AI エージェントを作成する
重要
この機能はパブリック プレビュー段階にあります。
この記事では、Mosaic AI Agent Framework を使用してツール呼び出しAI エージェントを作成する方法について説明します。
エージェント ツールを提供し、チャットを開始してエージェントをテストおよびプロトタイプ作成する方法について説明します。 エージェントのプロトタイプ作成が完了したら、AI エージェントを反復処理してデプロイするエージェントを定義する Python コードをエクスポートします。
要件
- 「複合 AI システムと AI エージェントとは 」の説明に従って、AI エージェントとツールの概念を理解します。
- Databricks では、エージェントの開発時に最新バージョンの MLflow Python クライアントをインストールすることをお勧めします。
AI エージェント ツールを作成する
最初の手順では、エージェントに提供するツールを作成します。 エージェントは、構造化データや非構造化データの取得、コードの実行、リモート サービスとの通信 (メールや Slack メッセージの送信など) など、言語生成以外のアクションを実行するツールを使用します。
このガイドでは、組み込みの Unity Catalog 関数 (system.ai.python_exec) を使用して、エージェントが任意の Python コードを実行できるようにします。
独自のエージェント ツールの作成の詳細については、「AI エージェント ツールの作成」を参照してください。
AI プレイグラウンドでのプロトタイプ ツール呼び出しエージェント
ツールが用意されたので、AI Playground を使用して、エージェントにツールを提供し、それを操作して動作を検証およびテストします。 AI プレイグラウンドは、ツール呼び出しエージェントのプロトタイプを作成するためのサンドボックスを提供します。
Note
Unity Catalog、 サーバーレス コンピューティング、 Mosaic AI エージェント フレームワーク、トークンごとの 基本モデル または external モデルのいずれかを使用できる必要があります 現在のワークスペースで、AI プレイグラウンドのエージェントのプロトタイプを作成する必要があります。
ツール呼び出しエンドポイントのプロトタイプを作成します。
Playground で、 Tools が有効になっているモデル 選択します。
[ツール]を選択し、ドロップダウンで Unity Catalog 関数の名前を指定します。
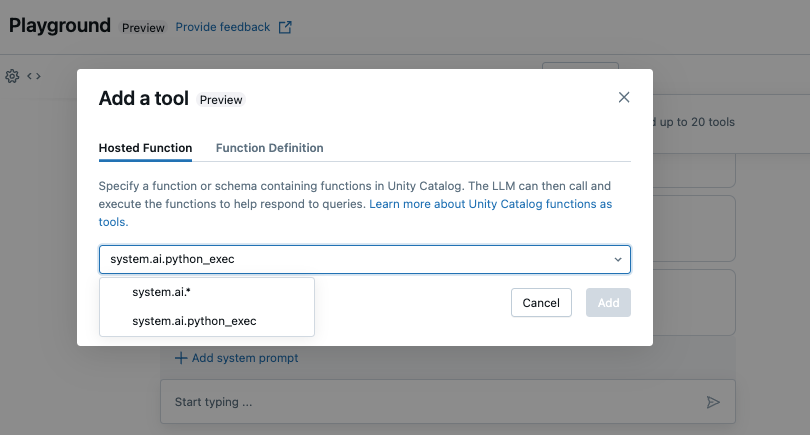
LLM、ツール、システム プロンプトの現在の組み合わせをテストし、バリエーションを試すチャット。
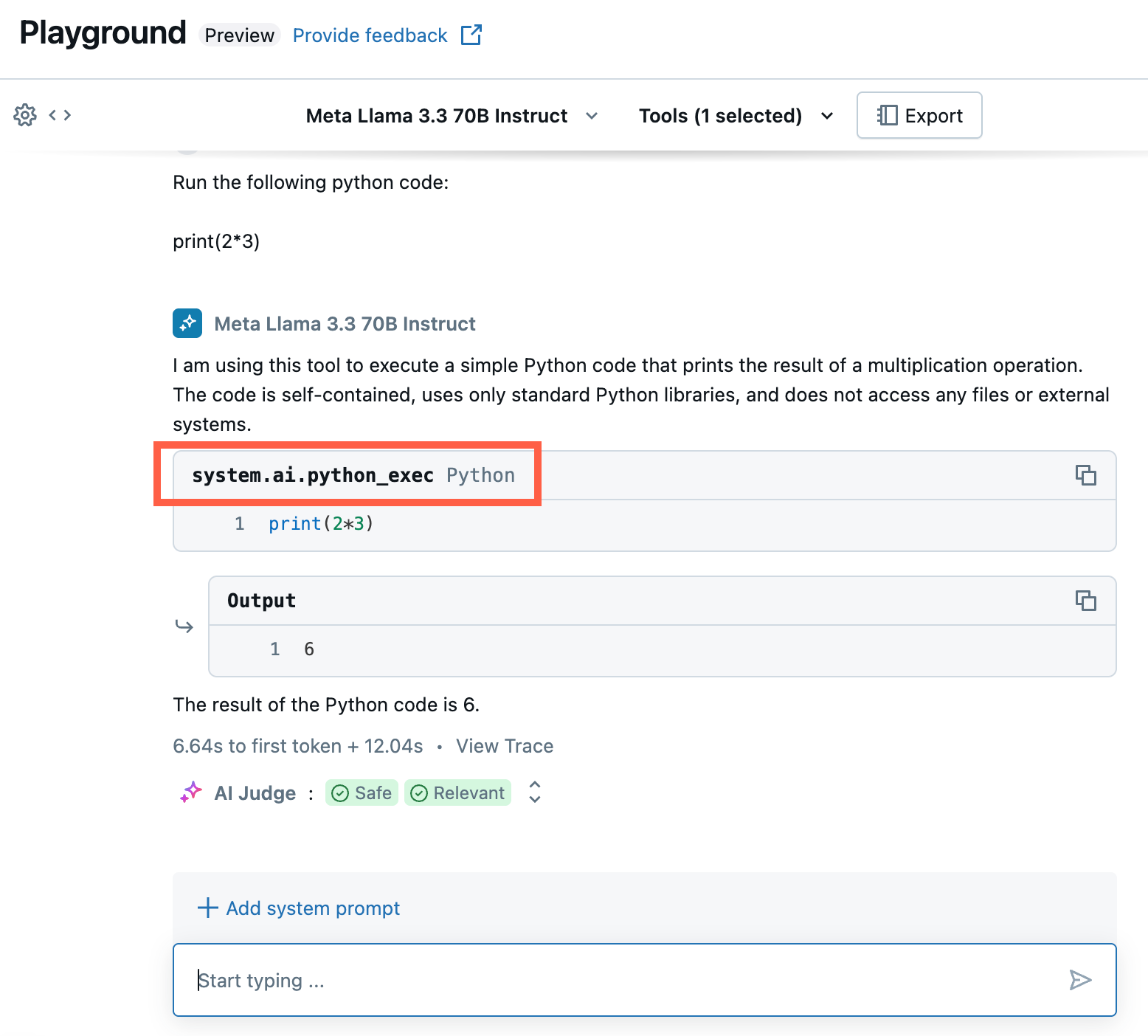
AI プレイグラウンド エージェントのエクスポートとデプロイ
AI Playground で AI エージェントのプロトタイプを作成して調整した後、それを Python ノートブックにエクスポートしてさらに開発したり、モデル サービス エンドポイントとして直接デプロイしたりできます。
[ Export をクリックして、AI エージェントの開発とデプロイに役立つ Python ノートブックを生成します。
エージェント コードをエクスポートすると、ワークスペースに次の 3 つのファイルが保存されます。
agentノートブック: LangChain を使用してエージェントを定義する Python コードが含まれています。driverノートブック: Mosaic AI エージェント フレームワークを使用して AI エージェントのログ記録、トレース、登録、デプロイを行う Python コードが含まれています。config.yml: ツール定義を含む、エージェントに関する構成情報が含まれます。
agentノートブックを開いてエージェントを定義する LangChain コードを表示します。このノートブックを使用して、より多くのツールの定義やエージェントのパラメーターの調整など、プログラムによってエージェントをテストして反復処理します。Note
エクスポートされたコードの動作は、AI プレイグラウンド セッションとは異なる場合があります。 Databricks では、エクスポートされたノートブックを実行して、さらに反復処理とデバッグを行い、エージェントの品質を評価してから、エージェントをデプロイして他のユーザーと共有することをお勧めします。
エージェントの出力に問題がなければ、
driverノートブックを実行して、エージェントをログに記録し、Model Serving エンドポイントにデプロイできます。
コードでエージェントを定義する
AI Playground からエージェント コードを生成するだけでなく、LangChain や Python コードなどのフレームワークを使用して、コードでエージェントを自分で定義することもできます。 エージェント フレームワークを使用してエージェントをデプロイするには、その入力が サポートされている入力形式と出力形式のいずれかに準拠している必要があります。
パラメーターを使用してエージェントを構成する
エージェント フレームワークでは、パラメーターを使用してエージェントの実行方法を制御できます。 これにより、コードを変更することなく、エージェントのさまざまな特性を使用して迅速に反復処理できます。 パラメーターは、Python ディクショナリまたは .yaml ファイルで定義するキーと値のペアです。
コードを構成するには、キーと値のパラメーターのセットである ModelConfig を作成します。 ModelConfig は Python ディクショナリまたは .yaml ファイルです。 たとえば、開発中にディクショナリを使用し、運用環境のデプロイと CI/CD 用の .yaml ファイルに変換できます。 ModelConfig の詳細については、MLflow のドキュメントを参照してください。
ModelConfig の例を次に示します。
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
コードから構成を呼び出すには、次のいずれかを使用します。
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
取得元スキーマを設定する
AI エージェントは、多くの場合、ベクター検索インデックスを使用して関連するドキュメントを検索して返す一種のエージェント ツールであるレトリバーを使用します。 レトリーバーの詳細については、非構造化検索 AI エージェントツールを参照してください。
レトリバーが正しくトレースされるようにするには、コードでエージェントを定義するときに mlflow.models.set_retriever_schema を呼び出します。 set_retriever_schemaを使用して、返されたテーブル内の列名を、primary_key、text_column、doc_uriなどの MLflow の予期されるフィールドにマップします。
# Define the retriever's schema by providing your column names
# These strings should be read from a config dictionary
mlflow.models.set_retriever_schema(
name="vector_search",
primary_key="chunk_id",
text_column="text_column",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
Note
doc_uri列は、レトリバーのパフォーマンスを評価する際に特に重要です。 doc_uri は、取得者によって返されるドキュメントの主な識別子であり、それらをグラウンド トゥルース評価セットと比較できます。 評価セットを参照してください
other_columns フィールドを使用して列名の一覧を指定することで、取得元のスキーマに追加の列を指定することもできます。
複数のレトリバーがある場合は、各レトリバー スキーマに一意の名前を使用して、複数のスキーマを定義できます。
サポートされている入力形式と出力形式
Agent Framework では、MLflow モデルシグネチャを使用して、エージェントの入力スキーマと出力スキーマを定義します。 モザイク AI エージェント フレームワークの機能では、レビュー アプリや AI プレイグラウンドなどの機能を操作するために、入力/出力フィールドの最小セットが必要です。 詳細については、「 エージェントの入力スキーマと出力スキーマを定義するを参照してください。
ノートブックの例
これらのノートブックは、Databricks でチェーン アプリケーションを作成する方法を示す単純な "Hello World" チェーンを作成します。 最初の例では、単純なチェーンを作成します。 2 番目のノートブック例では、開発中にパラメーターを使用してコードの変更を最小限に抑える方法を示します。