Python でチャット アプリの回答を評価する
この記事では、チャット アプリの回答を正しい回答または理想的な回答 (グラウンド トゥルースと呼ばれる) のセットと比較して評価する方法について説明します。 回答に影響を与えるような方法でチャット アプリケーションを変更するたびに、評価を実行して変更を比較します。 このデモ アプリケーションには、評価の実行を容易にするために現在使用できるツールが用意されています。
この記事の手順に従うと、次の操作を実行できます。
- 関心領域に合わせて調整したサンプル プロンプトを使用します。 これらのプロンプトは既にリポジトリにあります。
- 独自のドキュメントから、ユーザーへのサンプルの質問とそれらのグラウンド トゥルースの回答を生成します。
- 生成されたユーザーの質問と共にサンプル プロンプトを使用して評価を実行します。
- 回答の分析を確認します。
Note
この記事では、記事内の例とガイダンスの土台として、1 つ以上の AI アプリ テンプレートを使用しています。 AI アプリ テンプレートを使用すると、デプロイが容易な保守性の高い参照実装が提供されます。 AI アプリの高品質な開始点を確保するのに役立ちます。
アーキテクチャの概要
アーキテクチャの主なコンポーネントは次のとおりです:
- Azure ホステッド チャットアプリ: チャットアプリは Azure App Service で実行されます。
- Microsoft AI チャット プロトコル: このプロトコルは、AI ソリューションと言語全体で標準化された API コントラクトを提供します。 チャット アプリは Microsoft AI チャット プロトコルに準拠しているため、このプロトコルに準拠する任意のチャット アプリに対して評価を実行できます。
- Azure AI Search: チャット アプリは Azure AI Search を使用して、独自のドキュメントのデータを保存します。
- サンプル質問生成ツール: このツールは、ドキュメントごとに多数の質問とそれらのグラウンド トゥルースを生成できます。 質問が多いほど、評価が長くなります。
- エバリュエーター: ツールは、チャット アプリに対してサンプルの質問とプロンプトを実行し、結果を返します。
- レビュー ツール: ツールは、評価の結果を確認します。
- Diff ツール: ツールは評価間で回答を比較します。
この評価を Azure にデプロイすると、独自の 容量を持つ GPT-4 モデル用に Azure OpenAI サービス エンドポイントが作成されます。 チャット アプリケーションを評価するときは、エバリュエーターが独自の容量を持つ GPT-4 を使用して、独自の Azure OpenAI リソースを持っている必要があります。
前提条件
Azure サブスクリプション。 無料でひとつ作成する。
チャット アプリを Azure にデプロイするには、前のチャット アプリの手順 を完了します。 このリソースは、評価が機能するために必要です。 前の手順の「リソースのクリーンアップ」セクションを完了しないでください。
そのデプロイ (この記事ではチャット アプリと呼んでいます) から次の Azure リソース情報が必要になります。
- Chat API URI。
azd upプロセスの最後に表示されるサービス バックエンド エンドポイント。 - Azure AI Search。 次の値が必要です。
- リソース名:
azd upプロセス中にSearch serviceとして報告される Azure AI Search リソース名の名前。 - インデックス名: ドキュメントが格納されている Azure AI Search インデックスの名前。 検索サービスについては、Azure portal で確認できます。
- リソース名:
チャット API URL を使用すると、評価はバックエンド アプリケーションを介して要求を行うことができます。 Azure AI 検索情報を使用すると、評価スクリプトは、ドキュメントと共に読み込まれたバックエンドと同じデプロイを使用できます。
この情報を収集したら、チャット アプリ開発環境をもう一度使用する必要はありません。 この記事では、評価アプリでチャット アプリがどのように使用されるかを示すために、後で数回参照します。 この記事の手順全体を完了するまで、チャット アプリリソースを削除しないでください。
- Chat API URI。
開発コンテナー 環境には、この記事を完了するために必要なすべての依存関係が用意されています。 開発コンテナーは、GitHub Codespaces (ブラウザー) で実行することも、Visual Studio Code を使用してローカルで実行することもできます。
- GitHub アカウント
開発環境を開く
この記事を完了するため、すべての依存関係がインストールされている開発環境から始めます。 このドキュメントと開発環境を同時に表示できるように、モニター ワークスペースを配置します。
この記事は、評価デプロイの switzerlandnorth リージョンでテストされました。
GitHub Codespaces は、 Visual Studio Code for the Web をユーザー インターフェイスとして使用して、GitHub によって管理される開発コンテナーを実行します。 最も簡単な開発環境では、GitHub Codespaces を使用して、この記事を完了するために正しい開発者ツールと依存関係がプレインストールされるようにします。
重要
すべての GitHub アカウントでは、2 つのコア インスタンスで毎月最大 60 時間無料で GitHub Codespaces を使用できます。 詳細については、「GitHub Codespaces に月単位で含まれるストレージとコア時間」を参照してください。
Azure-Samples/ai-rag-chat-evaluator GitHub リポジトリの
mainブランチに新しい GitHub コードスペースを作成するプロセスを開始します。開発環境と使用可能なドキュメントを同時に表示するには、次のボタンを右クリックし、[新しいウィンドウでリンクを開く] 選択。

Create codespace のページで、コードスペースの構成設定を確認し、新しいコードスペースを作成するには、を選択します。 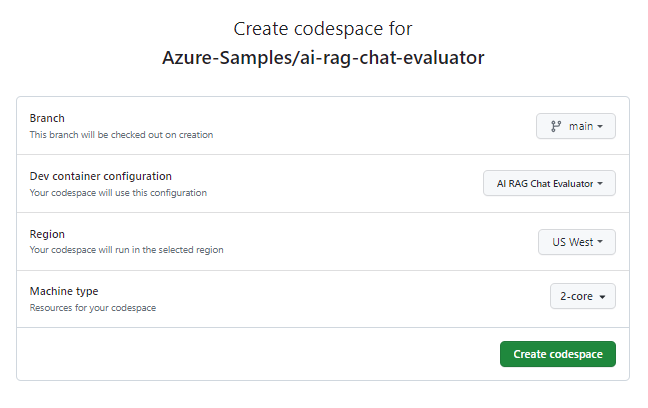
Codespace が起動するまで待ちます。 この起動プロセスには数分かかることがあります。
画面の下部にあるターミナルで、Azure Developer CLI を使用して Azure にサインインします。
azd auth login --use-device-codeターミナルからコードをコピーし、ブラウザーに貼り付けます。 手順に従って、Azure アカウントで認証します。
評価アプリに必要な Azure リソース Azure OpenAI Service をプロビジョニングします。
azd upこの
AZDコマンドは評価アプリをデプロイしませんが、ローカル開発環境で評価を実行するために必要なGPT-4デプロイで Azure OpenAI リソースを作成します。
この記事の残りのタスクは、この開発コンテナーのコンテキストで行われます。
GitHub リポジトリの名前が検索バーに表示されます。 このビジュアル インジケーターは、評価アプリとチャット アプリを区別するのに役立ちます。 この記事で、この ai-rag-chat-evaluator リポジトリは 評価アプリ として参照されます。

環境値と構成情報を準備する
評価アプリの前提条件
.env.sampleに基づいて.envファイルを作成します。cp .env.sample .envこのコマンドを実行して、デプロイされたリソース グループから
AZURE_OPENAI_EVAL_DEPLOYMENTとAZURE_OPENAI_SERVICEに必要な値を取得します。 これらの値を.envファイルに貼り付けます。azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICEAzure AI Search インスタンスのチャット アプリから、
.envファイルに次の値を追加します。このファイルは、「前提条件」セクションで収集しました。AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
構成情報に Microsoft AI チャット プロトコルを使用する
チャット アプリと評価アプリの両方に、使用と評価に使用される、オープンソース、クラウド、言語に依存しない AI エンドポイント API コントラクトである Microsoft AI チャット プロトコル仕様が実装されています。 クライアントと中間層のエンドポイントがこの API 仕様に準拠している場合は、AI バックエンドで評価を一貫して使用して実行できます。
my_config.jsonという名前の新規ファイルを作成して、それに次の内容をコピーします。{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }評価スクリプトによって、
my_resultsフォルダーが作成されます。overridesオブジェクトには、アプリケーションに必要な構成設定が含まれています。 各アプリケーションは、独自の設定プロパティのセットを定義します。次の表を使用して、チャット アプリに送信される設定プロパティの意味を理解します。
プロパティの設定 説明 semantic_rankerセマンティック ランカーを使用するかどうか。これは、ユーザーのクエリに対するセマンティック類似性に基づいて検索結果を再ランク付けするモデルです。 このチュートリアルでは、コストを削減するために無効にします。 retrieval_mode使用する取得モード。 既定値は、 hybridです。temperatureモデルの温度設定。 既定値は、 0.3です。top返す検索結果の数。 既定値は、 3です。prompt_template質問と検索結果に基づいて回答を生成するために使用されるプロンプトのオーバーライド。 seedGPT モデルへの呼び出しのシード値。 シードを設定すると、評価間でより一貫性のある結果が得られます。 target_url値をチャット アプリの URI 値に変更します。この値は、「前提条件の」セクションで収集しました。 チャット アプリは、チャット プロトコルに準拠している必要があります。 URI の形式は次のとおりです:https://CHAT-APP-URL/chat。 プロトコルとchatルートが URI の一部であることを確認してください。
サンプル データを作成する
新しい回答を評価するには、特定の質問に対する理想的な答えである 地上の真理 答えと比較する必要があります。 チャット アプリの Azure AI Search に格納されているドキュメントから質問と回答を生成します。
example_inputフォルダーをmy_inputという名前の新しいフォルダーにコピーします。ターミナルで、次のコマンドを実行してサンプル データを生成します。
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
質問と回答のペアは生成され、次の手順で使用するエバリュエーターへの入力として my_input/qa.jsonl (JSONL 形式ので) 格納されます。 運用環境の評価では、より多くの質問と回答のペアを生成します。 このデータセットに対して 200 を超えるデータが生成されます。
Note
この手順をすばやく完了できるように、ソースごとにいくつかの質問と回答が生成されます。 これは運用環境の評価ではなく、ソースごとにさらに多くの質問と回答が必要です。
絞り込まれたプロンプトで最初の評価を実行する
my_config.json構成ファイルのプロパティを編集します。プロパティ 新しい値 results_dirmy_results/experiment_refinedprompt_template<READFILE>my_input/prompt_refined.txt調整したプロンプトは関心領域について具体的です。
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers, ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information, return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by a colon and the actual information. Always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].ターミナルで、次のコマンドを実行して評価を実行します。
python -m evaltools evaluate --config=my_config.json --numquestions=14このスクリプトにより、評価を含む新しい実験フォルダーが
my_results/に作成されました。 フォルダーには、評価の結果が含まれています。ファイル名 説明 config.json評価に使用される構成ファイルのコピー。 evaluate_parameters.json評価に使用されるパラメーター。 config.jsonに似ていますが、タイムスタンプなどの他のメタデータが含まれています。eval_results.jsonl各質問および回答と、各質問/回答ペアに関する GPT メトリック。 summary.json平均 GPT メトリックなどの全体的な結果。
弱いプロンプトで 2 番目の評価を実行する
my_config.json構成ファイルのプロパティを編集します。プロパティ 新しい値 results_dirmy_results/experiment_weakprompt_template<READFILE>my_input/prompt_weak.txtこの弱いプロンプトには、サブジェクト ドメインに関するコンテキストはありません。
You are a helpful assistant.ターミナルで、次のコマンドを実行して評価を実行します。
python -m evaltools evaluate --config=my_config.json --numquestions=14
特定の温度で 3 番目の評価を実行する
より創造的な回答を得るためのプロンプトを使用します。
my_config.json構成ファイルのプロパティを編集します。Existing プロパティ 新しい値 Existing results_dirmy_results/experiment_ignoresources_temp09Existing prompt_template<READFILE>my_input/prompt_ignoresources.txt新しい temperature0.9既定の
temperatureは 0.7 です。 温度が高いほど、回答はより創造的になります。ignoreプロンプトは短い形式です。Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!results_dirをパスに置き換えた点を除き、構成オブジェクトは次の例のようになります。{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }ターミナルで、次のコマンドを実行して評価を実行します。
python -m evaltools evaluate --config=my_config.json --numquestions=14
評価の結果を確認する
さまざまなプロンプトとアプリ設定に基づいて 3 つの評価を実行しました。 結果は my_results フォルダーに保存されています。 設定に基づいて結果がどのように異なるかを確認します。
レビュー ツールを使用して、評価の結果を確認します。
python -m evaltools summary my_results結果は次のようになります。

各値は数値とパーセンテージとして返されます。
以下の表を使用して、値の意味を理解します。
Value 説明 現実性 モデルの応答が、実際の検証可能な情報に基づいてどの程度適切であるかを確認します。 回答が事実に基づき現実を反映している場合、その回答は根拠があると見なされます。 関連性 モデルの応答がコンテキストまたはプロンプトにどの程度近いかを測定します。 回答がユーザーの質問や発言に過不足なく対処している場合、関連性があると見なされます。 一貫性 モデルの応答の論理的な整合性を確認します。 回答が一貫していて論理的な流れを保っている場合、矛盾しないと見なされます。 引用 プロンプトで要求された形式で回答が返されたかどうかを示します。 長さ 応答の長さを測定します。 結果は、3 つの評価すべてが高い関連性を持ち、
experiment_ignoresources_temp09の関連性が最も低かったことを示す必要があります。評価の構成を表示するフォルダーを選択します。
Ctrl
C 入力してアプリを終了し、ターミナルに戻ります。
回答を比較する
評価から返された回答を比較します。
比較する評価の 2 つを選択し、同じレビュー ツールを使用して回答を比較します。
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09結果を確認します。 結果は異なる場合があります。

Ctrl
C 入力してアプリを終了し、ターミナルに戻ります。
さらなる評価のための提案
my_inputのプロンプトを編集して、関心領域や長さなど、回答をカスタマイズします。my_config.jsonファイルを編集して、temperatureやsemantic_rankerなどのパラメーターを変更し、実験を再実行します。- さまざまな回答を比較して、プロンプトと質問が回答の質にどのような影響を与えるかを理解します。
- Azure AI Search インデックス内のドキュメントごとに、質問とグラウンド トゥルースの回答の個別のセットを生成します。 その後、評価を再実行して、回答がどのように異なるかを確認します。
- プロンプトの最後に要件を追加することで、より短いまたは長い回答を示すようにプロンプトを変更します。 例として、
Please answer in about 3 sentences.
リソースと依存関係をクリーンアップする
次の手順では、使用したリソースをクリーンアップするプロセスについて説明します。
Azure リソースをクリーンアップする
この記事で作成した Azure リソースは、Azure サブスクリプションに課金されます。 今後これらのリソースが必要になるとは思わない場合は、削除して、より多くの料金が発生しないようにします。
Azure リソースを削除してソース コードを削除するには、次の Azure Developer CLI コマンドを実行します。
azd down --purge
GitHub Codespaces と Visual Studio Code をクリーンアップする
GitHub Codespaces 環境を削除すると、アカウントに対して取得するコア時間単位の無料エンタイトルメントの量を最大化できます。
重要
GitHub アカウントのエンタイトルメントの詳細については、「 GitHub Codespaces に月単位で含まれるストレージとコア時間」を参照してください。
GitHub Codespaces ダッシュボードにサインインします。
Azure-Samples/ai-rag-chat-evaluator GitHub リポジトリから入手した現在実行中のコードスペースを見つけます。
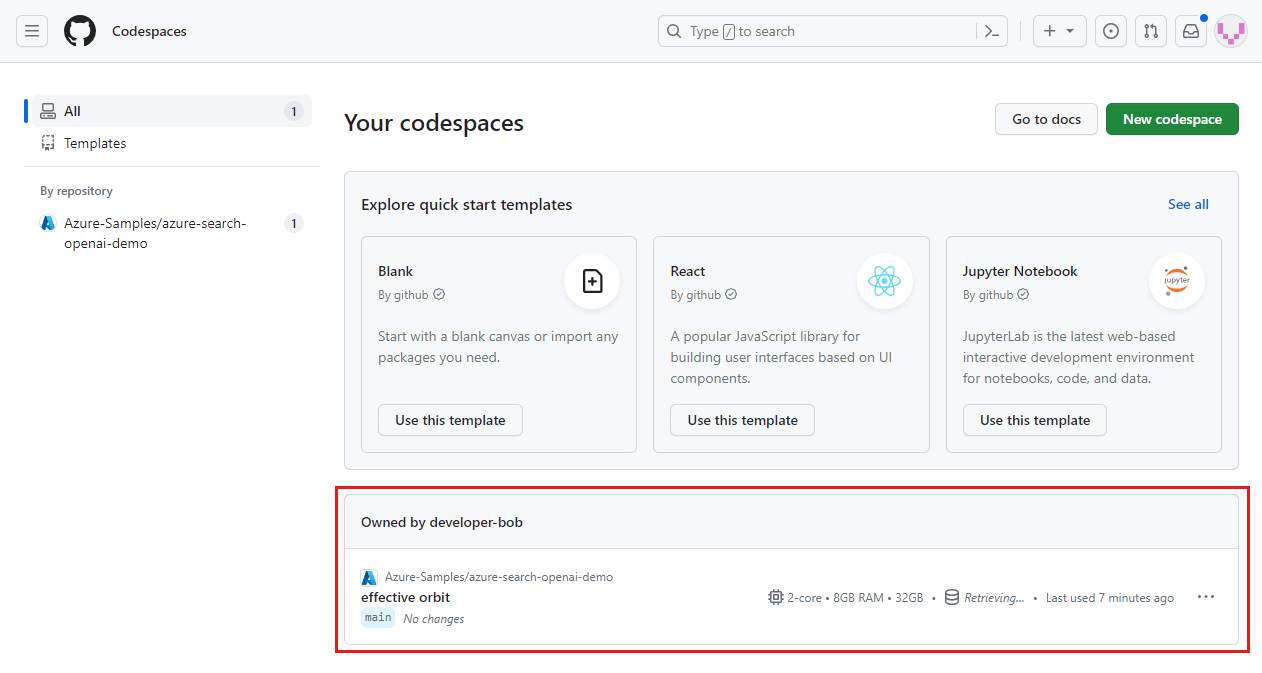
コードスペースのコンテキスト メニューを開き、[
削除] を選択します。 ![[削除] オプションが強調表示されている 1 つのコードスペースのコンテキスト メニューを示すスクリーンショット。](../ai/media/get-started-app-chat-evaluations/github-codespace-delete.png)
これらのリソースをクリーンアップするには、チャット アプリの記事に戻ります。
関連コンテンツ
- 評価リポジトリを参照してください。
- エンタープライズ チャット アプリの GitHub リポジトリを参照してください。
- Azure OpenAI ベスト プラクティス ソリューション アーキテクチャを使用して
チャット アプリを構築します。 - Azure AI Searchを使用した生成 AI アプリでの
アクセス制御について説明します。 - Azure API Managementを使用して、エンタープライズ対応の
Azure OpenAI ソリューションを構築します。 - 「Azure AI Search:ベクター検索を上回るハイブリッド取得とランク付け機能をご確認ください。」