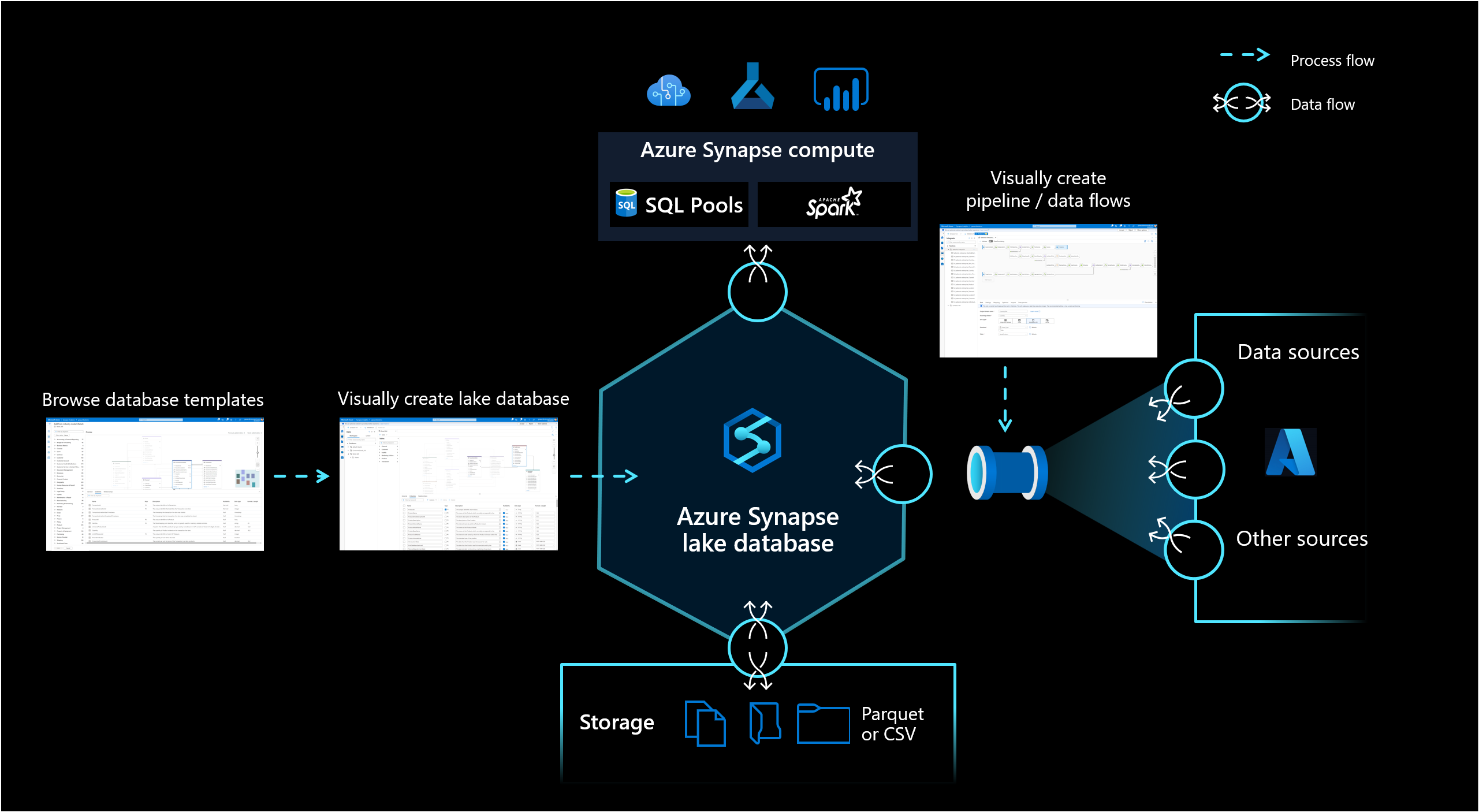
Lake データベース
Azure Synapse Analytics の Lake データベースを使用すると、お客様は、データベースのデザイン、格納されているデータに関するメタ情報、データを格納する方法と場所を記述できる可能性をまとめることができます。 レイク データベースでは、データがどのように構造化されているかを理解するのが難しいという今日のデータ レイクの課題に対処しています。
データベース デザイナー
Synapse Studio の新しいデータベース デザイナーを使用すると、自分の Lake データベース用にデータ モデルを作成し、さらに情報を追加することができます。 どのエンティティと属性も、モデルに関する詳細情報を提供するために記述することができます。これには、エンティティだけでなく、リレーションシップも含まれます。 特に、モデル リレーションシップの欠如は、データレイクの操作にとって課題でした。 この課題は、データベースで使用できるがレイクでは利用できない手段を提供する統合されたデザイナーによって解決されました。 また、説明と場合によってはデモ値をモデルに追加する機能により、今後この機能を操作するユーザーは、必要な場所に情報を格納してデータについて理解を深めることもできます。
Note
レイク データベース内のメタデータの最大サイズは 10 GB です。 サイズが 10 GB を超えるモデルを公開または更新しようとすると失敗します。 この問題を解決するには、テーブルと列を削除してモデルのサイズを小さくします。 この制限を回避するには、大規模なモデルを複数のレイク データベースに分割することを検討してください。
データ ストレージ
Lake データベースでは、Azure ストレージ アカウントのデータ レイクを使用して、データベースのデータを格納します。 データは、Parquet、Delta、または CSV 形式に格納することができ、さまざまな設定を使用してストレージを最適化できます。 各 Lake データベースは、リンク サービスを使用して、ルート データ フォルダーの場所を定義します。 エンティティごとに、既定では、データ レイク上のこのデータベース フォルダー内に個別のフォルダーが作成されます。 既定では、Lake データベース内のすべてのテーブルで同じ形式が使用されますが、データの形式と場所は、要求された場合、エンティティごとに変更できます。
注意
Lake データベースを公開しても、Spark または SQL でデータのクエリを実行するために必要な基礎の構造またはスキーマは作成されません。 公開後に、パイプラインを使って Lake データベースにデータを読み込み、クエリを開始してください。
現時点では、レイク データベースの Delta 形式のサポートは、Synapse Studio ではサポートされていません。
ストレージと Synapse の間のレイク データベース オブジェクトの同期は一方向です。 Synapse Studio のデータベース デザイナーを使用し、レイク データベース オブジェクトの作成またはスキーマ変更を必ず実行してください。 このような変更を代わりに Spark から行うか、ストレージで直接行う場合、レイク データベースの定義が同期されなくなります。同期されないと、データベース デザイナーに古いレイク データベースの定義が表示されることがあります。 レイク データベースの再び同期させるには、このような変更をデータベース デザイナーで複製し、発行する必要があります。
データベース コンピューティング
Lake データベースは、Synapse SQL サーバーレス SQL プールと Apache Spark で公開されており、ストレージをコンピューティングから切り離す機能をユーザーに提供しています。 レイク データベースに関連付けられているメタデータを使用すると、さまざまなコンピューティング エンジンでは容易に、統合されたエクスペリエンスを提供するだけでなく、本来データ レイクでサポートされていなかった追加情報 (リレーションシップなど) も使用できるようになります。
関連するコンテンツ
次のリンクを使用して、データベース デザイナーの機能の詳細を引き続き確認します。