Copy アクティビティで Amazon RDS for SQL Server を構成する方法
この記事では、データ パイプラインの Copy アクティビティを使用して、Amazon RDS for SQL Server との間でデータをコピーする方法について説明します。
サポートされている構成
Copy アクティビティの下の各タブの構成については、それぞれ次のセクションを参照してください。
全般
[全般設定] タブを構成するには、全般設定のガイダンスを参照してください。
ソース
Copy アクティビティの [ソース] タブの Amazon RDS for SQL Server では、次のプロパティがサポートされています。
![[ソース] タブとプロパティのリストを示すスクリーンショット。](media/connector-amazon-rds-for-sql-server/source.png)
次のプロパティは必須です。
[データ ストアの種類]: [外部] を選択します。
接続: 接続リストから [Amazon RDS for SQL Server] 接続を選択します。 接続が存在しない場合は、[新規] を選択して新しい Amazon RDS for SQL Server 接続を作成します。
接続の種類: Amazon RDS for SQL Server を選択します。
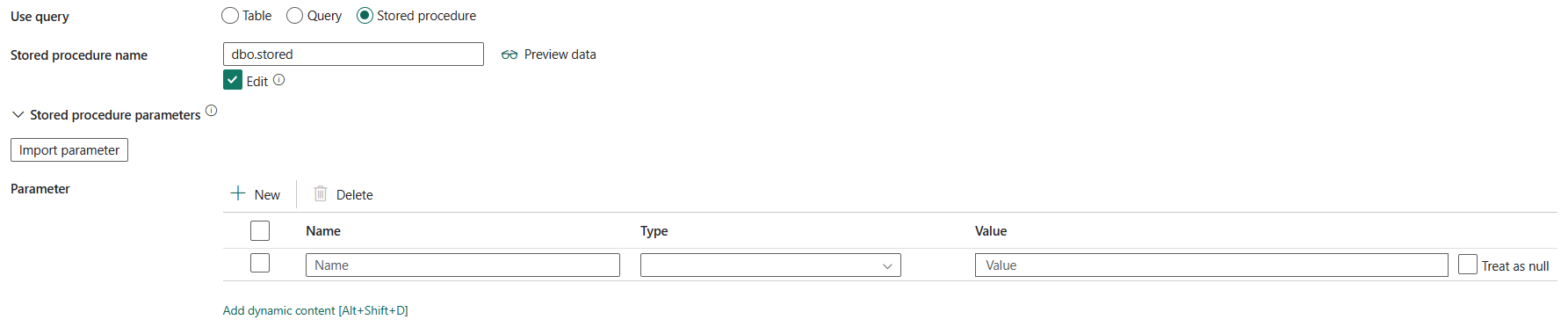
クエリの使用: データの読み取り方法を指定します。 [テーブル]、[クエリ]、または [ストアド プロシージャ] を選択できます。 次の一覧で、各設定の構成について説明します。
テーブル: 指定したテーブルからデータを読み取ります。 ドロップダウン リストからソース テーブルを選択するか、[編集] を選択して手動で入力します。
[クエリ]: カスタムの SQL クエリを使用してデータを読み取ります。 たとえば
select * from MyTableです。 または、鉛筆アイコンを選択してコード エディターで編集します。
[ストアド プロシージャ]: ストアド プロシージャを使用してソース テーブルからデータを読み取ります。 最後の SQL ステートメントはストアド プロシージャの SELECT ステートメントにする必要があります。
ストアド プロシージャ名: ストアド プロシージャを選択するか、[編集] を選択した場合はストアド プロシージャ名を手動で指定し、ソース テーブルからデータを読み取ります。
[ストアド プロシージャ パラメーター]: ストアド プロシージャ パラメーターの値を指定します。 使用可能な値は、名前または値のペアです。 パラメーターの名前とその大文字と小文字は、ストアド プロシージャのパラメーターの名前とその大文字小文字と一致する必要があります。 [インポート パラメーター] を選択して、ストアド プロシージャ パラメーターを取得できます。
[詳細設定] では、次のフィールドを指定できます。
[クエリ タイムアウト (分)]: クエリ コマンド実行時のタイムアウト時間を指定します。既定値は 120 分です。 このプロパティにパラメーターを設定する場合は、「02:00:00」(120 分) などの期間の値が使用できます。
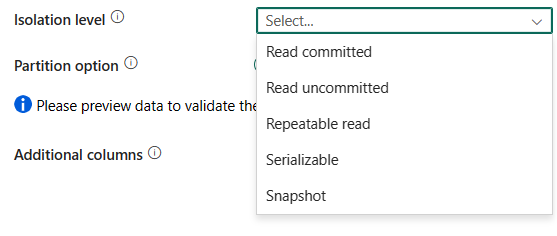
[分離レベル]: SQL ソースのトランザクション ロック動作を指定します。 許可される値は、Read committed、Read uncommitted、Repeatable read、Serializable、Snapshot のいずれかです。 指定しなかった場合は、データベースの既定の分離レベルが使用されます。 詳細については、「IsolationLevel 列挙型」 を参照してください。
パーティション オプション: Amazon RDS for SQL Server からのデータの読み込みに使用するデータ パーティション分割オプションを指定します。 使用できる値は、なし (既定値)、テーブルの物理パーティション、および動的範囲です。 パーティション オプションが有効になっている場合 (つまり、なしではない場合)、Amazon RDS for SQL Server から同時にデータを読み込む並列処理の次数は、Copy アクティビティの設定タブの [コピーの並列処理] によって制御されます。
[なし]: パーティションを使用しないようにするには、この設定を選択します。
[テーブルの物理パーティション]: 物理パーティションを使用する場合、パーティション列とメカニズムは、物理テーブル定義に基づいて自動的に決定されます。
[動的範囲]: 並列を有効にしたクエリを使用する場合は、範囲パーティション パラメーター (
?DfDynamicRangePartitionCondition) が必要です。 サンプル クエリ:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition。[パーティション列名]: 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (
int、smallint、bigint、date、smalldatetime、datetime、datetime2またはdatetimeoffset) のソース列の名前を指定します。 指定されない場合は、テーブルのインデックスまたは主キーが自動検出され、パーティション列として使用されます。クエリを使用してソース データを取得する場合は、WHERE 句で
?DfDynamicRangePartitionConditionをフックします。 例については、「SQL データベースからの並列コピー」セクションを参照してください。[パーティションの上限]: パーティション範囲の分割に使用するパーティション列の最大値を指定します。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 例については、「SQL データベースからの並列コピー」セクションを参照してください。
[パーティションの下限]: パーティション範囲の分割に使用するパーティション列の最小値を指定します。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 例については、「SQL データベースからの並列コピー」セクションを参照してください。
[追加の列]: ソース ファイルの相対パスまたは静的値を格納するための追加のデータ列を追加します。 後者では式がサポートされています。
以下の点に注意してください。
- ソースにクエリが指定されている場合、Copy アクティビティでは、データを取得するために Amazon RDS for SQL Server ソースに対してこのクエリを実行します。 ストアド プロシージャ名とストアド プロシージャ パラメーターを指定して、ストアド プロシージャを指定することもできます (ストアド プロシージャでパラメーターを使用する場合)。
- ソースのストアド プロシージャを使用してデータを取得する場合、異なるパラメーター値が渡されたときに別のスキーマを返すようにストアド プロシージャが設計されていると、UI からスキーマをインポートするときや、テーブルの自動作成を使用して SQL データベースにデータをコピーするときに、エラーが発生したり、予期しない結果になったりする可能性があります。
マッピング
[マッピング] タブの構成については、「[マッピング] タブでマッピングを構成する」を参照してください。
設定
[設定] タブの構成については、「[設定] タブで他の設定を構成する」を参照してください。
SQL データベースからの並列コピー
Amazon RDS for SQL Server コネクタでは、コピー アクティビティの際に、データを並列でコピーするための組み込みのデータ パーティション分割が提供されます。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
パーティション分割されたコピーを有効にすると、コピー アクティビティによって Amazon RDS for SQL Server ソースに対する並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列処理の次数は、Copy アクティビティの設定タブの [コピーの並列処理] によって制御されます。たとえば、並列処理の次数を 4 に設定した場合、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。各クエリでは、Amazon RDS for SQL Server からデータの一部を取得します。
特に、Amazon RDS for SQL Server から大量のデータを読み込む場合は、データ パーティション分割を使用した並列コピーを有効にすることをお勧めします。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 | パーティション オプション: テーブルの物理パーティション。 実行中に、サービスによって物理パーティションが自動的に検出され、パーティションごとにデータがコピーされます。 テーブルに物理パーティションがあるかどうかを確認するには、こちらのクエリを参照してください。 |
| 物理パーティションがなく、データ パーティション分割用の整数または日時の列がある大きなテーブル全体から読み込む。 | パーティション オプション: 動的範囲パーティション。 パーティション列 (省略可能):データのパーティション分割に使用される列を指定します。 指定されていない場合は、主キー列が使用されます。 パーティションの上限とパーティションの下限 (省略可能):パーティションのストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、テーブル内のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、Copy アクティビティによって値が自動検出されます。最小値と最大値によっては時間がかかることがあります。 上限と下限を指定することをお勧めします。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 |
| 物理パーティションがなく、データ パーティション分割用の整数列または日付/日時列がある大量のデータを、カスタム クエリを使用して読み込む。 | パーティション オプション: 動的範囲パーティション。 クエリ: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>パーティション列: データのパーティション分割に使用される列を指定します。 パーティションの上限とパーティションの下限 (省略可能):パーティションのストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、クエリ結果のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、Copy アクティビティによって値が自動検出されます。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 さまざまなシナリオのサンプル クエリを次に示します。 • テーブル全体に対してクエリを実行する: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• 列の選択と追加の where 句フィルターが含まれるテーブルからのクエリ: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• サブクエリを使用したクエリ: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• サブクエリにパーティションがあるクエリ: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
パーティション オプションを使用してデータを読み込む場合のベスト プラクティス:
- データ スキューを回避するため、パーティション列 (主キーや一意キーなど) には特徴のある列を選択します。
- テーブルに組み込みパーティションがある場合は、パフォーマンスを向上させるためにパーティション オプションとして "テーブルの物理パーティション" を使用します。
物理パーティションを確認するためのサンプル クエリ
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
テーブルに物理パーティションがある場合、次のように、"HasPartition" は "yes" と表示されます。

表の概要
Amazon RDS for SQL Server の Copy アクティビティの概要と詳細については、次の表を参照してください。
ソース情報
| 名前 | Description | Value | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| データ ストアの種類 | データ ストアの種類。 | 外部品目番号 | はい | / |
| 接続 | ソース データ ストアへの実際の接続。 | <実際の接続> | はい | つながり |
| 接続の種類 | 実際の接続の種類。 Amazon RDS for SQL Server を選択します。 | Amazon RDS for SQL Server | はい | / |
| クエリの使用 | カスタム SQL クエリを使用してデータを読み取ります。 | • [テーブル] • クエリ • ストアド プロシージャ |
はい | / |
| テーブル | ソース データ テーブル。 | <コピー先テーブルの名前> | いいえ | schema table |
| クエリ | カスタム SQL クエリを使用してデータを読み取ります。 | < クエリ > | いいえ | sqlReaderQuery |
| ストアド プロシージャ名 | このプロパティは、ソース テーブルからデータを読み取るストアド プロシージャの名前です。 最後の SQL ステートメントはストアド プロシージャの SELECT ステートメントにする必要があります。 | <ストアド プロシージャ名> | いいえ | sqlReaderStoredProcedureName |
| ストアド プロシージャ パラメーター | これらのパラメーターは、ストアド プロシージャ用です。 使用可能な値は、名前または値のペアです。 パラメーターの名前とその大文字と小文字は、ストアド プロシージャのパラメーターの名前とその大文字小文字と一致する必要があります。 | <名前または値のペア> | いいえ | storedProcedureParameters |
| クエリのタイムアウト | クエリ コマンドの実行のタイムアウト | TimeSpan (既定値は 120 分です) |
いいえ | queryTimeout |
| 分離レベル | SQL ソースのトランザクション ロック動作を指定します。 | • コミットされたものを読み取る • コミットされていないものを読み取る • 反復可能な読み取り • Serializable • Snapshot |
いいえ | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • Serializable • Snapshot |
| パーティション オプション | Amazon RDS for SQL Server からのデータの読み込みに使用されるデータ パーティション分割オプション。 | • なし (デフォルト) • テーブルの物理パーティション • 動的範囲 |
いいえ | partitionOption: • なし (既定値) • PhysicalPartitionsOfTable • DynamicRange |
| パーティション列名 | 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (int、smallint、bigint、date、smalldatetime、datetime、datetime2、または datetimeoffset) のソース列の名前。 指定されない場合は、テーブルのインデックスまたは主キーが自動検出され、パーティション列として使用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?DfDynamicRangePartitionCondition をフックします。 |
< パーティション列名> | いいえ | partitionColumnName |
| パーティション上限 | パーティション範囲の分割のための、パーティション列の最大値。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 | <パーティション上限> | いいえ | partitionUpperBound |
| パーティション下限 | パーティション範囲の分割のための、パーティション列の最小値。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 | <パーティション下限> | いいえ | partitionLowerBound |
| 追加の列 | ソース ファイルの相対パスまたは静的値を保存するための追加のデータ列を追加します。 後者では式がサポートされています。 | • 名前 • 値 |
いいえ | additionalColumns: •名前 • value |