AutoML での予測のためのモデル スイープと選択
この記事では、Azure Machine Learning で自動機械学習 (AutoML) が予測モデルを検索して選択する方法について説明します。 AutoML での予測方法についてさらに詳しく知りたい場合は、「AutoML の予測方法の概要」をご覧ください。 AutoML での予測モデルのトレーニング例を調べるには、「SDK と CLI で時系列予測モデルをトレーニングするために、AutoML を設定す」をご覧ください。
AutoML でのモデルのスイープ
AutoML の主なタスクは、いくつかのモデルをトレーニングして評価し、指定された主要メトリックに関して最適なものを選ぶことです。 ここでの "モデル" という単語は、ARIMA や Random Forest などのモデル クラスと、クラス内のモデルを区別する特定のハイパーパラメーター設定の両方を指します。 たとえば、ARIMA は、数学的テンプレートと一連の統計的仮定を共有するモデルのクラスを指します。 ARIMA モデルをトレーニングする (適合させる) には、モデルの正確な数学的形式を指定する正の整数のリストが必要です。 これらの値がハイパー パラメーターです。 ARIMA(1, 0, 1) と ARIMA(2, 1, 2) のモデルのクラスは同じですが、ハイパーパラメーターは異なります。 これらの定義は、トレーニング データに個別に適合させ、相互に評価することができます。 AutoML は、さまざまなモデル クラスおよびクラス内で、さまざまなハイパーパラメーターを使用して検索 (スイープ) します。
ハイパーパラメーターのスイープ方法
次の表には、AutoML でさまざまなモデル クラスに使用されるさまざまなハイパーパラメーター スイープ メソッドが示されています。
| モデル クラス グループ | モデルの種類 | ハイパーパラメーター スイープ方法 |
|---|---|---|
| Naive、Seasonal Naive、Average、Seasonal Average | タイム シリーズ | モデルがシンプルであるため、クラス内でのスイープなし |
| 指数平滑法、ARIMA(X) | タイム シリーズ | クラス内スイープのグリッド検索 |
| Prophet | 回帰 | クラス内でのスイープなし |
| Linear SGD、LARS LASSO、Elastic Net、K Nearest Neighbors、Decision Tree、Random Forest、Extremely Randomized Trees、Gradient Boosted Trees、LightGBM、XGBoost | 回帰 | AutoML のモデル レコメンデーション サービスでは、ハイパーパラメーター空間が動的に探索されます |
| ForecastTCN | 回帰 | モデルの静的リストの後に、ネットワーク サイズ、ドロップアウト率、学習率に対するランダム検索が続きます |
さまざまなモデルの種類の説明については、予測方法の概要に関する記事の「AutoML での予測モデル」セクションを参照してください。
AutoML によるスイープの量は、予測ジョブの構成によって異なります。 停止条件を時間制限または試行回数の制限として指定するか、モデルの同等数を指定することができます。 主要メトリックが改善されない場合は、どちらの場合も早期終了ロジックを使用してスイープを停止できます。
AutoML でのモデルの選択
AutoML は、次の 3 段階のプロセスに従って、予測モデルを検索し、選択します。
フェーズ 1: 最尤推定方法を使用して、時系列モデルをスイープし、各クラスから最適なモデルを選択します。
フェーズ 2: 回帰モデルをスイープし、検証セットの主要メトリック値に従って、フェーズ 1 の最適な時系列モデルと共にランク付けします。
フェーズ 3: 上位ランクのモデルからアンサンブル モデルを構築し、その検証メトリックを計算して、他のモデルと共にランク付けします。
フェーズ 3 の終了時に上位ランクのメトリック値を持つモデルが、最適なモデルとして指定されます。
重要
フェーズ 3 では、AutoML は常に、モデルの適合には使用されない、サンプル外のデータに対してメトリックを計算します。 このアプローチは、過剰適合から保護するのに役立ちます。
検証の構成
AutoML には、クロス検証と明示的な検証データという 2 つの検証構成があります。
クロス検証の場合、AutoML では入力構成を使用して、トレーニングおよび検証フォールドに分割されたデータを作成します。 これらの分割では時間順を保持する必要があります。 AutoML では、いわゆるローリング オリジン クロス検証が使用されます。その場合、起点の時点を使用して、系列がトレーニングと検証データに分割されます。 時間内の原点をスライドすると、クロス検証のフォールドが生成されます。 各検証フォールドには、指定されたフォールドの起点の位置の直後にある観測値の次の水平線が含まれます。 この戦略により、時系列データの整合性が維持され、情報漏えいのリスクが軽減されます。
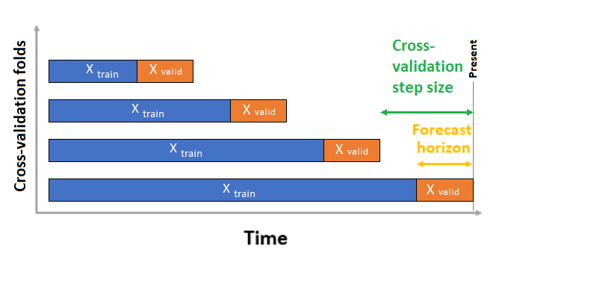
AutoML では通常のクロス検証手順に従い、フォールドごとに個別のモデルをトレーニングし、すべてのフォールドの検証メトリックを平均化します。
予測ジョブのクロス検証は、クロス検証フォールドの数と、必要に応じて、2 つの連続するクロス検証フォールド間の期間数を設定することによって構成されます。 予測のためのクロス検証の構成の詳細と例については、「カスタムのクロス検証設定」を参照してください。
独自の検証データを持ち込むこともできます。 詳細については、「AutoML (SDK v1) でのトレーニング、検証、クロス検証、テストのデータを構成する」を参照してください。