Teradata 移行のためのデータ移行、ETL、読み込み
この記事は、Teradata から Azure Synapse Analytics に移行する方法に関するガイダンスを提供する 7 つのパートから成るシリーズのパート 2 です。 この記事で注目するのは、ETL と読み込みの移行に関するベスト プラクティスです。
データ移行に関する考慮事項
Teradata からのデータ移行に関する最初の決定
Teradata データ ウェアハウスを移行するときには、いくつかの基本的なデータ関連の質問をする必要があります。 次に例を示します。
未使用のテーブル構造を移行する必要がありますか?
リスクとユーザーへの影響を最小限に抑えるために最適な移行方法は何ですか?
データ マートを移行するとき: 物理を維持しますか、仮想に移行しますか?
以降のセクションでは、Teradata からの移行のコンテキスト内で、これらの点について説明します。
未使用のテーブルを移行しますか?
ヒント
レガシ システムでは、テーブルが時間の経過と共に冗長になることは珍しくありません。ほとんどの場合、これらを移行する必要はありません。
既存のシステムで使用されているテーブルのみを移行する方が合理的です。 アクティブでないテーブルは、移行するのではなく、アーカイブできます。これにより、将来必要に応じてデータを使用できます。 ドキュメントは最新ではない可能性があるため、使用中のテーブルを判別するには、ドキュメントではなくシステム メタデータとログ ファイルを使用することをお勧めします。
有効にした場合、Teradata システム カタログ テーブルとログには、特定のテーブルが最後にアクセスされた時点を判別できる情報が含まれます。この情報を使用して、テーブルが移行の候補であるかどうかを判断できます。
最後のアクセスと最後の変更の日付を提供する DBC.Tables に対するクエリの例を次に示します。
SELECT TableName, CreatorName, CreateTimeStamp, LastAlterName,
LastAlterTimeStamp, AccessCount, LastAccessTimeStamp
FROM DBC.Tables t
WHERE DataBaseName = 'databasename'
ログ記録が有効になっていて、ログ履歴にアクセスできる場合は、テーブル DBQLogTbl や関連するログ記録テーブルで、SQL クエリ テキストなどの他の情報を使用できます。 詳細については、Teradata ログ履歴に関するページを参照してください。
リスクとユーザーへの影響を最小限に抑えるために最適な移行方法は何ですか?
企業でこの質問が頻繁に取り上げられるのは、企業はデータ ウェアハウス データ モデルへの変更の影響を軽減し、機敏性を向上させたいと考える場合が多いためです。 多くの場合、企業は ETL の移行中にデータをさらに最新化または変換する機会を見つけます。 このアプローチでは、複数の要因が同時に変化し、古いシステムと新しいシステムの結果を比較することが困難になるため、リスクがいっそう高くなります。 ここでデータ モデルを変更すると、他のシステムへのアップストリームまたはダウンストリームの ETL ジョブにも影響する可能性があります。 そのリスクのため、この規模での再設計はデータ ウェアハウス移行後に行うことをお勧めします。
データ モデルが移行全体の一部として意図的に変更される場合であっても、新しいプラットフォームで再エンジニアリングを行うのではなく、既存のモデルをそのまま Azure Synapse に移行するのがよい方法です。 このようにすると、既存の運用システムへの影響が最小限になる一方で、1 回限りの再エンジニアリング タスクに対しては Azure プラットフォームのパフォーマンスと柔軟なスケーラビリティによる利点があります。
Teradata から移行するときには、移行プロセスにおける足掛かりとして、Azure 内の VM に Teradata 環境を作成することを検討してください。
ヒント
データ モデルに対する変更が将来計画されている場合でも、最初は既存のモデルをそのまま移行します。
移行の一環として VM Teradata インスタンスを使用する
オンプレミス Teradata 環境から移行するために選択できる方法の 1 つは、Azure 環境を活用して、Azure 内の VM に Teradata インスタンスを作成することです。これは、ターゲット Azure Synapse 環境と併置されます。 これが可能になるのは、Azure が低コストのクラウド ストレージと柔軟なスケーラビリティを提供しているためです。
この方法では、Teradata Parallel Data Transporter などの標準 Teradata ユーティリティ (または、Attunity Replicate などのサードパーティ データ レプリケーション ツール) を使用して、VM インスタンスに移行される必要がある Teradata テーブルのサブセットを効率的に移動できます。 その後、Azure 環境内ですべての移行タスクを実行できます。 この方法には、いくつかの利点があります。
データの初期レプリケーションの後、移行タスクはソース システムに影響しません。
Azure 環境には、使い慣れた Teradata のインターフェイス、ツール、ユーティリティがあります。
Azure 環境では、オンプレミス ソース システムとクラウド ターゲット システムの間で利用可能なネットワーク帯域幅が提供されます。
Azure Data Factory などのツールを使用すると、Teradata Parallel Transporter などのユーティリティを効率的に呼び出して、データをすばやく簡単に移行できます。
移行プロセスは、Azure 環境内で完全に調整および制御されます。
データ マートを移行するとき: 物理を維持しますか、仮想に移行しますか?
ヒント
データ マートを仮想化すると、ストレージと処理リソースを節約できます。
レガシ Teradata データ ウェアハウス環境では、組織内の特定の部門またはビジネス機能に対して、パフォーマンスの優れたアド ホック セルフサービス クエリとレポート機能を提供するために構成されたいくつかのデータ マートを作成するのが一般的です。 そのため、データ マートは通常、データ ウェアハウスのサブセットで構成され、ユーザーが Microsoft Power BI、Tableau、MicroStrategy などのユーザーフレンドリなクエリ ツールを使用して速い応答時間で簡単にデータをクエリできる形式の、集計されたバージョンのデータを格納します。 この形式は通常、ディメンション データ モデルです。 データ マートの使用方法の 1 つは、基になるウェアハウス データ モデルが異なる (データ コンテナーである、などの) 場合でも、使用可能な形式でデータを公開することです。
組織内の個々の部署に対して別々のデータ マートを使用すると、ユーザーに自分に関係する特定のデータ マートへのアクセスのみを許可し、機密データを排除、難読化、または匿名化することにより、堅牢なデータ セキュリティ体制を実装できます。
これらのデータ マートが物理テーブルとして実装されている場合は、それらを格納するための追加のストレージ リソースと、それらを定期的にビルドおよび更新するための追加の処理が必要になります。 また、マート内のデータは、最後の更新操作の時点での最新状態を保っているだけなので、変動の激しいデータ ダッシュボードには適さない可能性があります。
ヒント
Azure Synapse のパフォーマンスとスケーラビリティにより、パフォーマンスを犠牲にすることなく仮想化が可能になります。
Azure Synapse などの比較的低コストでスケーラブルな MPP アーキテクチャの出現と、そのようなアーキテクチャに固有のパフォーマンス特性により、マートを物理テーブルのセットとしてインスタンス化しなくても、データ マート機能を提供できる可能性があります。 これは、データ マートの効率的な仮想化を、メイン データ ウェアハウスに対する SQL ビューを介して行うか、Azure や Microsoft パートナーの仮想化製品のビューなどの機能を使用して仮想化レイヤーを介して行うことで実現されます。 この方法では、追加のストレージと集計処理の必要性が軽減されるか不要になるため、移行する必要のあるデータベース オブジェクトの総数が減少します。
このアプローチには、もう 1 つの潜在的な利点があります。 仮想化レイヤー内に集計と結合のロジックを実装し、仮想化されたビューを介して外部レポート ツールを表示することにより、これらのビューを作成するのに必要な処理がデータ ウェアハウスに "プッシュ ダウン" されます。データ ウェアハウスは、通常、大量のデータに対して結合、集計などの関連する操作を実行するのに最適な場所です。
物理データ マートよりも仮想データ マートの実装を選択する主な推進要因は、以下のとおりです。
機敏性の向上: 仮想データ マートの方が、物理テーブルとその関連 ETL プロセスよりも変更しやすい。
総保有コストの低下: 仮想化された実装では必要なデータ ストアとデータのコピー数が少なくなる。
移行のための ETL ジョブを排除でき、仮想化環境のデータ ウェアハウス アーキテクチャが簡素化される。
パフォーマンス: これまでのところ物理データ マートの方がパフォーマンスは優れているとはいえ、仮想化製品にはその差を軽減するためのインテリジェントなキャッシュ手法が実装されるようになっている。
Teradata からのデータ移行
データを理解する
移行計画の一部は、移行する必要があるデータの量を詳しく理解することです。それが、移行方法に関する決定に影響を与える可能性があるためです。 システム メタデータを使用して、移行するテーブル内で "生データ" によって占有されている物理領域を判別します。 この文脈では、"生データ" とは、インデックスや圧縮などのオーバーヘッドを除く、テーブル内でデータ行によって使用されている領域のサイズを意味します。 これが特に当てはまるのは最大レベルのファクト テーブルです。これらのテーブルは、一般に、データの 95% 以上を構成しているためです。
データの代表的なサンプル (100 万行など) を、非圧縮のフラットな ASCII 区切りデータ ファイルに抽出することにより、特定のテーブルで移行されることになるデータの量について、正確な数字を取得できます。 次に、そのファイルのサイズを使用して、そのテーブルの行あたりの平均生データ サイズを取得します。 最後に、その平均サイズに、テーブル全体に含まれる行の総数を掛けて、そのテーブルの生データ サイズを求めます。 その生データ サイズを計画で使用します。
ETL 移行に関する考慮事項
Teradata ETL 移行に関する最初の決定
ヒント
ETL 移行の方法を事前に計画し、必要に応じて Azure 機能を活用します。
ETL/ELT 処理のために、レガシ Teradata データ ウェアハウスは、BTEQ や Teradata Parallel Transporter (TPT) などの Teradata ユーティリティ、または Informatica や Ab Initio などのサードパーティの ETL ツールを使用するカスタムビルド スクリプトを使用することがあります。 Teradata データ ウェアハウスは、時間の経過と共に進化する ETL と ELT の方法の組み合わせを使用することがあります。 Azure Synapse への移行を計画するときには、関連するコストとリスクを最小限に抑えながら、必要な ETL/ELT 処理を新しい環境に実装するために最適な方法を決定する必要があります。 ETL と ELT の処理の詳細については、ELT と ETL の設計方法の比較に関するページを参照してください。
以降のセクションでは、移行オプションについて説明し、さまざまなユース ケースに関する推奨事項を示します。 このフローチャートは、1 つの方法をまとめたものです。
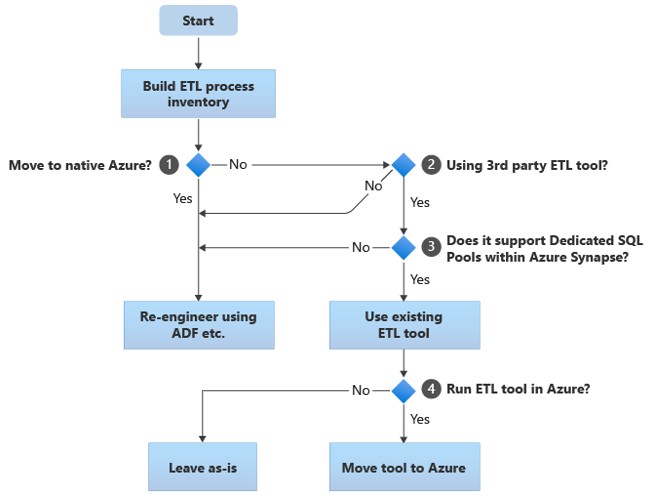
最初の手順では常に、移行する必要がある ETL/ELT プロセスのインベントリを作成します。 他の手順と同様に、標準の "組み込み" Azure 機能により、既存のプロセスの一部を移行する必要がなくなる場合があります。 計画目的では、実行する移行の規模を理解することが重要です。
前のフローチャートでは、決定 1 は、完全に Azure ネイティブの環境に移行するかどうかに関する高レベルの決定に関連しています。 完全に Azure ネイティブの環境に移行する場合は、Azure Data Factory のパイプラインとアクティビティまたは Azure Synapse Pipelines を使用して、ETL 処理を再エンジニアリングすることをお勧めします。 完全に Azure ネイティブの環境に移行しない場合、決定 2 は、既存のサードパーティの ETL ツールが既に使用されているかどうかです。
Teradata 環境では、ETL 処理の一部またはすべてが、BTEQ や TPT などの Teradata 固有のユーティリティを使用するカスタム スクリプトによって実行されることがあります。 この場合は、Data Factory を使用して再エンジニアリングする方法をとる必要があります。
ヒント
既存のサードパーティ ツールへの投資を活用して、コストとリスクを軽減します。
サードパーティの ETL ツールが既に使用されていて、特にスキルに大きな投資が行われている場合や、複数の既存のワークフローとスケジュールがそのツールを使用している場合は、そのツールがターゲット環境として Azure Synapse を効率的にサポートできるかどうかが、決定 3 です。 最も効率的なデータ読み込みのためには、PolyBase や COPY INTO などの Azure 機能を活用できる "ネイティブ" コネクタがそのツールに含まれていれば理想的です。 PolyBase や COPY INTO などの外部プロセスを呼び出し、適切なパラメーターを渡す方法があります。 この場合は、Azure Synapse を新しいターゲット環境として、既存のスキルとワークフローを活用します。
既存のサードパーティの ETL ツールを持ち続ける場合は、(既存のオンプレミス ETL サーバーに対してではなく) Azure 環境内でそのツールを実行し、既存のワークフローの全体的オーケストレーションを Azure Data Factory に処理させるという利点が得られることがあります。 注目すべき利点の 1 つは、Azure からダウンロードし、処理してから、Azure に再びアップロードする必要があるデータが少なくなる点です。 そのため、決定 4 は、既存のツールをそのまま実行するか、Azure 環境に移行してコスト、パフォーマンス、スケーラビリティの利点を実現するかです。
既存の Teradata 固有のスクリプトを再エンジニアリングする
既存の Teradata ウェアハウス ETL/ELT 処理の一部またはすべてが、BTEQ、MLOAD、TPT などの Teradata 固有のユーティリティを利用するカスタム スクリプトによって処理される場合は、新しい Azure Synapse 環境用にこれらのスクリプトを再コーディングする必要があります。 同様に、ETL プロセスが Teradata のストアド プロシージャを使用して実装された場合は、これらのプロセスも再コーディングする必要があります。
ヒント
移行する ETL タスクのインベントリには、スクリプトとストアド プロシージャが含まれている必要があります。
ETL プロセスの一部の要素は、たとえば、外部ファイルからステージング テーブルへの単純な一括データ読み込みにより、簡単に移行できます。 たとえば、高速読み込みまたは MLOAD ではなく PolyBase を使用して、プロセスのそれらの部分を自動化することもできます。 エクスポートされたファイルが Parquet である場合は、ネイティブ Parquet リーダーを使用できます。これは PolyBase よりも高速なオプションです。 任意の複雑な SQL またはストアド プロシージャ (あるいはその両方) を含むプロセスの他の部分では、再エンジニアリングにかかる時間が長くなります。
Azure Synapse との互換性に関して Teradata SQL をテストする方法の 1 つは、Teradata ログからいくつかの代表的な SQL ステートメントをキャプチャし、それらのクエリの前にプレフィックス EXPLAIN を付け、(Azure Synapse での同種同士の移行データ モデルを想定した場合) Azure Synapse でそれらの EXPLAIN ステートメントを実行することです。 互換性のない SQL ではエラーが生成され、エラー情報によって再コーディング タスクの規模を判別できます。
Microsoft パートナーは、Teradata SQL とストアド プロシージャを Azure Synapse に移行するためのツールとサービスを提供します。
サードパーティの ETL ツールを使用する
前のセクションで説明したように、多くの場合、既存のレガシ データ ウェアハウス システムには、サードパーティの ETL 製品によって事前にデータが取り込まれ、保守されます。 Azure Synapse の Microsoft データ統合パートナーの一覧については、データ統合パートナーに関するページを参照してください。
Teradata からのデータ読み込み
Teradata からデータを読み込むときに使用できる選択肢
ヒント
サードパーティ ツールを使用して、移行プロセスを簡略化および自動化すると、リスクを軽減できます。
Teradata データ ウェアハウスからのデータ移行に関して言えば、データ読み込みに関連するいくつかの基本的な質問を解決する必要があります。 既存のオンプレミス Teradata 環境からクラウド内の Azure Synapse にデータを物理的に移動する方法と、転送と読み込みを実行するために使用されるツールを決定する必要があります。 以降のセクションで説明する次の質問を検討してください。
データをファイルに抽出しますか、ネットワーク接続を介して直接移動しますか?
プロセスのオーケストレーションは、ソース システムから行いますか、ターゲットの Azure 環境から行いますか?
プロセスの自動化と管理にはどのツールを使用しますか?
ファイルとネットワーク接続のどちらを介してデータを転送するか
ヒント
移行するデータの量と使用可能なネットワーク帯域幅を理解します。これらの要因は、移行方法の決定に影響を与えるためです。
移行するデータベース テーブルが Azure Synapse 内に作成されたら、データを移動して、レガシ Teradata システムからそれらのテーブルにデータを取り込み、新しい環境に読み込むことができます。 基本的な方法は 2 つあります。
ファイル抽出: BTEQ、高速エクスポート、または Teradata Parallel Transporter (TPT) を使用して、通常は CSV 形式で、Teradata テーブルからフラット ファイルにデータを抽出します。 データ スループットの観点からは TPT が最も効率的であるため、可能な限りこれを使用してください。
この方法では、抽出されたデータ ファイルを一時保管するためのスペースが必要です。 スペースは、ローカルの Teradata ソース データベース (十分なストレージが使用可能である場合) またはリモートの Azure Blob Storage に確保できます。 ファイルがローカルに書き込まれると、ネットワークのオーバーヘッドが回避されるため、最適なパフォーマンスが実現されます。
ストレージとネットワーク転送の所要量を最小限に抑えるには、gzip などのユーティリティを使用して、抽出されたデータ ファイルを圧縮することをお勧めします。
抽出されたフラット ファイルは、(ターゲット Azure Synapse インスタンスと併置される) Azure Blob Storage に移動するか、PolyBase または COPY INTO を使用して Azure Synapse に直接読み込むことができます。 ローカルのオンプレミス ストレージから Azure クラウド環境にデータを物理的に移動する方法は、データの量と使用可能なネットワーク帯域幅によって異なります。
Microsoft は、大量のデータを移動するためのさまざまなオプションを提供します。たとえば、ネットワーク経由でファイルを Azure Storage に移動するための AZCopy、プライベート ネットワーク接続経由で一括データを移動するための Azure ExpressRoute、ファイルを物理ストレージ デバイスに移動する (そのデバイスは読み込みのために Azure データ センターに出荷されます) ための Azure Data Box などです。 詳細については、データ転送に関するページを参照してください。
ネットワーク経由での直接抽出と読み込み: ターゲット Azure 環境は、データ抽出要求を (通常は SQL コマンドを介して) レガシ Teradata システムに送信して、データを抽出します。 結果は、ネットワーク経由で送信され、Azure Synapse に直接読み込まれます。データの到着場所を中間ファイルにする必要はありません。 このシナリオの制限要因は、通常、Teradata データベースと Azure 環境の間のネットワーク接続の帯域幅です。 データの量が非常に多い場合、この方法は実用的でない可能性があります。
両方の方法を併用するハイブリッドな方法もあります。 たとえば、小さなディメンション テーブルと、大きなファクト テーブルのサンプルについては、直接ネットワーク抽出方法を使用して、Azure Synapse にテスト環境をすばやく用意できます。 大量のデータがある過去のファクト テーブルについては、Azure Data Box を使用して、ファイルの抽出と転送による方法を使用できます。
Teradata または Azure のどちらから調整しますか?
Azure Synapse に移行するときに推奨される方法は、最も効率的なデータ読み込みのために、Azure 環境からデータ抽出と読み込みを調整することです。これには、Azure Synapse Pipelines または Azure Data Factory、さらには PolyBase や COPY INTO などの関連ユーティリティを使用します。 この方法は、Azure 機能を活用し、再利用可能なデータ読み込みパイプラインを簡単に構築する方法を提供します。
この方法の他の利点には、データ読み込みプロセス中の Teradata システムへの影響の軽減があります。これは、管理と読み込みのプロセスが Azure で実行されるためです。また、メタデータ駆動型のデータ読み込みパイプラインを使用してプロセスを自動化する機能があります。
使用できるツールは何ですか?
データ変換と移動のタスクは、すべての ETL 製品の基本的な機能です。 これらの製品のいずれかが既存の Teradata 環境で既に使用されている場合、既存の ETL ツールを使用すると、Teradata から Azure Synapse へのデータ移行が簡略化される可能性があります。 この方法では、ETL ツールがターゲット環境として Azure Synapse をサポートしていることを前提としています。 Azure Synapse をサポートしているツールの詳細については、データ統合パートナーに関するページを参照してください。
ETL ツールを使用している場合は、Azure 環境内でそのツールを実行することを検討してください。これにより、Azure クラウドのパフォーマンス、スケーラビリティ、コストの利点を享受し、Teradata データ センター内のリソースを解放することができます。 もう 1 つの利点は、クラウド環境とオンプレミス環境の間のデータ移動が減少することです。
まとめ
まとめると、Teradata から Azure Synapse にデータと関連 ETL プロセスを移行するための推奨事項は、次のとおりです。
移行作業が確実に成功するように事前に計画します。
できるだけ早期に、移行するデータとプロセスの詳細なインベントリを作成します。
システム メタデータとログ ファイルを使用して、データとプロセスの使用状況を正確に理解します。 ドキュメントは最新ではない可能性があるため、頼らないでください。
移行するデータの量と、オンプレミス データ センターと Azure クラウド環境の間のネットワーク帯域幅を理解します。
レガシ Teradata 環境からの移行をオフロードするための足掛かりとして、Azure VM で Teradata インスタンスを使用することを検討してください。
標準の "組み込み" Azure 機能を活用して、移行ワークロードを最小限に抑えます。
Teradata 環境と Azure 環境の両方でのデータ抽出と読み込みのために最も効率的なツールを特定して理解します。 プロセスの各フェーズで適切なツールを使用します。
Azure Synapse Pipelines や Azure Data Factory などの Azure 機能を使用して、Teradata システムへの影響を最小限に抑えながら、移行プロセスを調整および自動化します。
次の手順
セキュリティ アクセス操作の詳細については、このシリーズの次の記事「Teradata 移行のためのセキュリティ、アクセス、操作」を参照してください。