Netezza 移行のセキュリティ、アクセス、操作
この記事は、Netezza から Azure Synapse Analytics に移行する方法に関するガイダンスを提供する 7 つのパートから成るシリーズのパート 3 です。 この記事では、セキュリティ アクセス操作のベスト プラクティスに焦点をあてます。
セキュリティに関する考慮事項
この記事では、既存の Netezza レガシ環境の接続方法について説明し、どのようにすると、それらの接続方法を、リスクとユーザーへの影響を最小限に抑えて Azure Synapse Analytics に移行できるかを説明します。
この記事では、接続とユーザー、ロール、およびアクセス許可の構造については、既存の方法をそのまま移行する必要があると想定しています。 そうでない場合は、Azure portal を使用して、新しいセキュリティ体制を作成し、管理します。
Azure Synapse のセキュリティ オプションの詳細については、セキュリティに関するホワイト ペーパーを参照してください。
接続と認証
ヒント
Netezza と Azure Synapse の両方の認証は、"データベース内で"、または外部メソッドを通じて行うことができます。
Netezza の認可オプション
IBM Netezza システムでは、Netezza データベース ユーザー向けにいくつかの認証方法が用意されています。
ローカル認証: Netezza 管理者は、
CREATE USERコマンドを使用するか、Netezza 管理インターフェイスを通じて、データベース ユーザーとそのパスワードを定義します。 ローカル認証では、Netezza システムを使用してデータベース アカウントとパスワードを管理し、システムに対してデータベース ユーザーを追加および削除します。 この方法が既定の認証方法です。LDAP 認証: LDAP ネーム サーバーを使用して、データベース ユーザーの認証、パスワードの管理、データベース アカウントのアクティブ化と非アクティブ化を行います。 Netezza システムでは、ホットプラグ可能な認証モジュール (PAM) を使用して LDAP ネーム サーバー上のユーザーを認証します。 Microsoft Active Directory は LDAP プロトコルに準拠しているため、LDAP 認証の目的で LDAP サーバーのように扱えます。
Kerberos 認証: Kerberos ディストリビューション サーバーを使用して、データベース ユーザーの認証、パスワードの管理、データベース アカウントのアクティブ化と非アクティブ化を行います。
認証は、システム全体の設定です。 ユーザーは、ローカルで認証するか、方法として LDAP または Kerberos を使用して認証する必要があります。 LDAP または Kerberos の認証を選択する場合は、ユーザーごとにローカル認証を行うユーザーを作成します。 ユーザーを認証するために、LDAP と Kerberos を同時に使用することはできません。 Netezza ホストで LDAP または Kerberos の認証がサポートされるのは、ホストのオペレーティング システムに対してではなく、データベース ユーザーのログインに対してのみです。
Azure Synapse の認可オプション
Azure Synapse では、接続と認可について、2 つの基本的オプションがサポートされています。
SQL 認証: SQL 認証は、データベース識別子、ユーザー ID、パスワード、その他の省略可能なが含まれるデータベース接続を介して行われます。 これは、機能的には Netezza のローカル接続と同等です。
Microsoft Entra 認証: Microsoft Entra 認証を使用すると、データベース ユーザーの ID やその他の Microsoft サービスを一元管理できます。 ID の一元管理では、1 か所で Azure Synapse ユーザーを管理できるようになるため、アクセス許可の管理が容易になります。 Microsoft Entra ID では、LDAP および Kerberos サービスへの接続もサポートできます。たとえば、データベースの移行後に既存の LDAP ディレクトリを維持する場合は、Microsoft Entra ID を使用してそのディレクトリに接続できます。
ユーザー、ロール、アクセス許可
概要
ヒント
移行プロジェクトを成功させるには、高レベルの計画が極めて重要です。
Netezza と Azure Synapse のどちらでも、ユーザー、ロール (Netezza でのグループ)、アクセス許可を組み合わせてデータベースのアクセス制御を実装します。 両方で、標準 SQL の CREATE USER および CREATE ROLE/GROUP ステートメントを使用してユーザーとロールを定義し、GRANT および REVOKE ステートメントを使用してそれらのユーザーやロールに対するアクセス許可の割り当てまたは削除を行います。
ヒント
所要時間とエラーの範囲を減らすため、移行プロセスを自動化することをお勧めします。
2 つのデータベースは概念的に類似していて、既存のユーザー ID、グループ、アクセス許可の移行をある程度自動化できる可能性があります。 そのようなデータを移行するには、Netezza システム カタログのテーブルから既存のレガシ ユーザーとグループの情報を抽出し、それらに合致する同じユーザー/ロール階層を再作成するために Azure Synapse で実行する、同等の CREATE USER ステートメントと CREATE ROLE ステートメントを生成します。
データの抽出後、Netezza システム カタログのテーブルを使用して同等の GRANT ステートメントを生成し、(同等のアクセス許可が存在する場所に) アクセス許可を割り当てます。 次の図は、既存のメタデータを使用して必要な SQL を生成する方法を示しています。
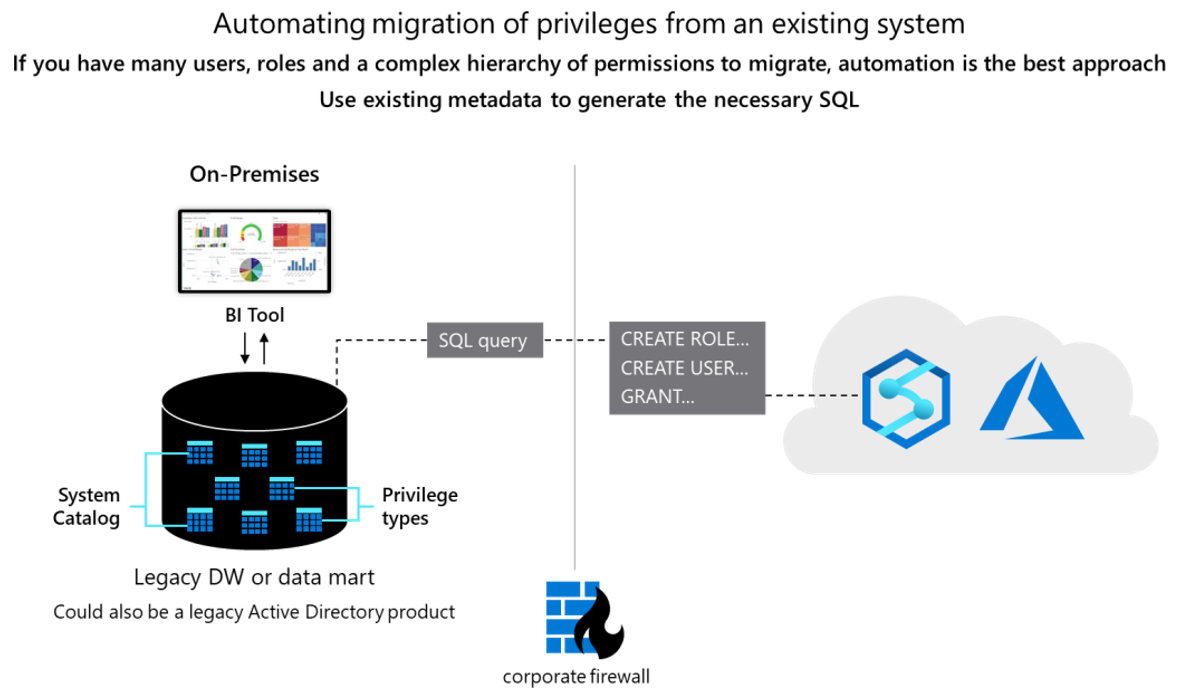
詳細については、以降のセクションを参照してください。
ユーザーと役割
ヒント
データ ウェアハウスを移行するには、テーブル、ビュー、SQL ステートメント以上のものが必要です。
Netezza システムの現在のユーザーとグループに関する情報は、システム・カタログ・ビューの _v_users と _v_groupusers に保持されています。 ユーザー特権をリスト表示するには、nzsql ユーティリティや、Netezza Performance、NzAdmin、Netezza Utility スクリプトなどのツールを使用します。 たとえば、nzsql の dpu コマンドと dpgu コマンドを使用して、ユーザーやグループをアクセス許可と共に表示します。
ユーティリティ スクリプトの nz_get_users および nz_get_user_groups を使用または編集して、同じ情報を必要な形式で取得します。
システム カタログ ビューに直接クエリを実行し (ユーザーがそれらのビューに対する SELECT アクセスを持っている場合)、システム内で定義されているユーザーとロールの現在の一覧を取得します。 ユーザー、グループ、またはユーザーとそれらのユーザーに関連付けられているグループを一覧表示する例を参照してください。
-- List of users
SELECT USERNAME FROM _V_USER;
--List of groups
SELECT DISTINCT(GROUPNAME) FROM _V_USERGROUPS;
--List of users and their associated groups
SELECT USERNAME, GROUPNAME FROM _V_GROUPUSERS;
SELECT ステートメント内に適切なテキストをリテラルとして含めることで SELECT ステートメントの例に変更を加え、一連の CREATE USER および CREATE GROUP ステートメントである結果セットを生成します。
既存のパスワードを取得する方法がないため、Azure Synapse で新しい初期パスワードを割り当てるためのスキームを実装する必要があります。
アクセス許可
ヒント
DML や DDL などの基本的なデータベース操作のためには、同等の Azure Synapse アクセス許可が存在します。
Netezza システムでは、システム テーブル _t_usrobj_priv で、ユーザーとロールのアクセス権を保持します。 これらのテーブルにクエリを実行して (ユーザーがそれらのテーブルに対する SELECT アクセスを持っている場合)、システム内で定義されているアクセス権の現在の一覧を取得します。
Netezza では、個々のアクセス許可は、フィールド特権、すなわち g_privileges 内の個々のビットとして表されます。 ユーザー グループのアクセス許可での SQL ステートメントの例を参照してください
ユーザーとグループの現在の特権をレプリケートする GRANT コマンドが含まれる DDL スクリプトを取得する最も簡単な方法は、適切な Netezza ユーティリティ スクリプトを使用することです。
--List of group privileges
nz_ddl_grant_group -usrobj dbname > output_file_dbname;
--List of user privileges
nz_ddl_grant_user -usrobj dbname > output_file_dbname;
出力ファイルに変更を加えて、Azure Synapse 用の一連のGRANT ステートメントであるスクリプトを生成できます。
Netezza では、アクセス権の 2 つのクラスとして、Admin と Object がサポートされています。 Netezza でのアクセス権と、Azure Synapse でのそれらと同等のアクセス権の一覧については、次の表を参照してください。
| Admin 特権 | 説明 | Azure Synapse での同等物 |
|---|---|---|
| Backup | ユーザーにバックアップの作成を許可します。 ユーザーはバックアップを実行できます。 ユーザーはコマンド nzbackup を実行できます。 |
1 |
| [Create] Aggregate | ユーザーにユーザー定義集計 (UDA) の作成を許可します。 既存の UDA を操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE FUNCTION 3 |
| [Create] Database | ユーザーにデータベースの作成を許可します。 既存のデータベースを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE DATABASE |
| [Create] External Table | ユーザーに外部テーブルの作成を許可します。 既存のテーブルを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE TABLE |
| [Create] Function | ユーザーにユーザー定義関数 (UDF) の作成を許可します。 既存の UDF を操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE FUNCTION |
| [Create] Group | ユーザーにグループの作成を許可します。 既存のグループを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE ROLE |
| [Create] Index | システムでの使用専用です。 ユーザーがインデックスを作成することはできません。 | CREATE INDEX |
| [Create] Library | ユーザーに共有ライブラリの作成を許可します。 既存の共有ライブラリを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | 1 |
| [Create] Materialized View | ユーザーに具体化されたビューの作成を許可します。 | CREATE VIEW |
| [Create] Procedure | ユーザーにストアド プロシージャの作成を許可します。 既存のストアド プロシージャを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE PROCEDURE |
| [Create] Schema | ユーザーにスキーマの作成を許可します。 既存のスキーマを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE SCHEMA |
| [Create] Sequence | ユーザーにデータベース シーケンスの作成を許可します。 | 1 |
| [Create] Synonym | ユーザーにシノニムの作成を許可します。 | CREATE SYNONYM |
| [Create] Table | ユーザーにテーブルの作成を許可します。 既存のテーブルを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE TABLE |
| [Create] Temp Table | ユーザーに一時テーブルの作成を許可します。 既存のテーブルを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE TABLE |
| [Create] User | ユーザーにユーザーの作成を許可します。 既存のユーザーを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE USER |
| [Create] View | ユーザーにビューの作成を許可します。 既存のビューを操作するためのアクセス許可は、オブジェクトの特権によって制御されます。 | CREATE VIEW |
| [Manage Hardware | ユーザーに、次のハードウェア関連の操作を許可します: ハードウェアの状態の表示、SPU の管理、トポロジとミラーリングの管理、診断テストの実行。 ユーザーは、nzhw コマンドと nzds コマンドを実行できます。 | 4 |
| [Manage Security | ユーザーに、次のような高度なセキュリティ オプションに関連するコマンドと操作の実行を許可します: 履歴データベースの管理と構成、複数レベルのセキュリティ オブジェクトの管理、ユーザーとグループのセキュリティの指定、監査データのデジタル署名のためのデータベース キー ストアとキーとキー ストアの管理。 | 4 |
| [Manage System | ユーザーが次の管理操作を実行することを許可します: システムの起動/停止/一時停止/再開、セッションの中止、配布マップの表示、システム統計、ログ。 ユーザーは次のコマンドを使用できます: nzsystem、nzstate、nzstats、nzsession。 | 4 |
| 復元 | ユーザーにシステムの復元を許可します。 ユーザーは nzrestore コマンドを実行できます。 | 2 |
| Unfence | ユーザーに、ユーザー定義の関数または集計を作成または変更し、非フェンス モードで実行することを許可します。 | 1 |
| Object 特権 Abort | 説明 | Azure Synapse での同等物 |
|---|---|---|
| 中止 | ユーザーに、セッションを中止することを許可します。 グループとユーザーに適用されます。 | KILL DATABASE CONNECTION |
| Alter | ユーザーにオブジェクト属性の変更を許可します。 すべてのオブジェクトに適用されます。 | ALTER |
| 削除 | ユーザーにテーブル行の削除を許可します。 テーブルにのみ適用されます。 | DELETE |
| Drop | ユーザーにオブジェクトの削除を許可します。 全種類のオブジェクトに適用されます。 | DROP |
| 実行 | ユーザーに、ユーザー定義関数、ユーザー定義集計、ストアド プロシージャの実行を許可します。 | EXECUTE |
| GenStats | ユーザーに、テーブルまたはデータベースに関する統計を生成することを許可します。 ユーザーは GENERATE STATISTICS コマンドを実行できます。 | 2 |
| Groom | ユーザーに、削除されたり古くなったりした行のディスク領域を解放すること、整理キーによってテーブルを再編成すること、複数のバージョンが格納されているテーブルのデータを移行することを許可します。 | 2 |
| 挿入 | ユーザーにテーブルへの行の挿入を許可します。 テーブルにのみ適用されます。 | INSERT |
| List | ユーザーに、リストまたは別の方法でのオブジェクト名の表示を許可します。 すべてのオブジェクトに適用されます。 | リスト |
| Select | ユーザーにテーブル内の行の選択 (またはクエリ) を許可します。 テーブルとビューに適用されます。 | SELECT |
| Truncate | ユーザーにテーブルからのすべての行の削除を許可します。 テーブルにのみ適用されます。 | TRUNCATE |
| 更新 | ユーザーにテーブル行の変更を許可します。 テーブルにのみ適用されます。 | UPDATE |
表の注記:
Azure Synapse に、この関数と直接的に同等である関数はありません。
これらの Netezza 関数は Azure Synapse で自動的に処理されます。
Azure Synapse の
CREATE FUNCTION機能には、Netezza 集計機能が組み込まれています。これらの機能は、Azure Synapse のシステムまたは Azure portal によって自動的に管理されます。 運用上の考慮事項については、次のセクションを参照してください。
Azure Synapse Analytics のセキュリティ アクセス許可に関するページを参照してください。
操作上の考慮事項
ヒント
データ ウェアハウスを効率的に運用し続けるには、運用タスクが必要です。
このセクションでは、ユーザーへのリスクと影響を最小限に抑えて、Netezza の一般的な運用タスクを Azure Synapse に実装する方法について説明します。
すべてのデータ ウェアハウス製品と同様に、いったん運用環境に移行すると、システムを効率的に実行し続け、監視と監査に向けてデータを提供するために、継続的な管理タスクが必要となります。 データのバックアップ/復元と同様に、将来の成長のためのリソース使用率と容量計画もこのカテゴリに分類されます。
Netezza 管理タスクは、通常、2 つのカテゴリに分類されます。
システム管理。ハードウェア、構成設定、システムの状態、アクセス、ディスク領域、使用状況、アップグレードなどのタスクを管理することです。
データベース管理。ユーザー データベースとその内容の管理、データの読み込み、データのバックアップ、データの復元、データとアクセス許可に対するアクセスの制御を行うことです。
IBM Netezza には、システムとデータベースに関するさまざまな管理タスクを実行するために使用できる方法やインターフェースがいくつか用意されています。
Netezza コマンド (
nz*コマンド) は、Netezza ホスト上の/nz/kit/binディレクトリにインストールされます。 多くのnz*コマンドの場合、これらのコマンドにアクセスして実行するためには、Netezza システムにサインインできる必要があります。 ほとんどの場合、ユーザーは既定のnzユーザー アカウントとしてサインインしますが、システムにその他の Linux ユーザー アカウントを作成できます。 一部のコマンドでは、タスクを実行するためのアクセス許可を持っていることを確認するため、データベース ユーザー アカウント、パスワード、データベースを指定する必要があります。Netezza CLI クライアント キットには、Windows と UNIX のクライアント システムから実行できる
nz*コマンドのサブセットがパッケージ化されています。 クライアント コマンドでも、タスク実行用のデータベース管理アクセス許可とオブジェクト アクセス許可を持っていることを確認するため、データベース ユーザー アカウント、パスワード、データベースの指定が求められる場合があります。SQL コマンドでは、SQL データベース セッション内での管理タスクとクエリがサポートされます。 SQL コマンドは、Netezza nzsql コマンド インタープリターから、または ODBC、JDBC、OLE DB プロバイダーなどの SQL API を通じて実行できます。 SQL コマンドを実行するには、実行するクエリとタスクにとって適切なアクセス許可を持っているデータベース ユーザー アカウントが必要です。
NzAdmin ツールは、Netezza システムを管理するために Windows クライアント ワークステーションで実行される Netezza インターフェイスです。
さまざまなデータ ウェアハウスの管理と運用のタスクは、概念的には類似していますが、個々の実装は異なっている場合があります。 一般に、Azure Synapse などの最新のクラウドベースの製品には (Netezza などの従来のデータ ウェアハウスでの、より "手作業が多い" アプローチとは対照的に)、自動化が進んだ "システムによる管理" のアプローチが組み込まれている傾向があります。
以降のセクションでは、さまざまな運用タスクについて、Netezza と Azure Synapse のオプションを比較します。
ハウスキープ処理タスク
ヒント
ハウスキープ処理タスクでは、運用ウェアハウスが効率的に動作している状態を保ち、ストレージなどのリソースの使用を最適化します。
従来のデータ ウェアハウス環境では、ほとんどの場合、通常の "ハウスキープ処理" タスクには多くの時間がかかります。 効率向上のため、更新や削除が行われた古いバージョンの行を削除したり、データ、ログ ファイル、インデックス ブロックを再編成したりして、ディスクのストレージ領域を解放します (Netezza では GROOM と VACUUM)。 クエリ実行プランの基になる最新データをクエリ オプティマイザーに提供するための、データの一括取り込みの後に必要となる統計の収集も、多くの時間を要することがあるタスクです。
Netezza では、以下のように統計を収集することが推奨されています。
データが入っていないテーブルの統計を収集し、内部処理で使用される間隔ヒストグラムを設定します。 この初期収集によって、後続の統計収集がより高速になります。 データが追加された後は必ず統計を再収集してください。
新しく設定されたテーブルのプロトタイプ フェーズ統計を収集します。
テーブルまたはパーティションにかなりの割合で変更が加えられた後 (およそ 10% の行)、運用フェーズの統計を収集します。 日付やタイムスタンプなどの一意でない値の量が多い場合は、7% で再収集すると有益である可能性があります。
ユーザーを作成し、実際のクエリの読み込みをデータベースに適用した後に、運用フェーズの統計を収集します (最大約 3 か月のクエリの実行)。
CPU 使用率が低い期間中のアップグレードまたは移行後、最初の数週間のうちに統計を収集します。
Netezza Database では、自動的に、または特定の機能が有効になった後にデータを蓄積する多くのログ テーブルが、データ辞書内に格納されます。 ログ データは時間の経過とともに増加するため、古い情報を消去して、永続的領域を使い切らないようにします。 これらのログを使用可能に保つメンテナンスを自動化するオプションが用意されています。
ヒント
ハウスキープ処理タスクは、Azure で自動化して監視します。
Azure Synapse には、必要に応じて使用できるように統計を自動的に作成するオプションがあります。 インデックスとデータ ブロックの最適化を、手動で、スケジュールに基づいて、または自動的に実行します。 ネイティブの組み込み Azure 機能を利用すると、移行の業務で必要な労力を削減できます。
監視と監査
ヒント
Netezza Performance Portal は、Netezza システムの監視とログ記録の推奨される方法です。
Netezza には、アクティビティ、パフォーマンス、キュー、リソース使用率など、1 つ以上の Netezza システムのさまざまな側面を監視するために、Netezza Performance Portal が用意されています。 Netezza Performance Portal は対話型の GUI で、ユーザーはこれを使用して、任意のグラフの低レベルの詳細までドリルダウンできます。
ヒント
Azure portal には、Azure のデータとプロセスすべてについて監視と監査のタスクを管理する GUI が用意されています。
同じように、Azure portal 内にある Azure Synapse のリッチな監視エクスペリエンスでは、データ ウェアハウスのワークロードに関する分析情報が表示されます。 データ ウェアハウスを監視するときの推奨されるツールである Azure portal では、構成可能なリテンション期間、アラート、推奨事項、およびメトリックとログのカスタマイズ可能なグラフとダッシュボードが提供されます。
ポータルでは、Operations Management Suite (OMS) や Azure Monitor (ログ) などの他の Azure 監視サービスと統合して、お使いのデータ ウェアハウスだけでなく、統合された監視エクスペリエンスに対する Azure 分析プラットフォーム全体も含む、総合的な監視エクスペリエンスを提供することもできます。
ヒント
低レベルのシステム全体が対象のメトリックは、Azure Synapse で自動的にログ記録されます。
Azure Synapse 用のリソース使用率の統計は、システム内で自動的にログ記録されます。 各クエリについてのメトリックには、CPU、メモリ、キャッシュ、I/O、一時ワークスペースの使用状況の統計情報のほか、失敗した接続試行数などの接続情報が含まれます。
Azure Synapse には、動的管理ビュー (DMV) のセットが用意されています。 これらのビューは、アクティブのトラブルシューティングを行うときと、ワークロードでパフォーマンスのボトルネックを特定するときに役に立ちます。
詳細については、Azure Synapse の操作と管理のオプションに関するページを参照してください。
高可用性 (HA) とディザスター リカバリー (DR)
Netezza アプライアンスは、冗長性のあるフォールト トレラント システムであり、Netezza システムには、高可用性とディザスター リカバリーを可能にするさまざまなオプションがあります。
ディザスター リカバリーのために IBM Netezza Replication Services を追加する場合は、ローカル ネットワークとワイド エリア ネットワークの全体にわたって冗長性を拡張することでフォールト トレランスが向上します。
IBM Netezza Replication Services では、プライマリ・システム (プライマリ・ノード) 上のデータと、1 つ以上のターゲット・ノード (下位ノード) 上のデータを同期することにで、データ損失からの保護が行われます。 これらのノードがレプリケーション セットを構成します。
High-Availability Linux (Linux-HA とも呼ばれます) では、プライマリまたはアクティブ Netezza ホストから、セカンダリまたはスタンバイ Netezza ホストへのフェールオーバー機能が提供されます。 Linux-HA ソリューションの主要なクラスター管理デーモンは、Heartbeat という名前です。 Heartbeat では、ホストの監視と、サービスの通信および状態の確認が管理されます。
それぞれのサービスがリソースです。
Netezza では、Netezza 固有のサービスを nps リソース グループにグループ化します。 Heartbeat では、ホストの障害状態や Netezza ユーザーに対するサービスが失われたことを意味する問題を検出した場合、スタンバイ ホストへのフェールオーバーを開始できます。
DRBD (分散レプリケート ブロック デバイス) は、ホスト間でブロック デバイス (ハード ディスク、パーティション、論理ボリューム) の内容をミラー化するブロック デバイス ドライバーです。 Netezza では、/nz および /export/home パーティションに対してのみ DRBD レプリケーションが使用されます。 新しいデータが、プライマリ ホストの /nz パーティションや /export/home パーティションに書き込まれると、DRBD ソフトウェアは自動的に、スタンバイ ホストの /nz パーティションと /export/home パーティションに同じ変更を加えます。
ヒント
Azure Synapse では、復旧時間が確実に短縮されるように、スナップショットを自動的に作成します。
Azure Synapse では、データベース スナップショットを使用してウェアハウスの高可用性を提供します。 データ ウェアハウス スナップショットでは、データ ウェアハウスの以前の状態を復旧またはコピーするために利用できる復元ポイントが作成されます。 Azure Synapse は分散システムであるため、データ ウェアハウス スナップショットは、Azure Storage 内にある多数のファイルで構成されます。 スナップショットでは、データ ウェアハウスに格納されたデータの増分の変更がキャプチャされます。
ヒント
キーの更新前に、ユーザー定義スナップショットを使用して復旧ポイントを定義します。
ヒント
Microsoft Azure では、DR を実現するために、地理的に離れた場所への自動バックアップを提供しています。
Azure Synapse では、スナップショットが終日自動的に取得され、7 日間利用できる復元ポイントが作成されます。 この保持期間は変更できません。 Azure Synapse では、8 時間の回復ポイントの目標 (RPO) がサポートされています。 データ ウェアハウスは、プライマリ リージョンで、過去 7 日間に作成されたいずれかのスナップショットから復元できます。
ユーザー定義の復元ポイントもサポートされており、大規模な変更の前後に、スナップショットを手動でトリガーして、データ ウェアハウスの復元ポイントを作成することができます。 この機能により、復元ポイントの論理的な一貫性が保証されており、ワークロードの中断やユーザー エラーが発生した場合には、必要とされる 8 時間未満での RPO に備えて追加のデータ保護が提供されます。
Azure Synapse では、前述のスナップショットだけでなく、geo バックアップも実行されます。これは、ペアになっているデータセンターに対して、1 日に 1 回、標準として実行されます。 geo 復元の RPO は 24 時間です。 geo バックアップは、Azure Synapse がサポートされているその他の任意のリージョン内のサーバーに復元することができます。 geo バックアップにより、プライマリ リージョン内の復元ポイントを利用できない場合でもデータ ウェアハウスを確実に復元できます。
ワークロードの管理
ヒント
運用データ ウェアハウスでは、一般に、異なるリソース使用特性を持つ混合ワークロードが同時に実行されています。
Netezza には、ワークロード管理用のさまざまな機能が組み込まれています。
| 手法 | 説明 |
|---|---|
| スケジューラ ルール | スケジューラ ルールは、プランのスケジュール設定に影響を及ぼします。 各スケジューラ ルールでは、条件または条件のセットを指定します。 スケジューラでは、プランを受け取るたびに、変更を行うスケジューラ ルールすべてを評価し、適切なアクションを実します。 スケジューラでは、実行するプランが選択されるたびに、制限を加えるスケジューラ ルールすべてを評価します。 プランが実行されるのは、それを実行しても、制限を加えるスケジューラ ルールによって課される制限を超えない場合のみです。 それ以外の場合、プランは待機します。 これは、他の WLM 手法 (SQB、GRA、PQE) に影響を及ぼす方法でプランの分類と操作を行う手段となります。 |
| 保証されたリソースの割り当て (GRA) | "リソース グループ" と呼ばれるエンティティには、システム リソース全体についての最小共有と最大割合を割り当てることができます。 各リソース・グループが、最小共有に比例してシステム・リソースを受け取ることは、スケジューラによって保証されます。 リソース グループでは、他のリソース グループがアイドル状態のときにはリソース共有をより多く受け取りますが、構成されている最大割合を超えるリソースを受け取ることはありません。 各プランはリソース グループに関連付けられ、そのリソース グループ設定の設定によって、プランを処理するために提供される使用可能なシステム リソースの割合が決定されます。 |
| 短いクエリ バイアス (SQB) | リソース (つまり、スロット、メモリ、優先キュー処理のスケジュール設定) は、短いクエリのために予約されます。 短いクエリは、コスト見積もりが、指定された最大値 (既定値は 2 秒) に満たないクエリです。 SQB を使用すると、システムが他のより長いクエリの処理でビジー状態であるときにも短いクエリを実行できます。 |
| 優先度付けされたクエリ実行 (PQE) | 構成する設定に基づいて、システムにより、各クエリに優先度 (重要、高、標準、低) が割り当てられます。 優先度は、そのクエリに関連付けられているユーザー、グループ、セッションなどの要因に応じたものになります。 その後システムでは、その優先度をリソース割り当ての基準として使用できます。 |
Azure Synapse は、リソース使用率の統計情報を自動的にログに記録します。 メトリックには、各クエリの CPU、メモリ、キャッシュ、I/O、一時ワークスペースの使用状況の統計情報が含まれます。 Azure Synapse は、接続の失敗などの接続情報もログに記録します。
ヒント
詳細レベルとシステム全体のメトリックが、Azure Synapse で自動的にログに記録されます。
Azure Synapse では、リソース クラスは、クエリ実行のためにコンピューティング リソースとコンカレンシーを制御する、あらかじめ決定されたリソース制限です。 リソース クラスは、ワークロードを管理するのに役立ちます。クラスに応じて、同時に実行されるクエリの数と、各クエリに割り当てられるコンピューティング リソースに制限を設定します。 メモリとコンカレンシーの間にはトレードオフがあります。
Azure Synapse では、次の基本的なワークロード管理の概念がサポートされています。
ワークロードの分類: ワークロード グループに要求を割り当てて、重要度レベルを設定できます。
ワークロードの重要度: 要求がリソースにアクセスする順序に影響を与えることができます。 既定では、クエリは、リソースが使用可能になると先入れ先出しでキューから解放されます。 ワークロードの重要度を使用すると、キューに関係なく、優先順位の高いクエリがリソースをすぐに受け取るようにできます。
ワークロードの分離: ワークロード グループのリソースを予約したり、さまざまなリソースの最大と最小の使用量を割り当てたり、要求のグループが使用できるリソースを制限したり、タイムアウト値を設定してランナウェイ クエリを自動的に強制終了したりできます。
混合ワークロードを実行すると、ビジー状態のシステムでリソースの問題が発生する可能性があります。 正常なワークロード管理スキームでは、リソースが効果的に管理され、リソースが確実に効率よく利用され、投資収益率 (ROI) が最大化されます。 ワークロードの分類、ワークロードの重要度、ワークロードの分離により、ワークロードでのシステム リソースの利用方法をより詳細に制御できます。
ワークロード管理ガイドでは、ワークロードの分析、[ワークロードの重要度の管理と監視](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md)の手法、リソース クラスのワークロード グループへの変換手順について説明されています。 Azure portal と DMV に対する T-SQL クエリを使用してワークロードを監視し、該当するリソースが効率的に利用されるようにします。 Azure Synapse には、ワークロード管理のすべての側面を監視するための一連の動的管理ビュー (DMV) が用意されています。 これらのビューは、アクティブにトラブルシューティングを行うときと、ワークロードでパフォーマンスのボトルネックを特定するときに役立ちます。
この情報を容量計画のために使用して、追加のユーザーやアプリケーション ワークロードのために必要なリソースを判断することもできます。 これは、頻度の低いアクティビティの期間に囲まれた一時的で激しいアクティビティのバーストを伴うワークロードなど、"スパイク" ワークロードのコスト効率の高いサポートのためのコンピューティング リソースのスケールアップ/スケールダウンを計画する場合にも当てはまります。
Azure Synapse でのワークロード管理の詳細については、「リソース クラスを使用したワークロード管理」を参照してください。
コンピューティング リソースをスケーリングする
ヒント
Azure の主な利点は、コンピューティング リソースをオンデマンドで個別にスケールアップおよびスケールダウンし、ピーク時間のあるワークロードをコスト効率よく処理できることです。
Azure Synapse のアーキテクチャでは、ストレージとコンピューティングが分離されており、それぞれを独立してスケーリングできます。 結果として、データ ストレージから独立して、パフォーマンスの需要を満たすためにコンピューティング リソースをスケーリングできます。 コンピューティング リソースは、一時停止して再開することもできます。 このアーキテクチャには、コンピューティングとストレージに対する課金は独立しているという当然の利点があります。 データ ウェアハウスが使用されていない場合は、コンピューティングを一時停止してコンピューティング コストを節約できます。
コンピューティング リソースは、そのデータ ウェアハウスのデータ ウェアハウス ユニット設定を調整することでスケールアップまたはスケールバックできます。 データ ウェアハウス ユニットを追加するにつれて、読み込みとクエリのパフォーマンスは直線的に増加します。
コンピューティング ノードを追加すると、より多くのコンピューティング能力と、より多くの並列処理を活用する機能が追加されます。 コンピューティング ノードの数が増加するにつれて、コンピューティング ノードあたりのディストリビューション数が減少し、コンピューティング能力と並列処理は、クエリのためにより多く提供されます。 同様に、データ ウェアハウス ユニットを減らすと、コンピューティング ノードの数が減少し、それによってクエリ用のコンピューティング リソースが減少します。
次のステップ
視覚化とレポートの詳細を確認するには、このシリーズの次の記事「Netezza 移行の視覚化とレポート」を参照してください。