dbt を使用したデータの変換
Note
Apache Airflow ジョブは、Apache Airflow を使用しています。
dbt (データ ビルド ツール) は、構造化された保守可能な方法で複雑な SQL コードを管理することにより、データ ウェアハウス内でのデータ変換とモデリングを簡略化するオープンソースのコマンド ライン インターフェイス (CLI) です。 これにより、データ チームは分析パイプラインの中核となる信頼性が高くテスト可能な変換を作成できます。
Apache Airflow と組み合わせると、dbt の変換機能が Airflow のスケジュール、オーケストレーション、タスク管理機能によって強化されます。 dbt の変換の専門知識と Airflow のワークフロー管理を組み合わせたこのアプローチは、効率的で堅牢なデータ パイプラインを実現し、最終的には、より迅速で洞察に富んだデータドリブンの意思決定につながります。
このチュートリアルでは、dbt を使用して Microsoft Fabric Data Warehouse に格納されているデータを変換する Apache Airflow DAG を作成する方法について説明します。
前提条件
開始するには、次の前提条件を満たしている必要があります。
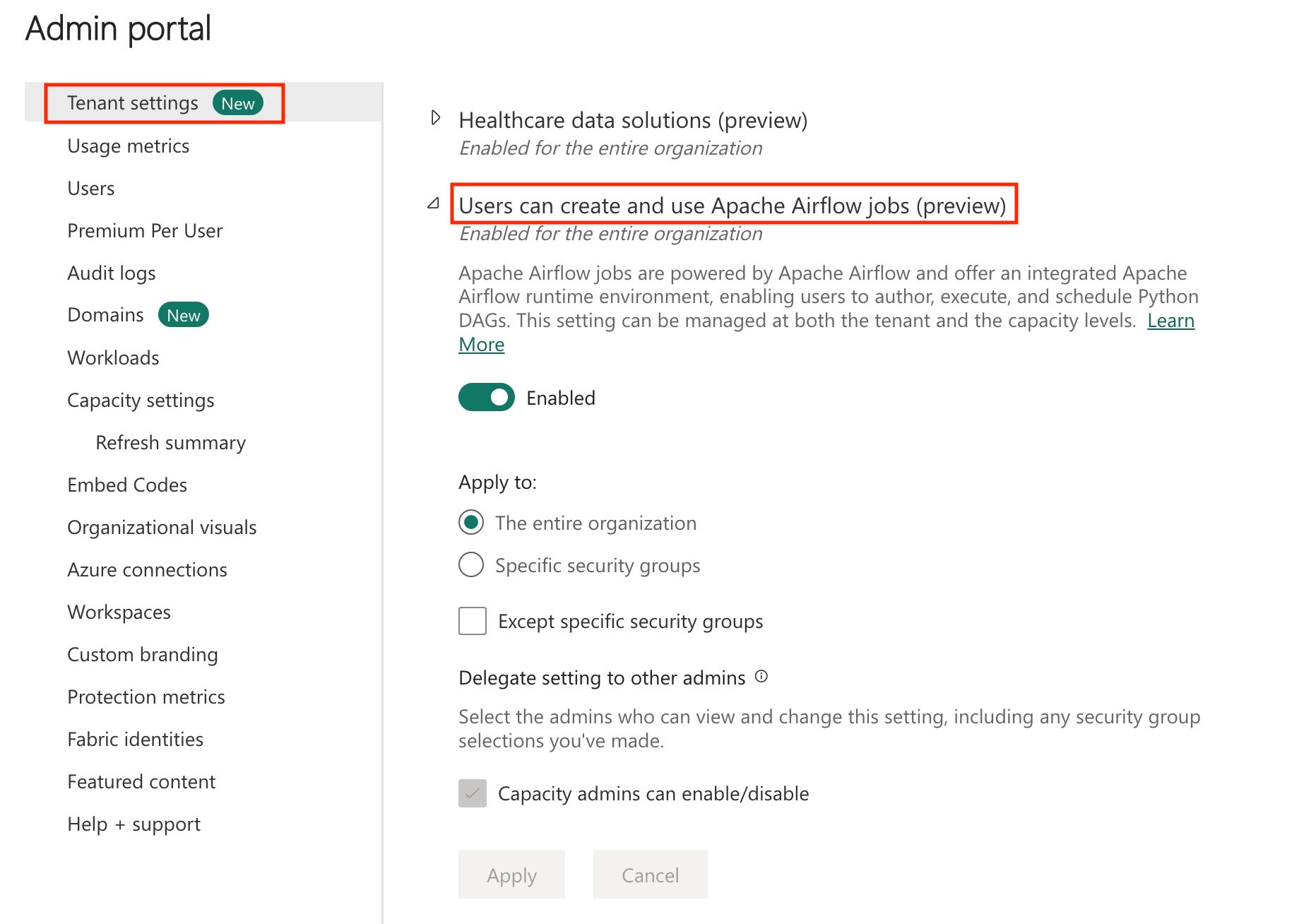
テナントで Apache Airflow ジョブを有効にします。
Note
Apache Airflow ジョブはプレビュー状態であるため、テナント管理者を通じて有効にする必要があります。Apache Airflow ジョブが既に表示されている場合は、テナント管理者が既に有効にしている可能性があります。
管理 ポータルに移動 -> [テナント設定] -> [Microsoft Fabric] の下 -> [ユーザーは Apache Airflow ジョブを作成して使用できます (プレビュー)] セクションを展開します。
適用を選択します。
サービス プリンシパルを作成します。 データ ウェアハウスを作成するワークスペースに、サービス プリンシパルを
Contributorとして追加します。用意していない場合は、Fabric Warehouse を作成します。 データ パイプラインを使用してウェアハウスにサンプル データを取り込みます。 このチュートリアルでは、NYC Taxi-Green サンプルを使用します。

dbt を使用して Fabric ウェアハウスに格納されているデータを変換します
このセクションでは、次の手順について説明します。
- 要件を指定します。
- Apache Airflow ジョブによって提供される Fabric マネージド ストレージに dbt プロジェクトを作成します。
- dbt ジョブを調整する Apache Airflow DAG を作成する
要件を指定する
dags フォルダー内にファイル requirements.txt を作成します。 Apache Airflow の要件として、次のパッケージを追加します。
astronomer-cosmos: このパッケージは、dbt コア プロジェクトを Apache Airflow dag およびタスク グループとして実行するために使用されます。
dbt-fabric: このパッケージは dbt プロジェクトの作成に使用され、その後、Fabric Data Warehouse にデプロイできます
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Apache Airflow ジョブによって提供される Fabric マネージド ストレージに dbt プロジェクトを作成します。
このセクションでは、次のディレクトリ構造を持つデータセット
nyc_taxi_greenの Apache Airflow ジョブにサンプル dbt プロジェクトを作成します。dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetdagsフォルダー内に、profiles.ymlファイルを使用して、nyc_taxi_greenという名前のファイルを作成します。 このフォルダーには、dbt プロジェクトに必要なすべてのファイルが含まれています。
次の内容を
profiles.ymlにコピーします。 この構成ファイルには、dbt によって使用されるデータベース接続の詳細とプロファイルが含まれています。 プレースホルダーの値を更新し、ファイルを保存します。config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>dbt_project.ymlファイルを作成し、次の内容をコピーします。 このファイルは、プロジェクト レベルの構成を指定します。name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tablenyc_taxi_greenフォルダーに、modelsフォルダーを作成します。 このチュートリアルでは、ベンダーごとに 1 日あたりの乗車数を示すテーブルを作成するnyc_trip_count.sqlという名前のファイルにサンプル モデルを作成します。 次のコンテンツをファイルにコピーします。with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


dbt ジョブを調整する Apache Airflow DAG を作成する
dagsフォルダーにmy_cosmos_dag.pyというファイルを作成し、それに次の内容を貼り付けます。import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
DAG を実行する
Apache Airflow ジョブ内で DAG を実行します。
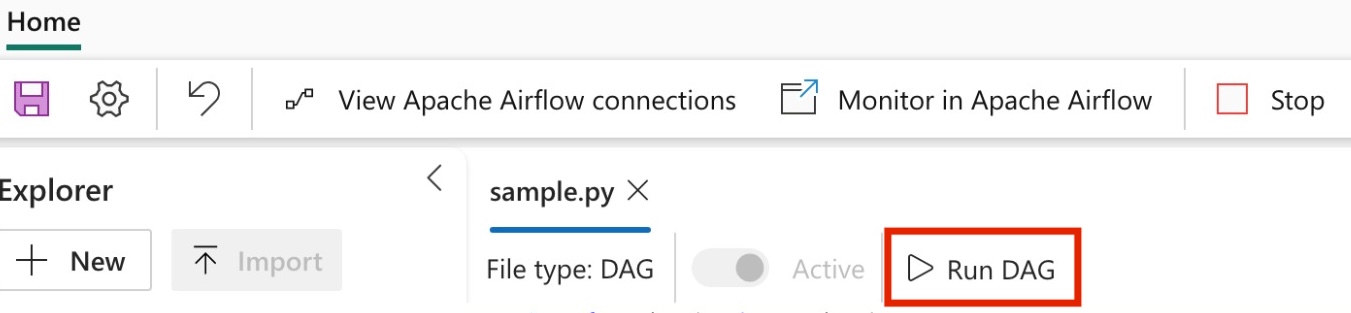
Apache Airflow UI に読み込まれた dag を表示するには、
Monitor in Apache Airflow.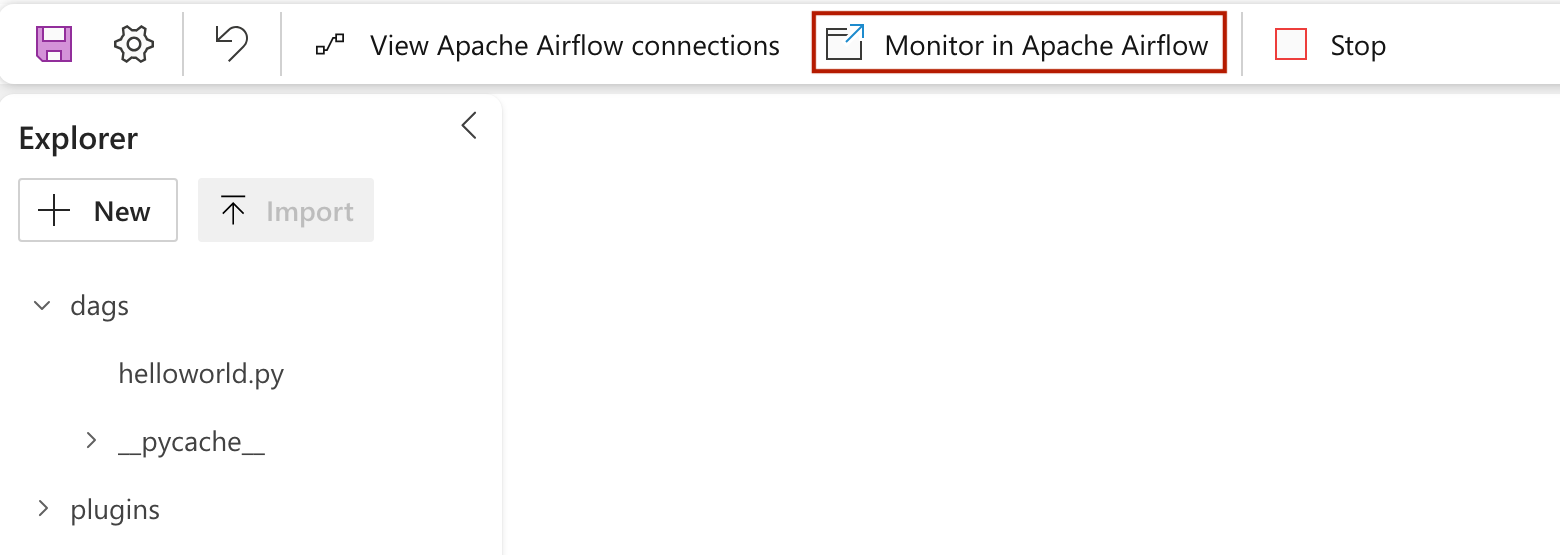
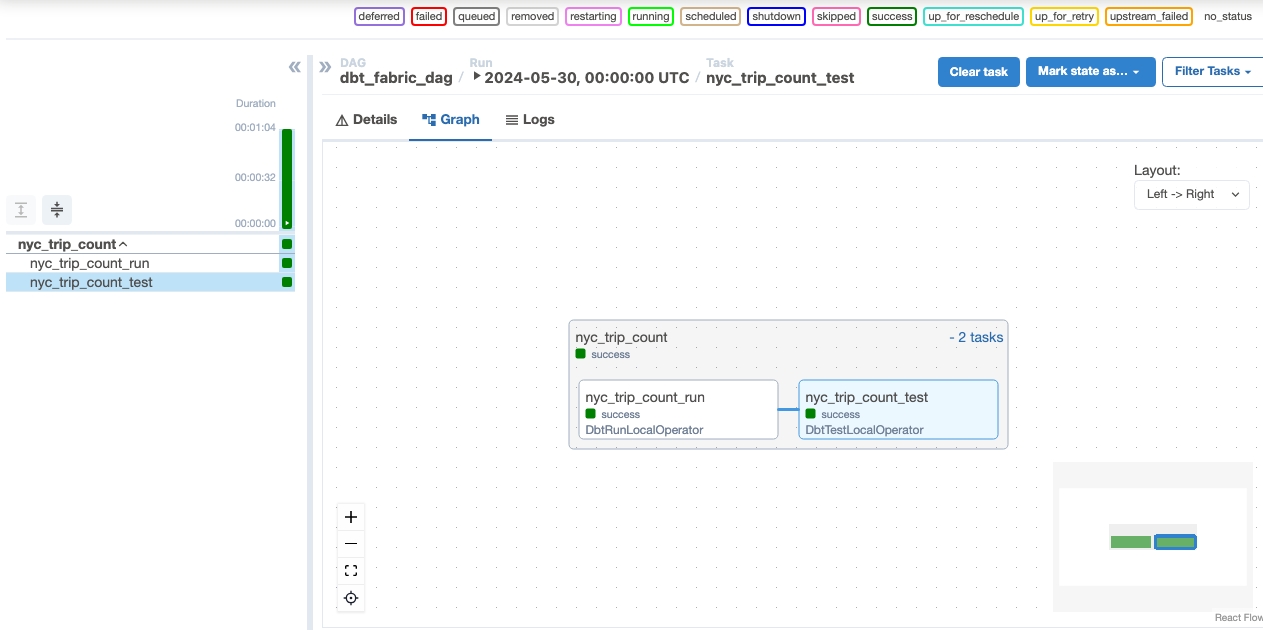 をクリックします
をクリックします



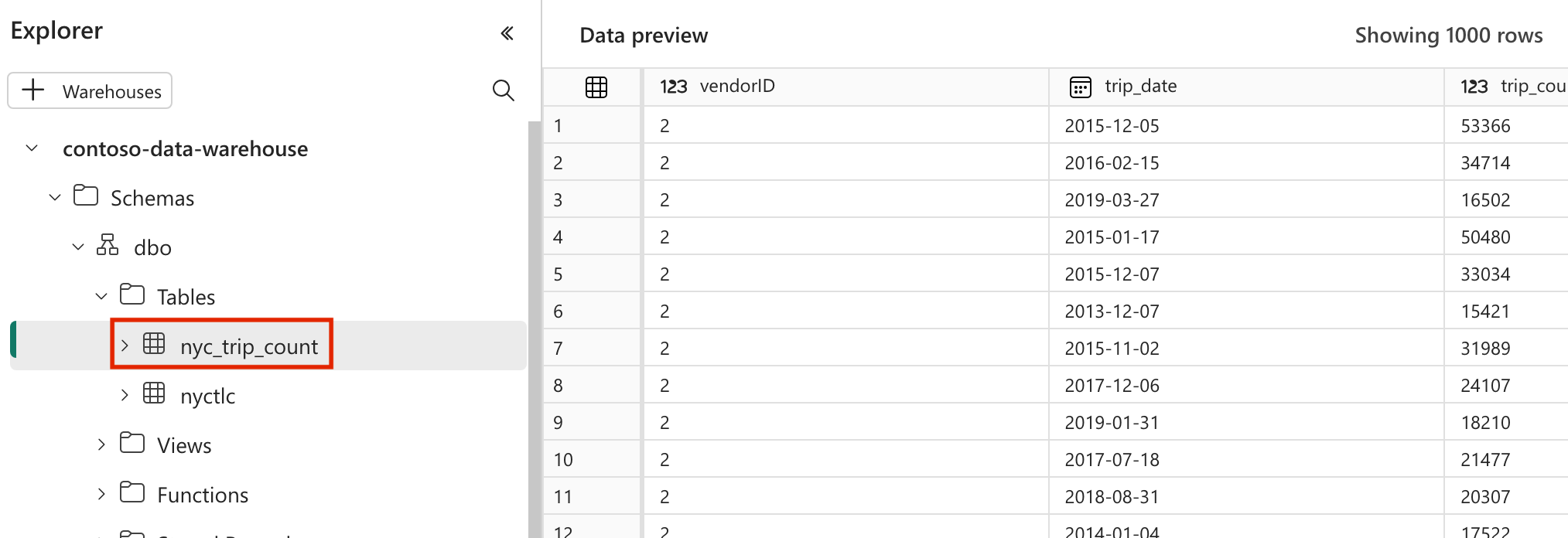
データを検証する
- 正常に実行されると、データを検証するために、Fabric データ ウェアハウスに作成された「nyc_trip_count.sql」という名前の新しいテーブルが表示されます。