Web ページから詳細を取得する
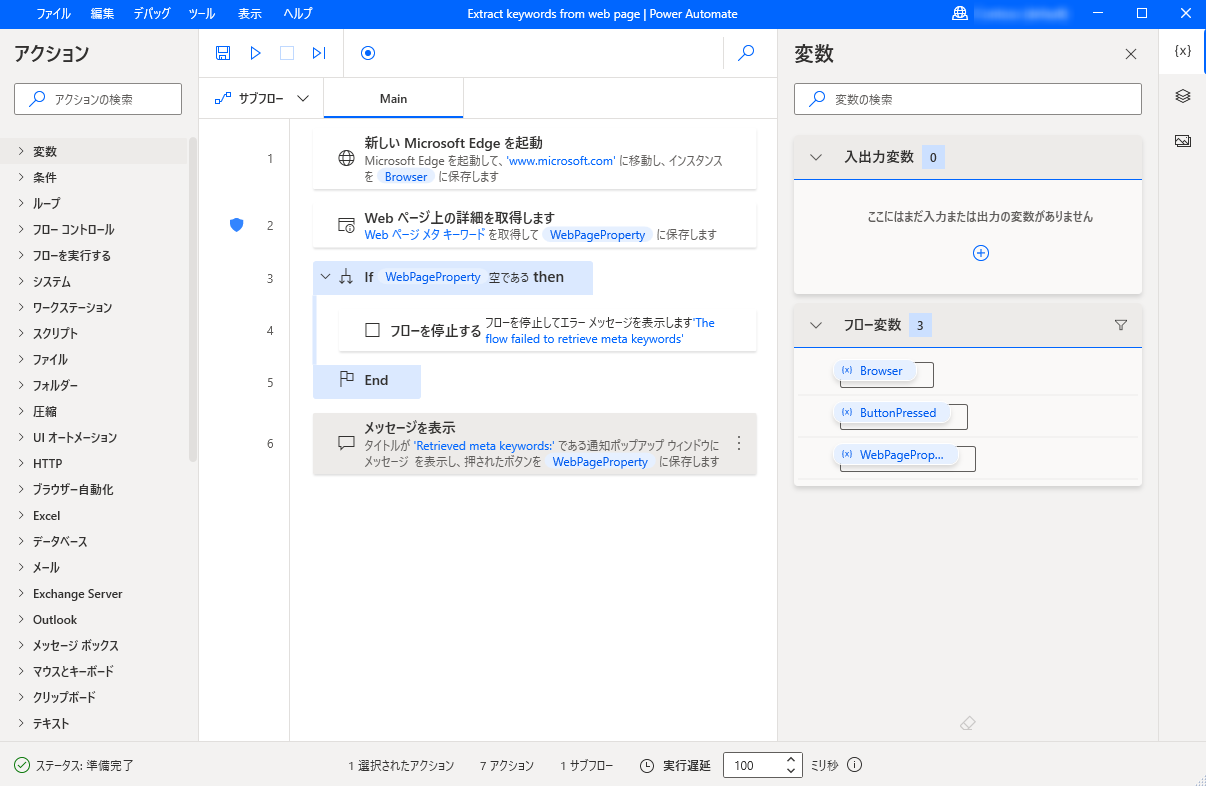
Web ページに関する情報の抽出は、ほとんどの Web 関連フローで不可欠な機能です。 Web ページ上の詳細を取得アクションでは、Web ページの各種詳細を取得し、デスクトップ フローで処理できます。
アクションを使用するには、詳細を抽出する Web ページを指定する作成済みのブラウザ インスタンスが必要です。 ブラウザ インスタンスは、任意のブラウザ起動アクションで作成できます。
適切なブラウザ インスタンスを選択した後、Web ページから抽出する情報を選択します。 Web ページの詳細を取得するアクションには 6 つの異なるオプションがあります。
- Web ページの説明
- Web ページのメタ キーワード
- Web ページのタイトル
- Web ページのテキスト
- Web ページのソース コード
- Web ページの URL アドレス
取得した情報は、後で使用するために、WebPageProperty という名前のテキスト変数に保存されます。
詳細を取得する際のエラーを防ぐ
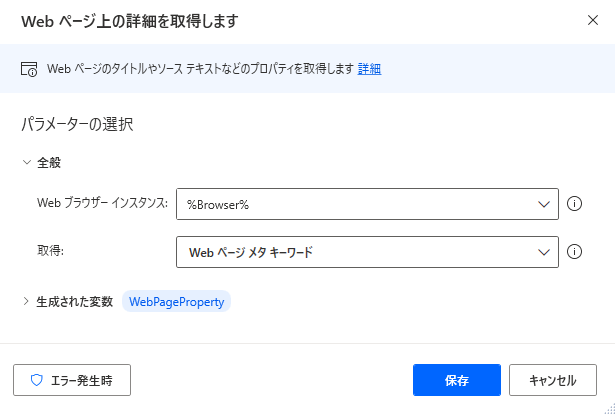
ほとんどのプロパティは事実上すべての Web ページに存在しますが、Web ページの詳細を取得するアクションを使っても、選択した詳細の取得に失敗するシナリオがあります。 たとえば、メタ キーワードのない Web ページはよくあります。
Web ページに属性が存在するかどうかわからない場合は、Webページの詳細を取得するアクションのエラー時オプションを、失敗後もフローの実行を継続するよう構成します。 アクション エラー処理の詳細については デスクトップ フローのエラーを処理する を参照してください。

データ抽出が成功したかどうかを判断するには、If 条件を使用して、WebPageProperty 変数が空かどうかをチェックします。
この条件を使うことで、データ抽出が成功した場合と失敗した場合に応じて、さまざまな機能を実装できます。 条件に関する詳細については、条件文を使用するを参照してください。
次のサブフローの例では、使用可能なメタ キーワードを Web ページから取得し、メッセージ ボックスに表示します。 抽出が失敗した場合、フローは停止し、エラー メッセージを返します。