チュートリアル: Eventhouse をベクター データベースとして使用する
このチュートリアルでは、Eventhouse をベクター データベースとして使用して、ベクター データをリアルタイム インテリジェンスに格納およびクエリする方法について説明します。 ベクター データベースの一般的な情報については、「Vector データベース」を参照してください。
このシナリオでは、Wikipedia のページに対するセマンティック検索を実行することで、共通のテーマを持つページを検索します。 使用可能なサンプル データセットを使用します。これには、数万件の Wikipedia ページのベクターが含まれています。 これらのページには、各ページのベクターを生成するための OpenAI モデルが既に埋め込まれています。 その後、ベクターとページに関連するメタデータが Eventhouse に格納されます。 このデータセットを使用することで、類似するページを検索したり、調べたいテーマに似たページを検索することができます。 たとえば、「19 世紀の有名な女性科学者」について調べたいとします。その場合、同じ OpenAI モデルを使用してこのフレーズをエンコードし、保存されている Wikipedia ページ データに対してベクター類似度検索を実行することで、最も高いセマンティック類似性を持つページを見つけることができます。
具体的には、このチュートリアルでは以下を行います。
- ベクター列の
Vector16エンコードを使用して Eventhouse 内にテーブルを準備します。 - 埋め込み済みデータセットからのベクターデータを Eventhouse に格納します。
- Open AI モデルを使用して自然言語クエリを埋め込みます。
- series_cosine_similarity KQL 関数を使用して、クエリ埋め込みベクターと wiki ページの類似点を計算します。
- 最も類似性の高い行を表示して、検索クエリに最も関連性の高い Wiki ページを取得します。
この構造は、以下のように視覚化できます。

前提条件
- Microsoft Fabric 対応の容量を持つワークスペース
- ワークスペース内のイベントハウス
- text-embedding-ada-002 (バージョン 2) モデルがデプロイされた Azure OpenAI リソース。 このモデルは現在、特定のリージョンでのみ使用できます。 詳細については、リソースの作成に関するページを参照してください。
- ローカル認証が Azure OpenAI リソースで有効になっていることを確認します。
- GitHub リポジトリからノートブックのサンプルをダウンロードします。
Note
このチュートリアルでは Azure OpenAI を使用しますが、任意の埋め込みモデル プロバイダーを使用してテキスト データのベクターを生成できます。
Eventhouse 環境を準備する
このセットアップ手順では、ベクター データの格納に必要な列とエンコード ポリシーを含むテーブルを Eventhouse 内に作成します。
Real Time Analytics でワークスペースのホーム ページを参照します。
「前提条件」で作成した Eventhouse を選択します。
ベクター データを格納するターゲット データベースを選択します。 まだデータストアを作成していない場合は、[新しいデータストア] を選択してデータストアを作成できます。
[自分のデータを探索する] を選択します。 次の KQL クエリをコピーして貼り付け、必要な列を含むテーブルを作成します。
.create table Wiki (id:string,url:string,['title']:string,text:string,title_vector:dynamic,content_vector:dynamic,vector_id:long)次のコマンドをコピー/貼り付けして、ベクター列のエンコード ポリシーを設定します。 これらのコマンドを順番に実行します。
.alter column Wiki.title_vector policy encoding type='Vector16' .alter column Wiki.content_vector policy encoding type='Vector16'
Eventhouse にベクター データを書き込む
埋め込まれた Wikipedia データをインポートして Eventhouse に書き込むには、次の手順を使用します。
ノートブックをインポートする
- GitHub リポジトリからノートブックのサンプルをダウンロードします。
- Fabric 環境を参照します。 エクスペリエンス スイッチャーで、[Data Engineering] を選択します。
- [ノートブックをインポートする]>[アップロード] を選択し、前の手順でダウンロードしたアップロードを選択します。

- インポートしたノートブック項目を開きます。
Eventhouse にデータを書き込む
セルを実行して環境を設定します。
%%configure -f {"conf": { "spark.rpc.message.maxSize": "1024" } }%pip install wget%pip install openaiセルを実行し、計算済みの埋め込みをダウンロードします。
import wget embeddings_url = "https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip" # The file is ~700 MB so it might take some time wget.download(embeddings_url)import zipfile with zipfile.ZipFile("vector_database_wikipedia_articles_embedded.zip","r") as zip_ref: zip_ref.extractall("/lakehouse/default/Files/data")import pandas as pd from ast import literal_eval article_df = pd.read_csv('/lakehouse/default/Files/data/vector_database_wikipedia_articles_embedded.csv') # Read vectors from strings back into a list article_df["title_vector"] = article_df.title_vector.apply(literal_eval) article_df["content_vector"] = article_df.content_vector.apply(literal_eval) article_df.head()Eventhouse に書き込むには、クラスター URI を入力します。クラスター URI は、システムの概要ページおよびデータベース名で確認できます。 テーブルがノートブックに作成され、後でクエリで参照されます。
# replace with your Eventhouse Cluster URI, Database name, and Table name KUSTO_CLUSTER = "Eventhouse Cluster URI" KUSTO_DATABASE = "Database name" KUSTO_TABLE = "Wiki"残りのセルを実行して、Eventhouse にデータを書き込みます。 この操作には時間がかかることがあります。
kustoOptions = {"kustoCluster": KUSTO_CLUSTER, "kustoDatabase" :KUSTO_DATABASE, "kustoTable" : KUSTO_TABLE } access_token=mssparkutils.credentials.getToken(kustoOptions["kustoCluster"])#Pandas data frame to spark dataframe sparkDF=spark.createDataFrame(article_df)# Write data to a table in Eventhouse sparkDF.write. \ format("com.microsoft.kusto.spark.synapse.datasource"). \ option("kustoCluster",kustoOptions["kustoCluster"]). \ option("kustoDatabase",kustoOptions["kustoDatabase"]). \ option("kustoTable", kustoOptions["kustoTable"]). \ option("accessToken", access_token). \ option("tableCreateOptions", "CreateIfNotExist").\ mode("Append"). \ save()
Eventhouse 内のデータを確認する
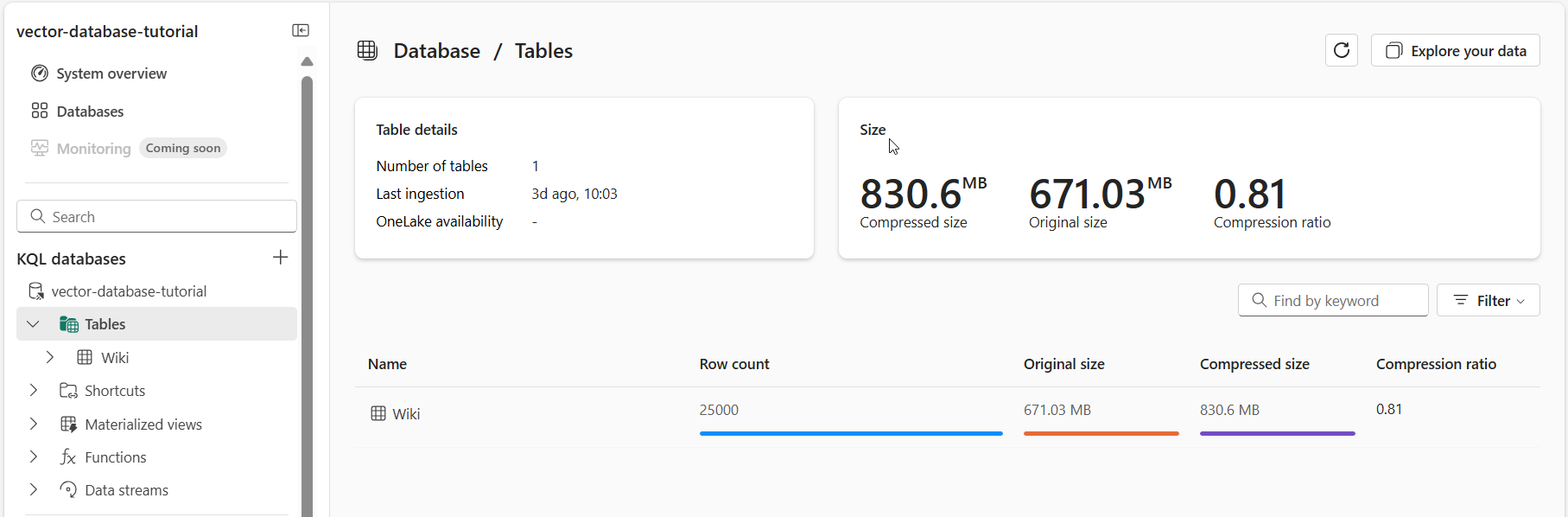
この時点で、データベースの詳細ページを参照して、データが Eventhouse に書き込まれたかどうかを確認できます。
Real Time Analytics でワークスペースのホーム ページを参照します。
前のセクションで指定したデータベース項目を選択します。 "Wiki" テーブルに書き込まれたデータの概要が表示されます。
検索語句の埋め込みを生成する
埋め込まれた Wiki データを Eventhouse に格納したら、このデータを参照として使用することで特定の記事のページを検索できます。 比較を行うには、検索語句を埋め込み、検索語句と Wikipedia ページの比較を行います。
Azure OpenAI に対して正常に呼び出しを行うには、エンドポイント、キー、展開 ID が必要です。
| 変数名 | Value |
|---|---|
| endpoint | この値は、Azure portal からのリソースを確認する際に、[キーとエンドポインド] セクションで確認することができます。 または、[Azure OpenAI Studio]>[プレイグラウンド]>[コード ビュー] で確認することもできます。 エンドポイントの例: https://docs-test-001.openai.azure.com/。 |
| API キー | この値は、Azure portal からのリソースを確認する際に、[キーとエンドポインド] セクションで確認することができます。 Key1 または Key2 を使用できます。 |
| 展開 ID | この値は、[Azure OpenAI Studio] の [展開] セクションにあります。 |
Azure OpenAI セルを実行するときは、表の情報を使用します。
重要
API キーを使用するには、Azure Open AI リソースでローカル認証を有効にする必要があります。
import openai
openai.api_version = '2022-12-01'
openai.api_base = 'endpoint' # Add your endpoint here
openai.api_type = 'azure'
openai.api_key = 'api key' # Add your api key here
def embed(query):
# Creates embedding vector from user query
embedded_query = openai.Embedding.create(
input=query,
deployment_id="deployment id", # Add your deployment id here
chunk_size=1
)["data"][0]["embedding"]
return embedded_query
searchedEmbedding = embed("most difficult gymnastics moves in the olympics")
#print(searchedEmbedding)
類似性クエリを実行する
クエリはノートブックから直接実行され、前の手順から返された埋め込みを使用して、Eventhouse に格納されている埋め込み Wikipedia ページとの比較を行います。 このクエリでは、コサイン類似性関数を使用して最も類似したベクター上位 10 個を返します。
ノートブック内のセルを実行して、クエリの結果を表示します。 検索語句を変更してクエリを再実行することで、さまざまな結果を確認できます。 Wiki データベース内の既存のエントリを比較して、類似のエントリを見つけることもできます。
kustoQuery = "Wiki | extend similarity = series_cosine_similarity(dynamic("+str(searchedEmbedding)+"), content_vector) | top 10 by similarity desc"
accessToken = mssparkutils.credentials.getToken(KUSTO_CLUSTER)
kustoDf = spark.read\
.format("com.microsoft.kusto.spark.synapse.datasource")\
.option("accessToken", accessToken)\
.option("kustoCluster", KUSTO_CLUSTER)\
.option("kustoDatabase", KUSTO_DATABASE)\
.option("kustoQuery", kustoQuery).load()
# Example that uses the result data frame.
kustoDf.show()

リソースをクリーンアップする
チュートリアルが完了したら、作成したリソースを削除して、他のコストが発生しないようにすることができます。 リソースを削除するには、次の手順を実行します。
- ワークスペースのホームページを参照します。
- このチュートリアルで作成したノートブックを削除します。
- このチュートリアルで使用した Eventhouse または database を削除します。