Azure Synapse Link for Azure SQL Database の概要
この記事は、Azure Synapse Link for Azure SQL Database の使用を開始するための詳細なガイドです。 この機能の概要については、「Azure Synapse Link for Azure SQL Database」を参照してください。
前提条件
Azure Synapse Link for SQL を取得するには、「新しいAzure Synapse ワークスペースを作成する」を参照してください。 このチュートリアルでは、パブリック ネットワークに Azure Synapse Link for SQL を作成します。 この記事では、Azure Synapse ワークスペースの作成時に [マネージド仮想ネットワークを無効にする] と [すべての IP アドレスからの接続を許可する] を選択していることを前提としています。 ネットワーク セキュリティを使用して Azure Synapse Link for Azure SQL Database を構成する場合は、「ネットワーク セキュリティを使用して Azure Synapse Link for Azure SQL Database を構成する 」も参照してください。
データベース トランザクション ユニット (DTU) ベースのプロビジョニングの場合は、Azure SQL Database サービスが最低でも 100 DTU 以上の Standard レベルであることを確認します。 プロビジョニングされた DTU が 100 未満の Free、Basic、Standard レベルはサポートされていません。
ソース Azure SQL データベースを構成する
Azure portal にサインインします。
お使いの Azure SQL 論理サーバーに移動し、[ID] を選択して、[システム割り当てマネージド ID] を [オン] に設定します。
![[システム割り当てマネージド ID] をオンにしているスクリーンショット。](../media/connect-synapse-link-sql-database/set-identity-sql-database.png)
[ネットワーク] に移動し、[Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] チェックボックスをオンにします。

Microsoft SQL Server Management Studio (SSMS) または Azure Data Studio を使用して、論理サーバーに接続します。 マネージド ID を使用して Azure Synapse ワークスペースを Azure SQL データベースに接続する場合は、論理サーバーで Microsoft Entra 管理者アクセス許可を設定します。 手順 6 で特権を適用するには、同じ管理者名を使用して、管理者権限で論理サーバーに接続します。
[データベース] を展開し、作成したデータベースを右クリックし、[新しいクエリ] を選びます。
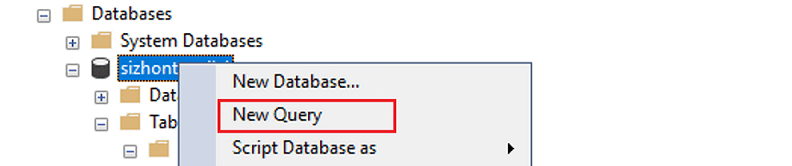
マネージド ID を使用して Azure Synapse ワークスペースをソース Azure SQL データベースに接続する場合は、次のスクリプトを実行して、ソース データベースにマネージド ID アクセス許可を付与します。
代わりに Azure Synapse ワークスペースを SQL 認証を使用してソース Azure SQL データベースに接続する場合は、この手順をスキップできます。
CREATE USER <workspace name> FROM EXTERNAL PROVIDER; ALTER ROLE [db_owner] ADD MEMBER <workspace name>;独自のスキーマを使用してテーブルを作成できます。 次のコードは、
CREATE TABLEクエリの一例にすぎません。 このテーブルに一部の行を挿入して、レプリケートするデータがあることを確認することもできます。CREATE TABLE myTestTable1 (c1 int primary key, c2 int, c3 nvarchar(50))
![[システム割り当てマネージド ID] をオンにしているスクリーンショット。](../media/connect-synapse-link-sql-database/set-identity-sql-database.png#lightbox)

ターゲット Azure Synapse SQL プールを作成する
Synapse Studio を開きます。
[管理] ハブに移動し、[SQL プール] を選び、[新規] を選びます。
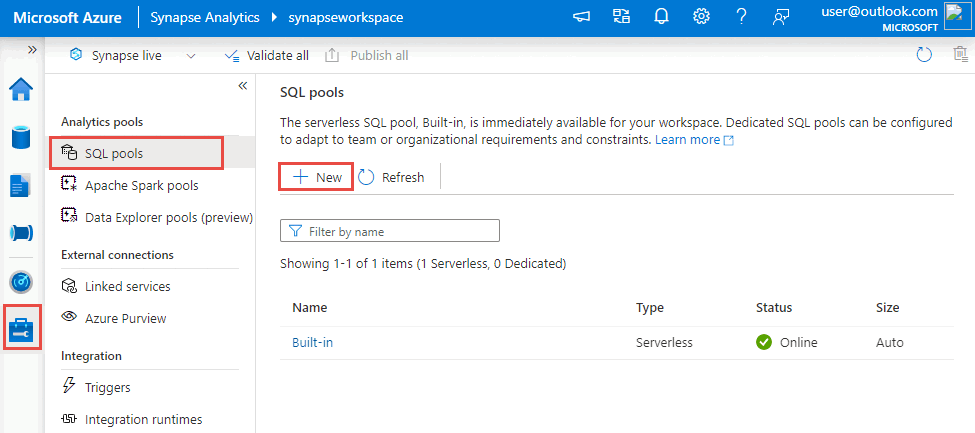
一意のプール名を入力し、既定の設定を使用して、専用プールを作成します。
予定していたスキーマがターゲット Azure Synapse SQL データベースで使用できない場合は、スキーマを作成する必要があります。 スキーマが "データベース所有者" (dbo) である場合は、この手順をスキップできます。

Azure Synapse Link 接続を作成する
Azure portal の左側のペインで、[統合] を選びます。
[統合] ペインで、プラス記号 (+) を選び、[リンク接続] を選びます。
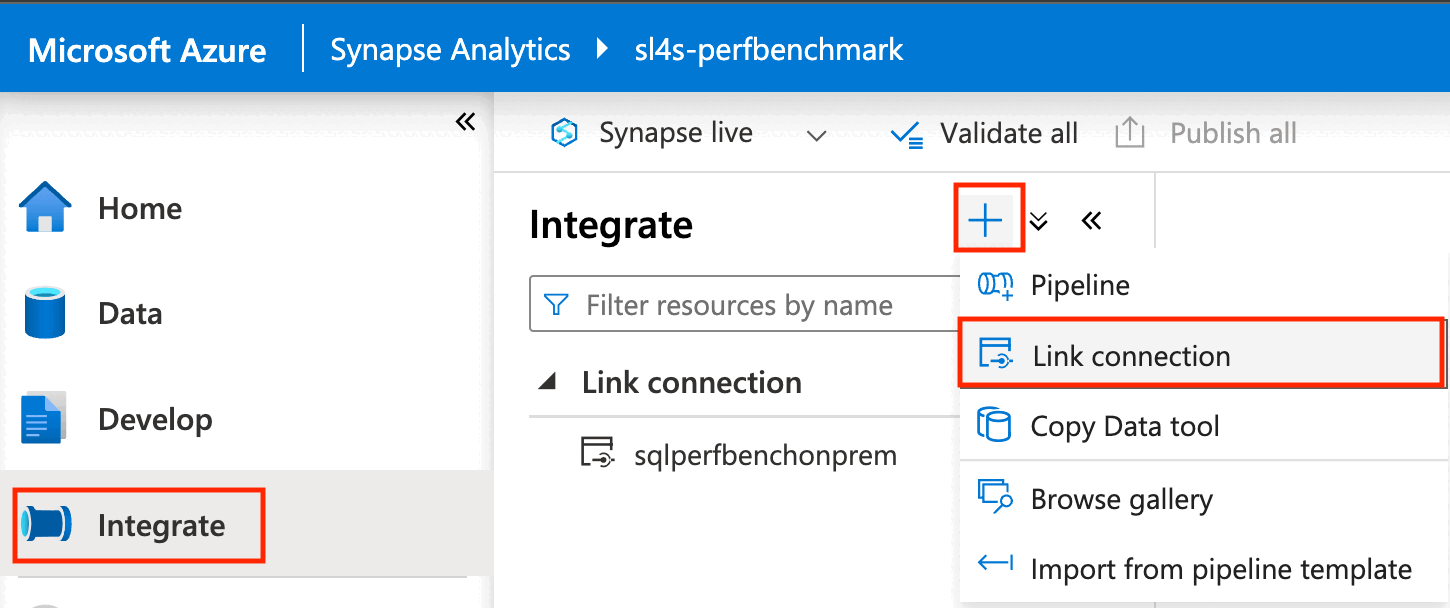
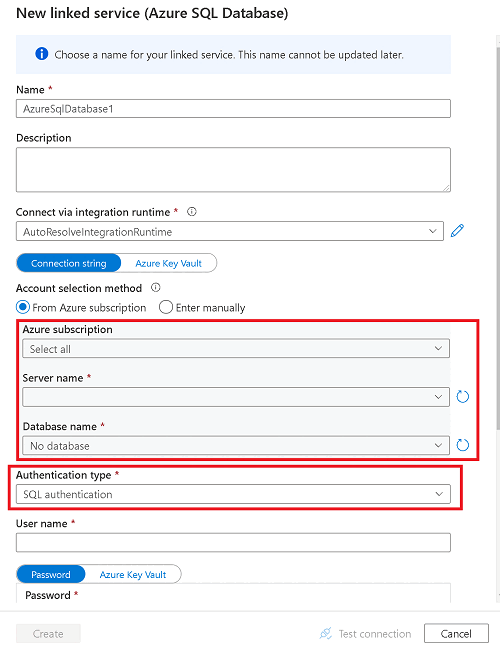
[ソースのリンク サービス] で [新規] を選択します。
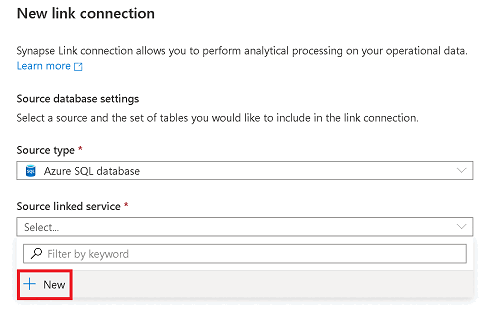
ソース Azure SQL データベースの情報を入力します。
- Azure SQL データベースに対応するサブスクリプション、サーバー、データベースを選択します。
- 以下のいずれかを実行します。
- ワークスペースのマネージド ID を使用して Azure Synapse ワークスペースをソース データベースに接続するには、[認証の種類] を [マネージド ID] に設定します。
- 代わりに SQL 認証を使用するには、使用するユーザー名とパスワードがわかっている場合は、[SQL 認証] を選びます。
Note
レガシ バージョンのリンク サービスのみがサポートされています。
[テスト接続] を選び、ファイアウォール規則が適切に構成され、ワークスペースがソース Azure SQL データベースに正常に接続できることを確認します。
[作成] を選択します
注意
ここで作成するリンク サービスは、Azure Synapse Link for SQL 専用ではありません。 これは、適切なアクセス許可を持つ任意のワークスペース ユーザーが使用できます。 時間を確保して、このリンク サービスとその資格情報にアクセスできるユーザーの範囲を把握します。 Azure Synapse ワークスペースのアクセス許可の詳細については、Azure Synapse ワークスペースのアクセス制御の概要 (Azure Synapse Analytics) に関するページを参照してください。
Azure Synapse ワークスペースにレプリケートする 1 つまたは複数のソース テーブルを選び、[続行] を選びます。
注意
指定されたソース テーブルは、一度に 1 つのリンク接続でのみ有効にできます。
ターゲット Azure Synapse SQL データベースとプールを選択します。
Azure Synapse Link 接続の名前を指定し、リンク接続コンピューティングのコア数を選択します。 これらのコアは、ソースからターゲットへのデータの移動に使用されます。
注意
- ここで選択したコアの数は、データの読み込みと変更を処理するためにインジェスト サービスに割り当てられます。 ソース Azure SQL Database 構成やターゲット専用 SQL プールの構成には影響しません。
- 少ないコア数から始めて、必要に応じてコア数を増やすことをお勧めします。
[OK] を選択します。
新しい Azure Synapse Link 接続が開いた状態で、ターゲット テーブルの名前、配布の種類、構造の種類を更新できます。
注意
- データに varchar(max)、nvarchar(max)、varbinary(max) が含まれている場合は、構造の種類に "ヒープ テーブル" を使用することを検討してください。
- リンク接続を開始する前に、Azure Synapse SQL 専用プールにスキーマが既に作成されていることを確認します。 Azure Synapse Link for SQL では、Azure Synapse SQL 専用プールのスキーマの下にテーブルが自動的に作成されます。
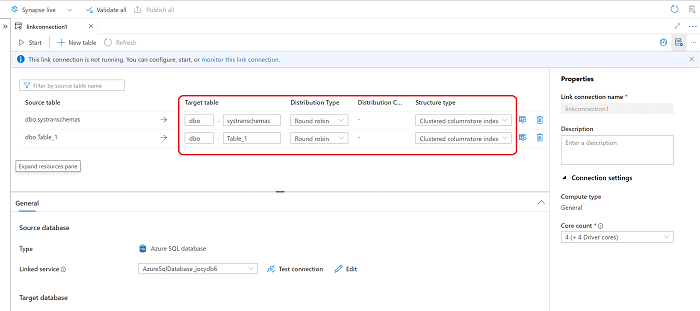
テーブルが宛先に既に存在する場合は、[既存のターゲット テーブルに対するアクション] ドロップダウン リストで、シナリオに最も適したオプションを選択します。
- テーブルを削除して再作成: 既存のターゲット テーブルが削除され、再作成されます。
- 空でないテーブルで失敗する: ターゲット テーブルにデータが含まれている場合、指定されたテーブルのリンク接続は失敗します。
- 既存のデータとのマージ: データは既存のテーブルにマージされます。
Note
[既存のデータとのマージ] を選択して複数のソースを同じ宛先にマージする場合は、競合や予期しない結果を避けるために、ソースに異なるデータが含まれていることを確認します。
テーブル間のトランザクション整合性を有効にするかどうかを指定します。
- このオプションを有効にすると、ソース データベース上の複数のテーブルにまたがるトランザクションは、常に 1 つのトランザクションでコピー先データベースにレプリケートされます。 ただし、これにより、レプリケーションの全体的なスループットにオーバーヘッドが生じます。
- このオプションを無効にすると、各テーブルの変更は、独自のトランザクション境界内で並列接続で宛先にレプリケートするため、レプリケーションの全体的なスループットが向上します。
Note
テーブル間でトランザクションの一貫性を保つには、Synapse 専用 SQL プールのトランザクション分離レベルが Read Committed スナップショット分離であることも確認してください。
[すべて公開] を選択し、サービスに対する新しいリンク接続を保存します。

Azure Synapse Link 接続を開始する
[開始] を選択して数分待つと、データがレプリケートされます。
注意
リンク接続は、ソース データベースからの完全な初期読み込みから始まり、Azure SQL Database の変更フィード機能を介した増分変更フィードが続きます。 詳細については、「Azure Synapse Link for SQL 変更フィード」を参照してください。
Azure Synapse Link 接続の状態を監視する
Azure Synapse Link 接続の状態を監視し、最初にコピーされるテーブル ("スナップショット") の確認や、継続レプリケーション モードのテーブル ("レプリケート") を確認できます。
[監視] ハブに移動し、[リンク接続] を選びます。
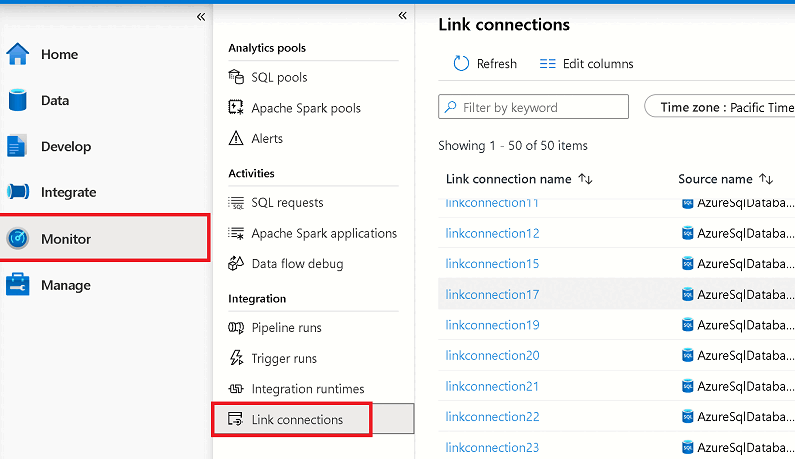
開始した Azure Synapse Link 接続を開き、各テーブルの状態を表示します。
接続の監視ビューで [最新の情報に更新] を選択して、状態が更新を確認します。
レプリケートされたデータにクエリを実行する
数分待ってから、予期されるテーブルとデータがターゲット データベースにあることを確認します。 ここで、ターゲット Azure Synapse SQL 専用プール内のレプリケートされたテーブルを調べることもできます。
[データ] ハブの [ワークスペース] で、ターゲット データベースを開きます。
[テーブル] でターゲット テーブルのいずれかを右クリックします。
[新しい SQL スクリプト] を選択してから [上位 100 行] を選びます。
このクエリを実行して、ターゲット Azure Synapse SQL 専用プール内のレプリケートされたデータを表示します。
SSMS またはその他のツールを使用してターゲット データベースにクエリを実行することもできます。 ワークスペースの SQL 専用エンドポイントをサーバー名として使用します。 この名前は通常、
<workspacename>.sql.azuresynapse.netです。 SSMS またはその他のツール経由で接続するときには、追加の接続文字列パラメーターとしてDatabase=databasename@poolnameを追加します。
既存の Azure Synapse Link 接続のテーブルを追加または削除する
Synapse Studio でテーブルを追加または削除するには、次の操作を行います。
[統合] ハブを開きます。
編集するリンク接続を選択して開きます。
以下のいずれかを実行します。
- テーブルを追加するには、[新しいテーブル] を選びます。
- テーブルを削除するには、その横にあるごみ箱アイコンを選びます。

注意
リンク接続が実行されているときに、直接、テーブルを追加または削除できます。

Azure Synapse Link 接続を停止する
Synapse Studio で Azure Synapse Link 接続を停止するには、次の操作を行います。
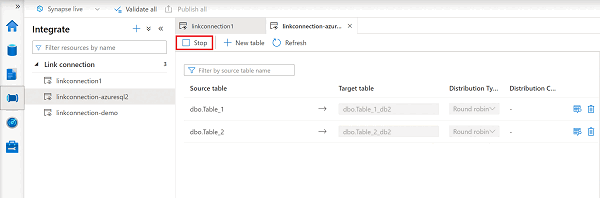
Azure Synapse ワークスペースで、[統合] ハブを開きます。
編集するリンク接続を選択して開きます。
[停止] を選択してリンク接続を停止すると、データのレプリケートが停止します。
Note
- リンク接続を停止した後に再び開始すると、ソース データベースからの完全な初期読み込みから開始され、次に増分変更フィードが行われます。
- 既存のターゲット テーブルに対するアクションとして [既存のデータとのマージ] を選択した場合、リンク接続を停止して再起動すると、その期間中にソースで削除されたレコードは宛先では削除されません。 このような場合、データの整合性を確保するには、停止/開始ではなく一時停止/再開を使用するか、リンク接続を再起動する前に宛先テーブルをクリーンアップすることを検討してください。