クイック スタート: Azure portal で検索インデックスを作成する
この Azure AI 検索のクイックスタートでは、[データのインポート] ウィザードと、Microsoft がホストする架空のホテル データを含んだ組み込みのサンプル データ ソースを使用して、初めての "検索インデックス" を作成します。 ウィザードでは、検索インデックスをコードなしで作成する手順が示され、興味のあるクエリを数分で作成することができます。
ウィザードでは、検索サービスに対するさまざまなオブジェクト (検索可能なインデックス) を作成できますが、自動化されたデータ取得のためのインデクサーとデータ ソース接続を作成することもできます。 このクイックスタートの最後に、各オブジェクトを確認します。
Note
[データのインポート] ウィザードには、OCR、テキスト翻訳、その他の AI エンリッチメントのオプションが含まれていますが、このクイックスタートでは説明しません。 応用 AI に焦点を当てた同様のチュートリアルについては、「クイックスタート: Azure portal でスキルセットを作成する」を参照してください。
前提条件
アクティブなサブスクリプションが含まれる Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search サービス (任意のレベルと任意のリージョン)。 サービスを作成するか、現在のサブスクリプションから既存のサービスを検索します。 このクイック スタート用には、無料のサービスを使用できます。
ウィザードに関する知識。 詳細については、Azure portal 内のデータ インポート ウィザードを参照してください。
組み込みのサンプル データを使用するこのクイック スタートでは、検索サービスにネットワーク アクセス制御が設定されていないことを確認します。 Azure portal コントローラーは、パブリック エンドポイントを使用して、Microsoft によってホストされている組み込みのサンプル データ ソースからデータとメタデータを取得します。 詳細については、インポート ウィザードでの安全な接続に関するページを参照してください。
領域の確認
多くのユーザーが最初に利用するのは、無料版のサービスです。 Free レベルでは、インデックス、データ ソース、インデクサーがそれぞれ 3 つに限定されています。 十分な空き領域があることを確認してから開始してください。 このクイックスタートでは、各オブジェクトを 1 つずつ作成します。
サービスの [概要] > [使用状況] タブをチェックして、既に所有しているインデックス、インデクサー、データ ソースの数を確認してください。
![Azure portal の Azure AI 検索サービス インスタンスの [概要] ページのスクリーンショット。インデックス、インデクサー、データ ソースの数が表示されています。](media/search-get-started-portal/overview-quota-usage.png#lightbox)
ウィザードを起動する
Azure アカウントを使用して Azure portal にサインインし、Azure AI Search サービスに移動します。
[概要] ページで、[データのインポート] を選択してウィザードを開始します。
![Azure portal で [データのインポート] ウィザードを開く方法を示すスクリーンショット。](media/search-import-data-portal/import-data-cmd.png)
インデックスの作成と読み込み
このセクションでは、4 つの手順でインデックスを作成して読み込みます。
データ ソースへの接続
ウィザードによって、Microsoft が Azure Cosmos DB でホストするサンプル データへのデータ ソース接続が作成されます。 このサンプル データは、パブリック エンドポイント経由のアクセスで取得されます。 このクイックスタートを実行するために、独自の Azure Cosmos DB アカウントやソース ファイルは必要ありません。
[データへの接続] で、[データ ソース] ドロップダウン リストを展開し、[サンプル] を選択します。
組み込みのサンプルの一覧で、[hotels-sample] を選択します。
![[データのインポート] ウィザードで [hotels-sample] データ ソースを選ぶ方法を示すスクリーンショット。](media/search-get-started-portal/import-hotels-sample.png)
[次: コグニティブ スキルを追加します (省略可能)] を選択して続行します。
コグニティブ スキルの構成をスキップする
[データのインポート] ウィザードでは、インデックス作成へのスキルセットと AI エンリッチメントの作成がサポートされています。
このクイックスタートでは、[コグニティブ スキルを追加します] タブの AI エンリッチメント構成オプションを無視します。
[スキップ先: 対象インデックスをカスタマイズします] を選択して続行します。
![[データのインポート] ウィザードで [Customize target index] (対象インデックスをカスタマイズ) タブにスキップする方法を示すスクリーンショット。](media/search-get-started-portal/skip-cognitive-skills.png)
ヒント
AI エンリッチメントに関心がある場合は、 「クイックスタート: Azure portal でスキルセットを作成する」をご覧ください
インデックスの構成
ウィザードによって、組み込みの hotels-sample インデックスのスキーマが推論されます。 インデックスを構成するには、次の手順に従います。
システムによって生成された値を [インデックス名] (hotels-sample-index) と [キー] フィールド (HotelId) にそのまま使用します。
システムによって生成された値をすべてのフィールド属性にそのまま使用します。
[次: インデクサーの作成] を選択して続行します。
![[データのインポート] ウィザードで生成された [hotels-sample] データ ソースのインデックス定義を示すスクリーンショット。](media/search-get-started-portal/hotels-sample-generated-index.png)
少なくとも、インデックスにはインデックス名とフィールドのコレクションが必要です。 フィールドのいずれかが、各ドキュメントを一意に識別するための "ドキュメント キー" としてマークされている必要があります。 値は常に文字列です。 ウィザードは、一意の文字列フィールドをスキャンし、キーのために 1 つを選択します。
各フィールドには、名前、データ型、検索インデックス内のフィールドの使用方法を制御する "属性" があります。 チェックボックスを使って、次の属性を有効または無効にすることができます。
- [取得可能]: クエリ応答で返されるフィールド。
- [フィルター可能]: フィルター式を指定できるフィールド。
- [並べ替え可能]: orderby 式を指定できるフィールド。
- [ファセット可能]: ファセット ナビゲーション構造で使用されるフィールド。
- [検索可能]: フルテキスト検索で使用されるフィールド。 文字列は検索可能です。 数値フィールドとブール型フィールドは通常、検索対象外として指定されます。
文字列 は、取得可能かつ検索可能です。 整数には、[取得可能]、[フィルター可能]、[Sortable] (並び替え可能)、[ファセット可能] の属性が付いています。
属性はストレージに影響します。 [フィルター可能] フィールドでは追加のストレージが使用されますが、[取得可能] では使用されません。 詳細については、「属性と suggester がストレージに与える影響を示す例」を参照してください。
オートコンプリートやクエリ候補が必要な場合は、言語アナライザーまたはサジェスターを指定できます。
インデクサーを構成して実行する
最後の手順では、インデクサーを構成して実行します。 このオブジェクトによって、実行可能なプロセスが定義されます。 この手順では、データ ソース、インデックス、インデクサーを作成します。
システムによって生成された値を [Indexer name] (インデクサー名) (hotels-sample-indexer) にそのまま使用します。
このクイックスタートでは、既定のオプションを使用して、インデクサーをすぐに 1 回実行します。 ホストされているデータは静的であるため、変更の追跡は有効になっていません。
[送信] を選択して、インデクサーを作成し、同時に実行します。
![[データのインポート] ウィザードで [hotels-sample] データ ソースのインデクサーを構成する方法を示すスクリーンショット。](media/search-get-started-portal/hotels-sample-indexer.png)
インデクサーの進行状況を監視する
Azure portal でインデクサーまたはインデックスの作成を監視できます。 サービスの概要ページには、Azure AI Search サービスで作成されたリソースへのリンクがあります。
左側の [インデクサー] を選びます。
![Azure portal でインデクサー作成の [実行中] の進行状況を示すスクリーンショット。](media/search-get-started-portal/indexers-status.png)
Azure portal でページの結果が更新されるまでには数分かかる場合があります。 状態が [実行中] または [成功] の新しく作成されたインデクサーが一覧に表示されます。 一覧には、インデックスが作成されたドキュメントの数も表示されます。
検索インデックスの結果をチェックする
左側の [インデックス] を選びます。
[hotels-sample-index] を選びます。
Azure portal のページが更新されるまで待ちます。 ドキュメント数とストレージ サイズと共にインデックスが表示されます。
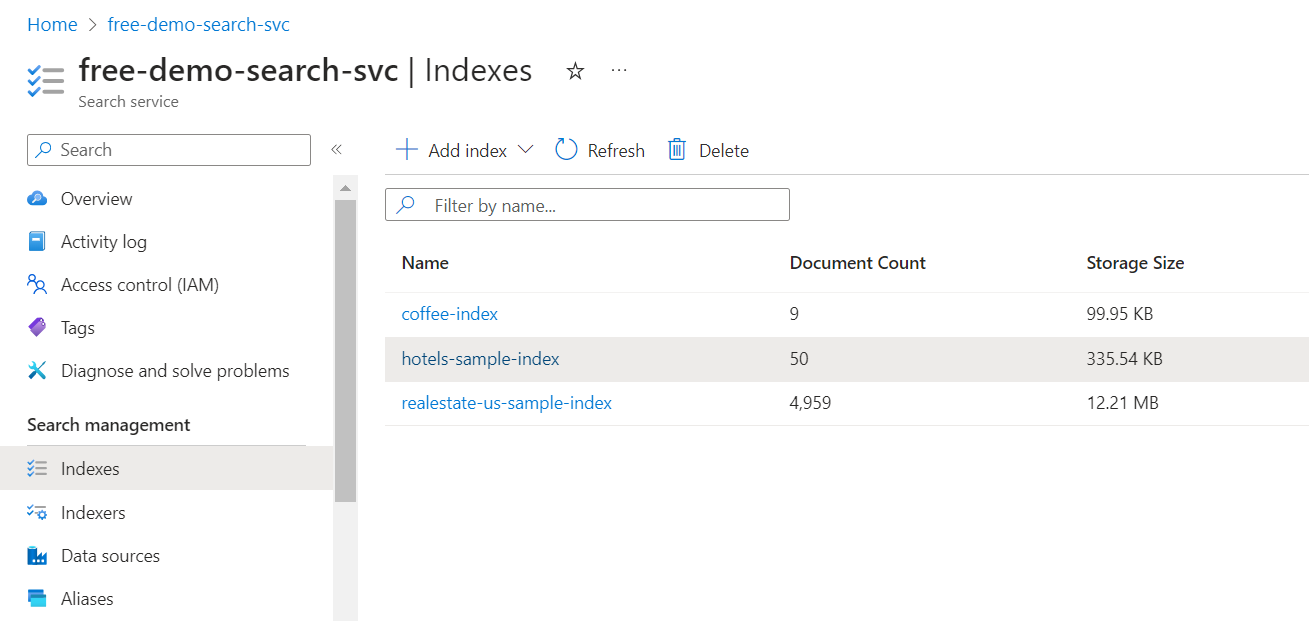
[フィールド] タブを選択して、インデックス スキーマを表示します。
どのようなクエリを作成すればよいか把握するために、[フィルター可能] または [並べ替え可能] なフィールドを確認します。
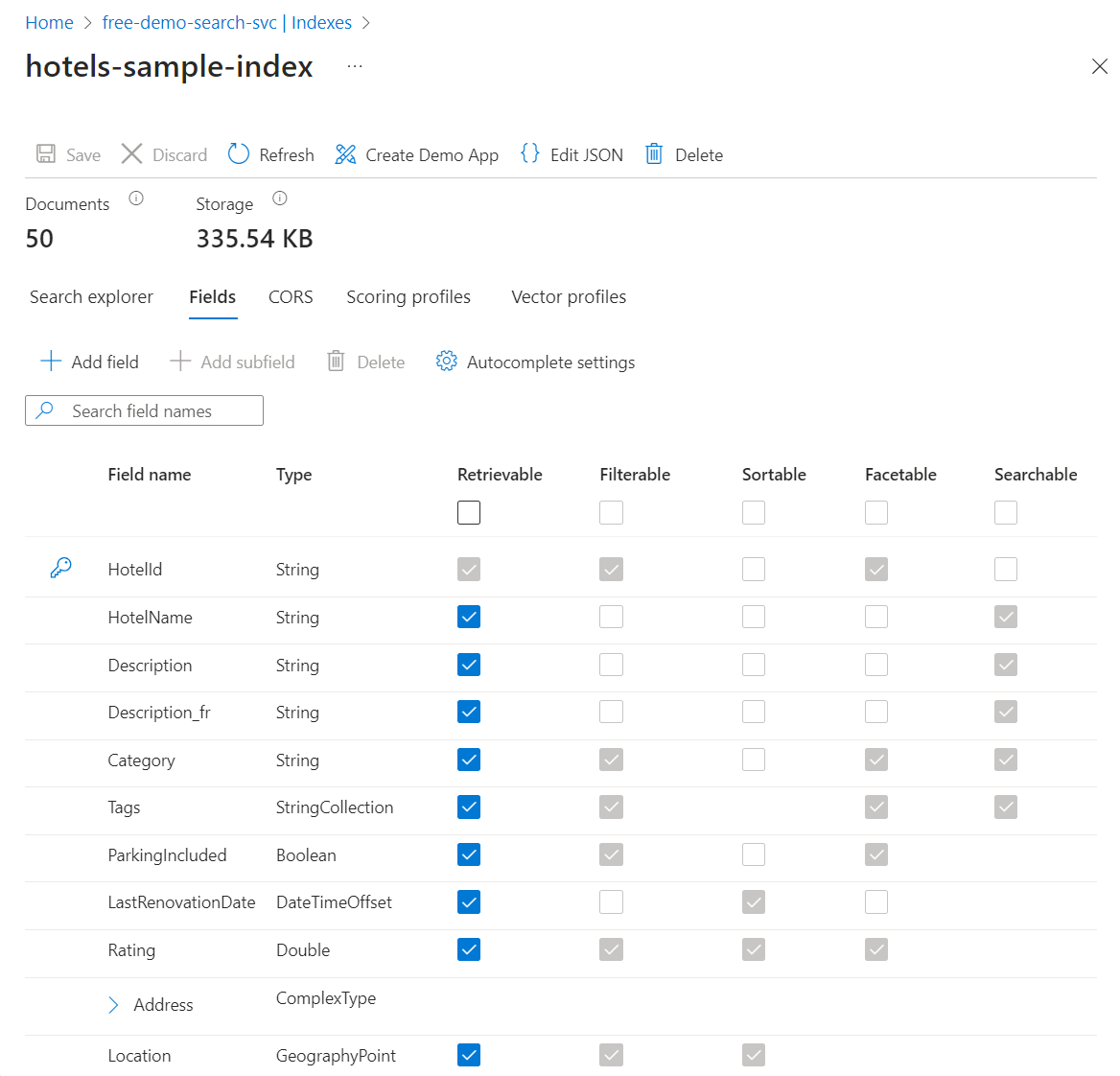
フィールドを追加または変更する
[フィールド] タブでは、[フィールドの追加] と名前、サポートされているデータ型、属性を使って、新しいフィールドを作成できます。
既存のフィールドの変更はより困難です。 既存のフィールドにはインデックスにおける物理的表現が含まれているため、コード内であっても編集することはできません。 既存のフィールドを根本的に変えるには、フィールドを新たに作成して、元のフィールドと置き換える必要があります。 その他のコンストラクト (スコアリング プロファイル、CORS オプションなど) は、いつでもインデックスに追加することができます。
インデックスの設計時に何を編集できて何を編集できないかを明確に理解するために、インデックスの定義オプションを確認してください。 フィールド の一覧で淡色表示されているオプションは、編集することも削除することもできない値を示しています。
検索エクスプローラーを使用したクエリ実行
これで、Search エクスプローラーを使ってクエリできる検索インデックスができました。 Search エクスプローラーは、Search POST REST API に準拠した REST 呼び出しを送信します。 このツールでは、単純なクエリ構文と完全な Lucene クエリ構文がサポートされています。
[Search エクスプローラー] タブで、検索するテキストを入力します。
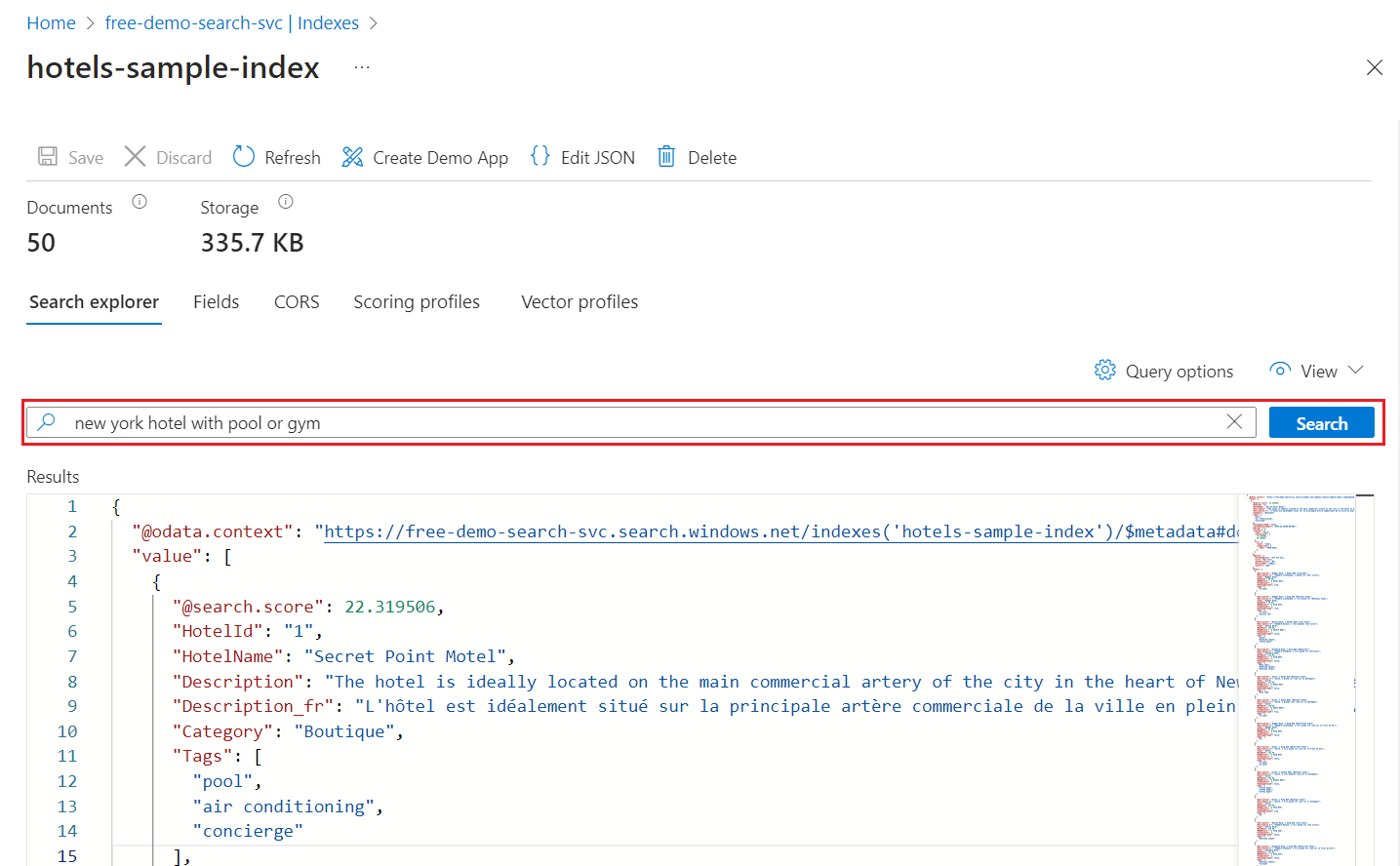
ミニマップを使って、出力の非表示領域にすばやくジャンプします。
構文を指定するには、JSON ビューに切り替えます。
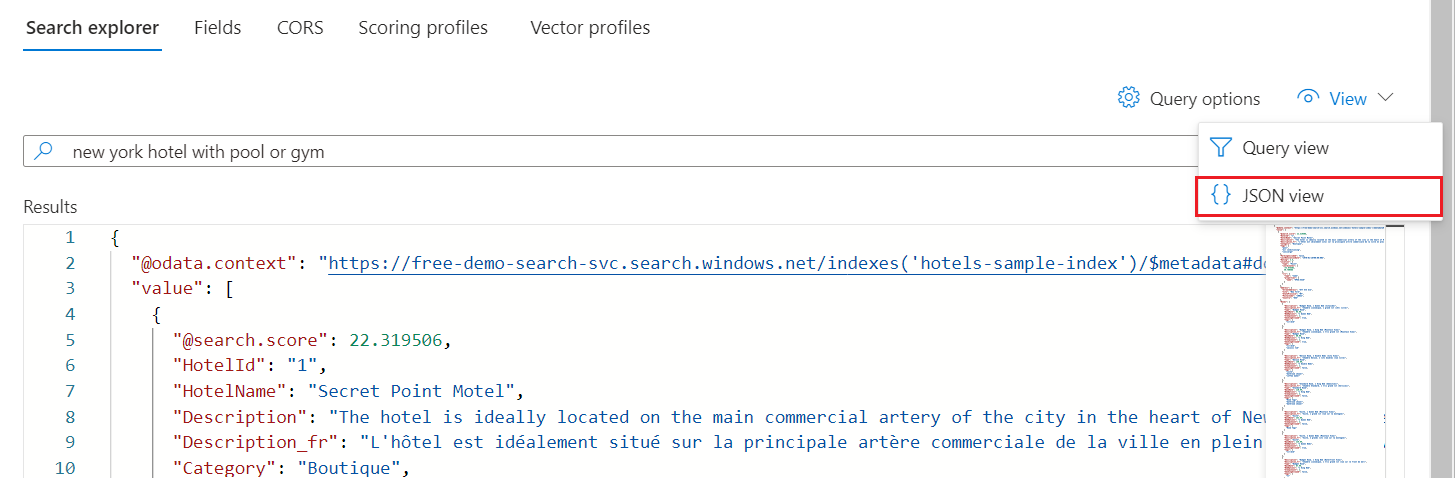
ホテルのサンプルのインデックスに対するクエリ例
以下の例では、JSON ビューと 2024-05-01-preview REST API バージョンを想定しています。
ヒント
JSON ビューでは、パラメーター名を補完する IntelliSense がサポートされるようになりました。 JSON ビュー内にカーソルを置き、スペース文字を入力すると、すべてのクエリ パラメーターの一覧が表示されます。"s" のような 1 文字を入力すると、"s" で始まるクエリ パラメーターのみが表示されます。 IntelliSense では無効なパラメーターも除外されないため、ご自身で最善の判断を行う必要があります。
フィルターの例
Parking、Tags、Renovation Date、Rating、Location はフィルター可能です。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "Rating gt 4"
}
ブール値のフィルターは、既定では "true" を想定します。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "ParkingIncluded"
}
地理空間の検索はフィルターベースです。 geo.distance 関数は、指定した Location と geography'POINT の各座標に基づいて位置データのすべての結果をフィルター処理します。 このクエリでは、緯度と経度の座標 -122.12 47.67 の 5 キロメートル以内にあるホテル ("レドモンド、ワシントン、米国") がシークされます。クエリには、ホテル名と住所の場所と共に一致項目の総数 &$count=true が表示されます。
{
"search": "*",
"select": "HotelName, Address/City, Address/StateProvince",
"count": true,
"top": 10,
"filter": "geo.distance(Location, geography'POINT(-122.12 47.67)') le 5"
}
完全な Lucene 構文の例
既定の構文は単純な構文ですが、あいまい検索、用語ブースト、または正規表現が必要な場合は、完全な構文を指定します。
{
"queryType": "full",
"search": "seatle~",
"select": "HotelId, HotelName,Address/City, Address/StateProvince",
"count": true
}
既定では、クエリ用語のスペルを間違うと (Seattle に対する seatle など)、通常の検索では一致する項目を返すことができません。 queryType=full パラメーターは、チルダ ~ オペランドをサポートする完全な Lucene クエリ パーサーを呼び出します。 これらのパラメーターが存在する場合、クエリは指定したキーワードのあいまい検索を実行します。 このクエリは、キーワードに類似しているものの、完全には一致しないドキュメントと一致します。
少し時間を取って、インデックスに対してこれらのクエリ例をいくつか試してみてください。 クエリについて詳しくは、「Azure AI Search でのクエリ実行」を参照してください。
リソースをクリーンアップする
独自のサブスクリプションを使用する場合は、プロジェクトの最後に、作成したリソースがまだ必要かどうかを確認することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースを個別に削除するか、リソース グループを削除してリソースのセット全体を削除することができます。
Azure portal の左側のペインにある [すべてのリソース] または [リソース グループ] で、お使いのサービスのリソースを検索および管理できます。
無料サービスを使用する場合は、インデックス、インデクサー、データ ソースがそれぞれ 3 つに制限されることに注意してください。 Azure portal で個別の項目を削除して、制限を超えないようにすることができます。
次のステップ
Azure portal のウィザードで、ブラウザーで動作するすぐに使用できる Web アプリを生成してみましょう。 このウィザードを使用して、このクイックスタートで作成した小さなインデックスで試すか、またはいずれかのビルトイン サンプル データ セットを使用して充実した検索環境を実現することができます。