Azure Data Science Virtual Machine 上のサンプル
Azure Data Science Virtual Machine (DSVM) には、サンプル コードの包括的なセットが含まれています。 これらのサンプルには、Python や R などの言語による Jupyter ノートブックおよびスクリプトが含まれています。
Note
データ サイエンス仮想マシン上で Jupyter ノートブックを実行する方法の詳細については、「Jupyter にアクセスする」のセクションを参照してください。
前提条件
これらのサンプルを実行するには、Ubuntu Data Science Virtual Machine をプロビジョニングしておく必要があります。
使用可能なサンプル
| サンプル カテゴリ | 説明 | 場所 |
|---|---|---|
| Python 言語 | サンプルでは、Azure ベースのクラウド データ ストアに接続する方法や、Azure Machine Learning を操作する方法などのシナリオについて説明します。 Python 言語 |
~notebooks |
| Julia 言語 | Julia でのプロットとディープ ラーニングの詳細な説明を提供します。 また、Julia から C および Python を呼び出す方法についても説明します。 Julia 言語 |
Windows: ~notebooks/Julia_notebooksLinux: ~notebooks/julia |
| Azure Machine Learning | Machine Learning で機械学習およびディープ ラーニング モデルを構築する方法を説明します。 モデルを任意の場所にデプロイします。 自動化された機械学習およびインテリジェント ハイパーパラメーター チューニングを使用します。 モデル管理および分散トレーニングも使用します。 Machine Learning |
~notebooks/AzureML |
| PyTorch ノートブック | PyTorch ベースのニューラル ネットワークを使用するディープ ラーニング サンプル。 ノートブックには初心者から高度なシナリオまでの幅があります。 PyTorch ノートブック |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | TensorFlow フレームワークを使用して実装された、さまざまなニューラル ネットワーク サンプルおよび技法。 TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | 実世界の問題のシナリオのために H2O を使用する Python ベースのサンプル。 H2O |
~notebooks/h2o |
| SparkML 言語 | Apache Spark 2.x 上で pySpark および MMLSpark: Microsoft Machine Learning for Apache Spark 経由で Apache Spark MLLib ツールキットの機能を使用するサンプル。 SparkML 言語 |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
| XGBoost | 分類、回帰などの、XGBoost における標準的な機械学習サンプル。 XGBoost |
Windows: \dsvm\samples\xgboost\demo |
Jupyter にアクセスする
Jupyter にアクセスするには、デスクトップまたはアプリケーション メニューの [Jupyter] アイコンを選択します。 また、DSVM の Linux エディションでも Jupyter にアクセスできます。 Web ブラウザーからのリモート アクセスについては、Ubuntu の https://<Full Domain Name or IP Address of the DSVM>:8000 を参照してください。
例外を追加し、ブラウザー経由で Jupyter にアクセスできるようにするには、このガイダンスを使用してください。
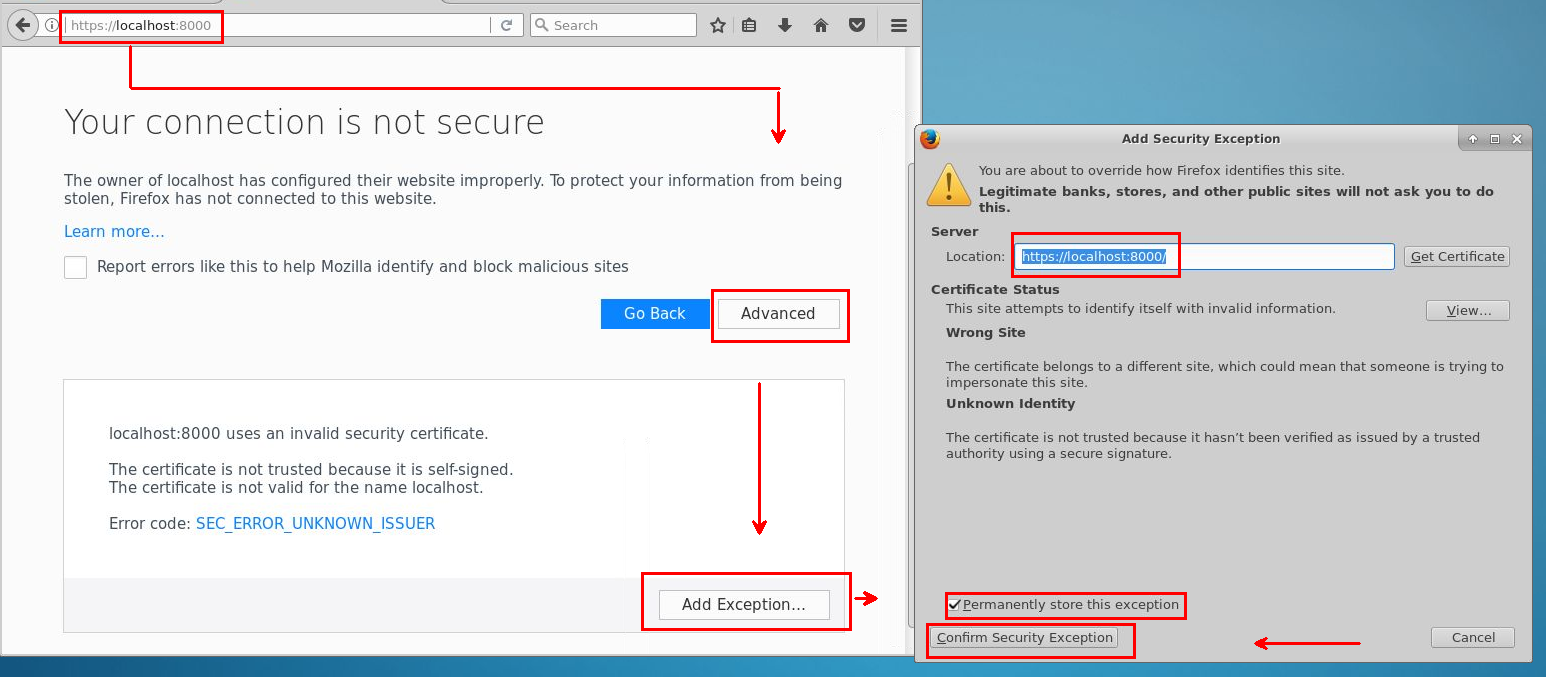
Data Science Virtual Machine へのログインに使用するパスワードと同じパスワードでサインインします。
Jupyter ホーム

R 言語

Python 言語

Julia 言語

Azure Machine Learning

PyTorch

TensorFlow

H2O

SparkML

XGBoost
