チュートリアル: 自動機械学習で Python のモデルをトレーニングする (非推奨)
Azure Machine Learning は、機械学習モデルのトレーニング、デプロイ、自動化、管理、追跡を可能にするクラウドベースの環境です。
このチュートリアルでは、Azure Machine Learning の自動機械学習を使用して、タクシー運賃を予測する回帰モデルを作成します。 このプロセスは、トレーニング データと構成設定を受け取り、さまざまな方法、モデル、およびハイパーパラメーター設定の組み合わせを自動的に反復処理することで、最適なモデルに到達します。
このチュートリアルでは、以下の内容を学習します。
- Apache Spark と Azure Open Datasets を使用してデータをダウンロードする。
- Apache Spark データフレームを使用してデータを変換およびクリーニングする。
- 自動機械学習で回帰モデルをトレーニングする。
- モデルの正確性を計算する。
開始する前に
- サーバーレス Apache Spark プールの作成に関するクイックスタートに従って、サーバーレス Apache Spark 2.4 プールを作成します。
- 既存の Azure Machine Learning ワークスペースがない場合は、Azure Machine Learning ワークスペースのセットアップのチュートリアルを完了します。
警告
- 2023 年 9 月 29 日より、Azure Synapse では Spark 2.4 ランタイムの公式サポートが中止となります。 2023 年 9 月 29 日の後は、Spark 2.4 に関連するサポート チケットに対応しません。 Spark 2.4 のバグやセキュリティ修正のためのリリース パイプラインはありません。 サポート終了後の Spark 2.4 の利用は自己責任で行われます。 セキュリティと機能に関する潜在的な懸念があるため、使用停止を強くお勧めしています。
- Apache Spark 2.4 の非推奨プロセスの一環として、Azure Synapse Analytics の AutoML も非推奨になることをお知らせします。 これには、ロー コード インターフェイスと、コードを介して AutoML 試用版を作成するために使用される API の両方が含まれます。
- AutoML 機能は Spark 2.4 ランタイムを通じて排他的に使用できました。
- AutoML 機能を引き続き利用したいお客様には、Azure Data Lake Storage Gen2 (ADLSg2) アカウントにデータを保存することをお勧めします。 そこから、Azure Machine Learning (AzureML) を介して AutoML エクスペリエンスにシームレスにアクセスできます。 この回避策の詳細については、こちらを参照してください。
回帰モデルについて
回帰モデルは、独立した予測子に基づいて数値の出力値を予測します。 回帰の目的は、1 つの変数が他の変数にどのように影響を及ぼすかを推定することによって、独立した予測変数間の関係を確立することです。
ニューヨーク市のタクシー データに基づく例
この例では、Spark を使用して、ニューヨーク市 (NYC) のタクシー乗車のチップ データに対して、いくつかの分析を実行します。 データは Azure Open Datasets から入手できます。 このデータセットのサブセットには、イエロー タクシー乗車に関する情報が格納され、各乗車、出発と到着の時刻および場所、料金に関する情報が含まれます。
重要
その保存場所からこのデータを取得するために、追加料金が発生する場合があります。 次の手順では、NYC のタクシー運賃を予測するモデルを作成します。
データのダウンロードと準備
その方法は次のとおりです。
PySpark カーネルを使用してノートブックを作成します。 手順については、「ノートブックを作成する」を参照してください。
Note
PySpark カーネルであるため、コンテキストを明示的に作成する必要はありません。 最初のコード セルを実行すると、Spark コンテキストが自動的に作成されます。
生データは Parquet 形式であるため、Spark コンテキストを使用して、ファイルをデータフレームとして、直接メモリにプルできます。 Open Datasets API を使用してデータを取得することにより、Spark データフレームを作成します。 ここでは、Spark データフレームの
schema on readプロパティを使用してデータ型とスキーマを推論します。blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)Spark プールのサイズによっては、生データが大きすぎるか、その操作に時間がかかりすぎる可能性があります。
start_dateおよびend_dateフィルターを使用して、1 か月分のデータなど、このデータをさらに絞り込むことができます。 データフレームをフィルター処理したら、新しいデータフレームに対してdescribe()関数も実行して、各フィールドの概要の統計を確認します。概要の統計に基づいて、データに多少の不規則性があることがわかります。 たとえば、最短乗車距離が 0 未満であると統計で示されています。 これらの不規則なデータ ポイントを除外する必要があります。
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()列のセットを選択し、乗車の
datetimeフィールドから時間ベースのさまざまな特徴量を作成することによって、データセットから特徴量を生成します。 前の手順で特定した外れ値を除外してから、最後の数列はトレーニングに不要なため、削除します。from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)これにより、次のように、月の日付、乗車時刻 (時)、曜日、合計乗車時間の列が追加された新しいデータフレームが作成されます。

テストおよび検証用データセットの生成
最終的なデータセットが完成したら、Spark の random_ split 関数を使用して、トレーニングとテストの各セットにデータを分割できます。 この関数は、指定された重みを使用して、モデル トレーニング用のトレーニング データセットとテスト用の検証データセットにデータをランダムに分割します。
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
この手順により、完成したモデルをテストするためのデータ ポイントがモデルのトレーニングに使用されていないことが保証されます。
Azure Machine Learning ワークスペースへの接続
Azure Machine Learning のワークスペースは、Azure サブスクリプションとリソースの情報を受け取るクラスです。 また、これにより、お客様のモデル実行を監視して追跡するためのクラウド リソースが作成されます。 この手順では、既存の Azure Machine Learning ワークスペースからワークスペース オブジェクトを作成します。
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
データフレームを Azure Machine Learning データセットに変換する
リモート実験を送信するには、データセットを Azure Machine Learning の TabularDataset インスタンスに変換します。 TabularDataset は、指定されたファイルを解析して、データを表形式で表します。
次のコードでは、既存のワークスペースと、Azure Machine Learning の既定のデータストアを取得します。 次に、データストアとファイルの場所をパス パラメーターに渡して、新しい TabularDataset インスタンスを作成します。
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

自動実験を送信する
以降のセクションでは、自動機械学習の実験を送信するプロセスについて説明します。
トレーニングの設定を定義する
実験を送信するには、トレーニング用の実験パラメーターとモデルの設定を定義する必要があります。 設定の全一覧については、Python での自動機械学習の実験の構成に関する記事を参照してください。
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}定義済みのトレーニング設定を
kwargsパラメーターとしてAutoMLConfigオブジェクトに渡します。 Spark を使用しているので、sc変数によって自動的にアクセス可能な Spark コンテキストも渡す必要があります。 さらに、トレーニング データとモデルの種類 (ここでは回帰) を指定します。from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
注意
自動機械学習の前処理手順は、基になるモデルの一部になります。 これらの手順には、特徴量の正規化、欠損データの処理、テキストから数値への変換などがあります。 モデルを予測に使用する場合、トレーニング中に適用されたものと同じ前処理手順が入力データに自動的に適用されます。
自動回帰モデルをトレーニングする
次に、Azure Machine Learning ワークスペースに実験オブジェクトを作成します。 実験は、個々の実行のコンテナーとして機能します。
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
実験が完了すると、完了した反復の詳細が出力で返されます。 各イテレーションでは、モデルの種類、実行継続時間、およびトレーニングの精度が表示されます。 BEST フィールドでは、メトリックの種類に基づいて、最高の実行トレーニング スコアが追跡されます。

注意
自動機械学習の実験を送信すると、さまざまな反復とモデルの種類が実行されます。 通常、この実行には 60 から 90 分かかります。
最高のモデルを取得する
反復から最適なモデルを選択するには、get_output 関数を使用して、最適な実行でかつ適合するモデルを返します。 次のコードでは、ログされた任意のメトリックや特定の反復に対する、最適な実行でかつ適合するモデルを取得します。
# Get best model
best_run, fitted_model = local_run.get_output()
モデルの精度をテストする
モデルの正確性をテストするには、最適なモデルを使用して、テスト データセットに対してタクシー料金の予測を実行します。
predict関数では、最適なモデルを使用して、検証データセットからy(金額) の値を予測します。# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)二乗平均平方根誤差は、モデルによって予測されたサンプル値と観測値の差の尺度であり、よく使用されます。
y_testデータフレームをモデルの予測値と比較して、結果の二乗平均平方根誤差を計算します。関数
mean_squared_errorは 2 つの配列を引数に取り、2 者間の平均二乗誤差を計算します。 次に、結果の平方根をとります。 このメトリックは、タクシー料金の予測が実際の料金の値からどの程度離れているかを大まかに示します。from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151二乗平均平方根誤差は、モデルによる応答の予測の正確性を示す良い尺度です。 結果から、モデルでのデータ セットの特徴量によるタクシー料金の予測はかなり良好で、概して 2.00 ドル以内であることがわかります。
次のコードを実行して、平均絶対誤差率を計算します。 このメトリックは、誤差のパーセンテージで精度を表します。 これは、予測値ごとに実際の値との絶対差を計算してから、すべての差を合計することによって行われます。 その後、その合計が、実際の値の合計に対する割合で表されます。
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.96344928961512632 つの予測正確性メトリックから、モデルでのデータ セットの特徴量によるタクシー料金の予測はかなり良好であることがわかります。
線形回帰モデルを適合させたら、モデルがデータにどの程度適合しているかを判定する必要があります。 これを行うには、予測された出力に対して実際の料金値をプロットします。 さらに、R 二乗メジャーを計算して、適合する回帰直線にデータがどれだけ近いかを把握します。
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()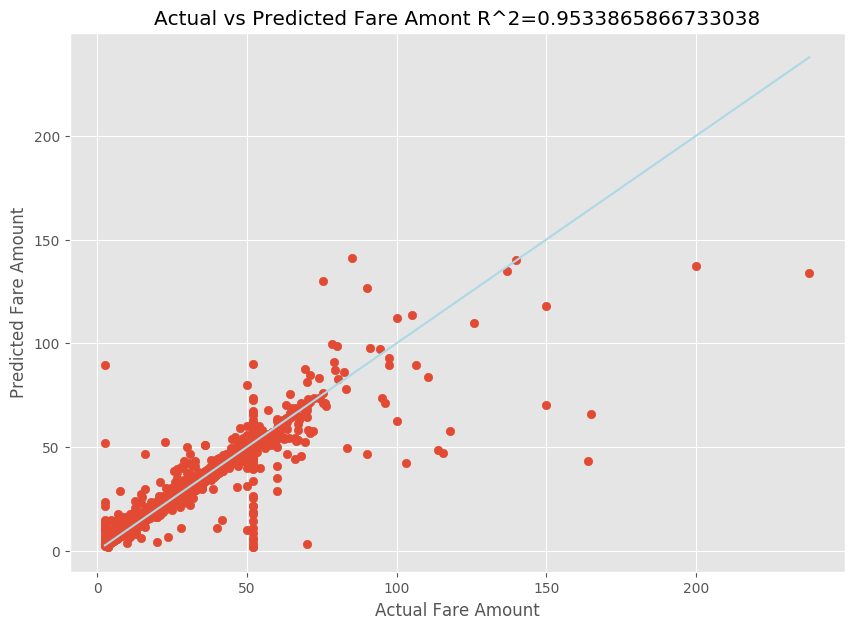
結果から、R 二乗メジャーが分散の 95 パーセントを占めていることがわかります。 これは、実際のプロットと予測されたプロットによっても検証されます。 回帰モデルが占める分散が大きいほど、データ ポイントは適合する回帰直線に近くなります。
Azure Machine Learning にモデルを登録する
最適なモデルを検証したら、Azure Machine Learning に登録できます。 その後、登録済みモデルをダウンロードするかデプロイし、登録したすべてのファイルを受信できます。
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
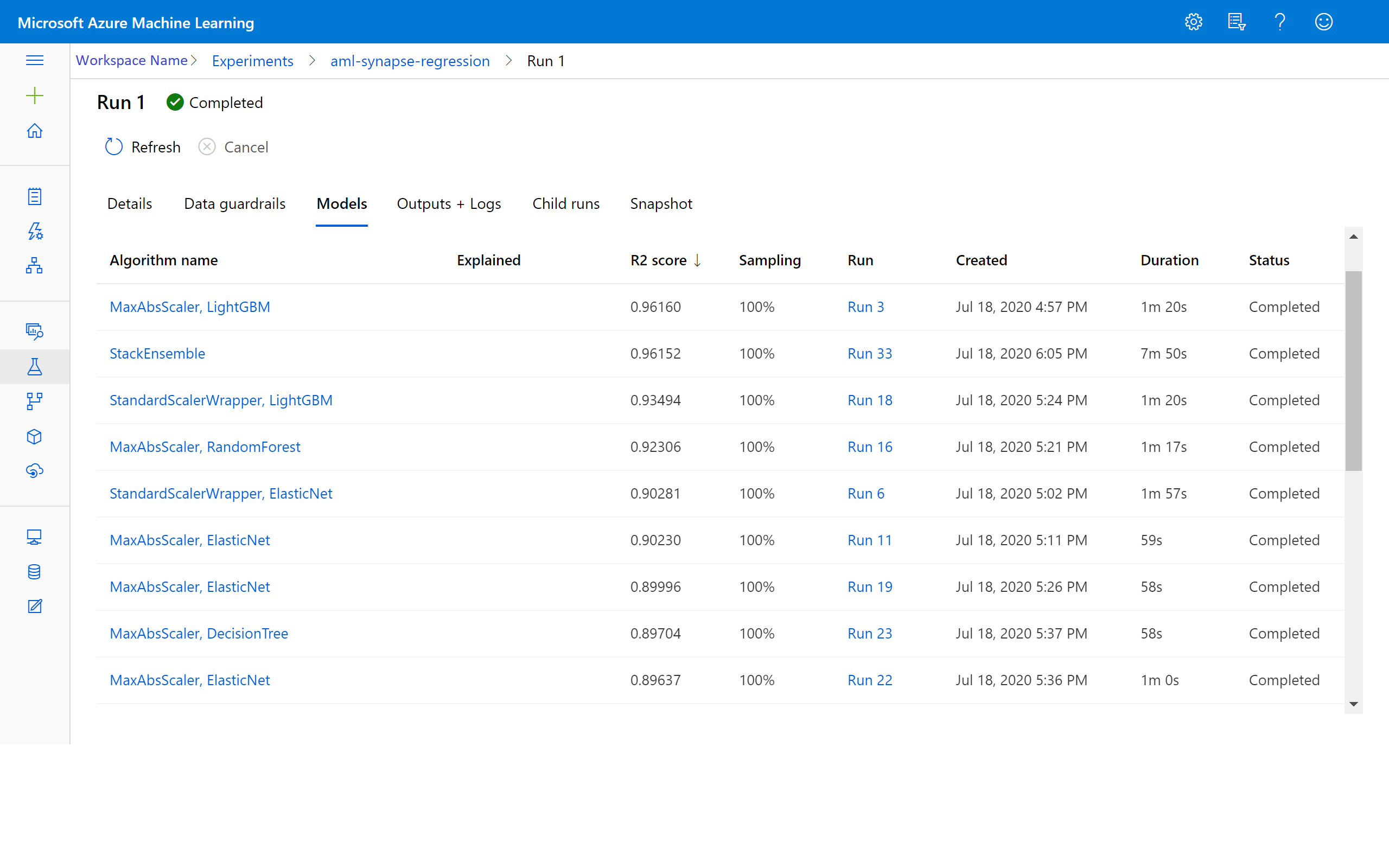
Azure Machine Learning で結果を表示する
Azure Machine Learning ワークスペースで実験に移動して、反復の結果にアクセスすることもできます。 ここでは、実行の状態、試行したモデル、その他のモデル メトリックの詳細を取得できます。