チュートリアル: クラウド ワークステーションでのモデル開発
Azure Machine Learning のクラウド ワークステーションでノートブックを使用してトレーニング スクリプトを開発する方法について説明します。 このチュートリアルでは、次のことを開始するために必要な基本について説明します。
- クラウド ワークステーションを設定して構成する。 クラウド ワークステーションには Azure Machine Learning コンピューティング インスタンスが備わっており、さまざまなモデル開発ニーズをサポートするための環境が事前に構成されています。
- クラウドベースの開発環境を使用する。
- MLflow を使用して、ノートブック内からすべてのモデル メトリックを追跡する。
前提条件
Azure Machine Learning を使用するには、ワークスペースが必要です。 まだない場合は、作業を開始するために必要なリソースの作成を完了し、ワークスペースを作成してその使用方法の詳細を確認してください。
コンピューティングから始める
ワークスペースの [コンピューティング] セクションでは、コンピューティング リソースを作成できます。 コンピューティング インスタンスは、Azure Machine Learning によって完全に管理されるクラウドベースのワークステーションです。 このチュートリアル シリーズでは、コンピューティング インスタンスを使います。 それを使って独自のコードを実行したり、モデルの開発とテストを行ったりすることもできます。
- Azure Machine Learning Studio にサインインします。
- まだ開いていない場合は、ワークスペースを選びます。
- 左側のナビゲーションで、[コンピューティング] を選びます。
- コンピューティング インスタンスがない場合は、画面の中央に [新規] と表示されます。 [新規] を選んで、フォームに入力します。 すべての既定値を使用できます。
- コンピューティング インスタンスがある場合は、一覧からそれを選びます。 停止されている場合は、[開始] を選びます。
Visual Studio Code (VS Code) を開く
実行状態になったコンピューティング インスタンスには、さまざまな方法でアクセスできます。 このチュートリアルでは、VS Code からコンピューティング インスタンスを使う方法を示します。 VS Code では、Azure Machine Learning リソースの機能を備えた完全な統合開発環境 (IDE) が提供されます。
コンピューティング インスタンスの一覧で、使用するコンピューティング インスタンスの [VS Code (Web)] または [VS Code (デスクトップ)] リンクを選びます。 [VS Code (デスクトップ)] を選んだ場合は、アプリケーションを開くかどうかを確認するポップアップが表示されることがあります。

この VS Code インスタンスは、お使いのコンピューティング インスタンスとワークスペース ファイル システムにアタッチされます。 デスクトップで開いても、表示されるファイルはワークスペース内のファイルです。
プロトタイプ作成用の新しい環境を設定する (省略可能)
スクリプトを実行するには、コードで想定される依存関係とライブラリを使用して構成された環境で作業する必要があります。 このセクションは、使用するコードに合わせた環境を作成するのに役立ちます。 ノートブックが接続する新しい Jupyter カーネルを作成するには、依存関係を定義する YAML ファイルを使用します。
ファイルをアップロードします。
アップロードしたファイルは Azure ファイル共有に保存されます。これらのファイルは各コンピューティング インスタンスにマウントされ、ワークスペース内で共有されます。
右上にある [Download raw file] (生ファイルのダウンロード) ボタンを使って、この conda 環境ファイル workstation_env.yml をお使いのコンピューターにダウンロードします。
ファイルをコンピューターから VS Code ウィンドウにドラッグします。 ファイルがワークスペースにアップロードされます。
自分のユーザー名のフォルダーにファイルを移動します。
このファイルを選んでプレビューし、そこで指定されている依存関係を確認します。 次のような内容が表示されます。
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibカーネルを作成します。
次に、ターミナルを使い、workstation_env.yml ファイルを基にして新しい Jupyter カーネルを作成します。
上部のメニュー バーで、[ターミナル] > [新しいターミナル] を選びます。
![ノートブック ツール バーの [ターミナルを開く] ツールを示すスクリーンショット。](media/tutorial-cloud-workstation/open-terminal.png?view=azureml-api-2)
現在の conda 環境を表示します。 アクティブな環境は * でマークされます。
conda env listcdを使って、workstation_env.yml ファイルをアップロードしたフォルダーに移動します。 たとえば、自分のユーザー フォルダーにアップロードした場合は、次のようになります。cd Users/myusernameworkstation_env.yml がこのフォルダーにあることを確認します。
ls提供された conda ファイルに基づいて環境を作成します。 この環境を構築するには数分かかります。
conda env create -f workstation_env.yml新しい環境をアクティブにします。
conda activate workstation_envNote
CommandNotFoundError が表示される場合は、指示に従って
conda init bashを実行し、ターミナルを閉じて新しく開きます。 その後、conda activate workstation_envコマンドを再試行します。正しい環境がアクティブであることを検証し、* でマークされた環境をもう一度探します。
conda env listアクティブな環境に基づいて新しい Jupyter カーネルを作成します。
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"ターミナル ウィンドウを閉じます。
これで新しいカーネルが作成されました。 次に、ノートブックを開き、このカーネルを使用します。
ノートブックを作成する
- 上部のメニュー バーで、[ファイル] > [新しいファイル] を選びます。
- 新しいファイルに develop-tutorial.ipynb という名前を付けます (または、任意の名前を入力します)。 .ipynb 拡張子を使っていることを確認します。
カーネルを設定する
- 右上にある [カーネルの選択] を選びます。
- [Azure ML コンピューティング インスタンス (<コンピューティング インスタンス名>)] を選びます。
- 作成したカーネル Tutorial Workstation Env を選びます。 それが表示されない場合は、右上にある [最新の情報に更新] ツールを選びます。
トレーニング スクリプトを開発する
このセクションでは、UCI データセットから準備されたテストとトレーニングの各データセットを使用して、クレジットカードの既定の支払いを予測する Python トレーニング スクリプトを開発します。
このコードでは、トレーニングには sklearn を使用して、メトリックのログ記録には MLflow を使用します。
まず、トレーニング スクリプトで使用するパッケージとライブラリをインポートするコードから始めます。
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split次に、この実験用のデータを読み込んで処理します。 このチュートリアルでは、インターネット上のファイルからデータを読み取ります。
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )トレーニング用のデータを準備します。
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesMLflowに自動ログ記録を開始するコードを追加して、メトリックと結果を追跡できるようにします。 モデル開発の反復的な性質により、MLflowは、モデルのパラメーターと結果をログに記録するのに役立ちます。 これらの実行を参照して、モデルのパフォーマンスを比較して理解します。 ログには、Azure Machine Learning 内のワークフローの開発フェーズからトレーニング フェーズに移行する準備ができた場合のコンテキストも提供されます。# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()モデルをトレーニングします。
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Note
mlflow の警告は無視できます。 追跡する必要があるすべての結果は引き続き受け取ります。
繰り返す
モデルの結果が得られたので、何かを変更して、もう一度やり直すことができます。 たとえば、別の分類子の手法を試してみてください。
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Note
mlflow の警告は無視できます。 追跡する必要があるすべての結果は引き続き受け取ります。
結果を検証する
2 つの異なるモデルを試したので、MLFfow で追跡した結果を使用して、どちらのモデルが優れているかを判断します。 正確性などのメトリックや、シナリオの最も重要なその他のインジケーターを参照できます。 MLflow によって作成されたジョブを確認することで、これらの結果をさらに詳しく調べることができます。
Azure Machine Learning スタジオでワークスペースに戻ります。
左側のナビゲーションで、[ジョブ] を選択します。
![ナビゲーションの [ジョブ] の選択方法を示すスクリーンショット。](media/tutorial-cloud-workstation/jobs.png?view=azureml-api-2)
[Develop on cloud tutorial] (クラウドでの開発チュートリアル) のリンクを選択します。
2 つの異なるジョブが表示されます。試した各モデルごとに 1 つです。 これらの名前は自動生成されます。 名前を変更する場合は、名前の上にマウス ポインターを置き、名前の横にある鉛筆ツールを使用します。
最初のジョブのリンクを選択します。 名前が上部に表示されます。 鉛筆ツールを使用してここで名前を変更することもできます。
ページには、プロパティ、出力、タグ、パラメーターなど、ジョブの詳細が表示されます。 [タグ] の下に、モデルの種類を説明する estimator_name が表示されます。
[メトリック] タブを選択して、
MLflowによってログに記録されたメトリックを表示します (異なるトレーニング セットを使用するため、結果が異なることを想定してください)。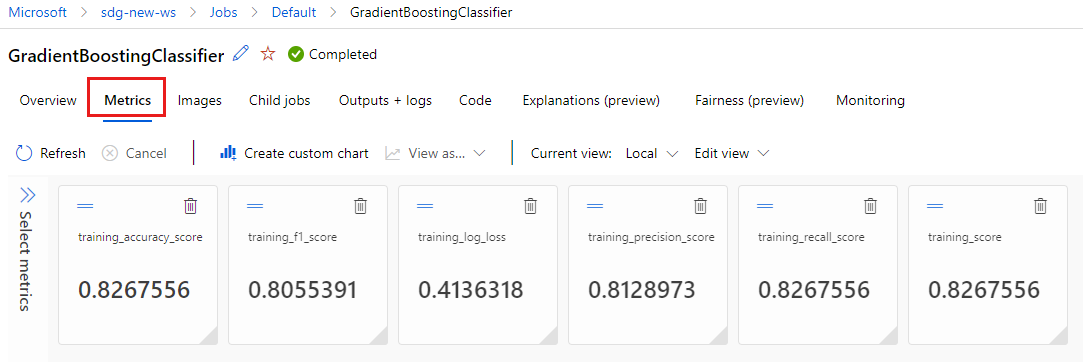
[イメージ] タブを選択して、
MLflowによって生成されたイメージを表示します。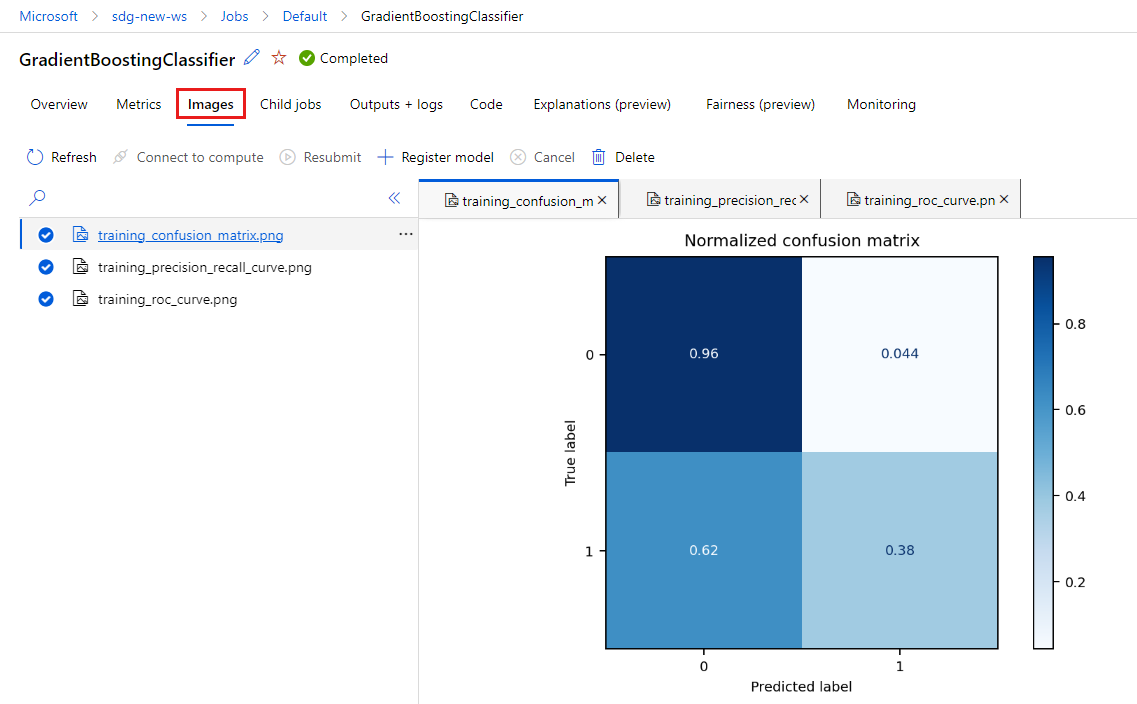
他のモデルのメトリックとイメージを戻って確認します。
Python スクリプトを作成する
次に、モデル トレーニング用にノートブックから Python スクリプトを作成します。
VS Code ウィンドウで、ノートブックのファイル名を右クリックして、[ノートブックをスクリプトにインポート] を選びます。
メニュー [ファイル] > [保存] を使って、この新しいスクリプト ファイルを保存します。 それに train.py という名前を付けます。
このファイルを確認し、トレーニング スクリプトに不要なコードを削除します。 たとえば、使用するモデルのコードを保持し、不要なモデルのコードを削除します。
- 自動ログを開始するコードは保持するようにします (
mlflow.sklearn.autolog())。 - Python スクリプトを (ここで行っているように) 対話形式で実行する場合は、実験名を定義する行を維持できます (
mlflow.set_experiment("Develop on cloud tutorial"))。 または、別の名前を付けて、[ジョブ] セクションの別のエントリとして表示することもできます。 ただし、トレーニング ジョブのスクリプトを準備する場合、その行は適用されないため、省略する必要があります。ジョブ定義には実験名が含まれます。 - 1 つのモデルをトレーニングする場合、実行開始と終了の各行 (
mlflow.start_run()とmlflow.end_run()) も必要ありません (効果はありません)。ただし、必要に応じて残すことができます。
- 自動ログを開始するコードは保持するようにします (
編集が完了したら、ファイルを保存します。
これで、希望するモデルのトレーニングに使用する Python スクリプトが作成されました。
Python スクリプトを実行する
ここでは、Azure Machine Learning 開発環境であるコンピューティング インスタンスでこのコードを実行しています。 チュートリアル: モデルのトレーニングでは、より強力なコンピューティング リソースに対して、よりスケーラブルな方法でトレーニング スクリプトを実行する方法について説明します。
Python のバージョン (workstations_env) として、このチュートリアルで前に作成した環境を選びます。 ノートブックの右下隅に、環境名が表示されます。 それを選んでから、画面の中央で環境を選びます。
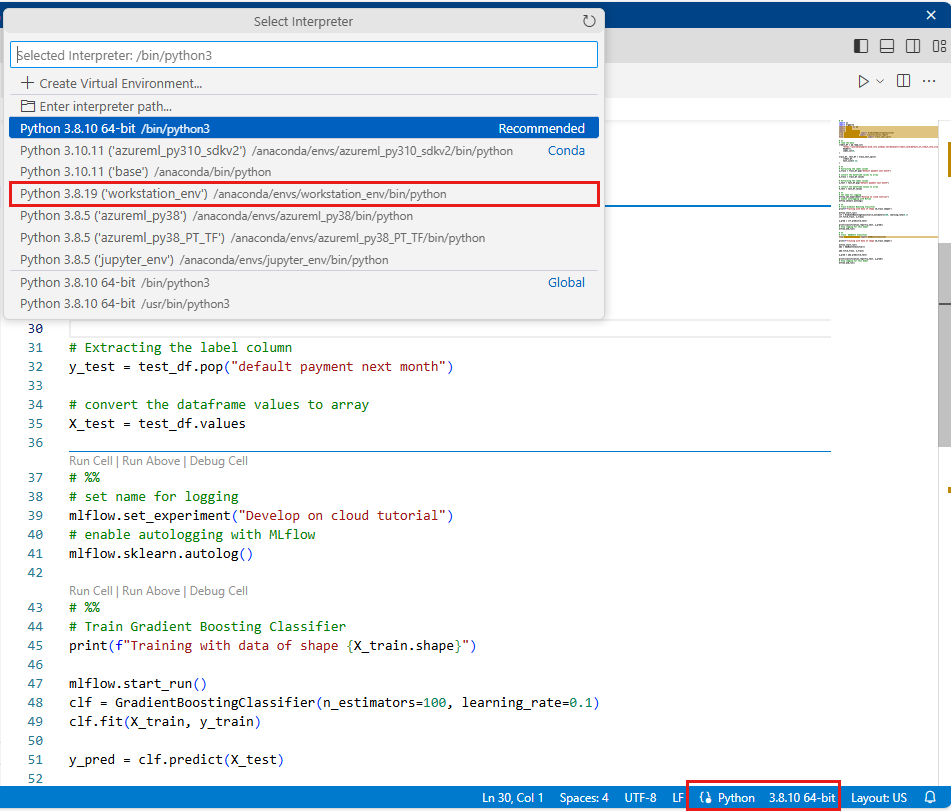
次に、Python スクリプトを実行します。 右上にある [Python ファイルの実行] ツールを使います。
![スクリーンショットでは、画面の右上にある [Python ファイルの実行] ツールが示されています。](media/tutorial-cloud-workstation/run-python.png?view=azureml-api-2)
Note
mlflow の警告は無視できます。 自動ログからのすべてのメトリックと画像は引き続き受け取ります。
スクリプトの結果を確認する
Azure Machine Learning スタジオのワークスペースで [ジョブ] に戻り、トレーニング スクリプトの結果を確認します。 トレーニング データは分割ごとに変化するため、実行間でも結果が異なることに注意してください。
リソースをクリーンアップする
引き続き他のチュートリアルに取り組む場合は、「次のステップ」に進んでください。
コンピューティング インスタンスを停止する
コンピューティング インスタンスをすぐに使用しない場合は、停止してください。
- スタジオの左側のナビゲーション領域で、[コンピューティング] を選択します。
- 上部のタブで、 [コンピューティング インスタンス] を選択します
- 一覧からコンピューティング インスタンスを選択します。
- 上部のツールバーで、 [停止] を選択します。
すべてのリソースの削除
重要
作成したリソースは、Azure Machine Learning に関連したその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
作成したどのリソースも今後使用する予定がない場合は、課金が発生しないように削除します。
Azure portal の検索ボックスに「リソース グループ」と入力し、それを結果から選択します。
一覧から、作成したリソース グループを選択します。
[概要] ページで、[リソース グループの削除] を選択します。
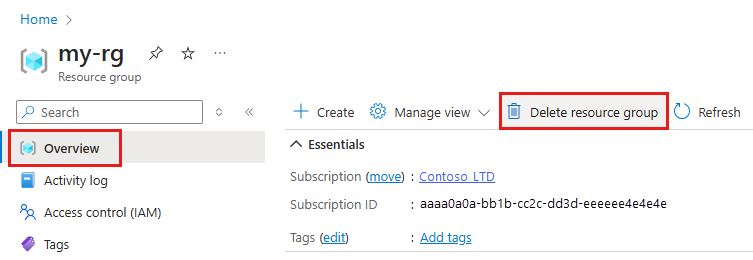
リソース グループ名を入力します。 次に、 [削除] を選択します。
次のステップ
各項目の詳細情報
- MLflow での成果物からモデルまで
- Azure Machine Learning で Git を使用する
- ワークスペースで Jupyter Notebook を実行する
- ワークスペースでコンピューティング インスタンスのターミナルを使用する
- ノートブックとターミナル セッションを管理する
このチュートリアルでは、コードが存在するのと同じコンピューターでプロトタイプを作成して、モデルを作成する初期の手順について説明しました。 運用トレーニングでは、より強力なリモート コンピューティング リソースでそのトレーニング スクリプトを使用する方法について説明します。