部分的なエラーを処理する
ヒント
このコンテンツは eBook の「コンテナー化された .NET アプリケーションの .NET マイクロサービス アーキテクチャ」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

マイクロサービスベースのアプリケーションのような分散システムでは、部分的なエラーが発生するリスクが常にあります。 たとえば、単一のマイクロサービス/コンテナーでエラーが発生する場合、短時間応答できない場合、単一の VM またはサーバーがクラッシュする場合があります。 クライアントとサービスは別のプロセスなので、サービスがクライアントの要求に迅速に応答できないことがあります。 サービスが過負荷になり、要求への応答が非常に遅くなる場合や、ネットワークの問題のために短時間アクセスできなくなる場合があります。
eShopOnContainers サンプル アプリケーションの [Order details](注文の詳細) ページを例にして考えてみましょう。 ユーザーが発注しようとしたときに発注マイクロサービスが応答しない場合、クライアント プロセスの不適切な実装 (MVC Web アプリケーション) では、たとえばクライアント コードがタイムアウトのない同期 RPC を使用する場合などに、応答を無期限に待機するスレッドがブロックされます。 不適切なユーザー エクスペリエンスが作り出されるだけでなく、応答しない待機が発生するたびにスレッドが消費またはブロックされます。また、スケーラブルなアプリケーションでは、スレッドは非常に重要です。 ブロックされたスレッドが多数発生すると、最終的にはアプリケーションの実行時にスレッドが不足する可能性があります。 その場合、図 8-1 に示すように、アプリケーションは部分的に応答しなくなるのではなく、全体的に応答しなくなる可能性があります。
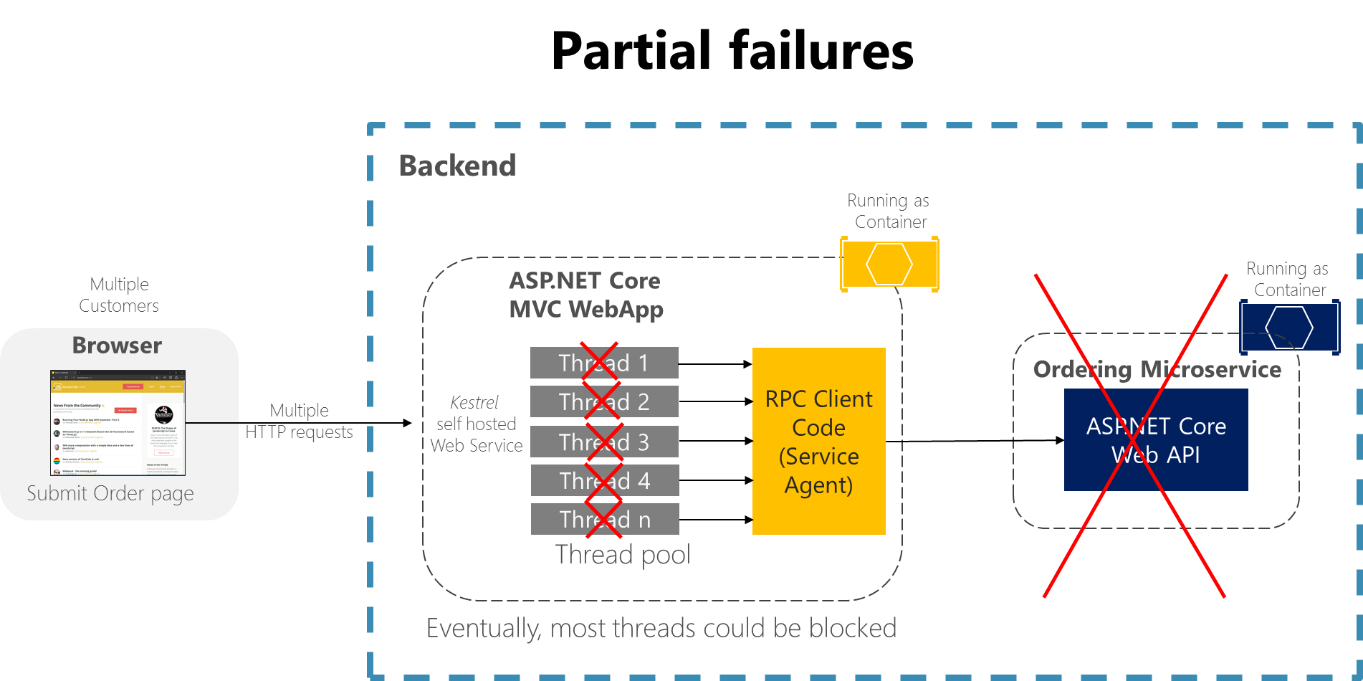
図 8-1。 サービス スレッドの可用性に影響する依存関係が原因の部分的なエラー
大規模なマイクロサービスベースのアプリケーションでは、部分的なエラーが拡大する可能性があります。特に、内部マイクロサービスの相互作用のほとんどが同期 HTTP 呼び出し (アンチパターンと見なされます) に基づいている場合は拡大する可能性があります。 1 日あたり何百万もの着信を受け取るシステムについて考えてみましょう。 同期 HTTP 呼び出しの長いチェーンに基づいているような不適切な設計のシステムの場合、このような着信の結果、同期の依存関係として数百万の発信が数十の内部マイクロサービスに対して行われる可能性があります (たとえば、1:4 の比率としましょう)。 この状況は、図 8-2、特に依存関係 #3 で示されています。これは、チェーンを開始し、依存関係 #4 を呼び出して、#5 を呼び出します。
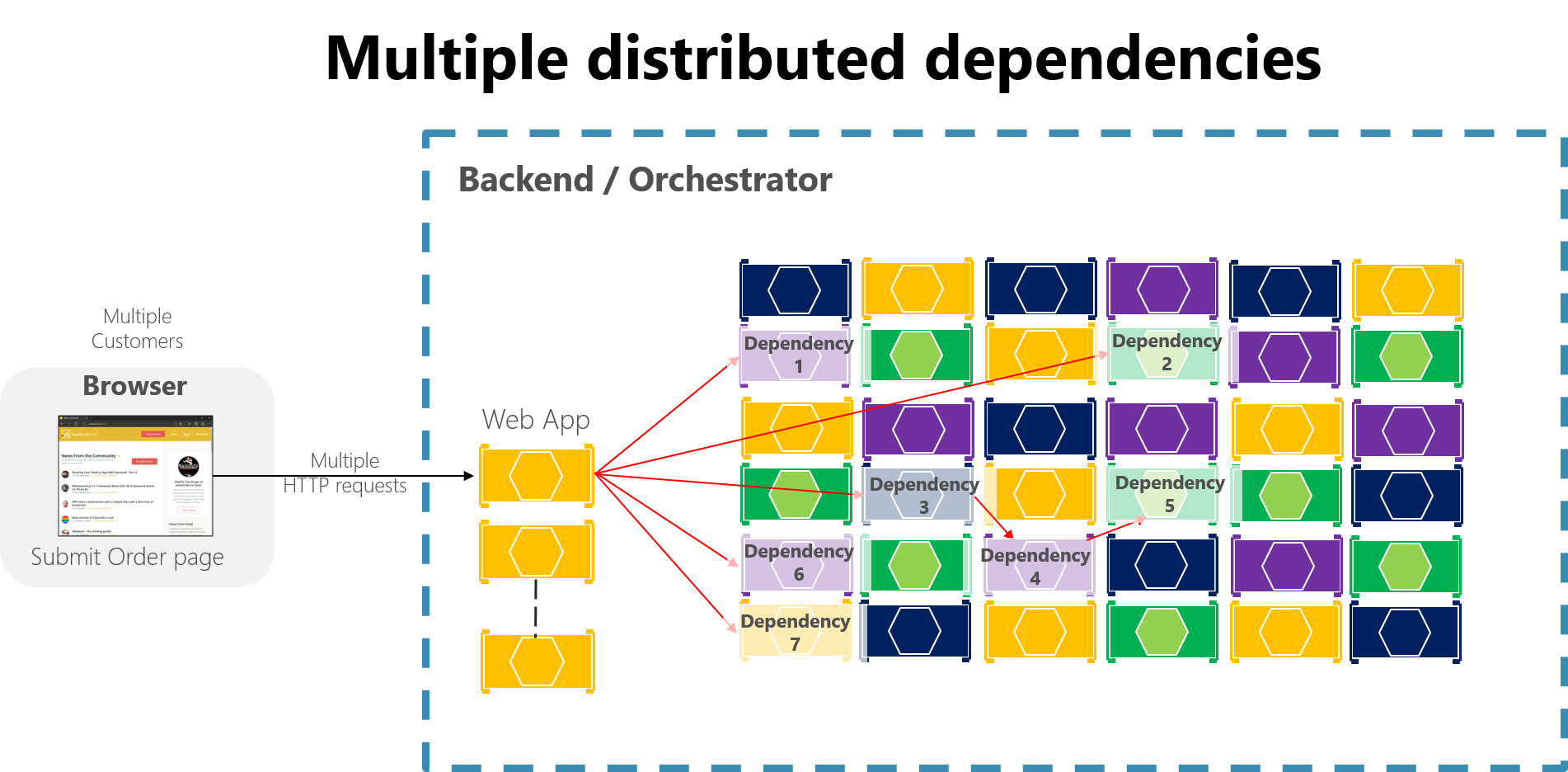
図 8-2。 HTTP 要求の長いチェーンが特徴の不適切な設計の影響
分散型のクラウド ベースのシステムでは、すべての依存関係自体に優れた可用性がある場合でも、断続的なエラーは必ず発生します。 この点を考慮する必要があります。
フォールト トレランスを確保するための手法を設計および実装していない場合は、たとえ短時間のダウンタイムであっても増幅する可能性があります。 たとえば、可用性がそれぞれ 99.99% の依存関係が 50 個ある場合、この波及効果のために毎月数時間のダウンタイムが発生します。 マイクロサービスの依存関係が大量の要求を処理しているときにエラーが発生すると、そのエラーによって各サービスのすべての使用可能な要求スレッドが短時間で飽和状態になり、アプリケーション全体がクラッシュする可能性があります。
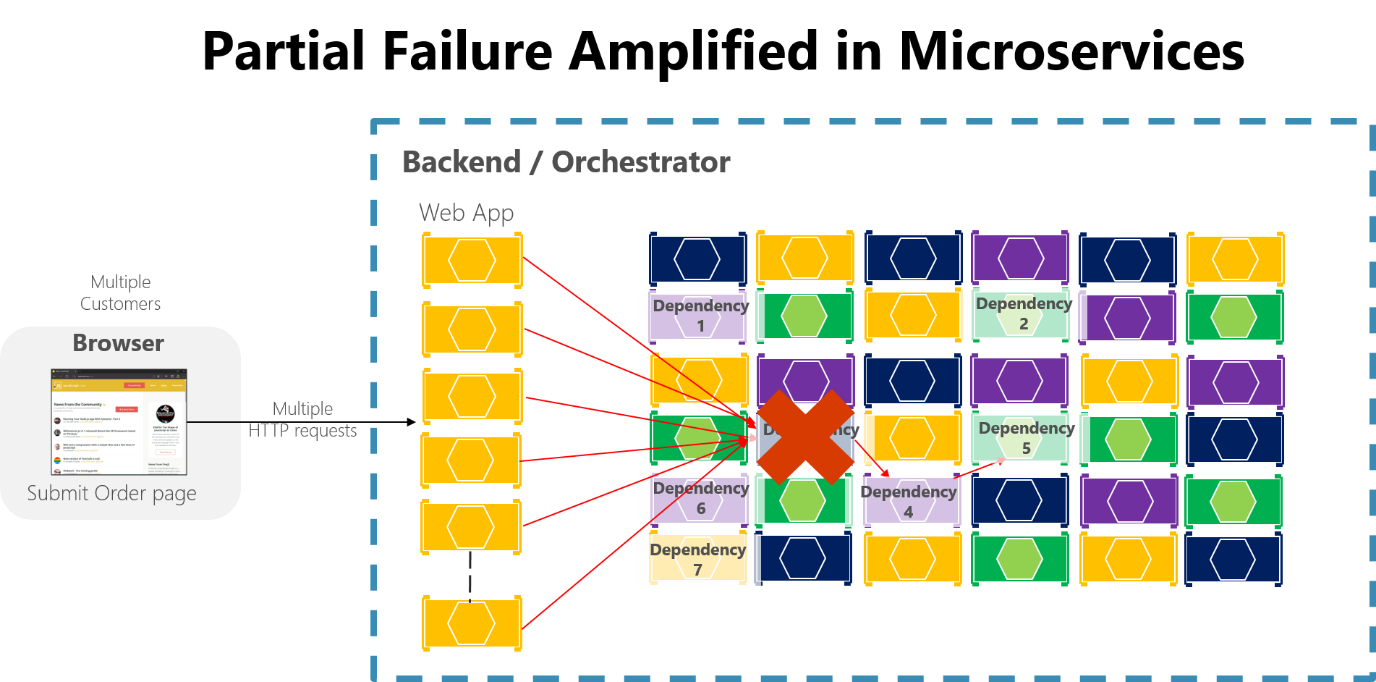
図 8-3。 同期 HTTP 呼び出しの長いチェーンがあるマイクロサービスによって増幅される部分的なエラー
この問題を最小限に抑えるために、このガイドの「マイクロ サービスの自律性を強制する非同期マイクロ サービスの統合」セクションでは、内部のマイクロサービス全体で非同期通信を使用することをお勧めしています。
さらに、部分的なエラーを処理する (つまり、回復力のあるマイクロサービスとクライアント アプリケーションを構築する) ようにマイクロサービスとクライアント アプリケーションを設計することが不可欠です。
.NET