Service Fabric のリソース使用量と負荷をメトリックで管理する
"メトリック" は、サービスが関心を持っているリソースであり、クラスター内のノードによって提供されます。 メトリックは、サービスのパフォーマンスを向上させたり監視したりするために管理する必要があるすべての要素を指します。 たとえば、メモリの消費量を監視して、サービスが過負荷になっているかどうかを知ることができます。 パフォーマンスを向上させるためにメモリ制約が少ないところにサービスを移動できるかどうかを確認するために使用することもできます。
メモリ、ディスク、CPU 使用率などはすべてメトリックの例です。 これらのメトリックは物理メトリック、つまり管理する必要があるノード上の物理リソースに対応するリソースです。 また、メトリックは論理メトリックの場合もあり、一般的にメトリックは論理的です。 "MyWorkQueueDepth"、"MessagesToProcess"、"TotalRecords" などは論理メトリックです。 論理メトリックはアプリケーションによって定義され、物理リソースの消費量に間接的に対応します。 論理メトリックが一般的なのは、物理リソースの消費量をサービス単位で計測してレポートすることは困難である可能性があるためです。 独自の物理メトリックの計測とレポートが複雑であることも、Service Fabric にいくつかの既定のメトリックが用意されている理由です。
Default metrics
サービスの記述とデプロイを開始するとしましょう。 この時点では、サービスがどの物理リソースや論理リソースを使用するかはわかりません。 それでも、何も問題ありません。 Service Fabric Cluster Resource Manager は、他のメトリックが指定されていない場合は、既定のメトリックを使用します。 これらは次のとおりです。
- PrimaryCount: ノード上のプライマリ レプリカの数
- ReplicaCount: ノード上のステートフル レプリカの合計数
- Count: ノード上のすべてのサービス オブジェクト (ステートレスおよびステートフル) の数
| メトリック | ステートレス インスタンス負荷 | ステートフル セカンダリ負荷 | ステートフル プライマリ負荷 | Weight |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | 高 |
| ReplicaCount | 0 | 1 | 1 | Medium |
| Count | 1 | 1 | 1 | 低 |
基本的なワークロードでは、既定のメトリックによって、作業がクラスターに適切に分散されます。 次の例で、2 つのサービスを作成し、均衡をとることを既定のメトリックに任せた場合は何が起こるかを見てみましょう。 1 つ目のサービスはステートフル サービスであり、3 つのパーティションとサイズが 3 に設定されたターゲット レプリカ セットがあります。 2 つ目のサービスはステートレス サービスであり、1 つのパーティションと 3 つのインスタンスがあります。
次のようになります。
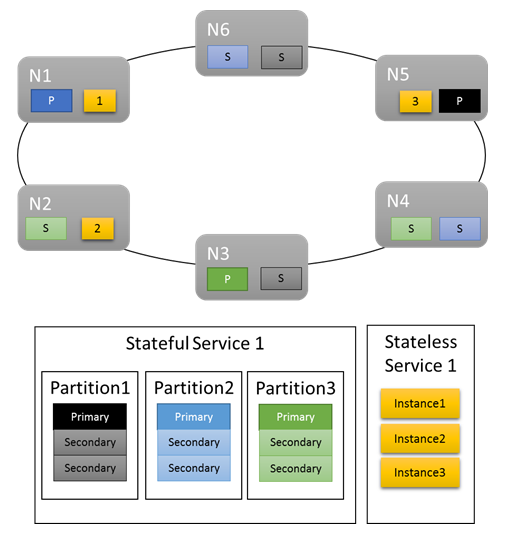
注意事項:
- ステートフル サービスのプライマリ レプリカは複数のノードに分散される
- 同じパーティションのレプリカは異なるノードに配置される
- プライマリおよびセカンダリの数がクラスター内に分散されている
- サービス オブジェクトがすべて各ノードに均等に割り当てられている
いいでしょう。
既定のメトリックは、手始めとしては十分に機能します。 ただし、既定のメトリックが有効なのはここまです。 次に例を示します。選択したパーティション構成が、すべてのパーティションによって完全に均等に使用される結果になる可能性はどの程度あるでしょうか。 特定のサービスに対する負荷が長時間一定であったり、特定の時点で複数のパーティションで負荷が同じであったりするのはどんなときでしょうか。
既定のメトリックだけを使用して実行することはできます。 ただし、そうすることは、通常は、クラスターの使用率が低くなり、思った以上に不均衡になることを意味します。 その理由は、既定のメトリックには適応性がなく、すべてが同等であると仮定しているためです。 たとえば、ビジー状態であるプライマリとビジー状態でないプライマリは、どちらも PrimaryCount メトリックでは "1" としてカウントされます。 最悪の場合、既定のメトリックのみの使用によって一部のノードに負荷の割り当てが集中し、それによってパフォーマンスが低下する可能性もあります。 クラスターを最大限活用し、パフォーマンスに関する問題を回避したいと考えているのであれば、カスタム メトリックと動的な負荷レポートを使用する必要があります。
カスタム メトリック
メトリックは、サービスを作成するときに名前付きサービス インスタンスごとに構成されます。
すべてのメトリックにはその内容について説明するプロパティ (名前、重み、および既定の負荷) があります。
- Metric Name:メトリックの名前。 メトリック名は、Resource Manager から見たクラスター内のメトリックの一意の識別子です。
注意
未定義の動作につながる可能性があるため、カスタム メトリック名をシステム メトリック名 (つまり、servicefabric:/_CpuCores または servicefabric:/_MemoryInMB) にすることはできません。 Service Fabric バージョン 9.1 以降、これらのカスタム メトリック名を持つ既存のサービスに対して、メトリック名が正しくないことを示す正常性警告が発行されます。
- Weight:メトリックの重みは、このサービスの他のメトリックに対する、このメトリックの相対的な重要度を定義します。
- Default Load:既定の負荷は、サービスがステートレスまたはステートフルであるかによって異なる方法で表されます。
- ステートレス サービスの場合、各メトリックに DefaultLoad という名前のプロパティが 1 つだけあります。
- ステートフル サービスの場合は、次のように定義します。
- PrimaryDefaultLoad:このサービスがプライマリのときに使用する、このメトリックの既定値
- SecondaryDefaultLoad:このサービスがセカンダリのときに使用する、このメトリックの既定値
注意
カスタム メトリックを定義し、"既定のメトリックも併用する" 場合は、既定のメトリックを "明示的に" 追加し、それらの重みと値を定義する必要があります。 これは、既定のメトリックとカスタム メトリックの関係を定義する必要があるためです。 たとえば、プライマリの分散よりも ConnectionCount や WorkQueueDepth のほうに関心があるとします。 既定では、PrimaryCount メトリックの重みは High であるため、他のメトリックを追加するときに PrimaryCount メトリックの重みを Medium に減らすことで、他のメトリックのほうが確実に優先順位が高くなるようにすることができます。
サービスに対するメトリックの定義 - 例
次のように構成するとします。
- サービスは "ConnectionCount"という名前のメトリックをレポートする
- 既定のメトリックも使用する
- 測定を何度か行った結果、サービスのプライマリ レプリカは、通常は 20 単位の "ConnectionCount" を使用することがわかった
- セカンダリは 5 単位の "ConnectionCount" を使用する
- この特定のサービスのパフォーマンスを管理する上で最も重要なメトリックは "ConnectionCount" であることがわかっている
- プライマリ レプリカの均衡をとることも望んでいる。 プライマリ レプリカの均衡をとることは、通常はどんな場合でも推奨されます。 これにより、ノードや障害ドメインの消失によって大多数のプライマリ レプリカに影響が及ぶことを回避できます。
- それ以外は、既定のメトリックで十分である
このメトリックの構成でサービスを作成するためのコードを次に示します。
コード:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
注意
上記の例とこのドキュメントの残りの部分では、名前付きサービスごとのメトリックの管理について説明しています。 サービスのメトリックをサービスの "種類" レベルで定義することも可能です。 これは、サービス マニフェストにそれらを指定することで実現します。 種類レベルのメトリックの定義は、いくつかの理由で推奨されません。 最初の理由は、メトリック名は多くの場合環境に固有であることです。 堅固な結び付きがない限り、ある環境のメトリック "Cores" が他の環境では "MiliCores" や "CoReS" ではないことを確信することはできません。 マニフェストにメトリックを定義する場合は、環境ごとに新しいマニフェストを作成する必要があります。 これは、通常は、わずかな違いがある複数のマニフェストの増殖につながり、それによって管理が困難になる可能性があります。
メトリックの負荷は、一般的に、名前付きサービス インスタンスごとに割り当てられます。 たとえば、使用頻度が高くない CustomerA 用に 1 つのサービス インスタンスを作成するとします。 同時に、作業負荷が高い CustomerB 用に別のインスタンスを作成するとします。 この場合、これらのサービスの既定の負荷を調整することができます。 マニフェスト経由で定義されたメトリックと負荷があるときに、このシナリオをサポートする場合は、顧客ごとに異なるアプリケーションとサービスの種類が必要です。 サービスの作成時に定義された値はマニフェストに定義された値をオーバーライドするため、それらの値を使用して特定の既定値を設定できます。 ただし、これを行うと、マニフェストに宣言された値とサービスの実行時に使用される値が一致しなくなります。 これにより、混乱が発生する可能性があります。
注意: 既定のメトリックのみを使用する場合は、メトリックのコレクションを修正したり、サービスの作成時に特別なことをしたりする必要はまったくありません。 既定のメトリックは、他のメトリッが定義されていないときに自動的に使用されます。
次に、各設定の詳細と動作に与える影響について説明します。
[読み込み]
メトリックを定義することの本質は、負荷を表現することです。 "負荷" とは、特定のノード上のサービス インスタンスまたはレプリカが使用する特定のメトリックの量のことです。 負荷はほぼどの時点でも構成できます。 次に例を示します。
- 負荷は、サービスの作成時に定義できます。 この種類の負荷構成は "既定の負荷" と呼ばれます。
- サービスの既定の負荷を含むメトリック情報は、サービスの作成後に更新できます。 このメトリックの更新は、"サービスを更新する" ことによって行われます。
- 特定のパーティションの負荷は、そのサービスの既定値にリセットできます。 このメトリックの更新は、"パーティションの負荷のリセット" と呼ばれます。
- 実行時にサービス オブジェクトごとに動的に負荷をレポートできます。 このメトリックの更新は、"負荷のレポート" と呼ばれます。
- パーティションのレプリカまたはインスタンスの負荷は、Fabric API 呼び出しを介して負荷値をレポートすることによって更新することもできます。 このメトリックの更新は、"パーティションの負荷のレポート" と呼ばれます。
サービスの有効期間中、これらの戦略のすべてを使用できます。
既定の負荷
"既定の負荷" とは、サービスの各サービス オブジェクト (ステートレス インスタンスまたはステートフル レプリカ) が使用するメトリックの量のことです。 Cluster Resource Manager は、動的な負荷レポートなどの他の情報を受信するまで、サービス オブジェクトの負荷としてこの数値を使用します。 単純なサービスでは、既定の負荷は静的な定義です。 既定の負荷が更新されることはなく、サービスの有効期間中、常に使用されます。 既定の負荷は、異なるワークロードに一定量のリソースが専用で割り当てられ、変化することがないという単純な容量計画シナリオでは十分に機能します。
注意
容量管理とクラスター内のノードの容量定義の詳細については、こちらの記事を参照してください。
Cluster Resource Manager は、ステートフル サービスがプライマリとセカンダリに対して異なる既定の負荷を指定することを許可します。 ステートレス サービスは、すべてのインスタンスに適用される 1 つの値のみを指定できます。 ステートフル サービスの場合、プライマリ レプリカとセカンダリ レプリカは、それぞれの役割に応じて異なる種類の操作を行うため、各レプリカの既定の負荷は通常は異なります。 たとえば、プライマリは、通常は読み取りと書き込みの両方に対応し、計算作業の大半を処理しますが、セカンダリはこれらを行いません。 通常、プライマリ レプリカの既定の負荷は、セカンダリ レプリカの既定の負荷よりも高くなります。 実際の値は、独自の測定値によって異なります。
動的な負荷
一定期間サービスを実行し、 監視したところ、次のことに気付いたとします。
- 指定のサービスの一部のパーティションやインスタンスが他よりも多くのリソースを使用している
- 一部のサービスの負荷が時間の経過とともに変化する
このような負荷の変動を引き起こす要因は数多く存在します。 たとえば、さまざまなサービスやパーティションが、要件が異なる複数のユーザーに割り当てられています。 サービスの作業量が 1 日の中で変化するるために、負荷が変動する可能性もあります。 理由に関係なく、通常は、既定で使用できる単一の数値はありません。 これは、クラスタを最大限活用したい場合は、特に当てはまります。 既定の負荷に対して選択した値はときに正しくありません。 正しくない既定の負荷を設定すると、Cluster Resource Manager によるリソースの割り当てが過剰または過少になります。 その結果、Cluster Resource Manager がクラスターは均衡がとれていると考えている場合でも、過剰または過少に使用されているノードが存在することになります。 既定の負荷は最初の配置で使用できる一定の情報を提供するため、有用ではありますが、実際のワークロードに完全に対応するわけではありません。 変化するリソース要件を正確に把握するために、Cluster Resource Manager では、各サービス オブジェクトが実行時の各自の負荷を更新できるようにしてます。 これを動的な負荷レポートと呼びます。
動的な負荷レポートを利用して、レプリカまたはインスタンスで有効期間内におけるメトリックの割り当てとレポートされる負荷を調整できます。 通常、コールド状態で何の動作もしていないサービス レプリカまたはインスタンスは、特定少数のメトリックを使用しているとレポートします。 負荷が高いレプリカやインスタンスは特定多数のメトリックを使用しているとレポートします。
レプリカまたはインスタンスごとの負荷のレポートによって、Cluster Resource Manager は、クラスター内の個々のサービス オブジェクトを再編成できます。 サービスを再編成することで、各サービスが確実に必要なリソースを取得できるようになります。 負荷の高いサービスは他の負荷の低いレプリカやインスタンスからリソースを効率的に「回収」します。
Reliable Services 内で負荷を動的にレポートするコードは次のようになります。
コード:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
サービスは、作成時に定義されたすべてのメトリックをレポートできます。 使用するように構成されていないメトリックの負荷をサービスがレポートした場合、Service Fabric はそのレポートを無視します。 有効なその他のメトリックが同時に報告された場合、それらのレポートは受け入れられます。 サービス コードは方法がわかっているすべてのメトリックを測定してレポートでき、オペレーターはサービス コードの変更なしで使用するメトリック構成を指定できます。
パーティションの負荷レポート
前のセクションでは、サービス レプリカまたはインスタンス レポートの負荷自体について説明しました。 Service Fabric API を使用して、パーティションのレプリカまたはインスタンスの負荷を動的にレポートするための、追加のオプションがあります。 パーティションの負荷をレポートするときに、複数のパーティションを一度にレポートすることができます。
これらのレポートは、レプリカまたはインスタンス自体からの負荷レポートとまったく同じ方法で使用されます。 報告された値は、レプリカまたはインスタンスによって、またはパーティションの新しい負荷値を報告することによって、新しい負荷値が報告されるまで有効になります。
この API を使用すると、複数の方法でクラスターの負荷を更新することができます。
- ステートフル サービス パーティションは、プライマリ レプリカの負荷を更新できます。
- ステートレスとステートフルのどちらのサービスでも、そのすべてのセカンダリ レプリカまたはインスタンスの負荷を更新できます。
- ステートレスとステートフルのどちらのサービスでも、ノード上の特定のレプリカまたはインスタンスの負荷を更新できます。
また、パーティションごとにこれらの更新を同時に組み合わせることもできます。 特定のパーティションに対する負荷の更新の組み合わせは、オブジェクト PartitionMetricLoadDescription を使用して指定する必要があります。これには、次の例に示すように、対応する負荷の更新のリストを含めることができます。 負荷の更新は、オブジェクト MetricLoadDescription によって表されます。これには、メトリック名で指定された、メトリックの現在または予測の負荷値を含めることができます。
注意
予測メトリック負荷値は現在プレビュー機能です。 予測負荷値を Service Fabric 側で報告して使用することができますが、その機能は現在有効にされていません。
1 回の API 呼び出しで複数のパーティションの負荷を更新できます。この場合、出力にはパーティションごとの応答が含まれます。 何らかの理由でパーティションの更新が正常に適用されない場合、そのパーティションの更新はスキップされ、対象パーティションの対応するエラー コードが提供されます。
- PartitionNotFound - 指定されたパーティション ID が存在しません。
- ReconfigurationPending - パーティションは現在再構成されています。
- InvalidForStatelessServices - ステートレス サービスに属しているパーティションのプライマリ レプリカの負荷を変更しようとしました。
- ReplicaDoesNotExist - 指定されたノードにセカンダリ レプリカまたはインスタンスが存在しません。
- InvalidOperation - システム アプリケーションに属しているパーティションの負荷を更新する、または予測された負荷の更新が有効になっていないという 2 つのケースで発生する可能性があります。
これらのエラーのいくつかが返された場合は、特定のパーティションの入力を更新して、その更新を再試行することができます。
コード:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
この例では、パーティション 53df3d7f-5471-403b-b736-bde6ad584f42 の最後に報告された負荷の更新を実行します。 メトリック CustomMetricName0 のプライマリ レプリカの負荷は、値 100 で更新されます。 同時に、ノード NodeName0 にある特定のセカンダリ レプリカに対して同じメトリックの負荷が、値 200 で更新されます。
サービスのメトリック構成の更新
サービスがライブ状態にあるときに、サービスに関連付けられているメトリックとそれらのメトリックのプロパティの一覧を動的に更新できます。 これにより、実験が可能になり、柔軟性を獲得できます。 これが役に立ついくつかの例を次に示します。
- レポートのバグが多い特定のサービスのメトリックを無効化する
- 目的の動作に基づいてメトリックの重みを再構成する
- コードがデプロイされ、他のメカニズムによって検証された後でのみ、新しいメトリックを有効にする
- 観察された動作と消費量に基づいてサービスの既定の負荷を変更する
メトリック構成を変更するための主要な API は、C# の場合は FabricClient.ServiceManagementClient.UpdateServiceAsync、PowerShell の場合は Update-ServiceFabricService です。 これらの API で指定したすべての情報は、サービスの既存のメトリック情報をすぐに置き換えます。
既定の負荷値と動的負荷レポートの混在
同じサービスに対して、既定の負荷と動的な負荷を使用できます。 サービスが既定の負荷と動的な負荷レポートの両方を使用する場合、動的なレポートが現れるまで既定の負荷が推定値として使用されます。 既定の負荷は Resource Manager に処理の根拠を提供するため、有用です。 既定の負荷により、Cluster Resource Manager は、サービス オブジェクトが作成されたときにそれを適切な場所に配置できます。 既定の負荷の情報が提供されない場合、サービスの配置は、事実上ランダムに行われます。 その後、負荷のレポートが到着すると、最初のランダムな配置は多くの場合間違っているため、Cluster Resource Manager はサービスを移動する必要があります。
前の例を使用して、カスタム レポートと動的な負荷レポートを追加するとどうなるかを見てみましょう。 この例では、メトリックの例として "MemoryInMb" を使用します。
Note
メモリは、Service Fabric がリソース管理を実行できるシステム メトリックの 1 つであり、自分でレポートするのは通常は困難です。 メモリの消費量に関して自分でレポートすることが実際に期待されているわけではありません。ここでは、Cluster Resource Manager の機能を説明するためにメモリを使用しています。
最初に次のコマンドを使用してステートフル サービスを作成していたとします。
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
繰り返しますが、この構文は ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad") です。
考えられるクラスター レイアウトの 1 つは、次のようなものになります。
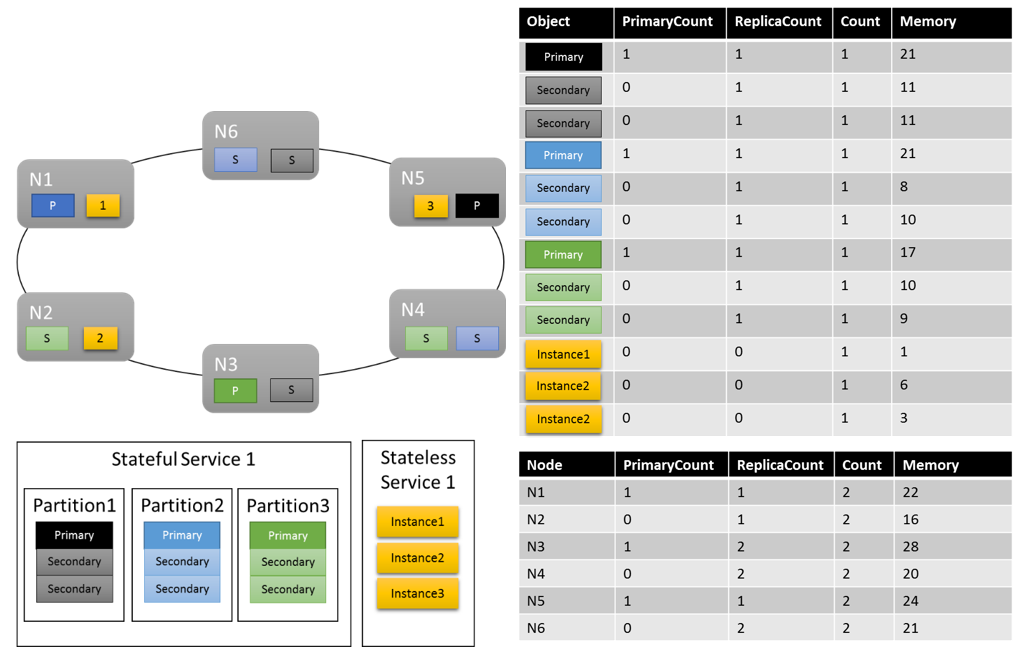
注目すべき点がいくつかあります。
- パーティション内のセカンダリ レプリカはそれぞれが独自の負荷を持つことができます。
- 全体としてメトリックの均衡はとれているように見えます。 メモリについては、最大負荷と最小負荷の比率は 1.75 (負荷が最も高いノードは N3、最も低いノードは N2 で、28/16 = 1.75) です。
さらに説明が必要な点がいくつかあります。
- 1\.75 という比率が妥当であるかどうかを、何を根拠に決定するのか。 Cluster Resource Manager はそれが十分であるか、もっと調整が必要であるかをどのように判断するのか。
- 負荷分散はいつ実行されるのか。
- Memory の重みが "High" であるとは、どのような意味があるのか。
メトリックの重み
異なるサービス間で同じメトリックを追跡することが重要です。 包括的な視点は、どうすれば Cluster Resource Manager がクラスター内の使用量を追跡し、ノード間で使用量の均衡をとり、ノードが容量を超えないことを保証できるかということです。 ただし、同じメトリックの重要性はサービスによって異なるため、サービスによって見方が異なる場合があります。 また、クラスターのメトリックやサービスの数が多い場合、すべてのメトリックについて完璧に均衡のとれたソリューションは存在しないことがあります。 Cluster Resource Manager はこのような状況をどのように処理するのでしょうか。
メトリックの重みは、Cluster Resource Manager でクラスターの均衡をとる方法を決定するときに、完璧な答えが存在しない場合の判断材料となります。 また、Cluster Resource Manager はメトリックの重みを使用して、サービスごとに均衡をとります。 メトリックには、Zero、Low、Medium、High という4 種類の重みレベルを設定できます。 重み Zero のメトリックは均衡がとれているかどうかを判断するときにはまったく考慮されません。 ただし、その負荷は、容量管理の際に考慮されます。 重み Zero のメトリックは、サービスの動作とパフォーマンスの監視の一部としても有用であり、その目的のために頻繁に使用されます。 サービスの監視と診断を行うためのメトリックの使用の詳細については、こちらの記事を参照してください。
メトリックの重みがクラスター内で異なることの実際の影響は、Cluster Resource Manager が異なるソリューションを生成することです。 メトリックの重みは、あるメトリックが他よりも重要なことを Cluster Resource Manager に伝えます。 完璧な解決策がない場合、Cluster Resource Manager はより高い重みのメトリックの均衡をとります。 サービスが特定のメトリックを重要でないと考えている場合は、そのメトリックを使用すると不均衡の原因なる可能性があることに気付くことができます。 これにより、別のサービスにとって重要な何らかのメトリックが均等に分散されるようになります。
それでは、いくつかの負荷レポートの例を使用して、メトリックの重みが変わるとクラスター内の割り当てがどのように変化するか見てみましょう。 この例では、メトリックの相対的な重みを切り替えると、Cluster Resource Manager が異なるサービスの配置を作成することがわかります。
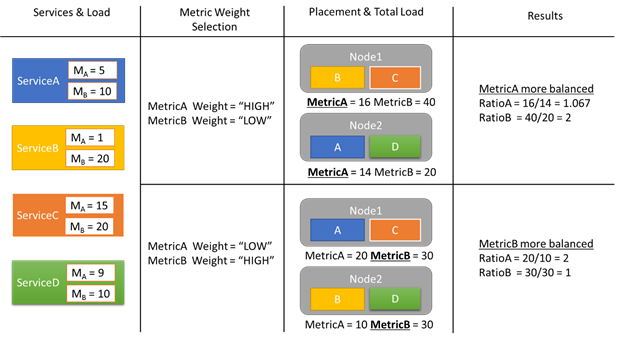
この例では、4 つの異なるサービスがあり、すべてのサービスが MetricA と MetricB という 2 つの異なるメトリックの異なる値をレポートします。 1 番目のケースでは、すべてのサービスが MetricA を最も重要なメトリック (重み = High) と定義し、MetricB を重要でないメトリック (重み = Low) と定義しています。 その結果、Cluster Resource Manager が MetricB よりも MetricA の均衡がとれるようにサービスを配置していることがわかります。 "均衡がとれる" とは、MetricA の標準偏差が MetricB のそれよりも小さいことを意味します。 2 番目のケースでは、メトリックの重みが逆になっています。 その結果、Cluster Resource Manager は サービス A とサービス B を入れ替えて、MetricA よりも MetricB の均衡がとれれた配置を見つけ出すことがわかります。
Note
メトリックの重みは、Cluster Resource Manager がどのように均衡をとるかを決定しますが、均衡化がいつ発生するかは決定しません。 均衡化の詳細については、こちらの記事を参照してください。
メトリックの重み
ServiceA が MetricA を重み High として定義し、ServiceB が MetricA の重みを Low または Zero に設定したとしましょう。 最終的に使用される実際の重みはどうなるでしょうか。
すべてのメトリックで追跡される複数の重みがあります。 最初の重みは、サービスの作成時にメトリックに対して定義された重みです。 もう 1 つの重みはグローバルな重みであり、これは自動的に計算されます。 Cluster Resource Manager はこれら両方の重みを使用してソリューションのスコアを計算します。 両方の重みを考慮することが重要です。 これにより、Cluster Resource Manager は、独自の優先順位に従って各サービスの均衡をとることができ、クラスター全体に適切に割り当てられていることも保証できます。
Cluster Resource Manager がグローバルとローカルのどちらかの均衡を考慮しなかった場合、どうなるでしょうか。 グローバルに均衡のとれたソリューションを構築することは簡単ですが、個々のサービスに対するリソースの分散は不均衡という結果になります。 次の例で、既定のメトリックのみを使用して構成されたサービスで、グローバルな均衡のみが考慮された場合はどうなるかを見てみましょう。
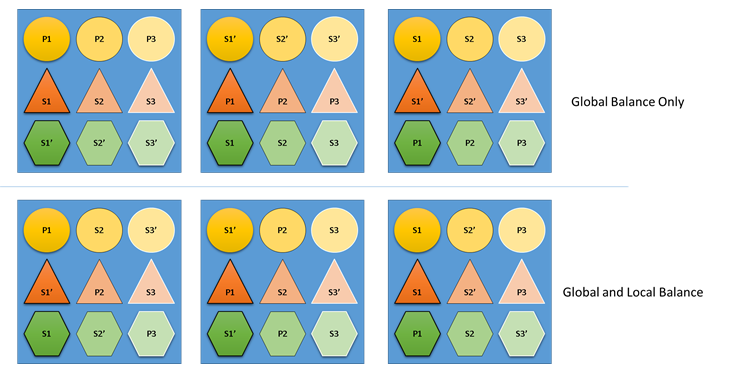
上の方の例は、グローバルな均衡に基づいています。クラスター全体は実際に均衡がとれています。 すべてのノードに同じ数のプライマリが含まれ、レプリカの合計数も同じです。 ただし、この割り当ての実際の影響を見てみると、それほど良いとは言えません。ノードが失われると、その中のプライマリもすべて失われるため、特定のワークロードに偏りが生じます。 たとえば、1 番目のノードで障害が発生すると、円のサービスの 3 つの異なるパーティションに対応する 3 つのプライマリが同時に失われます。 逆に、三角形サービスと六角形サービスでは、パーティションでレプリカが失われます。 これにより中断が発生することはなく、ダウンしたレプリカを回復すること以外は必要ありません。
下の方の例では、Cluster Resource Manager がグローバルのバランスとサービス単位のバランスの両方を考慮してレプリカを分散しています。 ソリューションのスコアを計算するとき、ほとんどの重みはグローバル ソリューションに充てられ、(構成可能な) 一部は個々のサービスに充てられます。 メトリックのグローバルな均衡は、各サービスのメトリックの重みの平均値に基づいて算出されます。 各サービスは、独自に定義されたメトリックの重みに従って均衡がとられます。 これにより、各サービスは、独自のニーズに従って、サービス内で均衡がとられます。 その結果、同じ 1 番目のノードで障害が発生した場合でも、障害はすべてのサービスのすべてのパーティションに分散され、 各サービスへの影響が同じになります。
次のステップ
- サービスの構成の詳細については、サービスの構成(service-fabric-cluster-resource-manager-configure-services.md) に関する記事を参照してください。
- 最適化メトリックの定義は、負荷を分散するのではなく、ノードで統合する方法の 1 つです。最適化を構成する方法については、 この記事
- クラスター リソース マネージャーでクラスターの負荷を管理し、分散するしくみについては、 負荷分散
- 最初から開始して、 Service Fabric クラスター リソース マネージャーの概要を確認するにはこちらを参照してください
- 移動コストは、特定のサービスが他のサービスよりも高額になっていることをクラスター リソース マネージャーに警告する信号の 1 つです。 移動コストの詳細については、 この記事