Apache Spark の設定を構成する
HDInsight Spark クラスターには、Apache Spark ライブラリのインストールが含まれています。 各 HDInsight クラスターには、Spark も含め、インストールされるすべてのサービスの既定の構成パラメーターが含まれています。 HDInsight Apache Hadoop クラスターの管理の重要な側面は、Spark ジョブを含むワークロードを監視することです。 Spark ジョブを最高の状態で実行するには、クラスターの論理構成を決定するときに、物理クラスターの構成を検討します。
既定の HDInsight Apache Spark クラスターには、3 つの Apache ZooKeeper ノード、2 つのヘッド ノード、および 1 つ以上のワーカー ノードが含まれています。
HDInsight クラスター内のノードの VM の数と VM のサイズも、Spark の構成に影響します。 HDInsight の構成が既定値ではない場合は、通常、Spark の構成にも既定ではない値が必要です。 HDInsight Spark クラスターを作成するときに、各コンポーネントの推奨される VM サイズが表示されます。 現在、Azure に対するメモリ最適化された Linux VM のサイズは、D12 v2 以上です。
Apache Spark のバージョン
クラスターに最適な Spark バージョンを使用します。 HDInsight サービスには、複数のバージョンの Spark および HDInsight 自体の両方が含まれます。 Spark の各バージョンには、既定のクラスター設定のセットが含まれます。
新しいクラスターを作成するときに、Spark のバージョンを複数のバージョンの中から選ぶことができます。 完全な一覧については、HDInsight のコンポーネントとバージョンに関するページを参照してください。
注意
HDInsight サービスに含まれる Apache Spark の既定のバージョンは、予告なく変更される場合があります。 バージョンの依存関係がある場合は、.NET SDK、Azure PowerShell、Azure クラシック CLI を使ってクラスターを作成するときに、特定のバージョンを指定することをお勧めします。
Apache Spark のシステム構成には 3 つの場所があります。
- Spark のプロパティは、ほとんどのアプリケーション パラメーターを制御し、
SparkConfオブジェクトまたは Java のシステム プロパティを使って設定できます。 - 環境変数は、IP アドレスなどのコンピューターごとの設定を設定するために使うことができ、各ノードで
conf/spark-env.shスクリプトを使って設定します。 - ログは、
log4j.propertiesを使って構成できます。
特定のバージョンの Spark を選ぶと、クラスターにはその既定の構成設定が含まれます。 カスタム Spark 構成ファイルを使用することで、既定の Spark 構成値を変更できます。 次に例を示します。
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
上記の例では、5 つの Spark 構成パラメーターのいくつかの既定値がオーバーライドされます。 これらの値は、Apache Hadoop MapReduce 分割の最小サイズと parquet ブロック サイズの圧縮コーデックです。 また、Spark SQL パーティションと開いているファイルのサイズの既定値です。 これらの構成の変更を選んだのは、関連するデータとジョブ (この例では、ゲノム データ) に、特定の特性があるためです。 これらの特性は、これらのカスタム構成設定を使うと向上します。
クラスターの構成設定を表示する
クラスターでパフォーマンスの最適化を実行する前に、現在の HDInsight クラスターの構成設定を確認します。 Azure Portal で Spark クラスター ウィンドウの [ダッシュボード] リンクをクリックして、HDInsight ダッシュボードを起動します。 クラスター管理者のユーザー名とパスワードでサインインします。
Apache Ambari Web UI に、主要なクラスター リソースの使用状況メトリックのダッシュボードが表示されます。 Ambari ダッシュボードには、Apache Spark の構成と、インストールされているその他のサービスが表示されます。 ダッシュボードには [Config History](構成履歴) タブがあり、Spark を含むインストールされているサービスの情報を見ることができます。
Apache Spark の構成値を見るには、 [Config History](構成履歴) を選び、 [Spark2] を選びます。 [Configs](構成) タブを選び、サービス一覧の Spark (または、バージョンによっては Spark2) を選びます。 クラスターの構成値の一覧が表示されます。
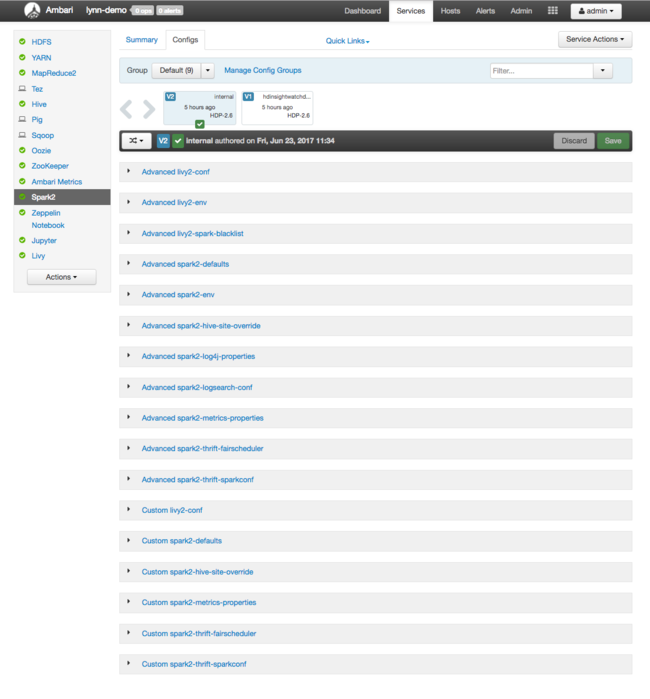
個別の Spark 構成値を表示および変更するには、タイトルに "spark" が含まれるリンクを選びます。 Spark の構成は、以下のカテゴリのカスタム構成値と詳細構成値の両方が含まれます。
- Custom Spark2-defaults (カスタム Spark2 既定値)
- Custom Spark2-metrics-properties (カスタム Spark2 メトリック プロパティ)
- Advanced Spark2-defaults (詳細 Spark2 既定値)
- Advanced Spark2-env (詳細 Spark2 環境)
- Advanced spark2-hive-site-override (詳細 Spark2 Hive サイト上書き)
既定以外の構成値のセットを作成すると、更新履歴が表示されます。 この構成履歴は、パフォーマンスが最善になる既定以外の構成を確認するのに役立ちます。
注意
共通の Spark クラスター構成設定を表示するだけで変更しない場合は、最上位の [Spark Job UI](Spark ジョブ UI) インターフェイスの [Environment](環境) タブを選びます。
Spark Executor の構成
次の図では、主要な Spark オブジェクトであるドライバー プログラムとそれに関連する Spark コンテキスト、およびクラスター マネージャーとその n 個のワーカー ノードが示されています。 各ワーカー ノードには、Executor、キャッシュ、および n 個のタスク インスタンスが含まれます。
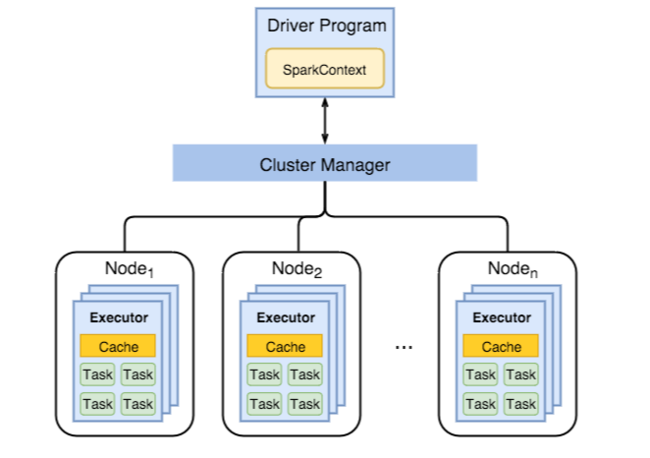
Spark ジョブはワーカーのリソース (具体的にはメモリ) を使うため、ワーカー ノードの Executor 用に Spark 構成値を調整するのが一般的です。
アプリケーションの要件が向上するよう Spark の構成をチューニングするために調整されることが多い 3 つの主要なパラメーターは、spark.executor.instances、spark.executor.cores、および spark.executor.memory です。 Executor は、Spark アプリケーション用に起動されるプロセスです。 Executor はワーカー ノードで動作し、アプリケーションのタスクを実行します。 ワーカー ノードの数とワーカー ノードのサイズによって、Executor の数と Executor のサイズが決まります。 これらの値はクラスターのヘッド ノード上の spark-defaults.conf に保存されます。 Ambari Web UI で [Custom spark-defaults](カスタム Spark 既定値) を選ぶことで、実行中のクラスターでのこれらの値を編集できます。 変更を行った後は、影響を受けるすべてのサービスの再起動を求める UI が表示されます。
注意
3 つの構成パラメーターは、クラスター レベルで (クラスター上で動作するすべてのアプリケーションに対して) 構成できるほか、個々のアプリケーションに対して指定することもできます。
Spark Executor で使われるリソースに関するもう 1 つの情報ソースは、Spark アプリケーション UI です。 UI では、[Executor] に、構成と消費されたリソースの概要ビューと詳細ビューが表示されます。 クラスター全体または特定のジョブ実行のセットのどちらの Executor 値を変更するかを決定します。
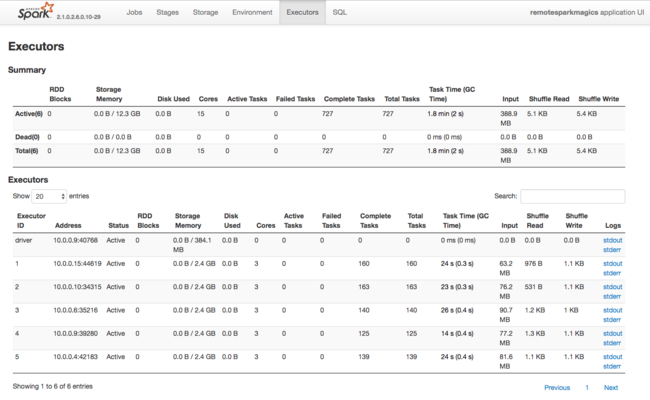
または、Ambari REST API を使って、プログラムで HDInsight と Spark クラスターの構成設定を確認することもできます。 詳細については、GitHub の Apache Ambari API リファレンスを参照してください。
Spark のワークロードによっては、既定以外の Spark 構成のほうが Spark ジョブの実行をより最適化することがわかる場合があります。 既定以外のクラスター構成を検証するには、サンプルのワークロードを使用してベンチマーク テストを実行します。 調整を検討する可能性がある一般的なパラメーターを次に示します。
| パラメーター | 説明 |
|---|---|
| --num-executors | Executor の数を設定します。 |
| --executor-cores | 各 Executor のコア数を設定します。 他のプロセスが使用可能なメモリの一部を消費するため、中規模の Executor を使うことをお勧めします。 |
| --executor-memory | Apache Hadoop YARN 上の各 Executor のメモリ サイズ (ヒープ サイズ) を制御するため、実行オーバーヘッド用にある程度のメモリを残しておく必要があります。 |
構成値が異なる 2 つのワーカー ノードの例を次に示します。

次の一覧では、Spark Executor の主要なメモリ パラメーターを示します。
| パラメーター | 説明 |
|---|---|
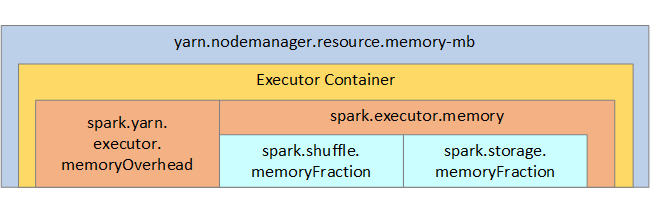
| spark.executor.memory | Executor で使用可能なメモリの総量を定義します。 |
| spark.storage.memoryFraction | (既定値は最大 60%) 永続化された RDD の格納に使用可能なメモリの量を定義します。 |
| spark.shuffle.memoryFraction | (既定値は最大 20%) シャッフル用に確保されるメモリの量を定義します。 |
| spark.storage.unrollFraction と spark.storage.safetyFraction | (合計で総メモリ量の最大 30%) Spark によって内部的に使用されるので、変更しないでください。 |
YARN は、各 Spark ノード上のコンテナーで使われる最大合計メモリを制御します。 次の図では、YARN 構成オブジェクトと Spark オブジェクトの間のノードごとの関係を示します。
Jupyter Notebook で実行されているアプリケーションのパラメーターを変更する
HDInsight の Spark クラスターには、既定で複数のコンポーネントが含まれます。 これらの各コンポーネントには、必要に応じてオーバーライドできる既定の構成値が含まれます。
| コンポーネント | 説明 |
|---|---|
| Spark Core | Spark Core、Spark SQL、Spark ストリーミング API、GraphX、Apache Spark MLlib。 |
| Anaconda | Python パッケージ マネージャー。 |
| Apache Livy | Apache Spark REST API (HDInsight Spark クラスターへのリモート ジョブの送信に使われます)。 |
| Jupyter Notebook と Apache Zeppelin Notebook | Spark クラスターを操作するためのブラウザー ベースの対話型 UI。 |
| ODBC ドライバー | HDInsight の Spark クラスターを、Microsoft Power BI や Tableau などのビジネス インテリジェンス (BI) ツールに接続します。 |
Jupyter Notebook で実行されているアプリケーションについては、%%configure コマンドを使って、Notebook 自体の内部から構成を変更できます。 これらの構成変更は、お使いの Notebook インスタンスから実行された Spark ジョブに適用されます。 そのような変更は、最初のコード セルを実行する前、アプリケーションの冒頭で行います。 変更された構成は、Livy セッションの作成時に適用されます。
注意
アプリケーションの後のステージで構成を変更するには、-f (force) パラメーターを使う必要があります。 ただし、アプリケーションのすべての進捗が失われます。
以下のコードでは、Jupyter Notebook で実行されているアプリケーションの構成を変更する方法を示します。
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
まとめ
Spark ジョブの実行が予測可能で高いパフォーマンスを発揮するように、コア構成設定を監視します。 これらの設定は、特定のワークロードに対する Spark クラスターの最善の構成を決定するのに役立ちます。 また、実行時間の長い、またはリソース消費の多い Spark ジョブの実行を監視する必要があります。 最も一般的な課題は、不適切な構成 (Executor の不適切なサイズ変更など) によるメモリ不足が中心になります。 実行時間の長い操作や、デカルト演算につながるタスクもあります。