セキュリティ インシデント対応に関する推奨事項
Azure Well-Architected フレームワーク セキュリティ チェックリストの推奨事項に適用されます。
| SE:12 | 局所的な問題からディザスター リカバリーまで、さまざまなインシデントをカバーする効果的なインシデント対応手順を定義してテストします。 手順を実行するチームまたは個人を明確に定義します。 |
|---|
このガイドでは、ワークロードに対するセキュリティ インシデント対応を実装するための推奨事項について説明します。 システムのセキュリティが侵害された場合、体系的なインシデント対応アプローチに従うことで、セキュリティ インシデントの特定、管理、軽減にかかる時間を短縮できます。 これらのインシデントは、ソフトウェア システムとデータの機密性、整合性、可用性を脅かす可能性があります。
ほとんどの企業には、中央セキュリティ オペレーション チーム (セキュリティ オペレーション センター (SOC) または SecOps とも呼ばれます) があります。 セキュリティ オペレーション チームの責任は、潜在的な攻撃を迅速に検出し、優先順位を付け、トリアージすることです。 このチームは、セキュリティ関連のテレメトリ データを監視し、セキュリティ侵害を調査します。
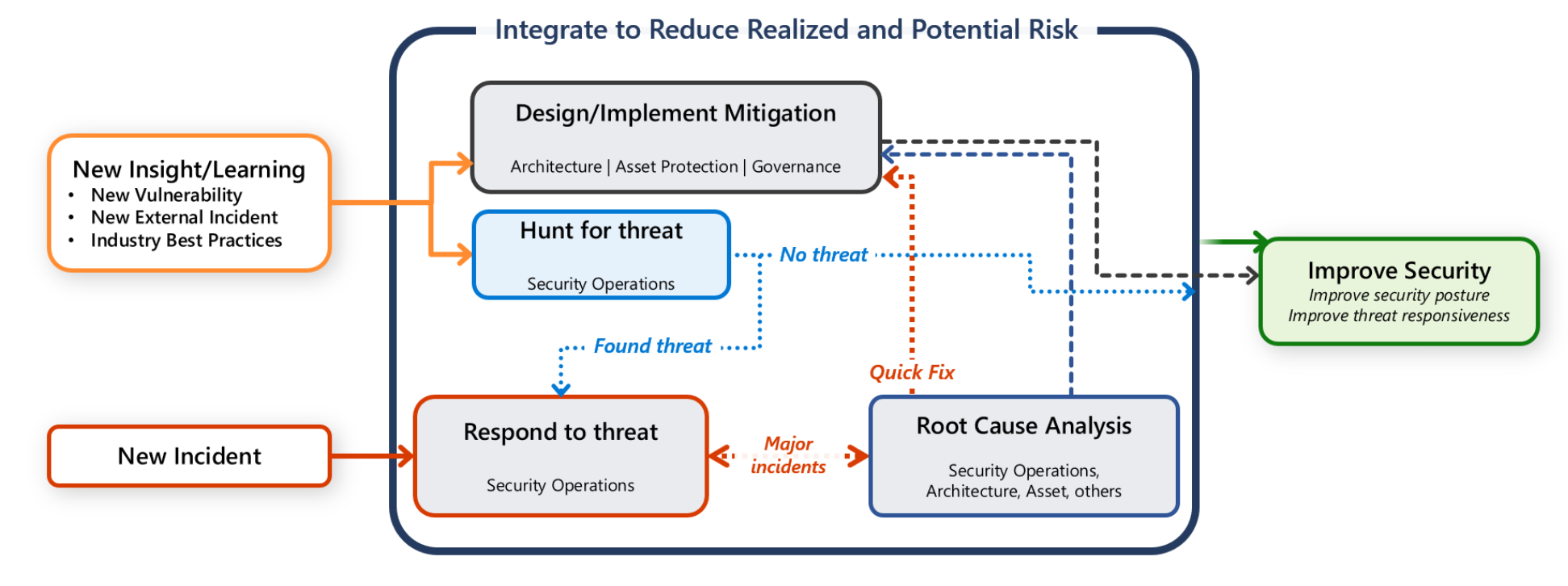
ただし、ワークロードを保護する責任もあります。 あらゆるコミュニケーション、調査、ハンティング アクティビティは、ワークロード チームと SecOps チームの共同作業であることが重要です。
このガイドでは、攻撃を迅速に検出、トリアージ、調査できるように、お客様とそのワークロード チーム向けの推奨事項を示します。
定義
| 相談 | 定義 |
|---|---|
| アラート | インシデントに関する情報を含む通知。 |
| アラートの忠実度 | アラートを決定するデータの精度。 忠実度の高いアラートには、直ちに対応するために必要なセキュリティ コンテキストが含まれています。 忠実度の低いアラートは、情報が不足しているか、ノイズが含まれています。 |
| 偽陽性 | 発生しなかったインシデントを示すアラート。 |
| インシデント | システムへの未承認アクセスを示すイベント。 |
| インシデント対応 | インシデントに関連するリスクを検出し、対応し、軽減するプロセス。 |
| トリアージ | セキュリティの問題を分析し、その軽減策に優先順位を付けるインシデント対応操作。 |
主要な設計戦略
侵害の可能性のシグナルまたはアラートがあった場合、お客様とそのチームはインシデント対応操作を実行します。 忠実度の高いアラートには、アナリストが意思決定を下すのに役立つ十分なセキュリティ コンテキストが含まれています。 忠実度の高いアラートでは、擬陽性の数が少なくなります。 このガイドでは、アラート システムが忠実度の低いシグナルをフィルター処理し、実際のインシデントを示す可能性のある忠実度の高いアラートに焦点を当てていることを前提としています。
インシデント通知の連絡先を指定する
セキュリティ アラートは、チームおよび組織内の適切な人物に届く必要があります。 インシデント通知を受け取るために、ワークロード チームに連絡先を指定します。 これらの通知には、侵害されたリソースとシステムに関するできるだけ多くの情報が含まれている必要があります。 チームが迅速に対応できるよう、アラートには次の手順を含める必要があります。
監査証跡を保持する専用のツールを使用して、インシデントの通知と対応をログに記録して管理することをお勧めします。 標準ツールを使用することで、潜在的な法的調査に必要となる可能性のある証拠を保存できます。 責任を負う当事者の責任に基づいて通知を送信可能な自動化を実装する機会を探します。 インシデント発生時のコミュニケーションと報告の明確なチェーンを維持します。
組織によって用意されたセキュリティ情報イベント管理 (SIEM) ソリューションとセキュリティ オーケストレーション自動応答 (SOAR) ソリューションを活用します。 または、インシデント管理ツールを調達し、すべてのワークロード チームに対してそれらを標準化するよう組織に促すこともできます。
トリアージ チームで調査する
インシデント通知を受け取ったチーム メンバーは、利用可能なデータに基づいて適切な担当者を関与させるトリアージ プロセスを設定する責任があります。 トリアージ チーム (多くの場合、"ブリッジ チーム" とも呼ばれます) は、コミュニケーションのモードとプロセスについて合意する必要があります。 このインシデントには、非同期のディスカッションまたはブリッジ通話が必要ですか? チームは調査の進捗状況をどのように追跡し、伝える必要がありますか? チームはどこでインシデント資産にアクセスできますか?
インシデント対応では、システムのアーキテクチャ レイアウト、コンポーネント レベルでの情報、プライバシーまたはセキュリティの分類、所有者、主要連絡先など、ドキュメントを最新の状態に保つことが重要です。 情報が不正確または古い場合、ブリッジ チームは、システムがどのように機能するか、各領域の責任者は誰か、イベントの影響は何かなどを理解しようとして貴重な時間を無駄にします。
さらに調査を進めるには、適切な人物を関与させます。 インシデント マネージャー、セキュリティ責任者、またはワークロード中心のリードを含めることができます。 トリアージを集中的に行うために、問題の範囲外の人物を除外します。 場合によっては、個別のチームがインシデントを調査します。 最初に問題を調査してインシデントの軽減を試みるチームと、広範な問題を特定するために詳細な調査を行うフォレンジックを実行する別の専門チームが存在する可能性があります。 ワークロード環境を隔離して、フォレンジック チームが調査を行えるようにすることができます。 場合によっては、同じチームが調査全体を担当することもあります。
初期フェーズでは、トリアージ チームは潜在的なベクトルと、それがシステムの機密性、整合性、可用性 (CIA とも呼ばれます) に与える影響を判断する責任を負います。
CIA のカテゴリ内で、損害の深刻度と修復の緊急性を示す初期重大度レベルを割り当てます。 トリアージのレベルでさらに多くの情報が検出されるため、このレベルは時間の経過とともに変化することが予想されます。
検出フェーズでは、即時の一連の対応およびコミュニケーション計画を決定することが重要です。 システムの実行状態に変化はありますか? さらなる悪用を阻止するために、どのようにしたら攻撃を封じ込めることができますか? チームは、責任ある開示など、社内外にコミュニケーションを発信する必要がありますか? 検出および対応の期間を考慮します。 侵害の種類によっては、特定の期間 (通常は数時間または数日間) 内に規制当局に報告することが法的に義務付けられている場合があります。
システムをシャットダウンする場合は、次の手順でワークロードのディザスター リカバリー (DR) プロセスに進みます。
システムをシャットダウンしない場合は、システムの機能に影響を与えずにインシデントを修復する方法を決定します。
インシデントから復旧する
セキュリティ インシデントを障害と同様に扱います。 修復に完全復旧が必要がな場合は、セキュリティの観点から適切な DR メカニズムを使用します。 復旧プロセスでは、再発の可能性を防ぐ必要があります。 そうしないと、破損したバックアップから復旧することで問題が再発します。 同じ脆弱性を持つシステムを再展開すると、同じインシデントが発生します。 フェールオーバーとフェールバックの手順とプロセスを検証します。
システムが引き続き機能している場合は、システムの実行部分に対する影響を評価します。 適切なデグレード プロセスを実施して、他の信頼性とパフォーマンスの目標が達成または再調整されるようシステムの監視を継続します。 軽減策のためにプライバシーを侵害しないでください。
診断は、ベクトル、および修正とフォールバックの可能性が特定されるまでの対話型プロセスです。 診断後、チームは修復に取り組み、許容期間内に必要な修正を特定して適用します。
復旧メトリックは、問題の解決にかかる時間を測定します。 シャットダウンが発生した場合、修復時間に関して緊急性が生じる可能性があります。 システムを安定させるために、修正、パッチ、テストを適用し、更新プログラムを展開する場合は時間がかかります。 さらなる損害とインシデントの拡大を防ぐための封じ込め戦略を決定します。 環境から脅威を完全に取り除くための根絶手順を開発します。
トレードオフ: 信頼性の目標と修復時間の間にはトレードオフがあります。 インシデント発生中は、他の非機能要件または機能要件を満たしていない可能性があります。 たとえば、インシデント調査中は、システムの一部を無効にしたり、インシデントの範囲を特定するまでシステム全体をオフラインにしたりする必要がある場合があります。 ビジネスの意思決定者は、インシデント中に許容される目標を明示的に決定する必要があります。 その決定に対して責任を負う人物を明確に指定します。
インシデントから学ぶ
インシデントにより、設計や実装におけるギャップや脆弱な点が明らかになります。 これは、技術的な設計面、自動化、テストを含む製品開発プロセス、およびインシデント対応プロセスの有効性に関する教訓によってもたらされる改善の機会です。 実施した対応、タイムライン、結果など、詳細なインシデント レコードを管理します。
根本原因分析や振り返りなど、構造化されたインシデント事後レビューを実施することを強くお勧めします。 これらのレビューの結果を追跡して優先順位を付け、学んだ内容を将来のワークロード設計に使用することを検討します。
改善計画には、事業継続とディザスター リカバリー (BCDR) 訓練などのセキュリティ訓練とテストの更新が含まれている必要があります。 BCDR 訓練を実施するためのシナリオとして、セキュリティ侵害を使用します。 訓練では、文書化されたプロセスがどのように機能するかを検証できます。 インシデント対応プレイブックは複数存在すべきではありません。 インシデントの規模と、影響がどの程度広範囲または局所的であるかに基づいて調整できる単一のソースを使用します。 訓練は仮定の状況に基づいて行われます。 リスクの低い環境で訓練を実施し、訓練に学習フェーズを含めます。
インシデントの事後レビュー (事後検証) を実施して、対応プロセスの弱点と改善すべき領域を特定します。 インシデントから学んだ教訓に基づいて、インシデント対応計画 (IRP) とセキュリティ コントロールを更新します。
コミュニケーション計画の定義
ユーザーに中断を通知し、修復と改善について内部関係者に知らせるためのコミュニケーション プランを実装します。 将来のインシデントを防ぐために、組織内の他のユーザーにワークロードのセキュリティ ベースラインに対する変更を通知する必要があります。
社内使用のため、また必要に応じて規制コンプライアンスや法的な目的のためにインシデント レポートを生成します。 また、SOC チームがすべてのインシデントに使用する標準形式レポート (セクションが定義されたドキュメント テンプレート) を採用します。 調査を終了する前に、すべてのインシデントにレポートが関連付けられていることを確認します。
Azure ファシリテーション
Microsoft Sentinel は、SIEM および SOAR ソリューションです。 これは、アラートの検出、脅威の可視性、予防的なハンティング、脅威への対応のための単一ソリューションです。 詳細については、「Microsoft Sentinel とは」を参照してください。
内部プロセスを通じてセキュリティ オペレーションが直接通知されるように、Azure 登録ポータルに管理者の連絡先情報が含まれていることを確認します。 詳細については、「通知設定を更新する」を参照してください。
Microsoft Defender for Cloud から Azure インシデント通知を受信する連絡先を指定する方法の詳細については、「セキュリティ アラートの電子メール通知を構成する」を参照してください。
組織の配置
Azure のクラウド導入フレームワークでは、インシデント対応の計画とセキュリティ オペレーションに関するガイダンスが提供されます。 詳細については、「セキュリティ運用」を参照してください。
関連リンク
- Microsoft セキュリティ アラートからインシデントを自動的に作成する
- ハント機能を使用してエンドツーエンドの脅威ハンティングを実施する
- セキュリティ アラートの電子メール通知を構成する
- インシデント対応の概要
- Microsoft Azure Incident Readiness
- Microsoft Sentinel でのインシデントの確認と調査
- セキュリティ コントロール: インシデント対応
- Microsoft Sentinel の SOAR ソリューション
- トレーニング: Azure Incident Readiness の概要
- Azure portal の通知設定を更新する
- SOC とは
- Microsoft Sentinel とは
セキュリティ チェックリスト
レコメンデーションの完全なセットを参照してください。