Azure HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
HDInsight Spark クラスターには、Apache Zeppelin Notebook が含まれています。 Notebook を使用して、Apache Spark ジョブを実行します。 この記事では、HDInsight クラスターで Zeppelin Notebook を使用する方法について説明します。
前提条件
- HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
- クラスターのプライマリ ストレージの URI スキーム。 スキームは、Azure Blob Storage の場合は
wasb://、Azure Data Lake Storage Gen2 の場合はabfs://、Azure Data Lake Storage Gen1 の場合はadl://です。 Blob Storage で安全な転送が有効になっている場合、URI はwasbs://になります。 詳細については、「Azure Storage で安全な転送が必要」を参照してください。
Apache Zeppelin Notebook を起動する
Spark クラスターの [概要] で、 [クラスター ダッシュボード] から [Zeppelin Notebook] を選択します。 クラスターの管理者資格情報を入力します。
注意
ブラウザーで次の URL を開き、クラスターの Zeppelin Notebook にアクセスすることもできます。 CLUSTERNAME をクラスターの名前に置き換えます。
https://CLUSTERNAME.azurehdinsight.net/zeppelin新しい Notebook を作成します。 ヘッダー ウィンドウから、 [Notebook]>[新しいメモを作成します] の順に移動します。
Notebook の名前を入力し、 [Note の作成] を選択します。
Notebook のヘッダーに [接続] というステータスが表示されることを確認します。 これは、右上隅の緑色の点で示されます。
サンプル データを一時テーブルに読み込みます。 HDInsight の Spark クラスターを作成すると、サンプル データ ファイル
hvac.csvが、関連するストレージ アカウントの\HdiSamples\SensorSampleData\hvacにコピーされます。新しい Notebook に既定で作成される空の段落に、次のスニペットを貼り付けます。
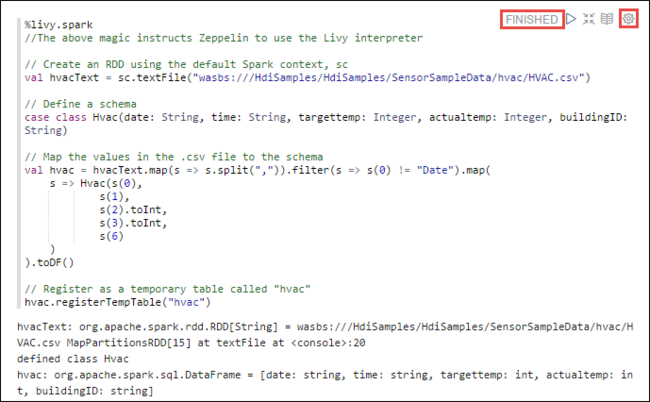
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Shift + Enter キーを押すか、段落の [プレイ] ボタンを選択して、スニペットを実行します。 段落の右上隅にあるステータスが、[準備完了]、[保留中]、[実行中]、[完了] の順に進行します。 出力が同じ段落の下に表示されます。 スクリーンショットは次の図のようになります。
各段落にタイトルを指定することもできます。 段落の右上隅から [設定] アイコン (鎖歯車) を選択し、 [タイトルの表示] を選択します。
注意
%spark2 インタープリターは、いずれの HDInsight バージョンの Zeppelin Notebook でもサポートされていません。また、%sh インタープリターは HDInsight 4.0 以降ではサポートされなくなります。
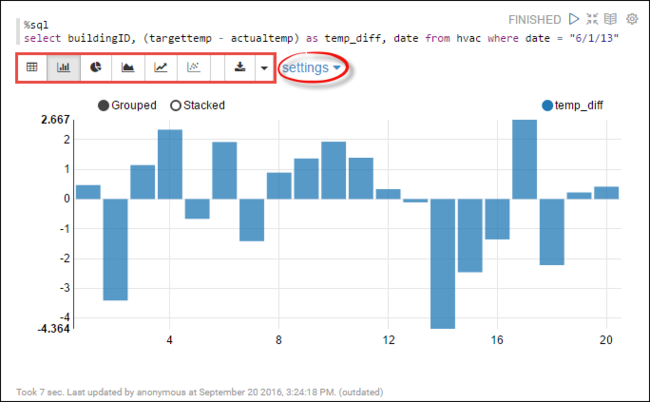
hvacテーブルに対して Spark SQL ステートメントを実行できます。 次のクエリを新しい段落に貼り付けます。 このクエリでは、建物の ID が取得されます。 また、特定の日の各建物の目標温度と実温度の差も取得されます。 Shift + Enterキーを押します。%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"先頭にある %sql ステートメントは、Livy Scala インタープリターを使用するように Notebook に指示します。
棒グラフ アイコンを選択し、表示を変更します。 棒グラフを選択した後に表示される [設定] で、[キー] と [値] を選択できます。 次のスクリーンショットでは出力を示します。
クエリの変数を使用して Spark SQL ステートメントを実行することもできます。 次のスニペットでは、クエリで変数
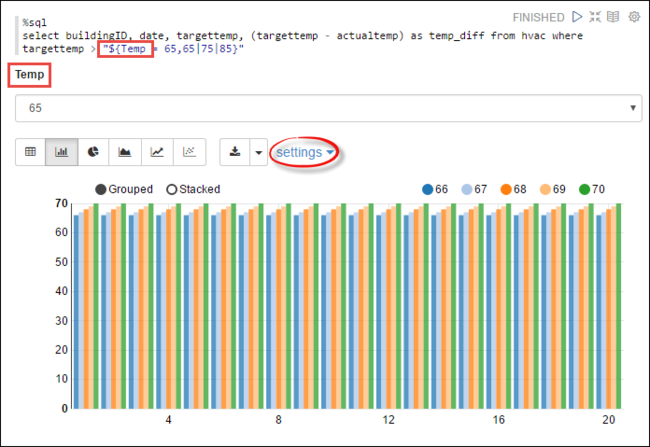
Tempと照会できる値を定義する方法を示します。 初めてクエリを実行すると、変数に指定した値がドロップダウンに自動的に設定されます。%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"このスニペットを新しい段落に貼り付けて、 Shift + Enterキーを押します。 [Temp] ドロップダウン リストから [65] を選択します。
棒グラフ アイコンを選択し、表示を変更します。 次に、 [設定] を選択し、次の変更を行います。
Groups:targettemp を追加します。
[値]: 1. date を削除します。 2. temp_diff を追加します。 3. アグリゲーターを SUM から AVG に変更します。
次のスクリーンショットでは出力を示します。
Notebook で外部のパッケージを使用する方法
HDInsight 上の Apache Spark クラスター内の Zeppelin Notebook では、クラスターに含まれない、外部のコミュニティから提供されているパッケージを使用できます。 利用できるすべてのパッケージについては、Maven リポジトリを検索してください。 公開されているパッケージの一覧を他のソースから入手してもかまいません。 たとえば、コミュニティから提供されている全パッケージの一覧を Spark Packagesで入手できます。
この記事では、Jupyter Notebook で spark-csv パッケージを使用する方法について説明します。
インタープリターの [設定] を開きます。 右上隅のログインしている [ユーザー名] を選択し、 [インタープリター] を選択します。
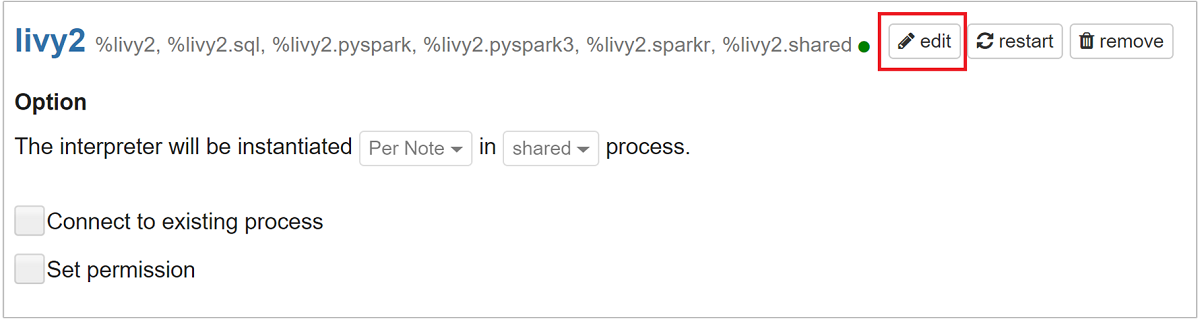
livy2 までスクロールし、 [編集] を選択します。
キー
livy.spark.jars.packagesに移動し、group:id:versionの形式で値を設定します。 したがって、spark-csv パッケージを使用する場合は、キーの値をcom.databricks:spark-csv_2.10:1.4.0に設定する必要があります。
[保存] 、 [OK] の順に選択し、Livy インタープリターを再起動します。
上記で入力したキーの値に到達する方法を理解するには、次のようにします。
a. Maven リポジトリから目的のパッケージを探します。 この記事では spark-csv を使用しました。
b. リポジトリで GroupId、ArtifactId、Version の値を確認します。
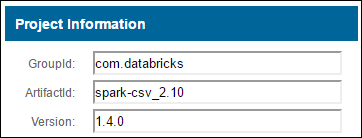
c. 3 つの値をコロン ( : ) で区切って連結します。
com.databricks:spark-csv_2.10:1.4.0
Zeppelin Notebook の保存場所
Zeppelin Notebook は、クラスターのヘッドノードに保存されます。 そのため、クラスターを削除すると、Notebook も同様に削除されます。 後で別のクラスターで使用するように Notebook を保存する場合は、ジョブの実行を完了した後に Notebook をエクスポートする必要があります。 Notebook をエクスポートするには、下の図に示すように [エクスポート] アイコンを選択します。
この操作により、Notebook は JSON ファイルとしてダウンロード先に保存されます。
Note
HDI 4.0 では、zeppelin ノートブックのディレクトリ パスは次のとおりです
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/例: /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
HDI 5.0 以降では、このパスが異なり、次のようになります
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/例: /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
HDI 5.0 では、格納されるファイル名が異なります。 これは、次の名前で格納されます
<notebook_name>_<sessionid>.zpln例: testzeppelin_2JJK53XQA.zpln
HDI 4.0 では、ファイル名は note.json だけで、session_id ディレクトリの下に格納されます。
例: /2JMC9BZ8X/note.json
HDI Zeppelin では、ノートブックは常に、hn0 ローカル ディスク内のパス
/usr/hdp/<version>/zeppelin/notebook/に保存されます。クラスターを削除した後もノートブックを使用できるようにするには、Azure ファイル ストレージを使用し (SMB プロトコルを使用)、それをローカル パスにリンクしてみてください。 詳細については、「SMB Azure ファイル共有を Linux でマウントする」を参照してください
マウント後、ambari UI で zeppelin 構成 zeppelin.notebook.dir をマウント パスに変更できます。
- zeppelin バージョン 0.10.1 の場合、GitNotebookRepo ストレージとしての SMB ファイル共有は推奨されません
Shiro を使用して Enterprise セキュリティ パッケージ (ESP) クラスターで Zeppelin インタープリターへのアクセスを構成する
前述のように、%sh インタープリターは HDInsight 4.0 以降ではサポートされていません。 さらに、%sh インタープリターは、シェル コマンドを使用した keytab へのアクセスなど、潜在的なセキュリティの問題が発生するため、HDInsight 3.6 の ESP クラスターからも削除されています。 つまり、既定では、 [Create new note](新しいメモの作成) をクリックしても、インタープリターの UI でも、%sh インタープリターは使用できません。
特権ドメイン ユーザーは、Shiro.ini ファイルを使用してインタープリターの UI へのアクセスを制御できます。 これらのユーザーだけが、新しい %sh インタープリターを作成し、それぞれの新しい %sh インタープリターにアクセス許可を設定できます。 shiro.ini ファイルを使用してアクセスを制御するには、次の手順に従います。
既存のドメイン グループ名を使用して、新しいロールを定義します。 次の例で、
adminGroupNameは AAD の特権ユーザーのグループです。 グループ名には特殊文字や空白を使用しないでください。=の後の文字によって、このロールのアクセス許可が付与されます。*は、グループに完全なアクセス許可があることを意味します。[roles] adminGroupName = *Zeppelin インタープリターにアクセスするための新しいロールを追加します。 次の例では、
adminGroupName内のすべてのユーザーに Zeppelin インタープリターへのアクセス権が付与され、新しいインタープリターを作成できます。roles[]内の角かっこの間には、複数の役割をコンマで区切って指定できます。 その後、必要なアクセス許可を持つユーザーは、Zeppelin インタープリターにアクセスできます。[urls] /api/interpreter/** = authc, roles[adminGroupName]
複数のドメイン グループの例 shiro.ini:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy セッションを管理する
Zeppelin Notebook のコードの最初の段落では、クラスターに新しい Livy セッションが作成されます。 このセッションは、後で作成するすべての Zeppelin Notebook 間で共有されます。 何らかの理由で Livy セッションが強制終了された場合、ジョブは Zeppelin Notebook から実行されません。
このような場合は、Zeppelin Notebook からジョブの実行を開始する前に、次の手順を実行する必要があります。
Zeppelin Notebook から Livy インタープリターを再起動します。 再起動するには、右上隅のログインしている [ユーザー名] を選択してインタープリターの [設定] を開き、 [インタープリター] を選択します。
livy2 までスクロールし、 [再起動] を選択します。
既存の Zeppelin Notebook からコードのセルを実行します。 このコードでは、HDInsight クラスター内に新しい Livy セッションが作成されます。
一般情報
サービスの検証
Ambari からサービスを検証するには、https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary に移動します。ここで、CLUSTERNAME はクラスターの名前です。
コマンド ラインからサービスを検証するには、ヘッド ノードに SSH 接続します。 コマンド sudo su zeppelin を使用して、ユーザーを zeppelin に切り替えます。 状態コマンド:
| command | 説明 |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
サービスの状態。 |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
サービスのバージョン。 |
ps -aux | grep zeppelin |
PID を識別します。 |
ログの場所
| サービス | Path |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| サーバー ログ | /var/log/zeppelin |
構成インタープリター、Shiro、site.xml、log4j |
/usr/hdp/current/zeppelin-server/conf または /etc/zeppelin/conf |
| PID ディレクトリ | /var/run/zeppelin |
デバッグ ログの有効化
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summaryに移動します。ここで、CLUSTERNAME はクラスターの名前です。[CONFIGS](構成)>[Advanced zeppelin-log4j-properties](詳細 zeppelin-log4j-properties)>[log4j_properties_content] に移動します。
log4j.appender.dailyfile.Threshold = INFOをlog4j.appender.dailyfile.Threshold = DEBUGに変更します。log4j.logger.org.apache.zeppelin.realm=DEBUGを追加します。変更を保存し、サービスを再起動します。