AutoML 予測を使用したディープ ラーニング
この記事では、AutoML での時系列予測のディープ ラーニング方法に焦点を当てています。 AutoML で予測モデルをトレーニングする手順と例については、時系列予測用に AutoML を設定するの記事を参照してください。
ディープ ラーニングには、言語モデリングからタンパク質フォールディングに至るまで、数多くのユース ケースがあります。 時系列予測も、ディープ ラーニング テクノロジの最近の進歩の恩恵を受けています。 たとえば、ディープ ニューラル ネットワーク (DNN) モデルは、著名な Makridakis 予測コンペティションの第 4 回と第 5 回において、最も優れたモデルの中で大きな実績を表しました。
この記事では、モデルをご自身のシナリオに最適な形で適用できるように、AutoML の TCNForecaster モデルの構造と運用について説明します。
TCNForecaster の概要
TCNForecaster は、時系列データ用に設計された DNN アーキテクチャを備えたテンポラル畳み込みネットワーク (TCN) です。 このモデルでは、ターゲット数量の履歴データと関連する特徴量を使用して、指定された予測期間までのターゲットの確率予測を行います。 次の図に、TCNForecaster アーキテクチャの主要なコンポーネントを示します。
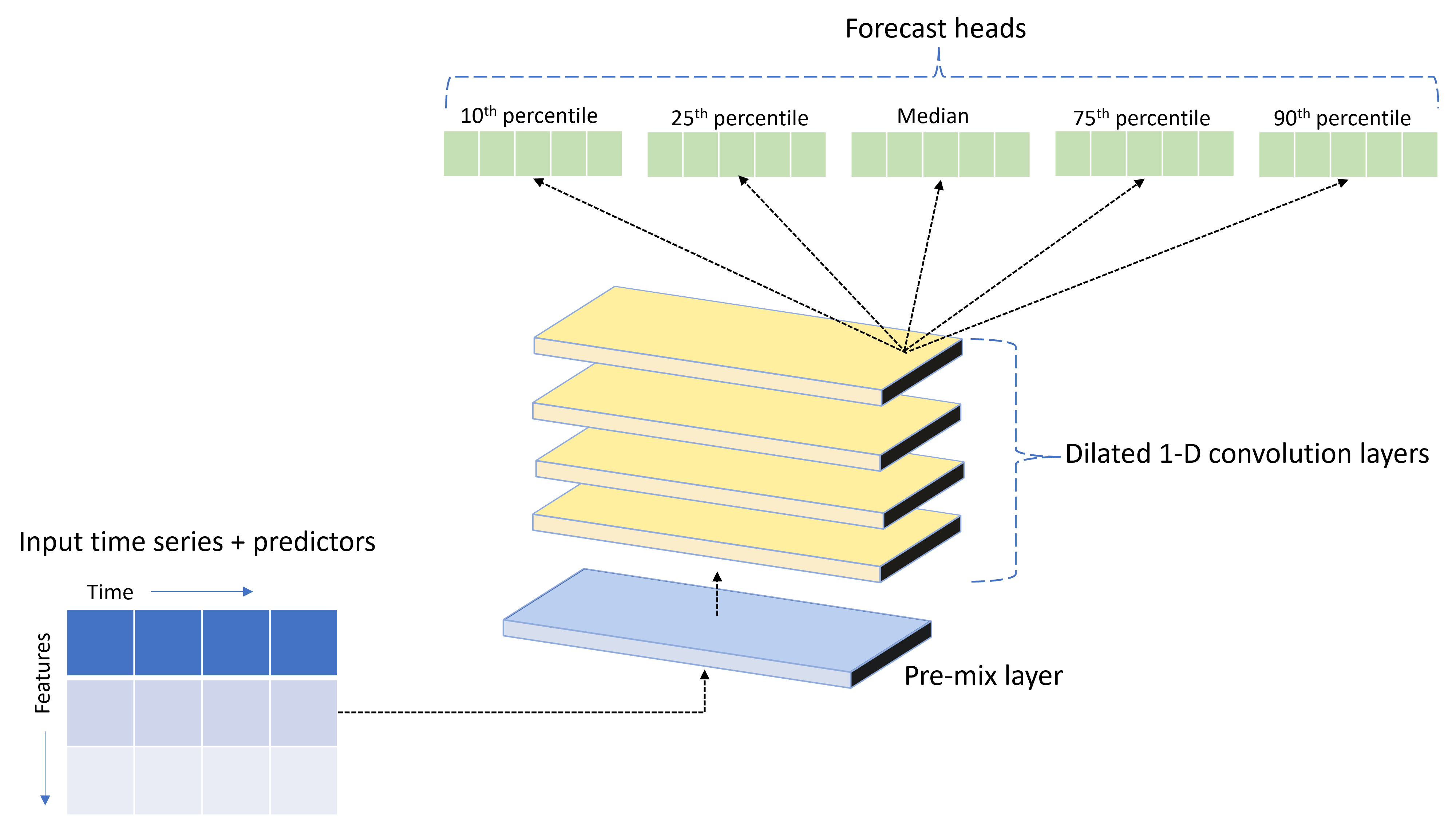
TCNForecaster には、次の主要なコンポーネントがあります。
- 事前混合レイヤー。入力時系列と特徴のデータを、畳み込みスタックで処理されるシグナル チャネルの配列に混合します。
- 膨張畳み込みレイヤーのスタック。チャネル配列を順次に処理します。スタック内の各レイヤーでは、前のレイヤーの出力を処理して新しいチャネル配列を生成します。 この出力の各チャネルには、入力チャネルからの畳み込みフィルター処理されたシグナルが混合して含まれています。
- 予測ヘッド ユニットのコレクション。畳み込みレイヤーからの出力シグナルを結合し、この潜在表現からターゲット数量の予測を生成します。 各ヘッド ユニットでは、予測分布の分位点の範囲までの予測を生成します。
膨張コーザル畳み込み
TCN の中心的な動作は、入力シグナルの時間ディメンションに沿って膨張されたコーザル畳み込みです。 直感的には、畳み込みによって、入力内で近くにある時間ポイントの値が混合されます。 この混合内の部分が畳み込みのカーネル (重み) であるのに対し、この混合内のポイント間の分離が膨張です。 入力に沿ってカーネルを時間でスライドさせ、各位置で混合を蓄積することで、入力から出力シグナルが生成されます。 コーザル畳み込みでは、カーネルが各出力ポイントに相対する過去の入力値のみを混合し、出力が将来を "見る" のを防ぎます。
膨張畳み込みをスタックすると、TCN が、長期間にわたり、カーネルの重みが比較的少ない入力信号内の相関関係をモデル化できます。 たとえば、次の図は、各レイヤーに 2 つの重みのカーネルがあり、膨張係数が指数関数的に増加する 3 つのスタックされたレイヤーを示しています。
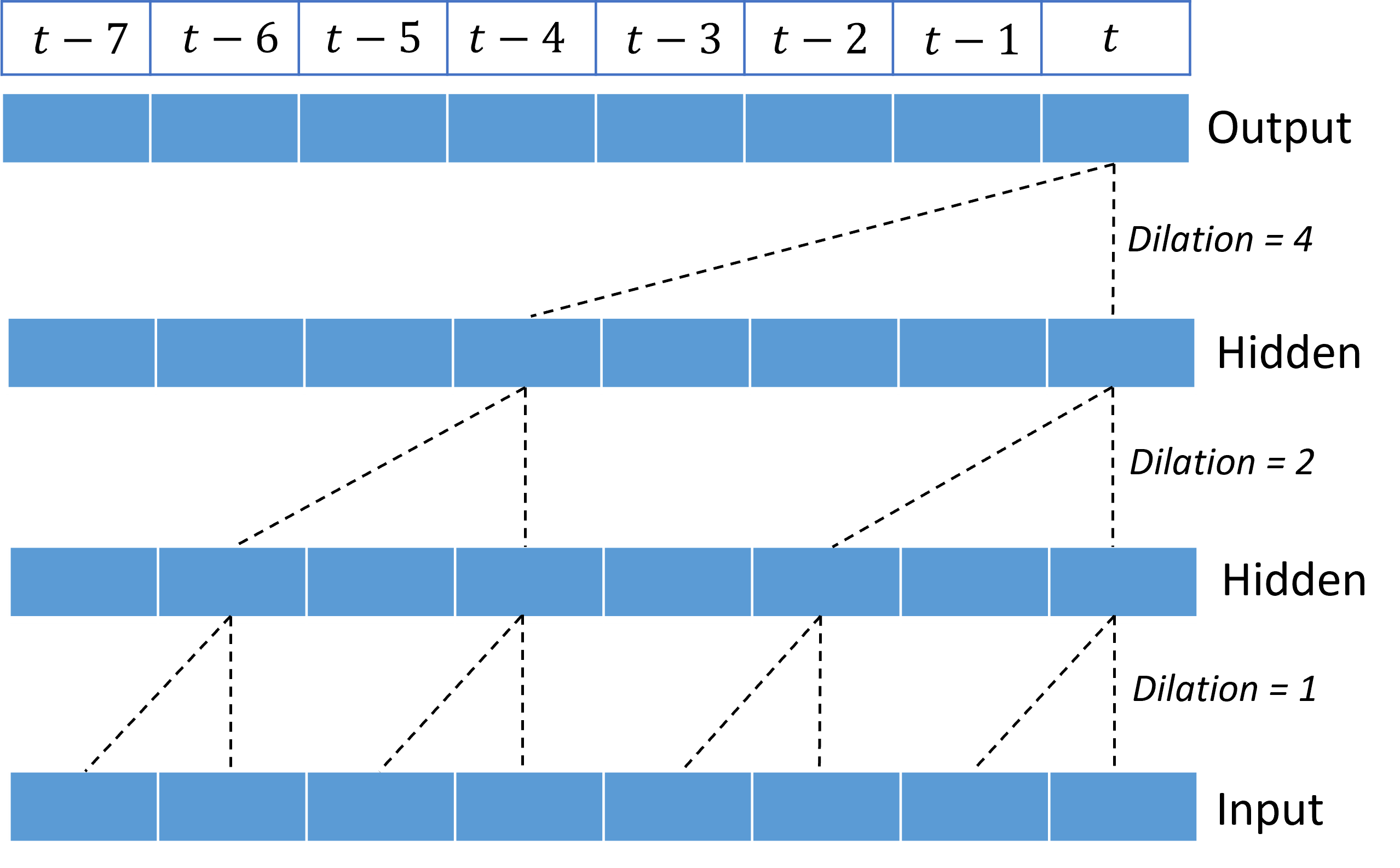
破線は、時間 $t$ の出力で終了する、ネットワーク全体のパスを示しています。 これらのパスは入力の最後の 8 ポイントをカバーし、各出力ポイントが入力内の 8 つの比較的最近のポイントの関数であることを示しています。 予測を行うために畳み込みネットワークで使用される履歴 ("ルック バック") の長さは受容野と呼ばれ、全面的に TCN アーキテクチャによって決定されます。
TCNForecaster アーキテクチャ
TCNForecaster アーキテクチャの中核となるのは、プレミックスと予測ヘッドの間の畳み込みレイヤーのスタックです。 このスタックは、ブロックと呼ばれる繰り返し単位に論理的に分割されますが、これは残差セルで構成されています。 残差セルでは、正規化と非線形活性化と共に、設定された膨張でコーザル畳み込みを適用します。 重要なのは、各残差セルで、いわゆる残差接続を使用してその出力がその入力に追加されることです。 これらの接続は、DNN トレーニングに役立つと思われています。理由として考えられるのは、これらによって、ネットワークを介したより効率的な情報フローが可能になることです。 次の図は、あるサンプル ネットワークの畳み込みレイヤーのアーキテクチャを示しています。ここでは、各ブロックに 2 つのブロックと 3 つの残差セルがあります。
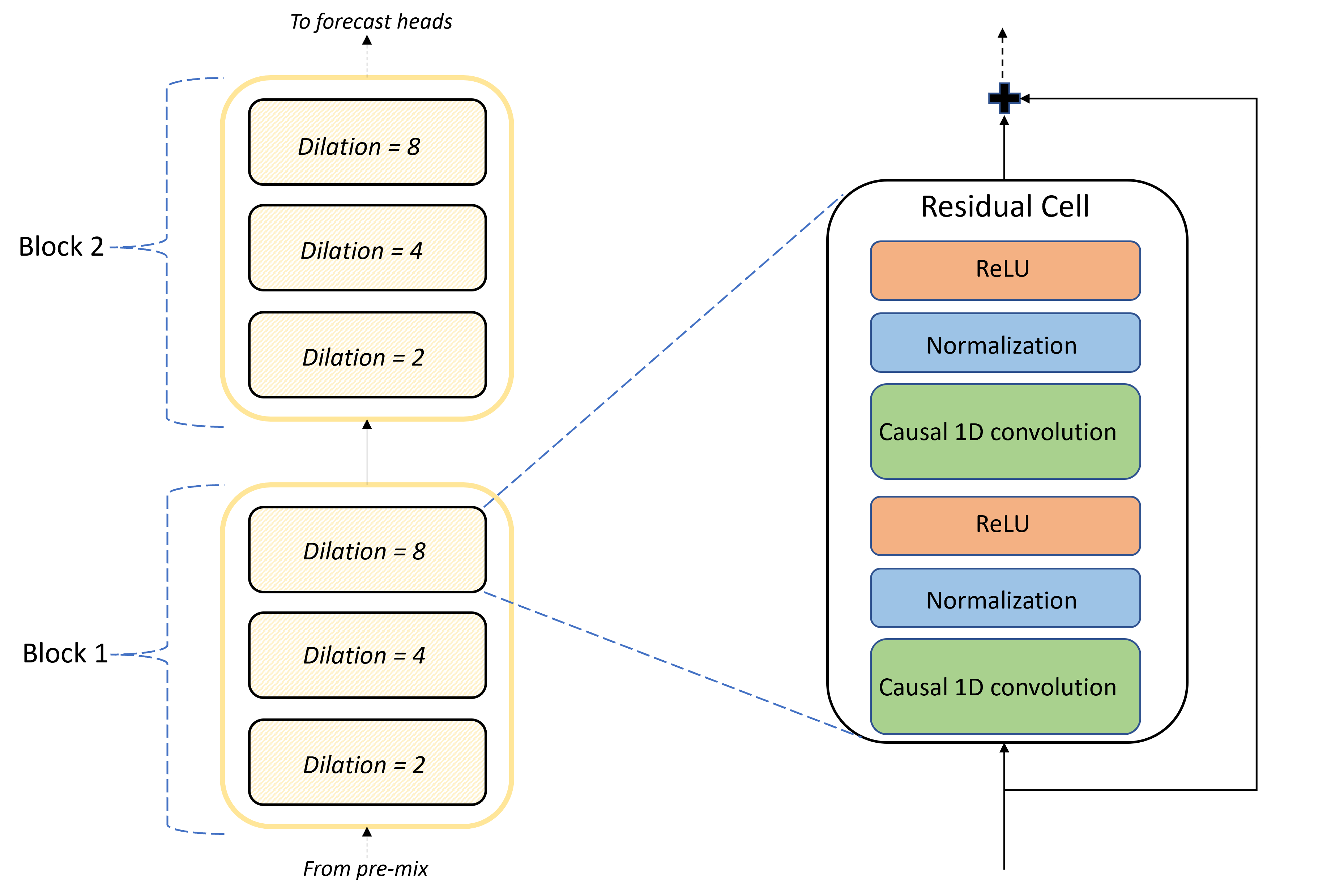
ブロックとセルの数と、各レイヤー内のシグナル チャネルの数によって、ネットワークのサイズが制御されます。 TCNForecaster のアーキテクチャ パラメーターを次の表にまとめています。
| パラメーター | 説明 |
|---|---|
| $n_{b}$ | ネットワーク内のブロックの数。"深度" とも呼ばれます。 |
| $n_{c}$ | 各ブロック内のセルの数 |
| $n_{\text{ch}}$ | 非表示レイヤー内のチャネルの数 |
受容野は深度パラメーターによって決まり、数式によって求めます。
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
数式を使うと、TCNForecaster アーキテクチャのより正確な定義が得られます。 $X$ を、各行に入力データからの特徴値が含まれる入力配列であるとします。 $X$ は、数値とカテゴリの特徴配列 $X_{\text{num}}$ と $X_{\text{cat}}$ に分割できます。 これにより、TCNForecaster が数式によって示されます。
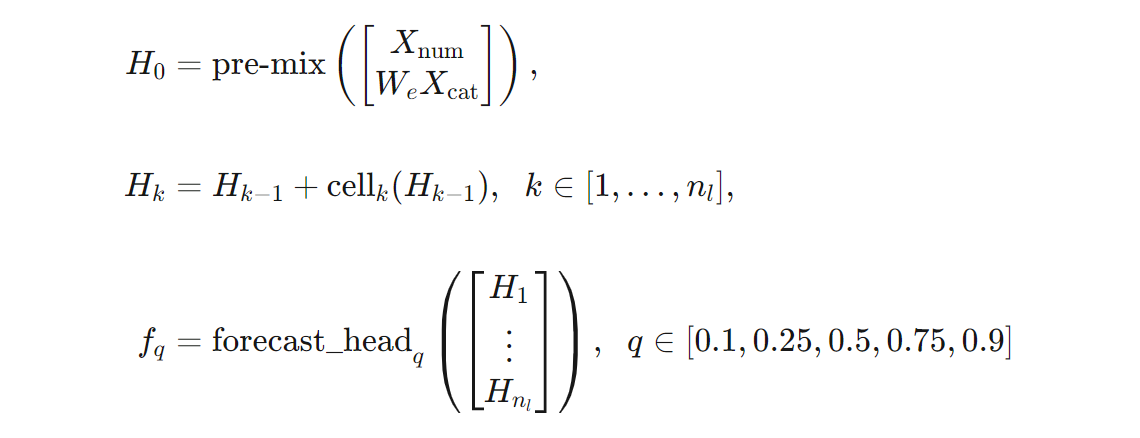
ここで、$W_{e}$ はカテゴリ特徴の埋め込み行列であり、$n_{l} = n_{b}n_{c}$ は残差セルの合計数、$H_{k}$ は非表示レイヤーの出力を表し、$f_{q}$ は予測分布の特定の分位点の予測出力です。 理解を深めるために、これらの変数のディメンションを次の表に示します。
| 変数 | 説明 | Dimensions |
|---|---|---|
| $X$ | 入力配列 | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | $i=0,1,\ldots,n_{l}$ の非表示レイヤーの出力 | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | 分位点 $q$ の予測出力 | $h$ |
この表で、$n_{\text{input}} = n_{\text{features}} + 1$ であり、これは予測器/特徴変数の数にターゲット数量を加算したものです。 予測ヘッドでは、1 回のパスで最大ホライズン ($h$) までのすべての予測を生成します。そのため、TCNForecaster は直接予測器です。
AutoML の TCNForecaster
TCNForecaster は AutoML のオプションのモデルです。 その使用方法については、「ディープ ラーニングを有効にする」を参照してください。
このセクションでは、データの前処理、トレーニング、モデル検索の説明など、AutoML でデータを使用して TCNForecaster モデルを構築する方法について説明します。
データの前処理の手順
AutoML では、データに対していくつかの前処理手順を実行して、モデルのトレーニングを準備します。 次の表では、これらの手順を実行順に示します。
| 手順 | 説明 |
|---|---|
| 不足データを充てんする | 欠損値と観測ギャップを補完し、必要に応じて短い時系列を埋め込むかドロップします |
| カレンダー特徴を作成する | 曜日や、必要に応じて特定の国や地域の休日など、カレンダーから派生した特徴を使用して入力データを拡張します。 |
| カテゴリ データをエンコードする | ラベル エンコード文字列とその他のカテゴリ型。これには、すべての時系列 ID 列が含まれます。 |
| ターゲットの変換 | オプションで、特定の統計テストの結果に応じて自然対数関数をターゲットに適用します。 |
| 正規化 | Z スコアによってすべての数値データを正規化します。正規化は、時系列 ID 列の定義に従って、特徴と時系列グループごとに実行されます。 |
これらの手順は AutoML の変換パイプラインに含まれているため、推論時に必要が生じると自動的に適用されます。 手順への逆演算が推論パイプラインに含まれている場合があります。 たとえば、AutoML がトレーニング中にターゲットに $\log$ 変換を適用した場合、未加工の予測が推論パイプラインで累乗されます。
トレーニング
TCNForecaster は、画像と言語の他のアプリケーションに共通する、DNN トレーニングのベスト プラクティスに従います。 AutoML では、前処理されたトレーニング データは、シャッフルされてバッチに結合される、例に分割されます。 ネットワークでは、誤差逆伝播法と確率的勾配降下法を使用してバッチを順番に処理し、損失関数に関してネットワークの重みを最適化します。 トレーニングでは、トレーニング データ全体で多くのパスを必要とする場合があり、各パスはエポックと呼ばれます。
次の表に、TCNForecaster のトレーニングの入力設定とパラメーターの一覧と説明を示します。
| トレーニングの入力 | 説明 | 値 |
|---|---|---|
| 検証データ | ネットワークの最適化をガイドし、オーバーフィットを軽減するためにトレーニングから提供されるデータの一部。 | ユーザーによって提供されるか、提供されない場合はトレーニング データから自動的に作成されます。 |
| 主要メトリック | 各トレーニング エポックの最後にある検証データの中央値予測から計算されるメトリック。早期停止とモデルの選択に使用されます。 | ユーザーによって選択されます。正規化された二乗平均平方根誤差または正規化された平均絶対誤差。 |
| トレーニング エポック | ネットワークの重みを最適化するために実行するエポックの最大数。 | 100。自動早期停止ロジックを使用すると、より少数のエポックでトレーニングを終了できます。 |
| 早期停止のペイシェンス | トレーニングが停止されるまでの、主要メトリックの改善を待機するエポックの数。 | 20 |
| 損失関数 | ネットワークの重みの最適化のための目的関数。 | 10、25、50、75、90 パーセンタイル予測で平均した分位点損失。 |
| バッチ サイズ | バッチ内の例の数。 各例には、ディメンションとして、入力には $n_{\text{input}} \times t_{\text{rf}}$、出力には $h$ があります。 | トレーニング データ内の例の合計数から自動的に決定されます。最大値は 1024 です。 |
| 埋め込みディメンション | カテゴリ特徴の埋め込み空間のディメンション。 | 各特徴内の個別の値の数の 4 番目のルートに自動的に設定され、最も近い整数に切り上げられます。 しきい値は、最小値 3、最大値 100 で適用されます。 |
| ネットワーク アーキテクチャ* | ネットワークのサイズと形状を制御するパラメーター (深度、セル数、チャネル数)。 | モデル検索によって決定されます。 |
| ネットワークの重み | シグナルの混合、カテゴリ埋め込み、畳み込みカーネルの重み、予測値へのマッピングを制御するパラメーター。 | ランダムに初期化された後、損失関数に関して最適化されます。 |
| 学習率* | 勾配降下のそれぞれの繰り返しでネットワークの重みをどれだけ調整できるかを制御します。収束が近くなると動的に減らされます。 | モデル検索によって決定されます。 |
| ドロップアウト率* | ネットワークの重み付けに適用されるドロップアウトの正則化の度合いを制御します。 | モデル検索によって決定されます。 |
アスタリスク (*) が付いた入力は、次のセクションで説明するハイパーパラメーター検索によって決定されます。
モデル検索
AutoML では、モデル検索手法を使用して、次のハイパーパラメーターの値を見つけます。
- ネットワークの深度、または畳み込みブロックの数。
- ブロックあたりのセルの数
- 各非表示レイヤー内のチャネルの数
- ネットワーク正則化のドロップアウト率
- 学習率。
これらのパラメーターの最適な値は、問題のシナリオとトレーニング データによって大きく異なる可能性があるため、AutoML ではハイパーパラメーター値の空間内でいくつかの異なるモデルをトレーニングし、検証データの主要メトリックのスコアに従って最適なものを選択します。
モデル検索には、次の 2 つのフェーズがあります。
- AutoML で、12 の "ランドマーク" モデルに対して検索を実行します。 ランドマーク モデルは静的であり、ハイパーパラメーター空間に無理なくまたがるように選択されます。
- AutoML では、ランダム検索を使用してハイパーパラメーター空間を検索し続けます。
停止条件が満たされると、検索は終了します。 停止条件は予測トレーニング ジョブの構成によって異なりますが、一部の例には、時間制限、実行する検索試行の回数制限、検証メトリックが改善されない場合の早期停止ロジックが含まれます。
次のステップ
- 時系列予測モデルをトレーニングするために AutoML を設定する方法を確認します。
- AutoML の予測手法について確認します。
- AutoML での予測に関するよくある質問を参照します。