AI で類似の顧客を見つける (プレビュー)
[この記事はプレリリース ドキュメントであり、変更されることがあります。]
人工知能を使用して、顧客ベースで同様の顧客を見つけます。 この機能を使用するには、少なくとも 1 つのセグメントを作成する必要があります。 既存のセグメントの基準を拡張することで、そのセグメントに類似した顧客を見つけることができます。
Note
類似する顧客を見つけるは、自動化された手段を使用してデータを評価し、そのデータに基づいて予測を行います。 したがって、プロファイリング手法として使用する機能があり、この条件はさまざまなプライバシー法と規制によって定義されています。 お客様がこの機能を使用してデータを処理する場合、これらの法律や規制の対象になる可能性があります。 お客様は、予測を含む Dynamics 365 Customer Insights - Data の使用が、プライバシー、個人データ、生体認証データ、データ保護、通信の秘密保持に関連する法律を含む、適用されるすべての法律および規制に準拠していることを確認する責任があります。
類似する顧客を見つける
分析情報>セグメント を選択して、新規セグメントのベースにしたいセグメントを選択します。 ご利用のソース セグメントが最適でしょう。
類似する顧客を見つけるを選択します。
新たなセグメントの推奨名を確認し、必要に応じて変更します。
オプションで、タグを新しいセグメントに追加します。
新たなセグメントを定義するフィールドを確認します。 これらのフィールドは、システムがソース セグメントに類似する顧客を見つけようとする基準の定義を行います。 システムは既定で推奨フィールドを選択します。 必要に応じてフィールドを追加します。 モデルのパフォーマンスを大きく低下させる可能性があるフィールドは、自動的に除外されます。
- 次のデータ型のフィールドです : StringType、BooleanType、CharType、LongType、IntType、DoubleType、FloatType、ShortType
- カーディナリティ (フィールド内の要素数) が2未満、または30を超えるフィールド
ソース セグメントを除くすべての顧客を含めるか、新たなセグメントの異なるセグメントの顧客のみを含めるかを選択します。
既定では、システムはターゲットの対象ユーザーの全体の 20% のみを出力に含めることを推奨しています。 必要に応じてこのしきい値を編集してください。 しきい値を大きくすると、精度が低下します。
ソース セグメントの顧客を含めるには、類似の属性を持つ顧客に加えて、ソース セグメントのメンバーを含めるチェック ボックスをオンにします。
ページの下部で実行を選択し、データセットを分析する二項分類タスク (機械学習のメソッド) を開始します。
類似するセグメントを表示する
類似するセグメントを処理した後、新たなセグメントが、展開 タイプを持つ 分析情報>セグメント ページにリスト表示されます。
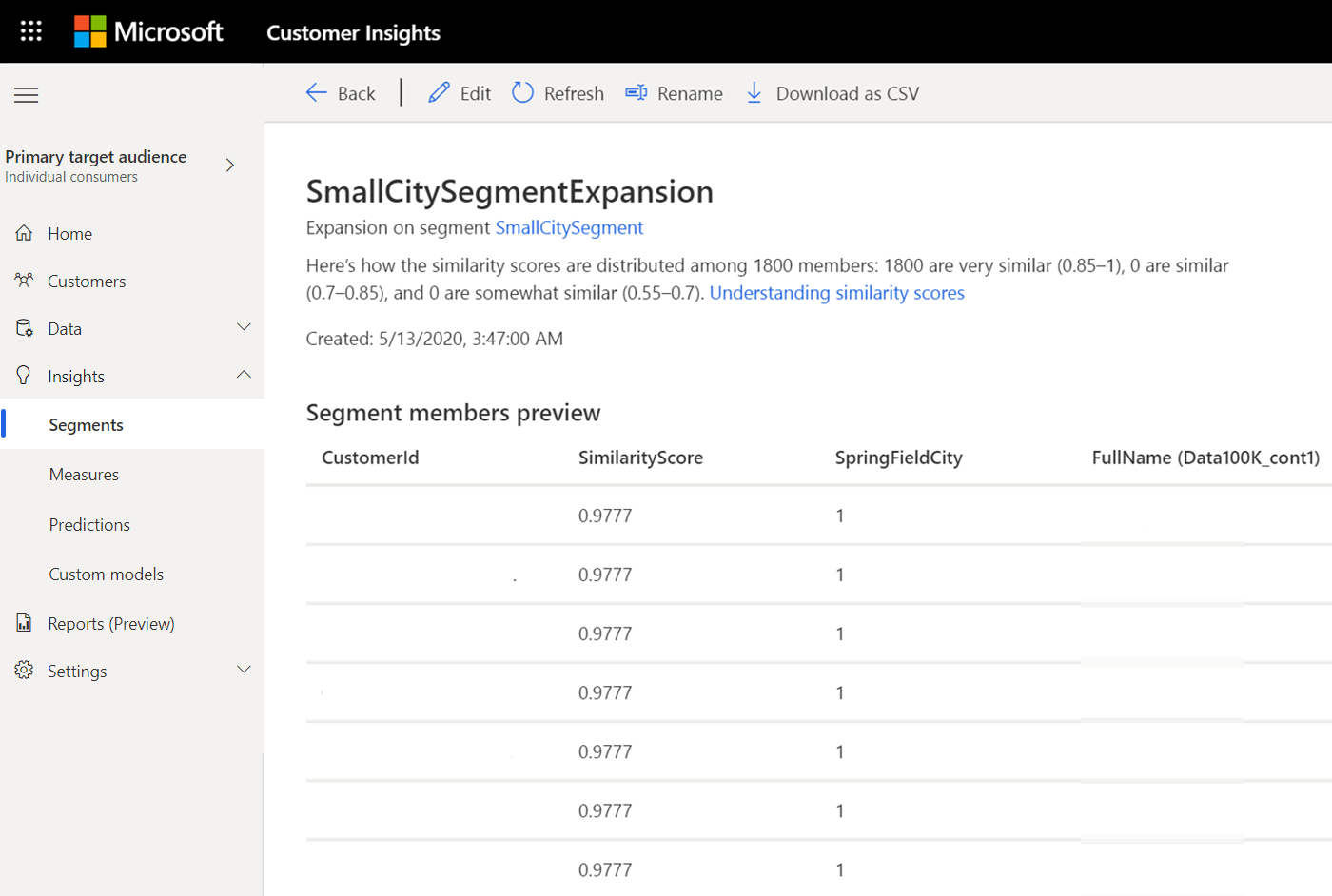
表示を選択し、セグメント メンバーのプレビューで、類似スコア における結果の分布と、類似性スコア値を確認します。。
類似したセグメントの管理
他のセグメントと同じように、類似するセグメントを使用して管理します。 たとえば、セグメントのエクスポート、またはメジャーを作成します。
類似するセグメントを編集、更新、名前変更、ダウンロード、削除します。 類似するセグメントを編集すると、データが再処理されます。 既に作成されているセグメントは、更新されたデータに基づいて更新されます。
類似性スコアについて
二項分類の機械学習モデルは、類似するセグメントの顧客に対してスコアを割り当てます。 このスコアは、ソース セグメント内の顧客との類似性に基づいています。
- 0.55 未満の類似性スコアは、システムがソース セグメントの顧客と 類似していない と分類した顧客です
- 0.55 ~ 0.7 の間の類似性スコアは、 やや類似していると分類されます
- 0.7 ~ 0.85 の間の類似性スコアは、 類似していると分類されます
- 0.85 ~ 1 の間の類似性スコアは、とても類似していると分類されます
類似性スコアが 0.4 未満の顧客はモデルの出力対象となりません。 システムは、これらソース セグメントと十分に類似していると見なしません。