クイック スタート:Azure portal を使用して Azure HDInsight 内に Apache Hadoop クラスターを作成する
この記事では、Azure portal を使用して HDInsight で Apache Hadoop クラスターを作成し、HDInsight で Apache Hive ジョブを実行する方法について説明します。 Hadoop ジョブのほとんどはバッチ ジョブです。 クラスターを作成し、いくつかのジョブを実行して、クラスターを削除します。 この記事では、3 つのすべてのタスクを実行します。 使用できる構成の詳細については、HDInsight でクラスターを設定する方法に関するページを参照してください。 ポータルを使用したクラスター作成の詳細については、ポータルでクラスターを作成する方法に関するページを参照してください。
このクイック スタートでは、Azure Portal を使用して HDInsight Hadoop クラスターを作成します。 また、Azure Resource Manager テンプレートを使用して、クラスターを作成することもできます。
現在、HDInsight には 7 種類のクラスターが用意されています。 クラスターの種類はそれぞれ異なるコンポーネント セットをサポートしていますが、 Hive は全種類のクラスターでサポートされています。 HDInsight でサポートされているコンポーネントの一覧については、Azure HDInsight で提供される Hadoop クラスター バージョンの新機能に関するページを参照してください。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
Apache Hadoop クラスターを作成する
このセクションでは、Azure Portal を使用して HDInsight で Hadoop クラスターを作成します。
Azure portal にサインインします。
上部のメニューで、 [+ リソースの作成] を選択します。
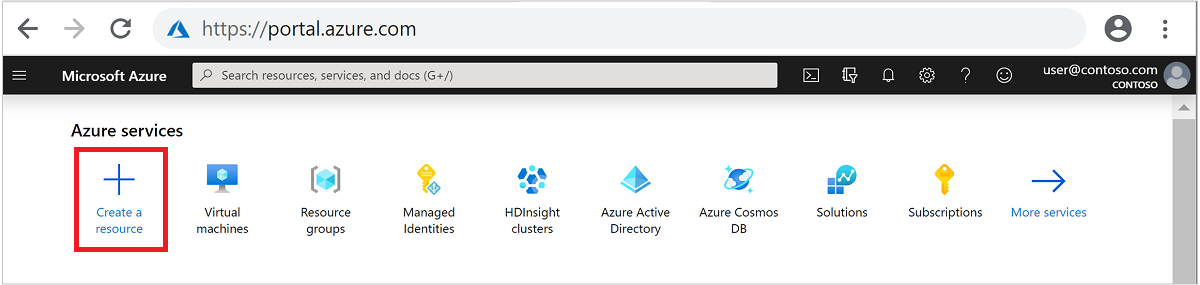
[分析]>[Azure HDInsight] の順に選択して [HDInsight クラスターの作成] ページに移動します。
[基本] タブで次の情報を指定します。
プロパティ 説明 サブスクリプション ドロップダウン リストから、このクラスターに使用する Azure サブスクリプションを選択します。 Resource group ドロップダウン リストから既存のリソース グループを選択するか、 [新規作成] を選択します。 クラスター名 グローバルに一意の名前を入力します。 この名前は、文字、数字、ハイフンを含む最大 59 文字で構成できます。 名前の先頭と末尾の文字をハイフンにすることはできません。 リージョン クラスターの作成先となるリージョンをドロップダウン リストから選択します。 パフォーマンスを向上させるため、お近くの場所を選択してください。 クラスターの種類 [クラスターの種類の選択] を選択します。 クラスターの種類として [Hadoop] を選択します。 Version ドロップダウン リストからバージョンを選択します。 どれを選択すべきかわからない場合は、既定のバージョンを使用します。 クラスターのサインイン ユーザー名とパスワード 既定のサインインは admin です。パスワードは 10 文字以上で、数字、大文字、小文字、英数字以外の文字 ( ' ` "を除く) をそれぞれ 1 文字以上含む必要があります。 "Pass@word1" などのよく使われるパスワードを指定していないことを確認してください。Secure Shell (SSH) ユーザー名 既定のユーザー名は sshuserです。 SSH ユーザー名に別の名前を指定できます。SSH にクラスター サインイン パスワードを使用する クラスター サインイン ユーザーに指定したのと同じパスワードを SSH ユーザーに使用する場合は、このチェック ボックスをオンにします。 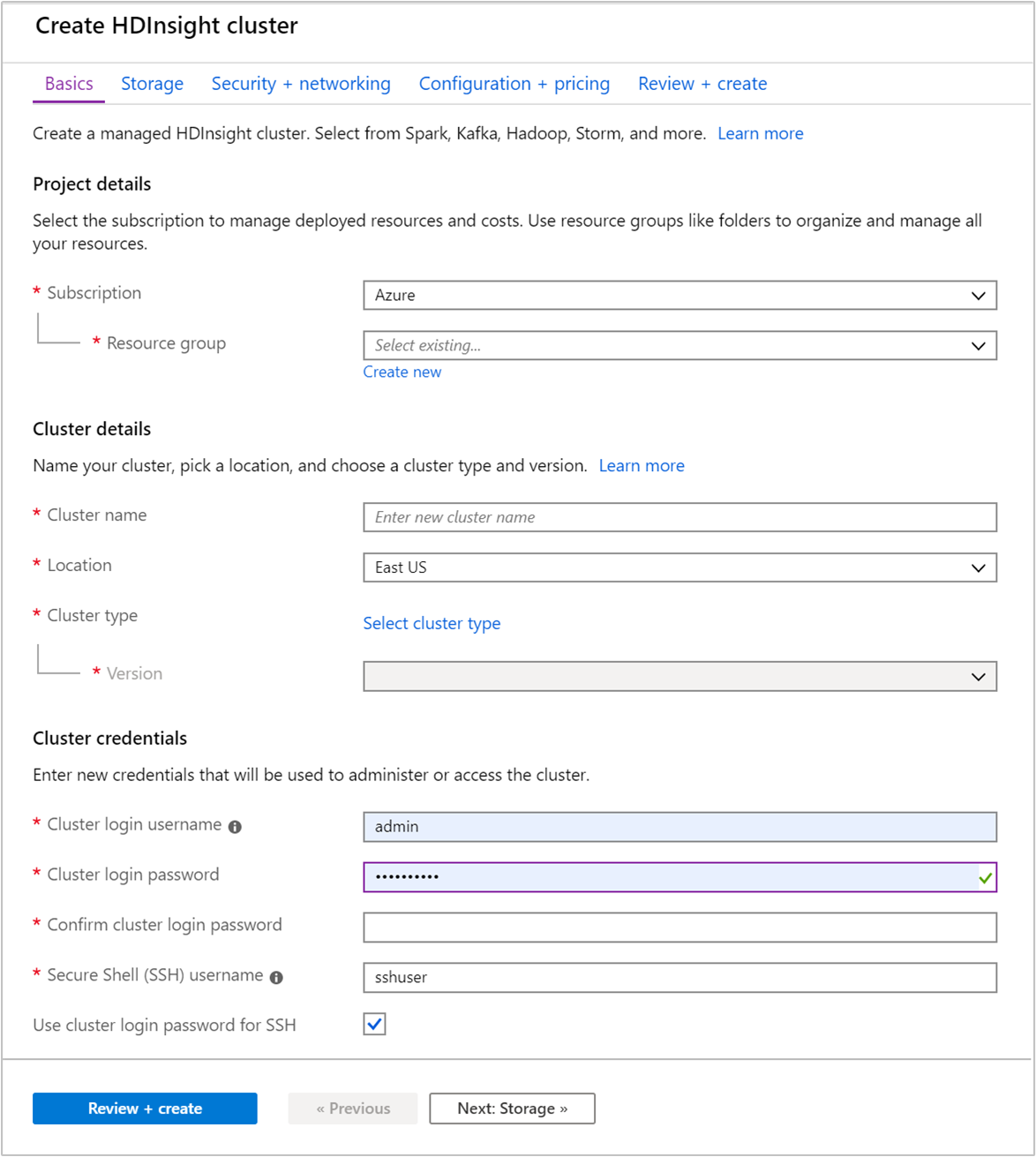
ページの下部にある [次へ: ストレージ >>] を選択して、ストレージの設定に進みます。
[ストレージ] タブから次の値を指定します。
プロパティ 説明 プライマリ ストレージの種類 既定値の [Azure Storage] を使用します。 メソッドの選択 既定値の [一覧から選択する] を使用します。 プライマリ ストレージ アカウント ドロップダウン リストを使用して既存のストレージ アカウントを選択するか、または [新規作成] を選択します。 新しいアカウントの作成時には、名前の長さは 3 から 24 文字とし、数字と小文字のみを使用できます コンテナー 自動入力されている値を使用します。 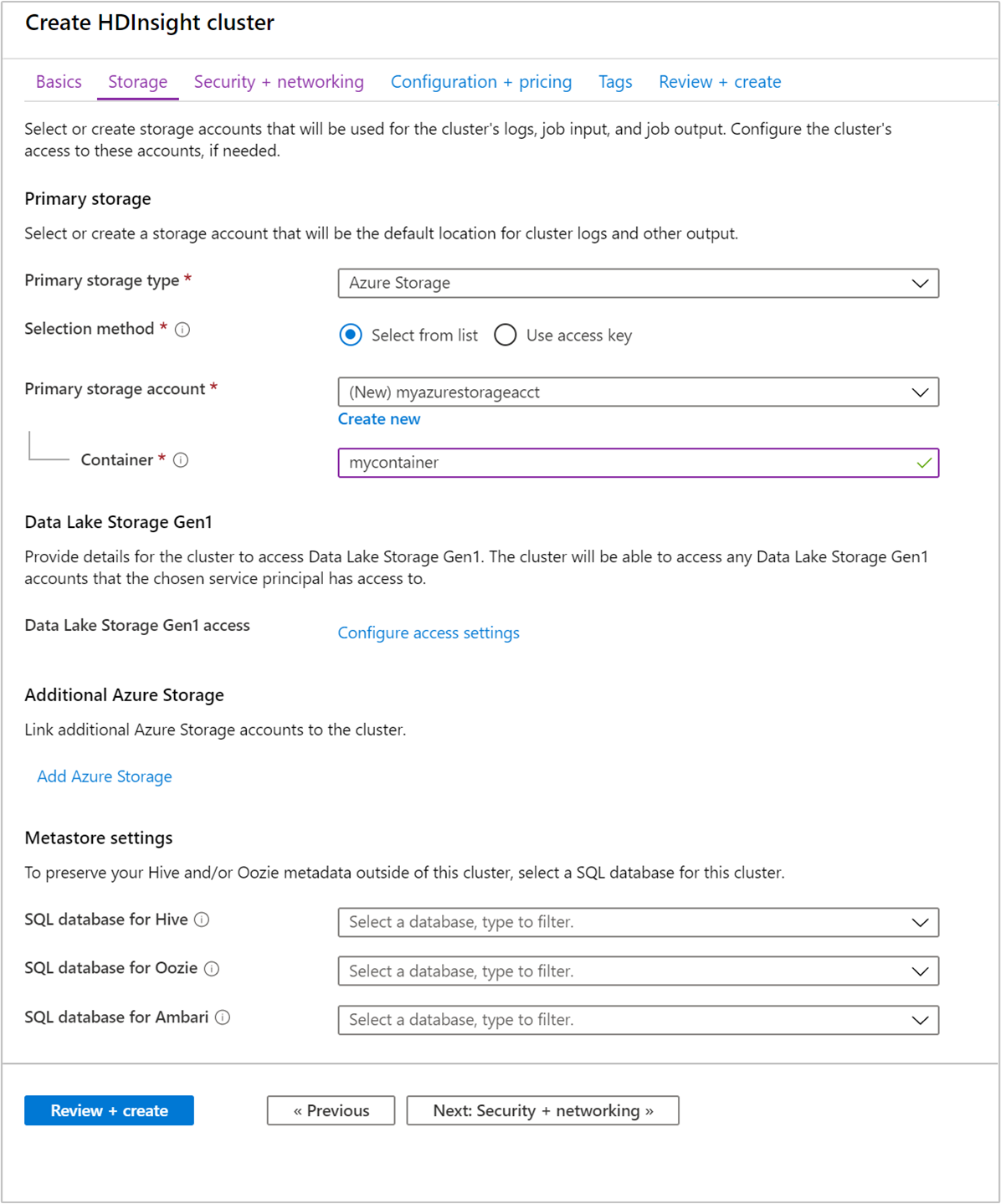
各クラスターには Azure Storage アカウント、または
Azure Data Lake Storage Gen2の依存関係があります。 このアカウントを、既定のストレージ アカウントと呼びます。 HDInsight クラスターとその既定のストレージ アカウントは、同じ Azure リージョンに配置されている必要があります。 クラスターを削除しても、ストレージ アカウントは削除されません。[確認および作成] タブを選択します。
[Review + create](確認と作成) タブで、前の手順で選択した値を確認します。
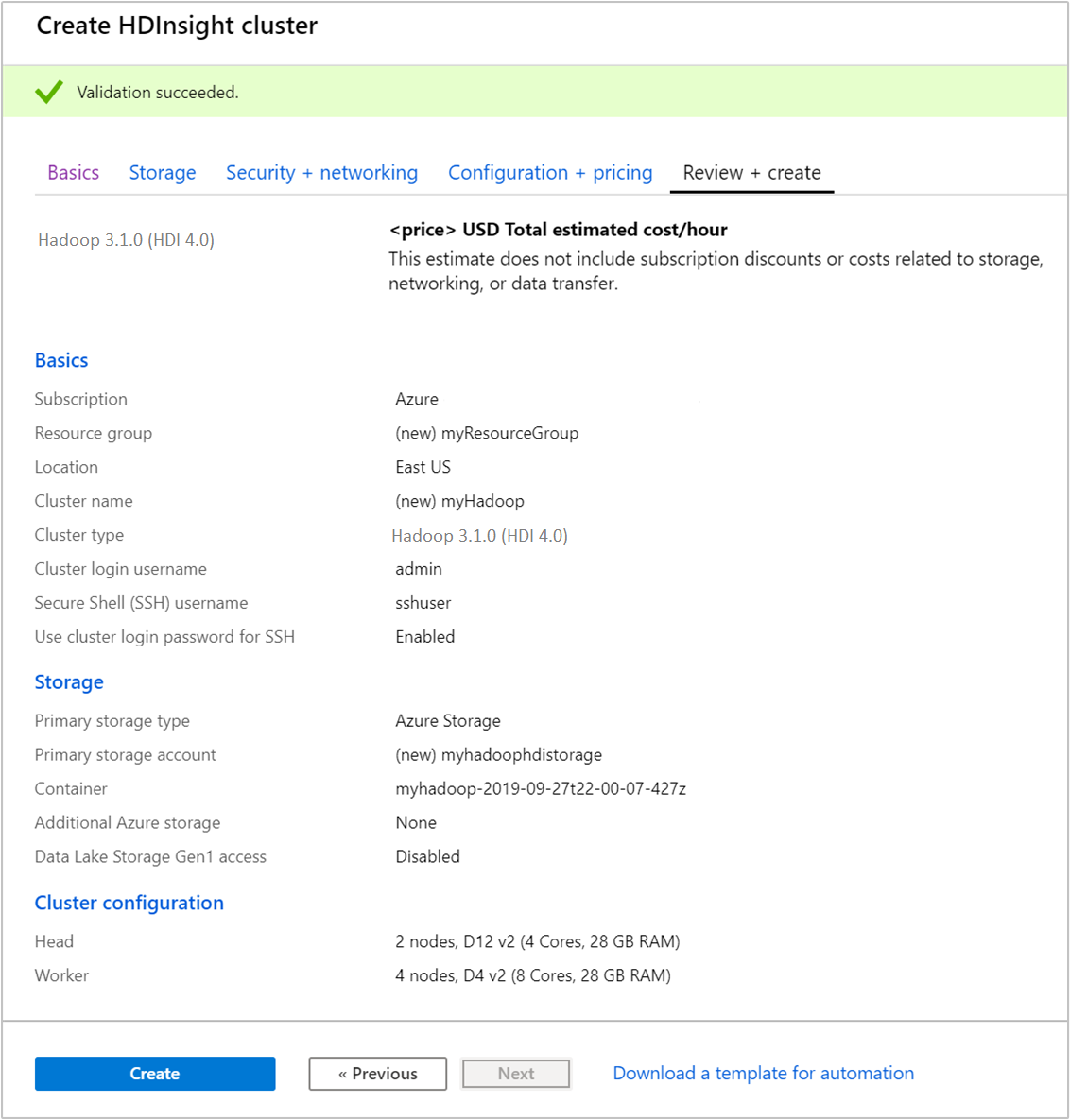
[作成] を選択します クラスターの作成には約 20 分かかります。
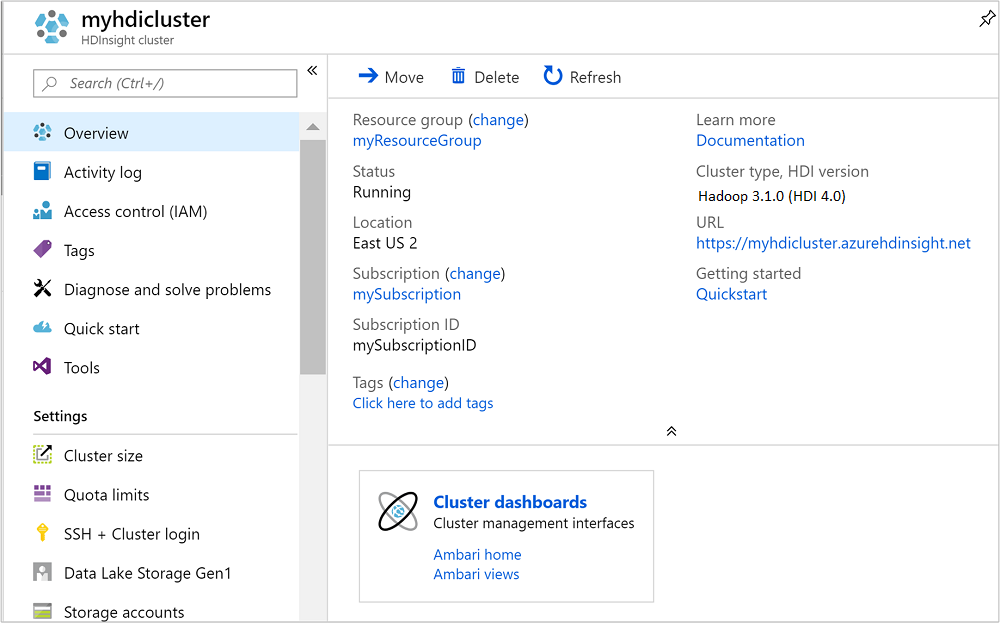
クラスターが作成されると、Azure Portal にクラスターの概要ページが表示されます。
Apache Hive クエリの実行
Apache Hive は、HDInsight で使用される最も一般的なコンポーネントです。 HDInsight で Hive ジョブを実行する方法は多数存在します。 このクイックスタートでは、ポータルから Ambari Hive ビューを使用します。 Hive ジョブを送信する他の方法については、「 HDInsight で Hadoop と共に Hive と HiveQL を使用して Apache log4j サンプル ファイルを分析する」を参照してください。
注意
HDInsight 4.0 では、Apache Hive ビューは使用できません。
Ambari を開くには、前のスクリーンショットから、 [クラスター ダッシュボード] を選択します。
https://ClusterName.azurehdinsight.netを参照することもできます。このClusterNameは前のセクションで作成したクラスターです。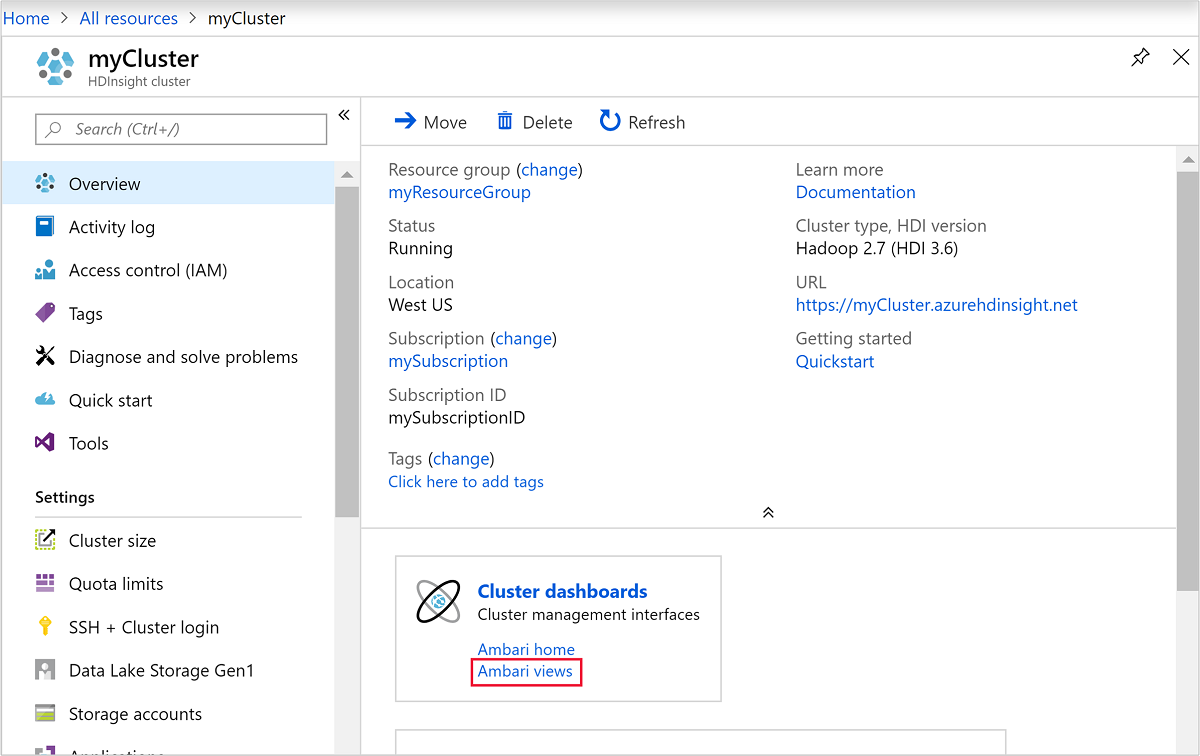
クラスターの作成時に指定した Hadoop ユーザー名とパスワードを入力します。 既定のユーザー名は
adminです。次のスクリーンショットのように [ハイブ ビュー] を開きます。
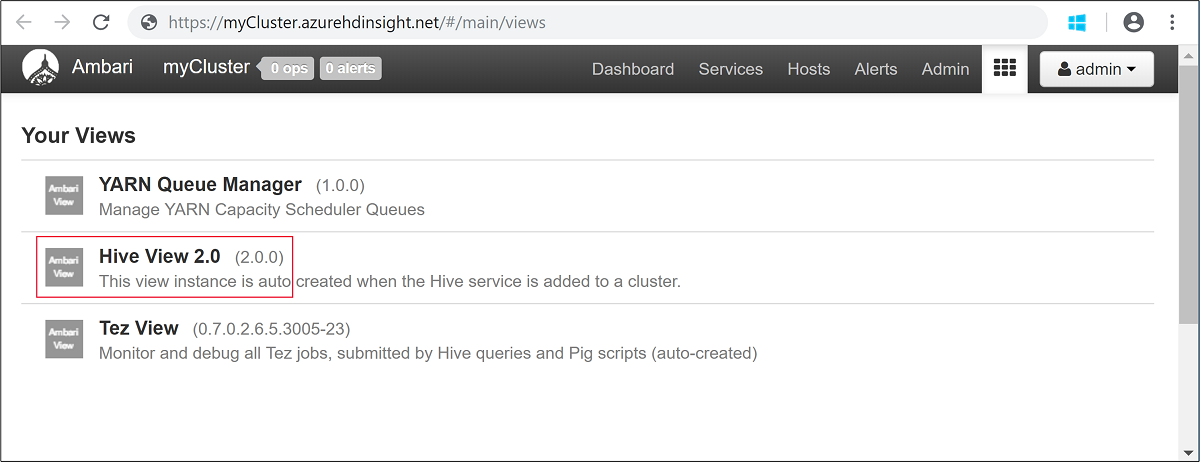
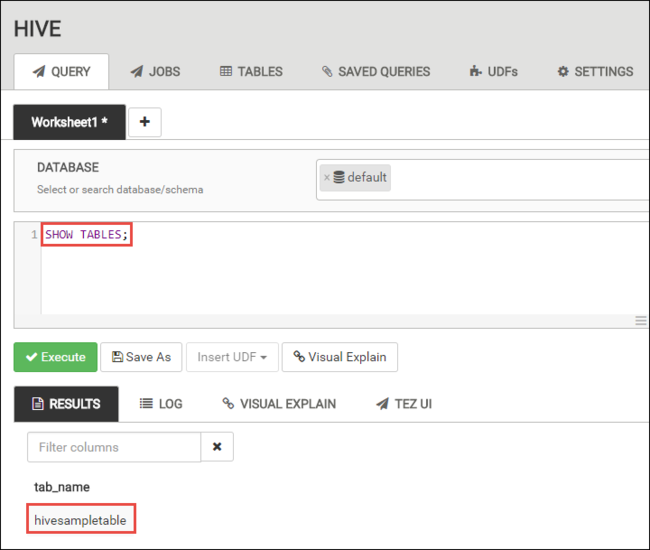
[QUERY](クエリ) タブで、次の HiveQL ステートメントをワークシートに貼り付けます。
SHOW TABLES;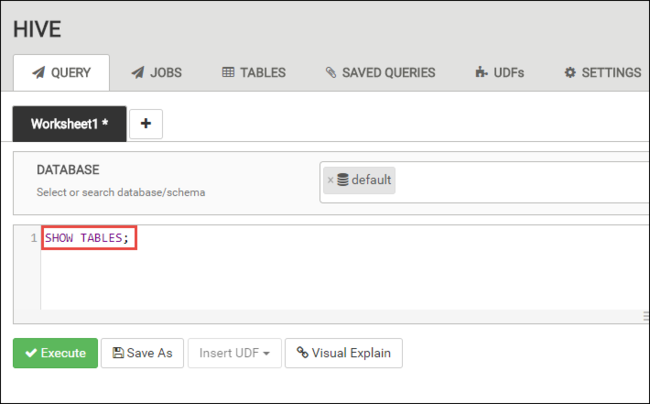
[実行] を選択します。 [QUERY](クエリ) タブの下に [RESULTS](結果) タブが表示され、ジョブについての情報が表示されます。
クエリが完了すると、 [QUERY](クエリ) タブに操作の結果が表示されます。 hivesampletableという名前のテーブルが 1 つ表示されます。 このサンプルの Hive テーブルにはすべての HDInsight クラスターが付属します。
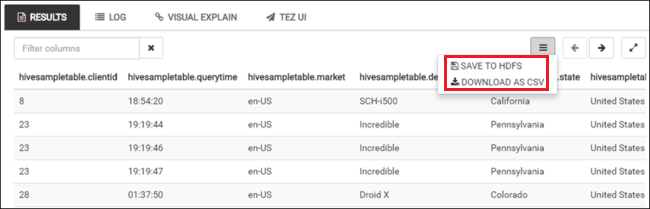
手順 4. と手順 5 を繰り返し、次のクエリを実行します。
SELECT * FROM hivesampletable;クエリの結果を保存することもできます。 右側のメニュー ボタンを選択し、結果を CSV ファイルとしてダウンロードするか、クラスターに関連付けられているストレージ アカウントに保存するかを指定します。
Hive ジョブが完了したら、結果を Azure SQL Database または SQL Server データベースにエクスポートできます。Excel を利用して結果を視覚化することもできます。 HDInsight で Hive を使用する方法の詳細については、HDInsight で Apache Hadoop と共に Apache Hive と HiveQL を使用して Apache Log4j サンプル ファイルを分析する方法に関するページを参照してください。
リソースをクリーンアップする
このクイックスタートを完了したら、必要に応じてクラスターを削除できます。 HDInsight を使用すると、データは Azure Storage に格納されるため、クラスターは、使用されていない場合に安全に削除できます。 また、HDInsight クラスターは、使用していない場合でも課金されます。 クラスターの料金は Storage の料金の何倍にもなるため、クラスターを使用しない場合は削除するのが経済的にも合理的です。
注意
すぐに次の記事に進み、HDInsight で Hadoop を使用して ETL 操作を実行する方法を学習する場合は、クラスターを実行したままにしておいてかまいません。 これは、そのチュートリアルでは Hadoop クラスターを再度作成する必要があるからです。 ただし、すぐに次の記事に進まない場合は、クラスターを今すぐ削除する必要があります。
クラスターと既定のストレージ アカウントを削除するには
ブラウザーの Azure Portal を開いているタブに戻ります。 [クラスターの概要] ページが表示されているはずです。 クラスターのみを削除し、既定のストレージ アカウントを保持する場合は、 [削除] を選択します。
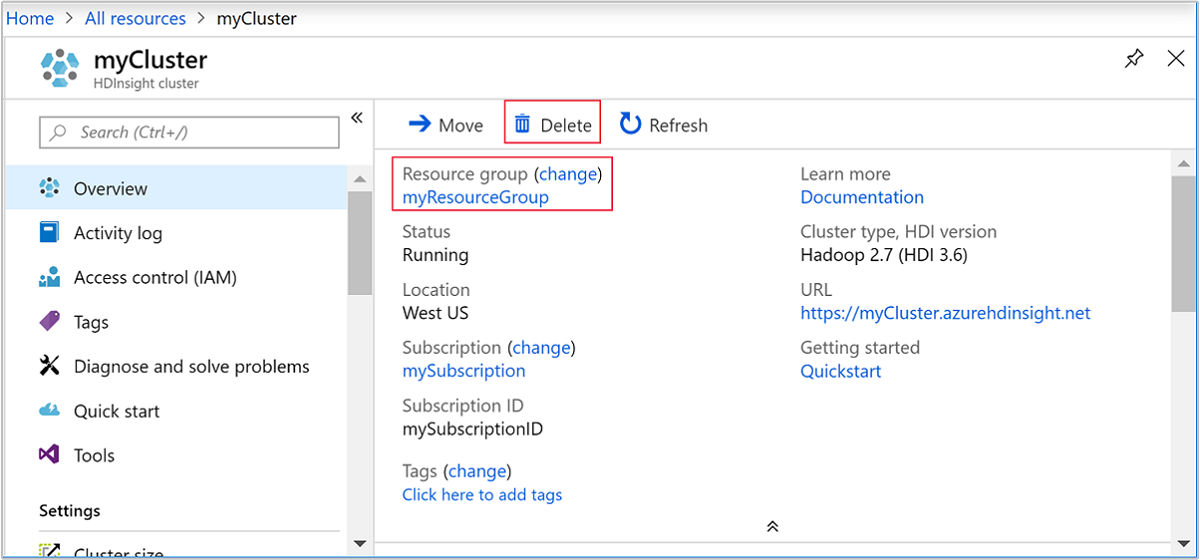
クラスターと既定のストレージ アカウントを削除する場合は、(上のスクリーンショットで強調表示されている) リソース グループ名を選択して、リソース グループのページを開きます。
[リソース グループの削除] を選択して、クラスターと既定のストレージ アカウントが含まれたリソース グループを削除します。 リソース グループを削除するとストレージ アカウントも削除されます。 ストレージ アカウントを残しておく場合は、クラスターのみを削除してください。
次のステップ
このクイックスタートでは、Resource Manager テンプレートを利用して Linux ベースの HDInsight クラスターを作成する方法と基本的な Hive クエリを実行する方法について学習しました。 次の記事では、HDInsight で Hadoop を使用して抽出、変換、読み込み (ETL) 操作を実行する方法を学習します。