バッチ エンドポイントのジョブと入力データを作成する
バッチ エンドポイントを使用すると、大量のデータに対して長いバッチ操作を実行できます。 データは、分散領域間など、さまざまな場所に配置できます。 特定の種類のバッチ エンドポイントでは、リテラル パラメーターを入力として受け取ることもできます。
この記事では、バッチ エンドポイントのパラメーター入力を指定し、デプロイ ジョブを作成する方法について説明します。 このプロセスでは、さまざまな種類のデータの操作がサポートされています。 例については、「入力と出力について」を参照してください。
前提条件
バッチ エンドポイントを正常に呼び出してジョブを作成するには、次の前提条件を満たしていることを確認します。
バッチ エンドポイントとデプロイ。 これらのリソースを持っていない場合は、「バッチ エンドポイントにスコアリング用のモデルをデプロイする」を参照してデプロイを作成します。
バッチ エンドポイント デプロイを実行するためのアクセス許可。 AzureML データ サイエンティスト、共同作成者、所有者 の各ロールを使用して、デプロイを実行できます。 カスタム ロールの定義については、「バッチ エンドポイントでの認可」を参照して、必要な特定のアクセス許可を確認してください。
エンドポイントを呼び出すためのセキュリティ プリンシパルを表す有効な Microsoft Entra ID トークン。 このプリンシパルには、ユーザー プリンシパルまたはサービス プリンシパルを指定できます。 エンドポイントを呼び出すと、Azure Machine Learning によって、トークンに関連付けられている ID の下にバッチ デプロイ ジョブが作成されます。 次の手順で説明するように、呼び出しには独自の資格情報を使用できます。
さまざまな種類の資格情報を使用してバッチ デプロイ ジョブを開始する方法の詳細については、「さまざまな種類の資格情報を使用してジョブを実行する方法」を参照してください。
エンドポイントがデプロイされているコンピューティング クラスターは、入力データを読み取るアクセス権を持っています。
ヒント
資格情報のないデータ ストアまたは外部の Azure Storage アカウントをデータ入力として使う場合は、必ずデータ アクセス用にコンピューティング クラスターを構成してください。 コンピューティング クラスターのマネージド ID は、ストレージ アカウントをマウントするために使われます。 ジョブの ID (呼び出し元) は、基になるデータを読み取るために引き続き使用されるので、きめ細かいアクセス制御を実現できます。
ジョブの基本を作成する
バッチ エンドポイントからジョブを作成するには、エンドポイントを呼び出します。 呼び出しは、Azure CLI、Azure Machine Learning SDK for Python、または REST API 呼び出しを使用して実行できます。 次の例は、処理用の単一の入力データ フォルダーを受け取るバッチ エンドポイントの呼び出しの基本を示しています。 さまざまな入力と出力の例については、「入力と出力について」を参照してください。
バッチ エンドポイントで invoke 操作を使用します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
特定のデプロイを呼び出す
バッチ エンドポイントは、同じエンドポイントで複数のデプロイをホストできます。 ユーザーが特に指定しない限り、既定のエンドポイントが使われます。 次の手順で使用するようにデプロイを変更できます。
引数 --deployment-name または -d を使ってデプロイの名前を指定します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
ジョブのプロパティを構成する
作成されたジョブでは、呼び出し時にいくつかのプロパティを構成できます。
Note
現在、ジョブのプロパティを構成する機能は、パイプライン コンポーネントのデプロイを使用するバッチ エンドポイントでのみ使用できます。
実験名を構成する
実験名を構成するには、次の手順に従います。
引数 --experiment-name を使って実験の名前を指定します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
入力と出力について
バッチ エンドポイントは、コンシューマーがバッチ ジョブの作成に使用できる永続的な API を提供します。 同じインターフェイスを使用して、デプロイで想定される入力と出力を指定できます。 入力を使用して、ジョブを実行するためにエンドポイントに必要な情報を渡します。
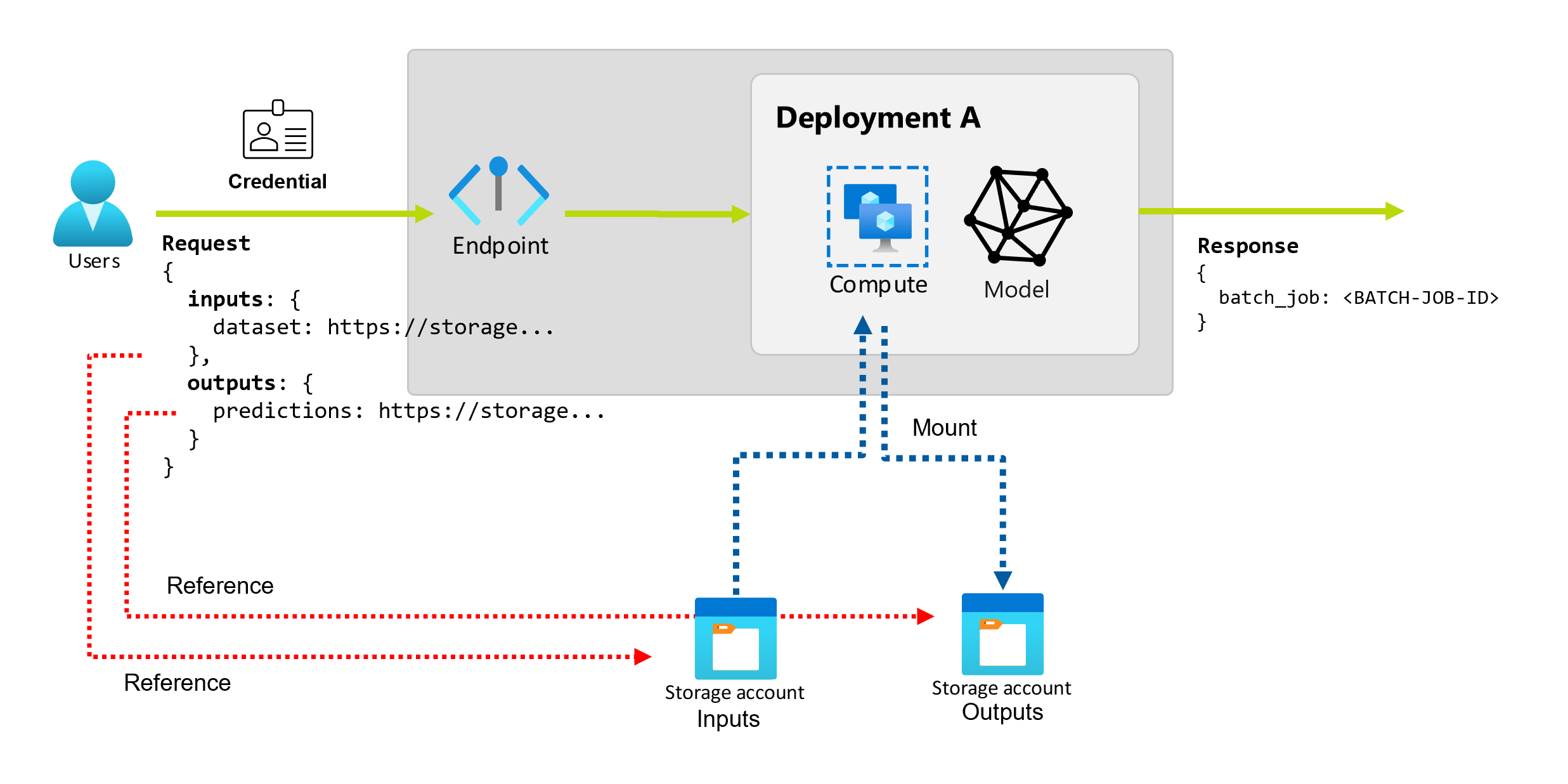
バッチ エンドポイントは次の 2 種類の入力をサポートします。
入力と出力の数と種類は、バッチ デプロイの種類によって異なります。 モデル デプロイは、常に 1 つのデータ入力を必要とし、1 つのデータ出力を生成します。 リテラル入力はサポートされていません。 ただし、パイプライン コンポーネント デプロイを使用すると、エンドポイントを構築するためのより一般的なコンストラクトが提供され、任意の数の入力 (データとリテラル) と出力を指定できます。
次の表は、バッチ デプロイの入力と出力をまとめたものです。
| デプロイの種類 | 入力の数 | サポートされている入力の種類 | 出力の数 | サポートされている出力の種類 |
|---|---|---|---|---|
| モデル デプロイ | 1 | データ入力 | 1 | データ出力 |
| パイプライン コンポーネント デプロイ | [0..N] | データ入力とリテラル入力 | [0..N] | データ出力 |
ヒント
入力と出力は常に名前付きです。 これらの名前は、呼び出し中にデータを識別し、実際の値を渡すためのキーとして機能します。 モデル デプロイでは、常に 1 つの入力と出力が必要であるため、呼び出し中に名前は無視されます。 "sales_estimation" のように、ユース ケースを最もよく表す名前を割り当てることができます。
データ入力を調べる
データ入力とは、データが配置されている場所を指す入力のことです。 バッチ エンドポイントは通常、大量のデータを消費するため、呼び出し要求の一部として入力データを渡すことはできません。 代わりに、バッチ エンドポイントがデータを検索する場所を指定します。 パフォーマンスを向上させるために、入力データはターゲット コンピューティングにマウントされ、ストリーミングされます。
バッチ エンドポイントでは、次のストレージ オプションに配置されているファイルの読み取りがサポートされています。
- Azure Machine Learning データ資産。フォルダー (
uri_folder)、ファイル (uri_file) などです。 - Azure Machine Learning データ ストア。Azure Blob Storage、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2 などです。
- Azure Storage アカウント。Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure Blob Storage などです。
- ローカル データ フォルダーまたはファイル (Azure Machine Learning CLI または Azure Machine Learning SDK for Python)。 ただし、その操作により、作業中のワークスペースの既定の Azure Machine Learning データ ストアにローカル データがアップロードされます。
重要
非推奨の通知: 型 FileDataset (V1) のデータセットは非推奨となり、今後廃止される予定です。 この機能に依存する既存のバッチ エンドポイントは引き続き機能します。 GA CLIv2 (2.4.0 以降) または GA REST API (2022-05-01 以降) で作成されたバッチ エンドポイントでは、V1 データセットはサポートされません。
リテラル入力を調べる
リテラル入力とは文字列、数値、ブール値など、呼び出し時に表現および解決できる入力のことです。 通常は、リテラル入力を使用して、パイプライン コンポーネント デプロイの一部としてエンドポイントにパラメーターを渡します。 バッチ エンドポイントでは、次のリテラル型がサポートされています。
stringbooleanfloatinteger
リテラル入力は、パイプライン コンポーネントのデプロイでのみサポートされます。 それらを指定する方法については、「リテラル入力を使ってジョブを作成する」を参照してください。
データ出力を調べる
データ出力とは、バッチ ジョブの結果が配置される場所のことです。 各出力には識別可能な名前が付けられ、Azure Machine Learning によって、名前付き出力のそれぞれに一意のパスが自動的に割り当てられます。 必要に応じて、別のパスを指定できます。
重要
バッチ エンドポイントでは、Azure Blob Storage データストアでの出力の書き込みのみがサポートされます。 階層型名前空間が有効なストレージ アカウント (Azure Datalake Gen2 または ADLS Gen2 とも呼ばれます) に書き込む必要がある場合、サービスは完全に互換性があるため、ストレージ サービスを Azure Blob Storage データストアとして登録できます。 このように、バッチ エンドポイントからの出力を ADLS Gen2 に書き込むことができます。
データ入力を使ってジョブを作成する
次の例は、データ資産、データ ストア、Azure Storage アカウントからデータ入力を取得してジョブを作成する方法を示しています。
データ資産からの入力データを使用する
Azure Machine Learning のデータ資産 (以前のデータセット) は、ジョブへの入力としてサポートされています。 Azure Machine Learning の登録済みデータ資産に格納されているデータを使用してバッチ エンドポイント ジョブを実行するには、次の手順に従います。
警告
型 Table (MLTable) のデータ資産は、現在サポートされていません。
最初にデータ資産を作成します。 このデータ資産は、バッチ エンドポイントを使って並列処理する複数の CSV ファイルを含む、1 つのフォルダーで構成されています。 データが既にデータ資産として登録されている場合は、この手順をスキップできます。
YAMLにデータ資産定義を作成します。heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/data次にデータ資産を作成します。
az ml data create -f heart-dataset-unlabeled.yml入力または要求を作成します。
エンドポイントを実行します。
--set引数を使用して入力を指定します。az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDモデル デプロイにサービスを提供するエンドポイントの場合、
--input引数を使用してデータ入力を指定できます。これは、モデルのデプロイで必要なデータ入力が常に 1 つだけであるためです。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_ID複数の入力が指定されている場合、引数
--setは長いコマンドを生成する傾向があります。 そのような場合は、YAMLファイルに入力を配置し、--file引数を使用して、エンドポイント呼び出しに必要な入力を指定します。inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latest次のコマンドを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
データ ストアからの入力データを使用する
Azure Machine Learning に登録済みのデータ ストアのデータをバッチ デプロイ ジョブで直接参照できます。 この例では、まず Azure Machine Learning ワークスペース内の既定のデータ ストアにある程度のデータをアップロードした後、それに対してバッチ デプロイを実行します。 データ ストアの格納データを使用してバッチ エンドポイント ジョブを実行するには、次の手順に従います。
Azure Machine Learning ワークスペースの既定のデータ ストアにアクセスします。 データが別のストアにある場合は、代わりにそのストアを使用できます。 既定のデータ ストアを使用しなくてもかまいません。
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')データ ストア ID は
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>のようになります。ヒント
ワークスペース内の既定の BLOB データ ストアの名前は workspaceblobstore です。 ワークスペース内の既定のデータ ストアのリソース ID が既にわかっている場合は、この手順をスキップできます。
サンプル データをいくつかデータ ストアにアップロードします。
この例では、リポジトリに含まれるサンプル データを、BLOB ストレージ アカウントのフォルダー
heart-disease-uci-unlabeledにあるフォルダーsdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/dataに既にアップロード済みであることを前提としています。 続行する前に、必ずこの手順を完了してください。入力または要求を作成します。
ファイル パスを
INPUT_PATH変数に配置します。DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"パスの
paths変数がデータ ストアのリソース ID にどのように追加されるかに注目してください。 この形式は、後続の値がパスであることを示します。ヒント
azureml://datastores/<data-store>/paths/<data-path>形式を使用して入力を指定することもできます。エンドポイントを実行します。
--set引数を使用して入力を指定します。az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHモデル デプロイにサービスを提供するエンドポイントの場合、
--input引数を使用してデータ入力を指定できます。これは、モデルのデプロイで必要なデータ入力が常に 1 つだけであるためです。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folder複数の入力が指定されている場合、引数
--setは長いコマンドを生成する傾向があります。 そのような場合は、YAMLファイルに入力を配置し、--file引数を使用して、エンドポイント呼び出しに必要な入力を指定します。inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>次のコマンドを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlデータがファイルの場合は、代わりに入力に
uri_file型を使用します。
Azure Storage アカウントからの入力データを使用する
Azure Machine Learning バッチ エンドポイントでは、Azure Storage アカウント内のクラウドの場所 (パブリックとプライベートの両方) からデータを読み取ることができます。 ストレージ アカウントに格納されているデータを使用してバッチ エンドポイント ジョブを実行するには、次の手順に従います。
ストレージ アカウントからデータを読み取るために必要な追加の構成の詳細については、「データ アクセス用にコンピューティング クラスターを構成する」を参照してください。
入力または要求を作成します。
エンドポイントを実行します。
--set引数を使用して入力を指定します。az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAモデル デプロイにサービスを提供するエンドポイントの場合、
--input引数を使用してデータ入力を指定できます。これは、モデルのデプロイで必要なデータ入力が常に 1 つだけであるためです。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folder複数の入力が指定されている場合、引数
--setは長いコマンドを生成する傾向があります。 そのような場合は、YAMLファイルに入力を配置し、--file引数を使用して、エンドポイント呼び出しに必要な入力を指定します。inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data次のコマンドを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlデータがファイルの場合は、代わりに入力に
uri_file型を使用します。
リテラル入力を使ってジョブを作成する
パイプライン コンポーネントのデプロイでは、リテラル入力を受け取ることができます。 次の例は、名前が score_mode、型が string、値が append の入力を指定する方法を示します。
YAML ファイルに入力を配置し、--file を使用して、エンドポイント呼び出しに必要な入力を指定します。
inputs.yml
inputs:
score_mode:
type: string
default: append
次のコマンドを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
引数 --set を使用して値を指定することもできます。 ただし、複数の入力が指定されている場合、このアプローチでは長いコマンドが生成される傾向があります。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
データ出力を使ってジョブを作成する
次の例は、score という名前の出力が配置される場所を変更する方法を示しています。 完全にするために、これらの例では heart_dataset という名前の入力も構成します。
Azure Machine Learning ワークスペース内の既定のデータ ストアを使用して、出力の保存します。 BLOB ストレージ アカウントであれば、ワークスペース内の他の任意のデータ ストアを使用できます。
データ出力を作成します。
OUTPUT_PATH変数を設定します。DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"完全にするために、データ入力も作成します。
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Note
パスの
paths変数がデータ ストアのリソース ID にどのように追加されるかに注目してください。 この形式は、後続の値がパスであることを示します。デプロイを実行します。