 クイックスタート チュートリアルでは、次の手順でパイプラインを作成しました。
- リンクされたサービスを作成します。
- 入力データセットと出力データセットを作成します。
- パイプラインを作成します。
このチュートリアルでは、最初にパイプラインを作成します。 その後、パイプラインの構成に必要な場合にリンクされたサービスとデータセットを作成します。
ホーム ページで [調整] を選択します。
![[オーケストレーション] ボタンが強調表示されたデータ ファクトリのホームページを示すスクリーンショット。](media/tutorial-data-flow/orchestrate.png)
パイプラインの [プロパティ] ペインで、パイプライン名として「CopyPipeline」と入力します。
[アクティビティ] ツール ボックスで [Move and Transform](移動と変換) カテゴリを展開し、ツール ボックスからパイプライン デザイナー画面に [データのコピー] アクティビティをドラッグします。 名前に「CopyFromBlobToSql」と入力します。
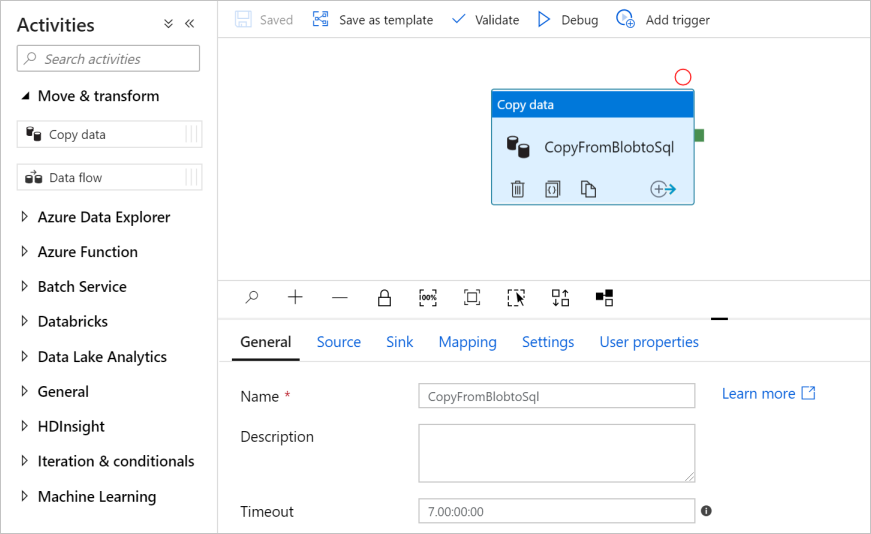
ソースを構成する
ヒント
このチュートリアルでは、ソース データ ストアの認証の種類として "アカウント キー" を使用します。 また、必要に応じて、SAS URI、サービス プリンシパル、マネージド ID など、サポートされている他の認証方法を選ぶこともできます。 詳細については、「Azure Data Factory を使用して Azure BLOB ストレージのデータをコピーおよび変換する」の対応するセクションを参照してください。
さらに、データ ストアのシークレットを安全に格納するために、Azure Key Vault の使用をお勧めします。 詳細な説明と図解については、「Azure Key Vault への資格情報の格納」を参照してください。
ソース データセットおよびリンクされたサービスを作成する
[ソース] タブに移動します。 [+ 新規] を選択して、ソース データセットを作成します。
[新しいデータセット] ダイアログ ボックスで [Azure Blob Storage] を選択し、 [続行] をクリックします。 ソース データは Blob Storage にあるので、ソース データセットには Azure Blob Storage を選択します。
[形式の選択] ダイアログ ボックスで、データの形式の種類を選択して、 [続行] を選択します。
[プロパティの設定] ダイアログ ボックスで、 [名前] に「SourceBlobDataset」を入力します。 [First row as header](先頭の行を見出しとして使用) のチェック ボックスをオンにします。 [リンクされたサービス] ボックスの下にある [+ 新規] を選択します。
[New linked service (Azure Blob Storage)](新しいリンクされたサービス (Azure Blob Storage)) ダイアログ ボックスで、 [名前] として「AzureStorageLinkedService」と入力し、 [ストレージ アカウント名] の一覧からご自身のストレージ アカウントを選択します。
[Interactive authoring](インタラクティブな作成) を必ず有効にしてください。 これは有効になるまでに 1 分程かかる場合があります。
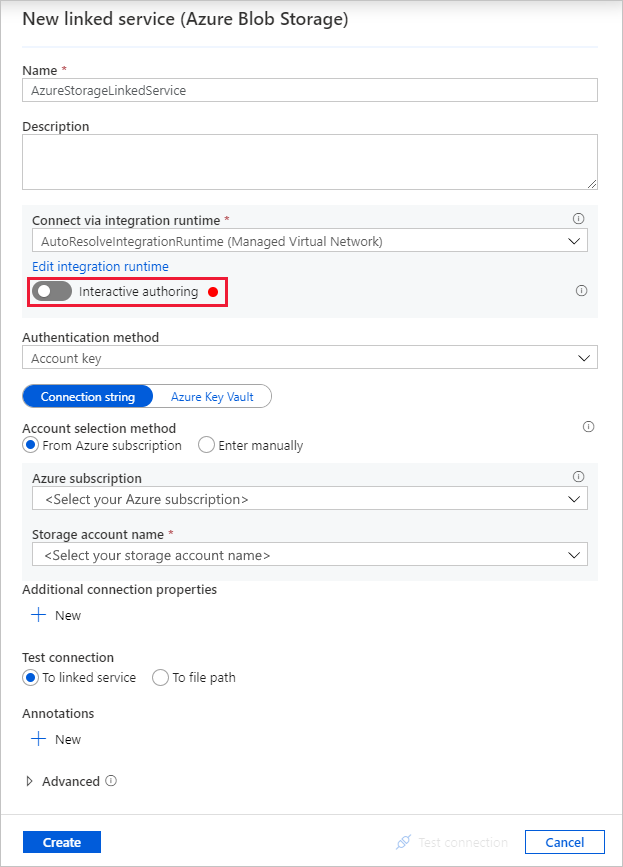
[接続テスト] を選択します。 これは、ストレージ アカウントが、選択したネットワークからのアクセスのみを許可していて、Data Factory に、使用する前に承認が必要なプライベート エンドポイントの作成を要求する場合、失敗します。 エラー メッセージ内に、プライベート エンドポイントを作成するためのリンクが表示されます。それをたどることで、マネージド プライベート エンドポイントを作成できます。 代わりに、 [管理] タブに直接移動し、次のセクションの指示に従って、マネージド プライベート エンドポイントを作成する方法もあります。
Note
データ ファクトリ インスタンスでは、そのすべてで [管理] タブを使用できない場合があります。 表示されない場合は、 [作成者]>[接続]>[プライベート エンドポイント] を選択して、プライベート エンドポイントにアクセスできます。
ダイアログ ボックスは開いたままにして、ストレージ アカウントに移動します。
このセクションの手順に従って、プライベート リンクを承認します。
ダイアログ ボックスに戻ります。 もう一度 [接続テスト] を選択し、 [作成] を選択して、リンクされたサービスをデプロイします。
リンクされたサービスが作成されると、 [プロパティの設定] ページに戻ります。 [ファイル パス] の横にある [参照] を選択します。
adftutorial/input フォルダーに移動して emp.txt ファイルを選択し、 [OK] を選択します。
[OK] を選択します。 自動的にパイプライン ページに移動します。 [ソース] タブで、 [SourceBlobDataset] が選択されていることを確認します。 このページのデータをプレビューするには、 [データのプレビュー] を選択します。
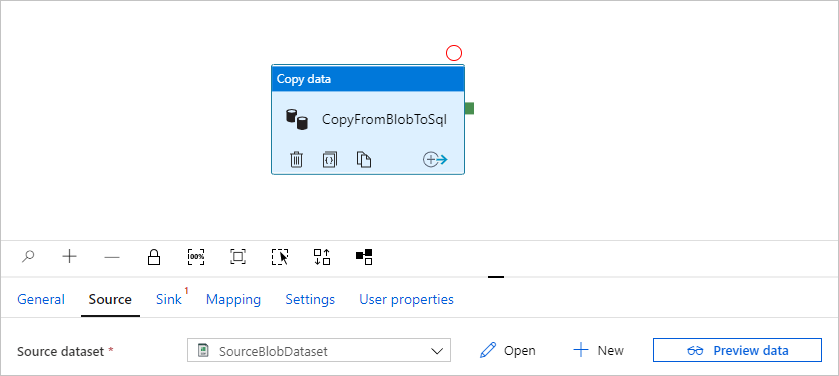
マネージド プライベート エンドポイントを作成する
接続をテストした際にハイパーリンクを選択しなかった場合は、パスに従います。 次に、作成済みのリンクされたサービスに接続するマネージド プライベート エンドポイントを作成する必要があります。
[管理] タブに移動します。
Note
Data Factory インスタンスでは、そのすべてで [管理] タブを使用できない場合があります。 表示されない場合は、 [作成者]>[接続]>[プライベート エンドポイント] を選択して、プライベート エンドポイントにアクセスできます。
[マネージド プライベート エンドポイント] セクションに移動します。
[マネージド プライベート エンドポイント] で、 [+ 新規] を選択します。
![[マネージド プライベート エンドポイント] の [新規] ボタンを示すスクリーンショット。](media/tutorial-copy-data-portal-private/new-managed-private-endpoint.png)
一覧から [Azure Blob Storage] タイルを選択し、 [続行] を選択します。
作成したストレージ アカウントの名前を入力します。
[作成] を選択します
数秒後に、作成されたプライベート リンクに承認が必要であることが表示されます。
作成したプライベート エンドポイントを選択します。 ストレージ アカウント レベルでプライベート エンドポイントを承認できるハイパーリンクが表示されます。
![[マネージド プライベート エンドポイント] ペインを示すスクリーンショット。](media/tutorial-copy-data-portal-private/manage-private-endpoint.png)
ストレージ アカウントでプライベート リンクを承認する
ストレージ アカウントで、 [設定] セクションの [プライベート エンドポイント接続] に移動します。
作成したプライベート エンドポイントのチェック ボックスをオンにし、 [承認] を選択します。
![プライベート エンドポイントの [承認] ボタンを示すスクリーンショット。](media/tutorial-copy-data-portal-private/approve-private-endpoint.png)
説明を追加し、 [はい] を選択します。
Data Factory の [管理] タブにある [マネージド プライベート エンドポイント] セクションに戻ります。
約 1 分から 2 分後に、Data Factory UI にプライベート エンドポイントの承認が表示されます。
シンクを構成する
ヒント
このチュートリアルでは、シンク データ ストアの認証の種類として SQL 認証を使用します。 また、必要に応じて、サービス プリンシパル、マネージド ID など、サポートされている他の認証方法を選ぶこともできます。 詳細については、「Azure Data Factory を使用して Azure SQL Database のデータをコピーおよび変換する」の対応するセクションを参照してください。
さらに、データ ストアのシークレットを安全に格納するために、Azure Key Vault の使用をお勧めします。 詳細な説明と図解については、「Azure Key Vault への資格情報の格納」を参照してください。
シンク データセットおよびリンクされたサービスを作成する
[シンク] タブに移動し、 [+ 新規] を選択してシンク データセットを作成します。
[新しいデータセット] ダイアログ ボックスで、検索ボックスに「SQL」と入力して、コネクタをフィルター処理します。 [Azure SQL Database] を選び、 [続行] を選びます。 このチュートリアルでは、SQL データベースにデータをコピーします。
[プロパティの設定] ダイアログ ボックスで、 [名前] に「OutputSqlDataset」を入力します。 [リンクされたサービス] ドロップダウン リストから [+ 新規] を選択します。 データセットをリンクされたサービスに関連付ける必要があります。 リンクされたサービスには、Data Factory が実行時に SQL データベースに接続するために使用する接続文字列が含まれています。 データセットは、コンテナー、フォルダー、データのコピー先のファイル (オプション) を指定します。
[New Linked Service (Azure SQL Database)](新しいリンクされたサービス (Azure SQL Database)) ダイアログ ボックスで、次の手順を実行します。
- [名前] に「AzureSqlDatabaseLinkedService」と入力します。
- [サーバー名] で、使用する SQL Server インスタンスを選択します。
- [Interactive authoring](インタラクティブな作成) を必ず有効にしてください。
- [データベース名] で、使用する SQL データベースを選択します。
- [ユーザー名] に、ユーザーの名前を入力します。
- [パスワード] に、ユーザーのパスワードを入力します。
- [接続テスト] を選択します。 これは失敗します。SQL サーバーが、選択したネットワークからのアクセスのみを許可し、Data Factory に、使用する前に承認が必要なプライベート エンドポイントの作成を要求するためです。 エラー メッセージ内に、プライベート エンドポイントを作成するためのリンクが表示されます。それをたどることで、マネージド プライベート エンドポイントを作成できます。 代わりに、 [管理] タブに直接移動し、次のセクションの指示に従って、マネージド プライベート エンドポイントを作成する方法もあります。
- ダイアログ ボックスは開いたままにして、選択した SQL サーバーに移動します。
- このセクションの手順に従って、プライベート リンクを承認します。
- ダイアログ ボックスに戻ります。 もう一度 [接続テスト] を選択し、 [作成] を選択して、リンクされたサービスをデプロイします。
[プロパティの設定] ダイアログ ボックスに自動的に移動します。 [テーブル] で [dbo].[emp] を選択します。 [OK] をクリックします。
パイプラインがあるタブに移動し、 [シンク データセット] で OutputSqlDataset が選択されていることを確認します。
![[パイプライン] タブを示すスクリーンショット。](media/tutorial-copy-data-portal-private/pipeline-tab-2.png)
必要に応じて「コピー アクティビティでのスキーマ マッピング」に従い、コピー元のスキーマをコピー先の対応するスキーマにマッピングすることができます。
マネージド プライベート エンドポイントを作成する
接続をテストした際にハイパーリンクを選択しなかった場合は、パスに従います。 次に、作成済みのリンクされたサービスに接続するマネージド プライベート エンドポイントを作成する必要があります。
[管理] タブに移動します。
[マネージド プライベート エンドポイント] セクションに移動します。
[マネージド プライベート エンドポイント] で、 [+ 新規] を選択します。
一覧から [Azure SQL Database] タイルを選択し、 [続行] を選択します。
選択した SQL サーバーの名前を入力します。
[作成] を選択します
数秒後に、作成されたプライベート リンクに承認が必要であることが表示されます。
作成したプライベート エンドポイントを選択します。 SQL サーバー レベルでプライベート エンドポイントを承認できるハイパーリンクが表示されます。
SQL サーバーでのプライベート リンクの承認
- SQL サーバーで、 [設定] セクションの [プライベート エンドポイント接続] に移動します。
- 作成したプライベート エンドポイントのチェック ボックスをオンにし、 [承認] を選択します。
- 説明を追加し、 [はい] を選択します。
- Data Factory の [管理] タブにある [マネージド プライベート エンドポイント] セクションに戻ります。
- プライベート エンドポイントの承認が表示されるまでに 1 分から 2 分かかります。
パイプラインをデバッグして発行する
Data Factory または独自の Azure Repos Git リポジトリにアーティファクト (リンクされたサービス、データセット、パイプライン) を発行する前に、パイプラインをデバッグできます。
- パイプラインをデバッグするには、ツール バーで [デバッグ] を選択します。 ウィンドウ下部の [出力] タブにパイプラインの実行の状態が表示されます。
- パイプラインを適切に実行できたら、上部のツール バーで [すべて発行] を選択します。 これにより、作成したエンティティ (データセットとパイプライン) が Data Factory に発行されます。
- [正常に発行されました] というメッセージが表示されるまで待機します。 通知メッセージを表示するには、右上隅にある [通知の表示] (ベル ボタン) を選択 ます。
まとめ
このサンプルのパイプラインでは、Data Factory マネージド仮想ネットワークのプライベート エンドポイントを使用して、Blob Storage から SQL Database にデータをコピーします。 以下の方法を学習しました。
- データ ファクトリを作成します。
- コピー アクティビティを含むパイプラインを作成します。