series_fit_2lines()
適用対象: ✅Microsoft Fabric✅Azure データ エクスプローラー✅Azure Monitor✅Microsoft Sentinel
系列に 2 つのセグメント化線形回帰を適用し、複数の列を返します。
動的数値配列を含む式を入力として受け取り 2 つのセグメント化された線形回帰を適用し 系列の傾向変化を特定して定量化します。 この関数は、系列インデックスに対して反復処理を行います。 各反復処理では、関数が、系列を 2 つの部分に分割し、(series_fit_line() を使用して) 各部分に別々の直線を適合させ、r-2 乗の合計を計算します。 最適な分割は r-2 乗を最大化したものです。この関数は次のパラメーターを返します。
| パラメーター | 説明 |
|---|---|
rsquare |
R-2 乗は、適合度の標準尺度です。 範囲 [0- 1] の数値です。1 は最適な適合値であり、0 はデータが順序付けされておらず、行に収まらないことを意味します。 |
split_idx |
2 つのセグメントのブレーク ポイントのインデックス (0 から始まる)。 |
variance |
入力データの分散。 |
rvariance |
入力データ値と近似値の差である残差分散 (2 つの線分による)。 |
line_fit |
最も適合する直線の値の系列を保持する数値配列。 系列の長さは入力配列の長さと同じです。 主にグラフ作成に使用されます。 |
right_rsquare |
分割の右側での直線の r-2 乗。「series_fit_line()」を参照してください。 |
right_slope |
右の近似直線の傾き (y=ax+b の形式)。 |
right_interception |
左の近似直線のインターセプト (y=ax+b からの b)。 |
right_variance |
分割の右側での入力データの分散。 |
right_rvariance |
分割の右側での入力データの残差分散。 |
left_rsquare |
分割の左側での直線の r-2 乗。「series_fit_line()」を参照してください。 |
left_slope |
左の近似直線の傾き (y=ax+b の形式)。 |
left_interception |
左の近似直線のインターセプト (y=ax+b の形式)。 |
left_variance |
分割の左側での入力データの分散。 |
left_rvariance |
分割の左側での入力データの残差分散。 |
Note
この関数は、複数の列を返すため、別の関数の引数として使用することはできません。
構文
project series_fit_2lines(series)
構文規則について詳しく知る。
- 前述のすべての列を series_fit_2lines_x_rsquare や series_fit_2lines_x_split_idx などの名前で返します。
project (rs, si, v)=series_fit_2lines(series)
- rs (r-2 乗)、si (分割インデックス)、v (差異) の各列を返します。残りの列は series_fit_2lines_x_rvariance、series_fit_2lines_x_line_fit などになります。
extend (rs, si, v)=series_fit_2lines(series)
- rs (r-2 乗)、si (分割インデックス)、v (差異) のみを返します。
パラメーター
| 件名 | タイプ | Required | 説明 |
|---|---|---|---|
| 系列 | dynamic |
✔️ | 数値の配列。 |
ヒント
この関数の最も便利な使い方は、make-series 演算子の結果に適用することです。
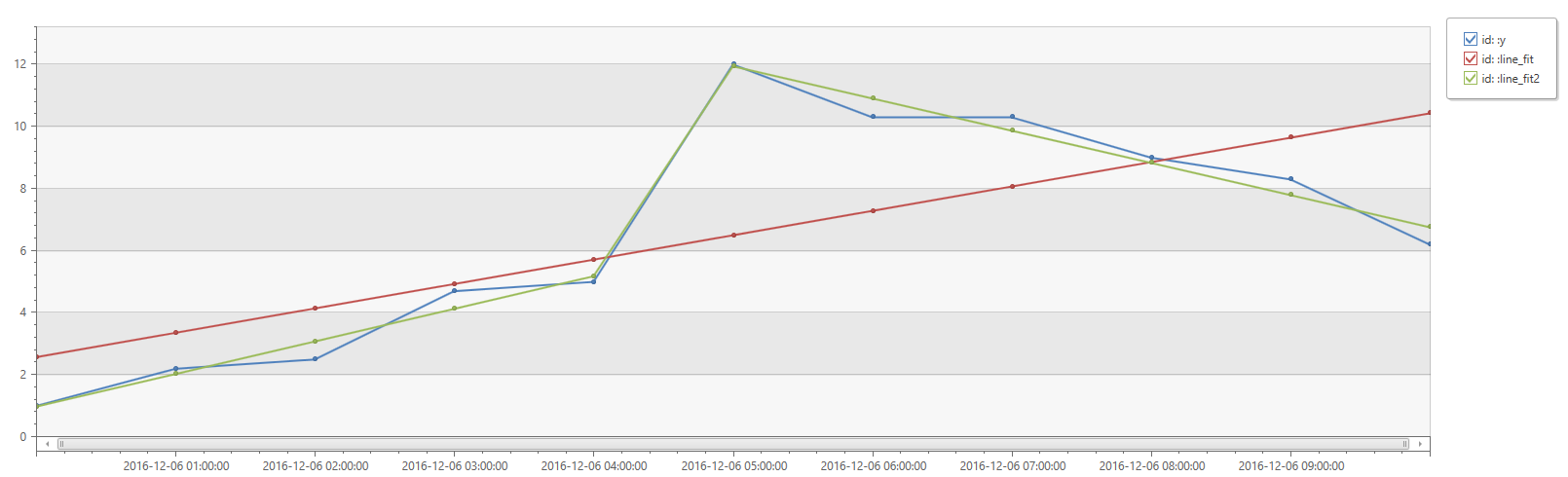
例
print
id=' ',
x=range(bin(now(), 1h) - 11h, bin(now(), 1h), 1h),
y=dynamic([1, 2.2, 2.5, 4.7, 5.0, 12, 10.3, 10.3, 9, 8.3, 6.2])
| extend
(Slope, Interception, RSquare, Variance, RVariance, LineFit)=series_fit_line(y),
(RSquare2, SplitIdx, Variance2, RVariance2, LineFit2)=series_fit_2lines(y)
| project id, x, y, LineFit, LineFit2
| render timechart