Microsoft Fabric の Data Factory での区切りテキスト形式
この記事では、Microsoft Fabric の Data Factory のデータ パイプラインで区切りテキスト形式を構成する方法について説明します。
サポートされる機能
区切りテキスト形式は、次のアクティビティとコネクタでソースとコピー先としてサポートされています。
| カテゴリ | コネクタ/アクティビティ |
|---|---|
| サポートされているコネクタ | Amazon S3 |
| Amazon S3 互換 | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| ファイル システム | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| レイクハウス ファイル | |
| Oracle Cloud Storage | |
| SFTP | |
| サポートされているアクティビティ | Copy アクティビティ (コピー元/コピー先) |
| Lookup アクティビティ | |
| GetMetadata アクティビティ | |
| アクティビティを削除する |
コピー アクティビティの区切りテキスト形式
区切りテキスト形式を構成するには、データ パイプラインのコピー アクティビティのソースまたはコピー先で接続を選択し、[ファイル形式] のドロップダウン リストで [DelimitedText] を選択します。 この形式をさらに構成するには、[設定] を選択します。
ソースとしての区切りテキスト形式
[ファイル形式] セクションで [設定] を選択すると、ポップアップの [ファイル形式設定] ダイアログ ボックスに次のプロパティが表示されます。
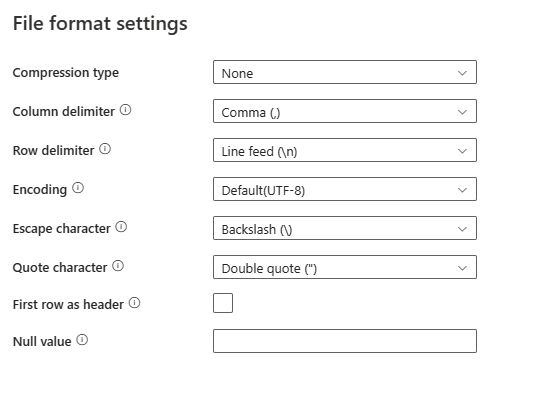
[圧縮の種類]: 区切りテキスト ファイルの読み取りに使用される圧縮コーデックです。 ドロップダウン リストでは、なし、bzip2、gzip、deflate、ZipDeflate、TarGzip、tar の種類から選択できます。
圧縮の種類として [ZipDeflate] を選択した場合、[ソース] タブの [詳細設定] の下に [ZIP ファイル名をフォルダー構造として保持する] が示されます。
- [ZIP ファイル名をフォルダー構造として保持する]: コピー時にソースの ZIP ファイル名をフォルダー構造として保持するかどうかを指定します。
- このボックスがオン (既定値) の場合、解凍されたファイルはサービスによって
<specified file path>/<folder named as source zip file>/に書き込まれます。 - このボックスがオフの場合、解凍されたファイルはサービスによって
<specified file path>に直接書き込まれます。 競合または予期しない動作を避けるために、異なるソース ZIP ファイルに重複したファイル名がないことを確認します。
- このボックスがオン (既定値) の場合、解凍されたファイルはサービスによって
圧縮の種類として [TarGzip/tar] を選択した場合、[ソース] タブの [詳細設定] の下に [圧縮ファイル名をフォルダーとして保持する] が示されます。
- [圧縮ファイル名をフォルダーとして保持する]: コピー時にソースの圧縮ファイル名をフォルダー構造として保持するかどうかを指定します。
- このボックスがオン (既定値) の場合、圧縮解除されたファイルがサービスによって
<specified file path>/<folder named as source compressed file>/に書き込まれます。 - このボックスがオフの場合、圧縮解除されたファイルがサービスによって
<specified file path>に直接書き込まれます。 競合または予期しない動作を避けるために、異なるソース ZIP ファイルに重複したファイル名がないことを確認します。
- このボックスがオン (既定値) の場合、圧縮解除されたファイルがサービスによって
- [ZIP ファイル名をフォルダー構造として保持する]: コピー時にソースの ZIP ファイル名をフォルダー構造として保持するかどうかを指定します。
[圧縮レベル]: 圧縮の種類を選択するときに圧縮率を指定します。 [最適] または [最速] から選択できます。
- Fastest: 圧縮操作は可能な限り短時間で完了しますが、圧縮後のファイルが最適に圧縮されていない場合があります。
- Optimal:圧縮操作で最適に圧縮されますが、操作が完了するまでに時間がかかる場合があります。 詳細については、 圧縮レベル に関するトピックをご覧ください。
[列区切り記号]: ファイル内の列を区切るために使用する文字です。 既定値はコンマ (
,) です。[行区切り記号]: ファイル内の行を区切るために使用する文字を指定します。 許可される文字は 1 つだけです。 既定値は改行
\nです。[エンコード]: テスト ファイルの読み取り/書き込みに使用するエンコードの種類です。 既定値は UTF-8です。
[エスケープ文字]: 引用符で囲まれた値の内部の引用符をエスケープするための 1 文字です。 デフォルトではバックスラッシュ
\です。 エスケープ文字が空の文字列として定義されているときは、[引用符文字] も空の文字列として設定する必要があり、その場合は、すべての列の値に区切り記号が含まれていないことを確認します。[引用符文字]: 列区切り記号が含まれる場合に列の値を引用符で囲むための 1 文字です。 既定値は二重引用符
"です。 [引用符文字] が空の文字列として定義されているときは、引用符がなく、列の値が引用符で囲まれないことを意味し、列区切り記号とそれ自体をエスケープするにはエスケープ文字が使われます。[先頭の行を見出しとして使用]: 1 行目を列の名前が含まれるヘッダー行として扱うかどうか、またはヘッダー行にするかどうかを指定します。 使用できる値はオンとオフ (既定値) です。 [先頭の行を見出しとして使用] がオフの場合、UI データ プレビューと検索アクティビティ出力によって Prop_{n} (0 から開始) という列名が自動生成されることに注意してください。コピー アクティビティでは、ソースからコピー先への明示的なマッピングが必要であり、序数 (1 から始まる) で列が検索されます。
[NULL 値]: null 値の文字列表現を指定します。 既定値は空の文字列です。
[ソース] タブの [詳細設定] に、その他の区切りテキスト形式に関連するプロパティが公開されます。
コピー先としての区切りテキスト形式
[ファイル形式] セクションで [設定] を選択すると、ポップアップの [ファイル形式設定] ダイアログ ボックスに次のプロパティが表示されます。
[圧縮の種類]: 区切りテキスト ファイルの書き込みに使用される圧縮コーデック。 ドロップダウン リストでは、なし、bzip2、gzip、deflate、ZipDeflate、TarGzip、tar の種類から選択できます。
[圧縮レベル]: 圧縮の種類を選択するときに圧縮率を指定します。 [最適] または [最速] から選択できます。
- Fastest: 圧縮操作は可能な限り短時間で完了しますが、圧縮後のファイルが最適に圧縮されていない場合があります。
- Optimal:圧縮操作で最適に圧縮されますが、操作が完了するまでに時間がかかる場合があります。 詳細については、 圧縮レベル に関するトピックをご覧ください。
[列区切り記号]: ファイル内の列を区切るために使用する文字です。 既定値はコンマ (
,) です。[行区切り記号]: ファイル内の行を区切るために使用する文字です。 許可される文字は 1 つだけです。 既定値は改行
\nです。[エンコード]: テスト ファイルの書き込みに使用するエンコードの種類です。 既定値は UTF-8です。
[エスケープ文字]: 引用符で囲まれた値の内部の引用符をエスケープするための 1 文字です。 デフォルトではバックスラッシュ
\です。 エスケープ文字が空の文字列として定義されているときは、[引用符文字] も空の文字列として設定する必要があり、その場合は、すべての列の値に区切り記号が含まれていないことを確認します。[引用符文字]: 列区切り記号が含まれる場合に列の値を引用符で囲むための 1 文字です。 既定値は二重引用符
"です。 [引用符文字] が空の文字列として定義されているときは、引用符がなく、列の値が引用符で囲まれないことを意味し、列区切り記号とそれ自体をエスケープするにはエスケープ文字が使われます。[先頭の行を見出しとして使用]: 1 行目を列の名前が含まれるヘッダー行として扱うかどうか、またはヘッダー行にするかどうかを指定します。 使用できる値はオンとオフ (既定値) です。 [先頭の行を見出しとして使用] がオフの場合、UI データ プレビューと検索アクティビティ出力によって Prop_{n} (0 から開始) という列名が自動生成されることに注意してください。コピー アクティビティでは、ソースからコピー先への明示的なマッピングが必要であり、序数 (1 から始まる) で列が検索されます。
[NULL 値]: null 値の文字列表現を指定します。 既定値は空の文字列です。
[コピー先] タブの [詳細設定] に、区切りテキスト形式に関連するプロパティがさらに表示されます。
[すべてのテキストを引用符で囲む]: すべての値を引用符で囲みます。
[ファイル拡張子]: 出力ファイルの名前に使用するファイル拡張子 (
.csv、.txtなど) です。[ファイルあたりの最大行数]: データをフォルダーに書き込むとき、複数のファイルに書き込み、ファイルあたりの最大行を指定することを選択できます。
[ファイル名プレフィックス]: [ファイルあたりの最大行数] が構成されている場合に適用されます。 データを複数のファイルに書き込むとき、ファイル名のプレフィックスを指定します。結果的に
<fileNamePrefix>_00000.<fileExtension>のパターンになります。 指定されていない場合、ファイル名プレフィックスは自動生成されます。 このプロパティは、ソースがファイルベース ストアかパーティション オプション対応データ ストアの場合、適用されません。
表の概要
ソースとしての区切りテキスト
区切りテキスト形式を使用するとき、コピー アクティビティの [ソース] セクションでは、次のプロパティがサポートされます。
| 名前 | 説明 | Value | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| ファイル形式 | 使用するファイル形式。 | DelimitedText | はい | type ("datasetSettings の下"):DelimitedText |
| [圧縮の種類] | 区切りテキスト ファイルの読み取りに使用される圧縮コーデックです。 | 次から選択してください。 なし bzip2 gzip deflate ZipDeflate TarGzip tar |
いいえ | type ("compression の下"):bzip2 gzip deflate ZipDeflate TarGzip tar |
| Preserve zip file name as folder (ZIP ファイル名をフォルダーとして保持する) | コピー時にソースの ZIP ファイル名をフォルダー構造として保持するかどうかを指定します。 ZipDeflate 圧縮を選択した場合に適用されます。 | オンまたはオフ | なし | preserveZipFileNameAsFolder (" compressionProperties>type の下に ZipDeflateReadSettings として") |
| Preserve compression file name as folder (圧縮ファイル名をフォルダーとして保持する) | コピー時にソースの圧縮ファイル名をフォルダー構造として保持するかどうかを指定します。 TarGzip/tar 圧縮を選択した場合に適用されます。 | 選択または選択解除 | いいえ | preserveCompressionFileNameAsFolder (" compressionProperties>type の下に TarGZipReadSettings または TarReadSettings として") |
| 圧縮レベル | 圧縮率です。 使用できる値は、Optimal または Fastest です。 | 最適 または 最速 | なし | level ("compression の下"):Fastest 最適 |
| 列区切り | ファイル内の列を区切るために使用する文字。 | < 選択した列区切り記号 > コンマ , (デフォルトで) |
いいえ | columnDelimiter |
| 行区切り | ファイルの行を区切るための文字。 | < 選択した行区切り記号 > \r、\n (既定値)、または r\n |
なし | rowDelimiter |
| [エンコード] | テスト ファイルの読み取り/書き込みに使用するエンコードの種類です。 | "UTF-8" (既定値)、"BOM なしの UTF-8"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"US-ASCII"、"UTF-7"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB2312"、"GB18030"、"JOHAB"、"SHIFT-JIS"、"CP875"、"CP866"、"IBM00858"、"IBM037"、"IBM273"、"IBM437"、"IBM500"、"IBM737"、"IBM775"、"IBM850"、"IBM852"、"IBM855"、"IBM857"、"IBM860"、"IBM861"、"IBM863"、"IBM864"、"IBM865"、"IBM869"、"IBM870"、"IBM01140"、"IBM01141"、"IBM01142"、"IBM01143"、"IBM01144"、"IBM01145"、"IBM01146"、"IBM01147"、"IBM01148"、"IBM01149"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-3"、"ISO-8859-4"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"ISO-8859-13"、"ISO-8859-15"、"WINDOWS-874"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255"、"WINDOWS-1256"、"WINDOWS-1257"、"WINDOWS-1258" | なし | encodingName |
| エスケープ文字 | 引用符で囲まれた値の内部の引用符をエスケープするための 1 文字です。 エスケープ文字が空の文字列として定義されているときは、[引用符文字] も空の文字列として設定する必要があり、その場合は、すべての列の値に区切り記号が含まれていないことを確認します。 | < 選択したエスケープ文字 > バックスラッシュ \ (デフォルトで) |
いいえ | escapeChar |
| 引用符文字 | 列区切り記号が含まれる場合に列の値を引用符で囲むための 1 文字です。 [引用符文字] が空の文字列として定義されているときは、引用符がなく、列の値が引用符で囲まれないことを意味し、列区切り記号とそれ自体をエスケープするにはエスケープ文字が使われます。 | < 選択した引用符文字 > 二重引用符 "(デフォルトで) |
いいえ | quoteChar |
| 先頭の行を見出しとして使用 | 指定したワークシート (または範囲) 内の先頭行を、列名を含んだヘッダー行として扱うかどうかを指定します。 | オンまたはオフ | いいえ | firstRowAsHeader: true または false (既定値) |
| Null 値 | null 値の文字列表現を指定します。 既定値は空の文字列です。 | < null 値の文字列表現 > 空の文字列 (既定値) |
いいえ | nullValue |
区切られたテキストをコピー先として指定する
区切りテキスト形式を使用するとき、コピー アクティビティの [コピー先] セクションでは、次のプロパティがサポートされます。
| 名前 | 説明 | Value | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| ファイル形式 | 使用するファイル形式。 | DelimitedText | はい | type ("datasetSettings の下"):DelimitedText |
| [圧縮の種類] | 区切りテキスト ファイルの書き込みに使用される圧縮コーデックです。 | 次から選択してください。 なし bzip2 gzip deflate ZipDeflate TarGzip tar |
いいえ | type ("compression の下"):bzip2 gzip deflate ZipDeflate TarGzip tar |
| Preserve zip file name as folder (ZIP ファイル名をフォルダーとして保持する) | コピー時にソースの ZIP ファイル名をフォルダー構造として保持するかどうかを指定します。 | 選択または選択解除 | なし | preserveZipFileNameAsFolder (" compressionProperties>type の下に ZipDeflateReadSettings として") |
| Preserve compression file name as folder (圧縮ファイル名をフォルダーとして保持する) | コピー時にソースの圧縮ファイル名をフォルダー構造として保持するかどうかを指定します。 | 選択または選択解除 | いいえ | preserveCompressionFileNameAsFolder (" compressionProperties>type の下に TarGZipReadSettings または TarReadSettings として") |
| 圧縮レベル | 圧縮率です。 使用できる値は、Optimal または Fastest です。 | 最適 または 最速 | なし | level ("compression の下"):Fastest 最適 |
| 列区切り | ファイル内の列を区切るために使用する文字。 | < 選択した列区切り記号 > コンマ , (既定値) |
いいえ | columnDelimiter |
| 行区切り | ファイルの行を区切るための文字。 | < 選択した行区切り記号 > \r、\n (既定値)、または r\n |
なし | rowDelimiter |
| [エンコード] | テスト ファイルの読み取り/書き込みに使用するエンコードの種類です。 | "UTF-8" (既定値)、"BOM なしの UTF-8"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"US-ASCII"、"UTF-7"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB2312"、"GB18030"、"JOHAB"、"SHIFT-JIS"、"CP875"、"CP866"、"IBM00858"、"IBM037"、"IBM273"、"IBM437"、"IBM500"、"IBM737"、"IBM775"、"IBM850"、"IBM852"、"IBM855"、"IBM857"、"IBM860"、"IBM861"、"IBM863"、"IBM864"、"IBM865"、"IBM869"、"IBM870"、"IBM01140"、"IBM01141"、"IBM01142"、"IBM01143"、"IBM01144"、"IBM01145"、"IBM01146"、"IBM01147"、"IBM01148"、"IBM01149"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-3"、"ISO-8859-4"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"ISO-8859-13"、"ISO-8859-15"、"WINDOWS-874"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255"、"WINDOWS-1256"、"WINDOWS-1257"、"WINDOWS-1258" | なし | encodingName |
| エスケープ文字 | 引用符で囲まれた値の内部の引用符をエスケープするための 1 文字です。 エスケープ文字が空の文字列として定義されているときは、[引用符文字] も空の文字列として設定する必要があり、その場合は、すべての列の値に区切り記号が含まれていないことを確認します。 | < 選択したエスケープ文字 > バックスラッシュ \ (デフォルトで) |
いいえ | escapeChar |
| 引用符文字 | 列区切り記号が含まれる場合に列の値を引用符で囲むための 1 文字です。 [引用符文字] が空の文字列として定義されているときは、引用符がなく、列の値が引用符で囲まれないことを意味し、列区切り記号とそれ自体をエスケープするにはエスケープ文字が使われます。 | < 選択した引用符文字 > 二重引用符 "(デフォルトで) |
いいえ | quoteChar |
| 先頭の行を見出しとして使用 | 指定したワークシート (または範囲) 内の先頭行を、列名を含んだヘッダー行として扱うかどうかを指定します。 | オンまたはオフ | いいえ | firstRowAsHeader: true または false (既定値) |
| すべてのテキストを引用符で囲む | すべての値を引用符で囲みます。 | オン (既定値) またはオフ | いいえ | quoteAllText: true (既定値) または false |
| [ファイル拡張子] | 出力ファイルの名前に使用するファイル拡張子です。 | < 使用するファイル拡張子 > .txt (既定値) |
いいえ | fileExtension |
| ファイルあたりの最大行数 | データをフォルダーに書き込むとき、複数のファイルに書き込み、ファイルあたりの最大行を指定することを選択できます。 | < ファイルあたりの最大行数 > | いいえ | maxRowsPerFile |
| ファイル名プレフィックス | [ファイルあたりの最大行数] が構成されている場合に適用されます。 データを複数のファイルに書き込むとき、ファイル名のプレフィックスを指定します。結果的に <fileNamePrefix>_00000.<fileExtension> のパターンになります。 指定されていない場合、ファイル名プレフィックスは自動生成されます。 このプロパティは、ソースがファイルベース ストアかパーティション オプション対応データ ストアの場合、適用されません。 |
< 実際のファイル名のプレフィックス > | いいえ | fileNamePrefix |