series_decompose()
適用対象: ✅Microsoft Fabric✅Azure データ エクスプローラー✅Azure Monitor✅Microsoft Sentinel
系列に分解変換を適用します。
系列 (動的数値配列) を含む式を入力として受け取り、季節、傾向、および残差成分に分解します。
構文
series_decompose(Series , [ Seasonality, Trend, Test_points, Seasonality_threshold ])
構文規則について詳しく知る。
パラメーター
| 件名 | タイプ | Required | 説明 |
|---|---|---|---|
| 系列 | dynamic |
✔️ | 数値の配列。通常は、 make-series または make_list 演算子の結果の出力です。 |
| 季節 | int |
季節分析を制御します。 指定できる値は、 - -1: series_periods_detectを使用して季節性を自動検出します。 これが既定値です。- 期間: ビンの数で予想される期間を指定する正の整数。たとえば、系列が 1 - h ビンにある場合、週単位の期間は 168 ビンです。- 0: 季節性がないため、このコンポーネントの抽出はスキップしてください。 |
|
| 傾向 | string |
傾向分析を制御します。 指定できる値は、 - avg: 傾向コンポーネントを average(x)として定義します。 これが既定です。- linefit:線形回帰を使用して傾向コンポーネントを抽出します。- none: 傾向がないため、このコンポーネントの抽出はスキップしてください。 |
|
| Test_points | int |
学習 (回帰) プロセスから除外する系列の末尾のポイント数を指定する正の整数。 このパラメーターは、予測のために設定する必要があります。 既定値は0です。 | |
| Seasonality_threshold | real |
Seasonalityが自動検出に設定されている場合の季節性スコアのしきい値。 既定のスコアしきい値は 0.6 です。 詳細については、「series_periods_detect」を参照してください。 |
返品
この関数からは、次のそれぞれの系列が返されます。
baseline: 系列の予測値 (季節成分と傾向成分の合計、以下を参照)。seasonal: 季節成分の系列:- 期間が検出されない場合または明示的に 0 に設定されている場合: 定数 0。
- 検出された場合または正の整数に設定されている場合: 同じフェーズの系列ポイントの中央値。
trend: 傾向成分の系列。residual: 残余成分 (つまり、x - ベースライン) の系列。
Note
- 成分実行順序:
- 季節系列を抽出する
- それを x から減算し、非季節系列を生成する
- 非季節系列から傾向成分を抽出する
- ベースライン = 季節 + 傾向を作成する
- 残差 = x - ベースラインを作成する
- 季節性と傾向のどちらかが有効になっている必要があります。 そうでない場合は、関数が不要になり、ベースライン = 0 と残差 = x のみを返します。
系列分解の詳細
この方式は、通常、周期動作および/または傾向動作を明確にするように想定されたメトリックの時系列に適用されます。 この方式を使用して、将来のメトリック値を予測したり、異常値を検出したりできます。 この回帰プロセスの暗黙の想定は、季節動作や傾向動作以外に、時系列が確率的で、ランダムに分散されていることです。 残差部分を無視して、季節成分と傾向成分から将来のメトリック値を予測します。 残差部分のみに関する外れ値検出のみに基づいて異常値を検出します。 詳細については、「時系列分解」の章を参照してください。
例
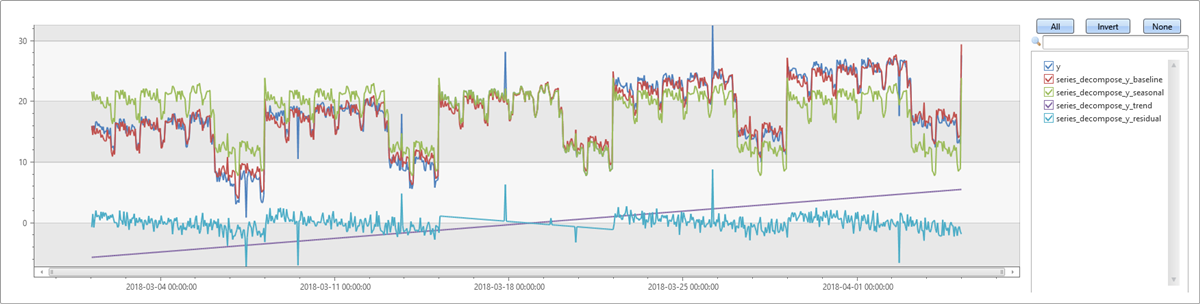
週単位の季節性
次の例では、傾向を伴わない週単位の季節性がある系列を生成してから、それにいくつかの外れ値を追加します。 series_decompose は、季節性を自動的に検索して検出し、季節成分とほぼ同じベースラインを生成します。 追加した外れ値は、残差成分で明確に確認できます。
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 10.0, 15.0) - (((t%24)/10)*((t%24)/10)) // generate a series with weekly seasonality
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose(y)
| render timechart
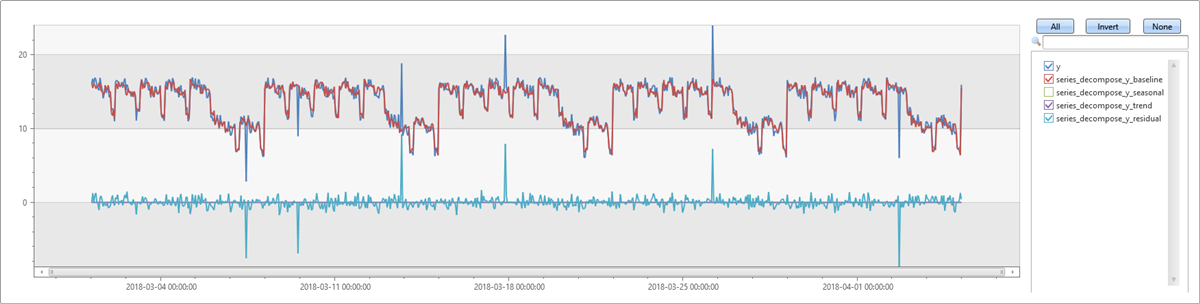
傾向を伴う週単位の季節性
この例では、前の例からの系列に傾向を追加します。 まず、既定のパラメーターを使用して series_decompose を実行します。 傾向 avg の既定値は、平均のみを取得し、傾向は計算しません。 生成されたベースラインには傾向が含まれません。 残差内の傾向を観察すると、この例は前の例よりも精度が低いことが明らかになります。
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and ongoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose(y)
| render timechart
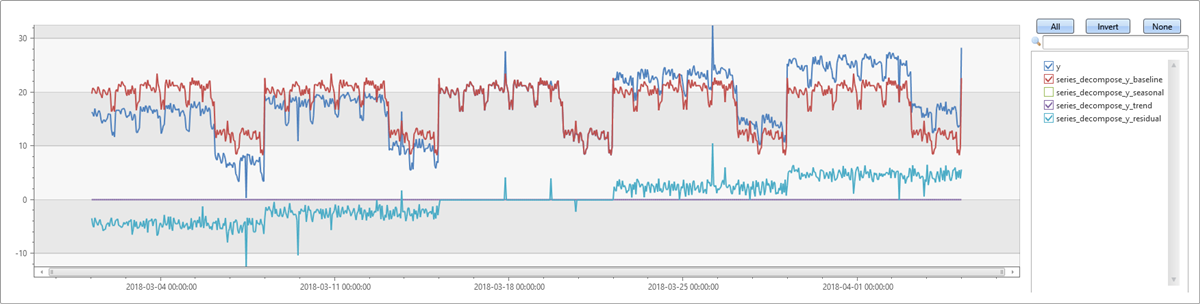
次に、同じ例を再実行します。 ここでは、系列内の傾向を想定しているため、trend パラメーターで linefit を指定します。 正の傾向が検出され、ベースラインが入力系列に非常に近いことがわかります。 残差は 0 に近く、外れ値のみが目立ちます。グラフで系列内のすべての成分を確認できます。
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and ongoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose(y, -1, 'linefit')
| render timechart