クイックスタート: Azure portal の検索エクスプローラーを使用して画像を検索する
このクイックスタートでは、Azure portal の [データのインポートとベクトル化] ウィザードを使用して画像検索を開始する方法について説明します。 また、検索エクスプローラーを使用して画像ベースのクエリを実行する方法も示します。
サンプル データは、azure-search-sample-data リポジトリ内の画像ファイルで構成されていますが、別の画像を使ってチュートリアルを実行することもできます。
前提条件
Azure サブスクリプション。 無料で作成できます。
Azure AI サービスのマルチサービス アカウント。画像のベクトル化と光学式文字認識 (OCR) に使用します。 アカウントは、Azure AI Vision マルチモーダル埋め込みを利用できるリージョンに存在する必要があります。
現在、使用できるリージョンは次のとおりです: EastUS、WestUS、WestUS2、NorthEurope、WestEurope、FranceCentral、SwedenCentral、SwitzerlandNorth、SoutheastAsia、KoreaCentral、AustraliaEast、JapanEast。 更新された一覧については、こちらのドキュメントを確認してください。
インデックス作成とクエリのための Azure AI 検索。 レベルは問いませんが、Azure AI サービスと同じリージョンにある必要があります。
サービス レベルによって、インデックスを作成できる BLOB の数が決まります。 このチュートリアルの作成には Free レベルを使用し、コンテンツを 10 個の JPG ファイルに制限しました。
画像ファイルを BLOB として保存する Azure Storage。 Azure Blob Storage または Azure Data Lake Storage Gen2 (階層型名前空間を持つストレージ アカウント)、標準パフォーマンス (汎用 v2) アカウントを使用します。 アクセス層は、ホット、クール、コールドにすることができます。
上記のすべてのリソースでは、ポータル ノードがそれらにアクセスできるように、パブリック アクセスが有効になっている必要があります。 そうでないと、ウィザードは失敗します。 ウィザードの実行後、セキュリティのために統合コンポーネントでファイアウォールとプライベート エンドポイントを有効にすることができます。 詳細については、インポート ウィザードでの安全な接続に関するページを参照してください。
プライベート エンドポイントが既に存在しており、それらを無効にすることができない場合、代替手段は仮想マシン上でスクリプトまたはプログラムからそれぞれのエンドツーエンド フローを実行することです。 仮想マシンはプライベート エンドポイントと同じ仮想ネットワーク上にある必要があります。 垂直統合用の Python コード サンプルを次に示します。 同じ GitHub リポジトリには、他のプログラミング言語のサンプルがあります。
無料検索サービスでは、Azure AI 検索への接続に対するロールベースのアクセス制御がサポートされていますが、Azure Storage または Azure AI Vision への送信接続でのマネージド ID はサポートされていません。 このレベルのサポートは、無料の検索サービスと他の Azure サービス間の接続でキーベースの認証を使用する必要があることを意味します。 より安全な接続のためには:
- Basic レベル以上を使用する。
- 他の Azure サービス上の Azure AI 検索からの要求を許可するようにマネージド ID とロールの割り当てを構成します。
領域の確認
Free サービスで始める場合は、3 つのインデックス、3 つのデータ ソース、3 つのスキルセット、3 つのインデクサーに制限されます。 十分な空き領域があることを確認してから開始してください。 このクイックスタートでは、各オブジェクトを 1 つずつ作成します。
サンプル データの準備
unsplash-signs 画像フォルダーをローカル フォルダーにダウンロードするか、自分の画像を見つけます。 Free の検索サービスでは、エンリッチメント処理の無料クォータに収まるように、画像ファイルを 20 個未満に抑えてください。
Azure アカウントを使用して Azure portal にサインインし、Azure Storage アカウントに移動します。
左側のペインにある [データ ストレージ] の下の [コンテナー] を選択します。
新しいコンテナーを作成してから、画像をアップロードします。
ウィザードを起動する
検索サービスと Azure AI サービスが同じサポートされているリージョンとテナントに配置されており、Azure Storage Blob コンテナーが既定の構成を使用している場合は、ウィザードを開始できる状態です。
Azure アカウントを使用して Azure portal にサインインし、Azure AI Search サービスに移動します。
[概要] ページで、[データのインポートとベクトル化] を選択します。

データへの接続
次の手順は、画像を提供するデータ ソースに接続することです。
[データ接続の設定] ページで、[Azure Blob Storage] を選択します。
Azure サブスクリプションを指定します。
Azure Storage の場合は、データを提供するアカウントとコンテナーを選択します。 残りのボックスについては既定値を使用します。
[次へ] を選択します。
テキストをベクター化する
生コンテンツにテキストが含まれている場合、またはスキルセットによってテキストが生成される場合、ウィザードからテキスト埋め込みモデルが呼び出され、そのコンテンツのベクトルが生成されます。 この演習では、次の手順で追加する OCR スキルからテキストが生成されます。
Azure AI Vision にはテキスト埋め込み機能があるため、そのリソースをテキストのベクトル化に使用します。
[テキストのベクトル化] ページで、[AI Vision のベクトル化] を選びます。 使用できない場合は、Azure AI 検索と Azure AI マルチサービス アカウントが、AI Vision マルチモーダル API をサポートするリージョンに一緒に存在していることを確認します。
[次へ] を選択します。
画像のベクトル化とエンリッチ
Azure AI Vision を使用して、画像ファイルのベクトル表現を生成します。
この手順では、AI を適用して画像からテキストを抽出することもできます。 ウィザードは、Azure AI サービスの OCR を使用して、画像ファイル内のテキストを認識します。
OCR がワークフローに追加されると、さらに 2 つの出力がインデックスに表示されます。
chunkフィールドには、画像に含まれる任意のテキストの OCR で生成された文字列が設定されます。text_vectorフィールドにはchunkの文字列を表す埋め込みが設定されます。
chunk フィールドにプレーン テキストを含めることは、セマンティック ランク付けやスコアリング プロファイルなどの文字列を操作する関連性機能を使用する場合に便利です。
[画像のベクトル化] ページで、[画像のベクトル化] チェックボックスをオンにして、[AI Vision ベクトル化] を選びます。
[テキストのベクトル化に選んだものと同じ AI サービスを使用する] を選びます。
エンリッチメント セクションで [画像からテキストを抽出する] と [画像のベクトル化に選択したものと同じ AI サービスを使用する] を選択します。
[次へ] を選択します。
インデックス作成をスケジュールする
[詳細設定] ページの [インデックス作成のスケジュール] で、インデクサーの実行スケジュールを指定します。 この演習では [1 回] をお勧めします。 基となるデータが揮発性のデータ ソースの場合は、インデックス作成をスケジュールして変更を取得できます。

[次へ] を選択します。
ウィザードを終了する
[構成の確認] ページで、ウィザードによって作成されるオブジェクトのプレフィックスを指定します。 共通のプレフィックスは、整理された状態を保つのに役立ちます。
[作成] を選択します
ウィザードの構成が完了すると、次のオブジェクトが作成されます。
インデックス作成パイプラインを駆動するインデクサー。
BLOB ストレージへのデータ ソース接続。
ベクトル フィールド、テキスト フィールド、ベクタライザー、ベクトル プロファイル、ベクトル アルゴリズムを含むインデックス。 ウィザードのワークフロー中に既定のインデックスを変更することはできません。 プレビュー機能を使用できるようにするために、インデックスは 2024-05-01-preview REST API に準拠しています。
次の 5 つのスキルを備えたスキルセット。
- OCR スキルを使うと、画像ファイル内のテキストを認識できます。
- テキスト マージ スキルを使うと、OCR 処理のさまざまな出力を統合できます。
- テキスト分割スキルを使うと、データ チャンクを追加できます。 このスキルはウィザードのワークフローに組み込まれています。
- Azure AI Vision マルチモーダル埋め込みスキルは、OCR から生成されたテキストをベクトル化するために使用されます。
- 画像をベクトル化するために、Azure AI Vision マルチモーダル埋め込みスキルが再度呼び出されます。
結果をチェックする
検索エクスプローラーでは、クエリ入力としてテキスト、ベクトル、画像を使用できます。 検索領域に画像をドラッグしたり、選択したりできます。 検索エクスプローラーによって画像がベクトル化され、ベクトルがクエリ入力として検索エンジンに送信されます。 画像のベクトル化では、インデックスにベクトル化定義 (埋め込みモデル入力に基づいて [データのインポートとベクトル化] が作成したもの) があることが想定されています。
Azure portal で [検索管理]>[インデックス] に移動し、作成したインデックスを選択します。 検索エクスプローラーは最初のタブです。
[表示] メニューで [画像ビュー] を選択します。
サンプル画像ファイルを含むローカル フォルダーから画像をドラッグします。 または、ファイル ブラウザーを開いてローカル画像ファイルを選びます。
[検索] を選んでクエリを実行します。
一番上の一致は検索した画像になるはずです。 ベクトル検索では類似したベクトルが一致するため、検索エンジンはクエリ入力に十分類似したドキュメントを返します (結果は最大
k個)。 JSON ビューに切り替えると、関連性の調整を含むより高度なクエリを実行できます。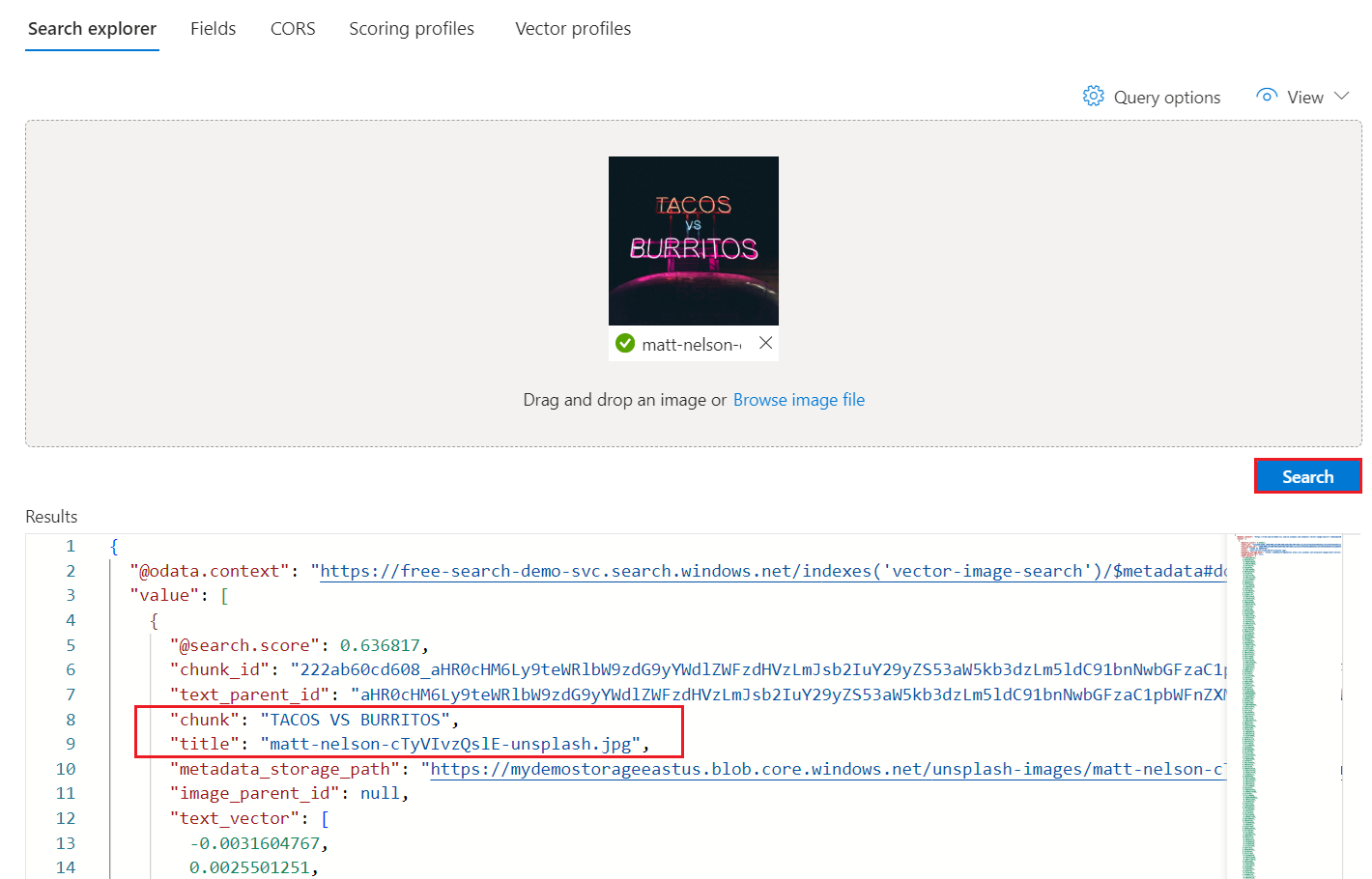
他のクエリ オプションを試して検索結果を比較してみてください。
- 結果を読みやすくするため、ベクトルを非表示にします (推奨)。
- クエリを実行するベクトル フィールドを選びます。 既定値はテキスト ベクトルですが、画像ベクトルを指定して、クエリの実行からテキスト ベクトルを除外できます。
クリーンアップ
このデモでは、課金対象の Azure リソースを使用します。 リソースが不要になった場合は、料金が発生しないようにサブスクリプションからリソースを削除してください。
次のステップ
このクイックスタートでは、画像検索に必要なすべてのオブジェクトを作成する [データのインポートとベクトル化] ウィザードについて説明しました。 各手順について詳しく確認するには、垂直統合サンプルを試してください。