クエリ フォールディングの例
この記事では、クエリ フォールディングの考えられる 3 つの結果のそれぞれについて、シナリオの例をいくつか提供します。 また、クエリ フォールディング メカニズムを最大限に活用する方法を提案し、クエリに及ぶ可能性がある影響について説明します。
シナリオ
Azure Synapse Analytics SQL データベース用の国際輸入業者データベースを使用して、Power Query でクエリを作成するシナリオを想像してください。このクエリでは、fact_Sale テーブルに接続し、次のフィールドのみを含む最近 10 件の売上を取得します。
- Sale Key
- カスタマー キー
- Invoice Date Key
- 説明
- Quantity
Note
この記事では、デモの目的で、国際輸入業者データベースを Azure Synapse Analytics に読み込むチュートリアルで説明したデータベースを使用します。 この記事での主な違いは、fact_Sale テーブルに保持されているのが 2000 年度のデータ (合計 3,644,356 行) のみである点です。
ここで得られる結果は、Azure Synapse Analytics ドキュメントのチュートリアルを実行して得られる結果とは完全に一致しない場合がありますが、この記事の目的は、重要な概念と、クエリ フォールディングがクエリに及ぼす可能性がある影響について説明することです。
この記事では、異なるレベルのクエリ フォールディングで同じ出力を実現する 3 つの方法について説明します。
- クエリ フォールディングなし
- 部分的クエリ フォールディング
- 完全クエリ フォールディング
クエリ フォールディングなしの例
重要
非構造化データ ソースのみに依存するクエリや、コンピューティング エンジンを持たない CSV ファイルや Excel ファイルなどのクエリには、クエリ フォールディング機能はありません。 その場合、Power Query ではすべての必要なデータ変換を Power Query エンジンを使用して評価します。
データベースに接続して fact_Sale テーブルに移動したら、[ホーム] タブの [行の削減] グループ内にある [下位の行を保持] 変換を選択します。
![ホーム タブの [行の削減] グループ内にある [下位の行を保持] 変換。](media/query-folding-basics/keep-bottom-rows-ui.png)
この変換を選択すると、新しいダイアログが表示されます。 この新しいダイアログで、保持する行数を入力できます。 今回は、値 10 を入力して [OK] を選択します。
![[下位の行を保持] ダイアログ内で値 10 を入力。](media/query-folding-basics/keep-bottom-rows-dialog.png)
ヒント
今回、この操作を実行すると、最近 10 件の売上の結果が得られます。 ほとんどのシナリオでは、どの行が最後に考慮されるかを、並べ替え操作をテーブルに適用することによって定義する、より明示的なロジックを提供することをお勧めします。
次に、[ホーム] タブの [列の管理] グループ内にある [列の選択] 変換を選択します。この後、保持する列をテーブルから選択し、残りは削除することができます。
![クエリ フォールディングなしの例で [列の選択] 変換を選択。](media/query-folding-basics/choose-columns-ui.png)
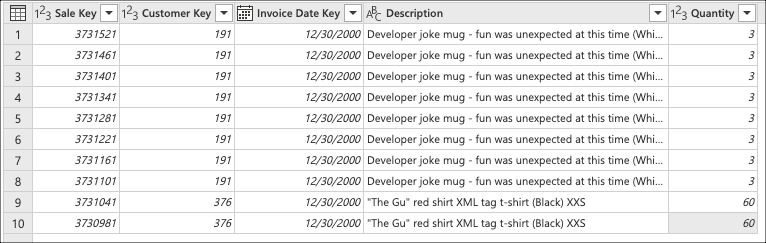
最後に、[列の選択] ダイアログ内で、Sale Key、Customer Key、Invoice Date Key、Description、Quantity の各列を選択して [OK] を選択します。
次のコード サンプルは、作成したクエリの完全な M スクリプトです。
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(#"Kept bottom rows", {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"})
in
#"Choose columns""
クエリ フォールディングなし: クエリの評価について理解する
Powerクエリエディタの適用されるステップの下にある、最下行を保持すると列を選択するのクエリ折りたたみインジケータは、データソースの外部、つまりPowerクエリエンジンによって評価されるステップとしてマークされていることがわかります。
![クエリの [適用したステップ] ペインで、クエリ折りたたみインジケーターが表示され、[最下行を維持] ステップと [他の列を削除] ステップが表示されます。](media/query-folding-basics/no-folding-steps.png)
クエリの最後のステップである [列の選択] を右クリックして [クエリ プランの表示] オプションを選択できます。 クエリ プランの目的は、クエリがどのように実行されるかの詳細なビューを提供することです。 この機能の詳細については、クエリ プランに関するページを参照してください。
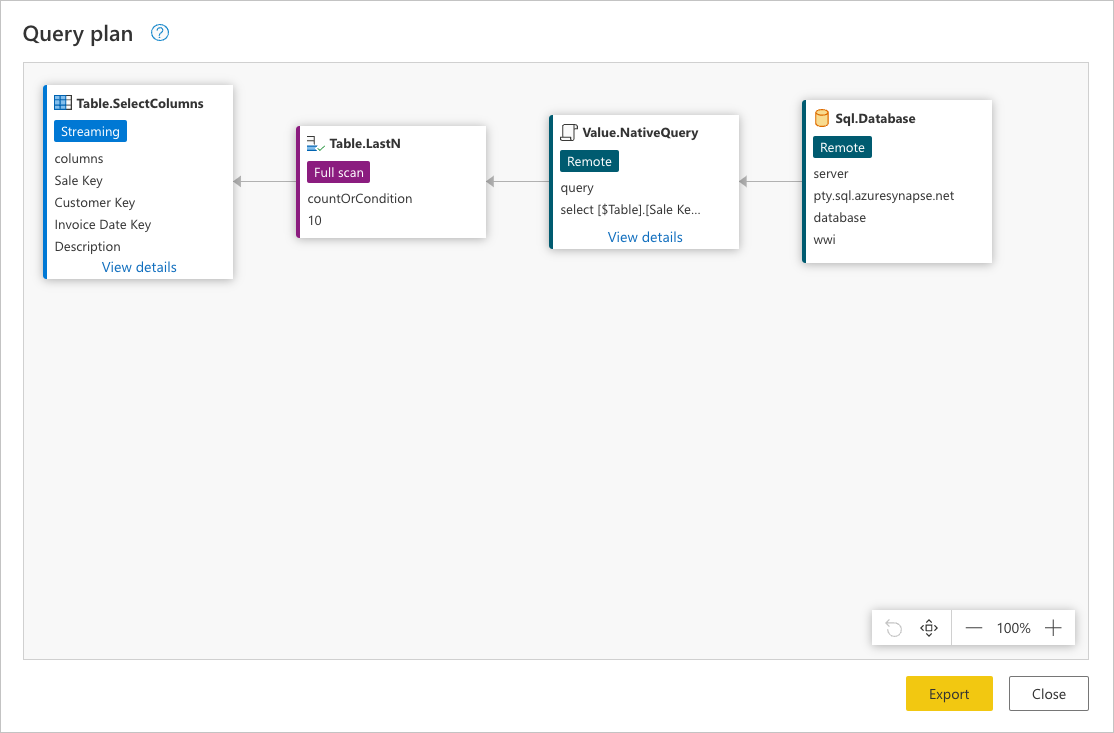
前の画像の各ボックスは "ノード" と呼ばれます。 ノードは、このクエリを満たすための操作の内訳を表します。 上記の例の SQL Server などのデータ ソースを表すノードと、クエリのどの部分がデータ ソースにオフロードされるかを表す Value.NativeQuery ノードがあります。 残りのノード (この場合、前の画像では四角形でハイライトされている Table.LastN と Table.SelectColumns) は、Power Query エンジンによって評価されます。 これら 2 つのノードは、追加した 2 つの変換 [下位の行を保持] と [列の選択] を表します。 残りのノードは、データ ソースのレベルで発生する操作を表します。
データ ソースに送信される要求全体を確認するには、Value.NativeQuery ノードで [詳細の表示] を選択します。
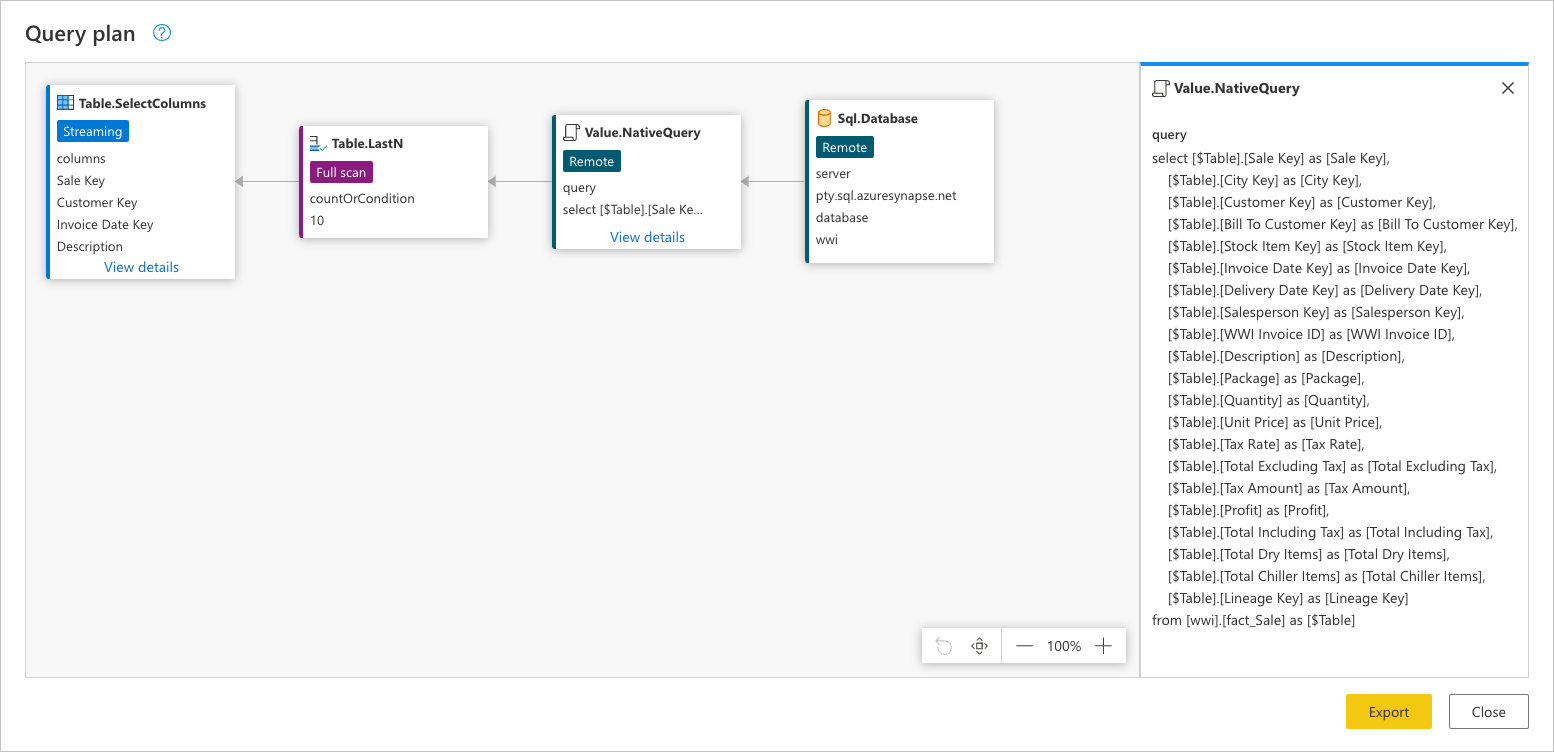
このデータ ソース要求は、データ ソースのネイティブ言語で行われます。 この場合、その言語は SQL であり、このステートメントは fact_Sale テーブルのすべての行とフィールドに対する要求を表します。
このデータ ソース要求を調べると、クエリ プランが伝えようとしているストーリーをより深く理解できます。
Sql.Database: このノードはデータ ソース アクセスを表します。 データベースに接続し、メタデータ要求を送信してその機能を理解します。Value.NativeQuery: クエリを満たすために Power Query によって生成された要求を表します。 Power Query では、データ要求をネイティブ SQL ステートメントでデータ ソースに送信します。 この場合、fact_Saleテーブルのすべてのレコードとフィールド (列) を表します。 このシナリオでは、数百万行が含まれるテーブルの最後の 10 行のみに関心があるため、このケースは望ましくありません。Table.LastN: Power Query では、fact_Saleテーブルからすべてのレコードを受信すると、Power Query エンジンを使用してテーブルをフィルター処理し、最後の 10 行のみを保持します。Table.SelectColumns: Power Query では、Table.LastNノードの出力を使用し、Table.SelectColumnsという名前の、保持する特定の列をテーブルから選択する新しい変換を適用します。
その評価のために、このクエリではすべての行とフィールドを fact_Sale テーブルからダウンロードする必要がありました。 このクエリは、Power BI データフローの標準インスタンス (データフローへのデータの評価と読み込みを考慮したもの) での処理に平均 6 分 1 秒かかりました。
部分的クエリ フォールディングの例
データベースに接続して fact_Sale テーブルに移動したら、まず、保持する列をテーブルから選択します。 [ホーム] タブから、[列の管理] グループ内にある [列の選択] 変換を選択します。この変換は、テーブルの列のうち保持するものを明示的に選択し、残りは削除するために役立ちます。
[列の選択] ダイアログ内で、Sale Key、Customer Key、Invoice Date Key、Description、Quantity の各列を選択して [OK] を選択します。
ここで、最後の売上がテーブルの一番下に来るようにテーブルを並べ替えるロジックを作成します。 Sale Key 列を選択します。これは、テーブルの主キーおよび増分シーケンスまたはインデックスです。 列のコンテキスト メニューから、このフィールドのみを使用して昇順でテーブルを並べ替えます。
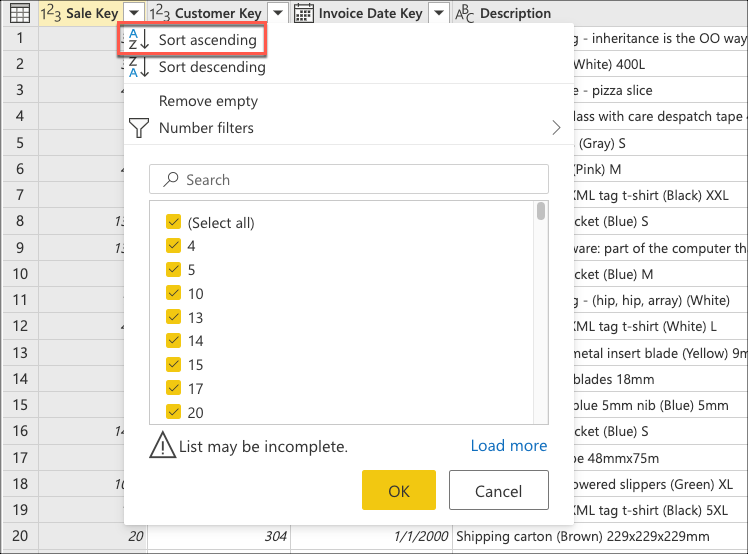
次に、テーブルのコンテキスト メニューを選択し、[下位の行を保持] 変換を選択します。
![テーブルのコンテキスト メニュー内の [下位の行を保持] オプションを選択します。](media/query-folding-basics/partial-folding-keep-bottom-rows.png)
[下位の行を保持] で、値 10 を入力して [OK] を選択します。
![テーブルの末尾 10 行のみを保持するために入力値として値 10 を入力した [下位の行を保持] ダイアログ。](media/query-folding-basics/partial-folding-keep-bottom-rows-dialog.png)
次のコード サンプルは、作成したクエリの完全な M スクリプトです。
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
部分的クエリ フォールディングの例: クエリの評価について理解する
[適用されたステップ] ペインを確認すると、クエリ折りたたみインジケータが、追加した最後の変換Kept bottom rows が、データソースの外部、つまり Power Query エンジンによって評価されるステップとしてマークされていることに気づきます。
![クエリの [適用したステップ] ペイン。クエリ折りたたみインジケーターが表示され、Kept の下位行がデータ ソースの外部で評価されるステップとしてマークされていることを示します。](media/query-folding-basics/partial-folding-steps.png)
クエリの最後のステップである Kept bottom rows を右クリックして [クエリ プラン] オプションを選択すると、クエリがどのように評価されるかをより深く理解できます。
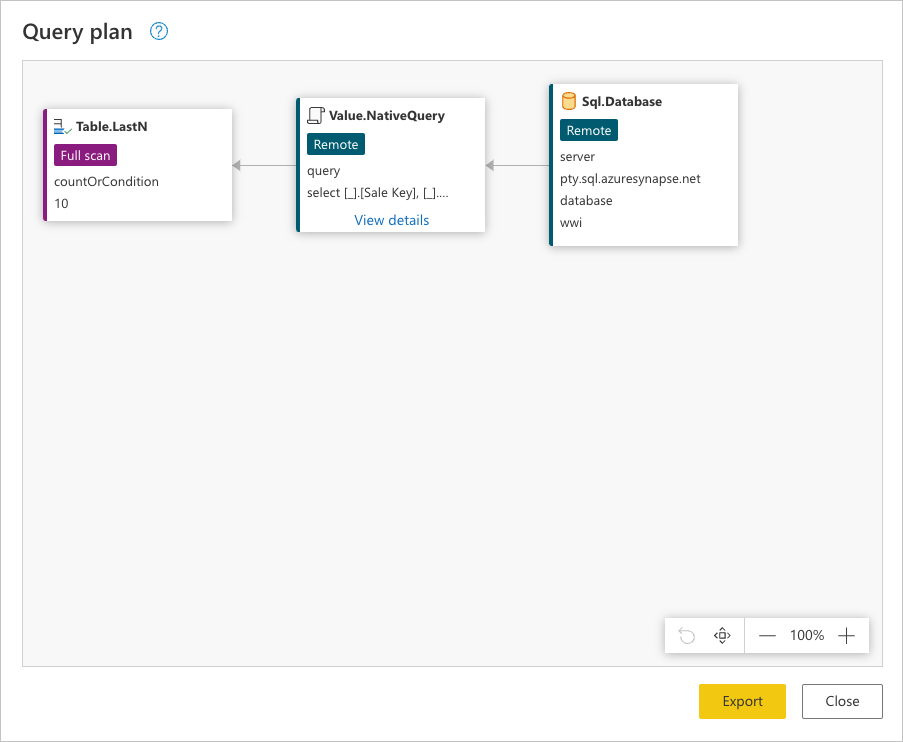
前の画像の各ボックスは "ノード" と呼ばれます。 ノードは、クエリが評価されるために (左から右の順に) 発生する必要があるすべてのプロセスを表します。 これらのノードの一部はデータ ソースで評価できる一方で、[下位の行を保持] ステップによって表される Table.LastN のノードなど、その他のノードは Power Query エンジンを使用して評価されます。
データ ソースに送信される要求全体を確認するには、Value.NativeQuery ノードで [詳細の表示] を選択します。
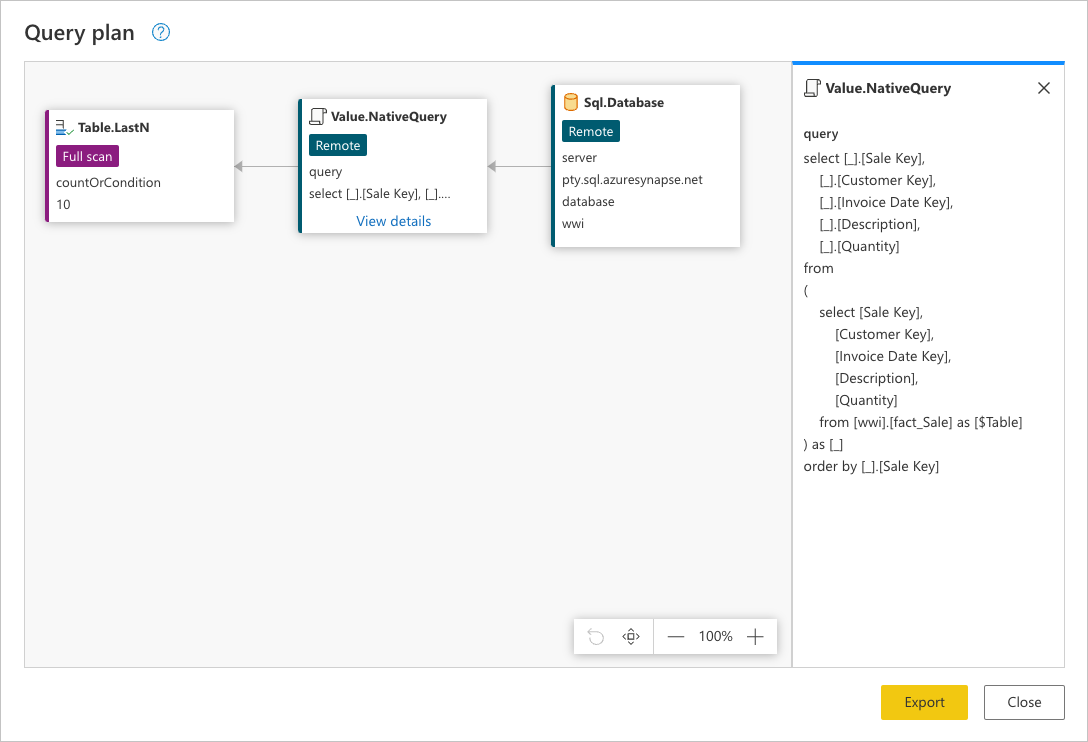
この要求は、データ ソースのネイティブ言語で行われます。 この場合、その言語は SQL であり、このステートメントは fact_Sale テーブルのすべての行 (要求されたフィールドのみを含み、Sale Key フィールドによって並べ替えたもの) に対する要求を表します。
このデータ ソース要求を調べると、クエリ プラン全体が伝えようとしているストーリーをより深く理解できます。 ノードの順序は、データ ソースのデータを要求することから始まるシーケンシャル プロセスです。
Sql.Database: データベースに接続し、メタデータ要求を送信してその機能を理解します。Value.NativeQuery: クエリを満たすために Power Query によって生成された要求を表します。 Power Query では、データ要求をネイティブ SQL ステートメントでデータ ソースに送信します。 この場合、データベースのfact_Saleテーブルのすべてのレコード (要求されたフィールドのみを含み、Sales Keyフィールドの昇順で並べ替えたもの) を表します。Table.LastN: Power Query では、fact_Saleテーブルからすべてのレコードを受信すると、Power Query エンジンを使用してテーブルをフィルター処理し、最後の 10 行のみを保持します。
その評価のために、このクエリではすべての行と、要求されたフィールドのみを fact_Sale テーブルからダウンロードする必要がありました。 Power BI データフローの標準インスタンスで処理するのに、(評価と、データフローへのデータの読み込みを含めて) 平均で 3 分 4 秒かかりました。
完全クエリ フォールディングの例
データベースに接続して fact_Sale テーブルに移動したら、まず、保持する列をテーブルから選択します。 [ホーム] タブから、[列の管理] グループ内にある [列の選択] 変換を選択します。この変換は、テーブルの列のうち保持するものを明示的に選択し、残りは削除するために役立ちます。
[列の選択] で、Sale Key、Customer Key、Invoice Date Key、Description、Quantity の各列を選択して [OK] を選択します。
ここで、最後の売上がテーブルの一番上に来るようにテーブルを並べ替えるロジックを作成します。 Sale Key 列を選択します。これは、テーブルの主キーおよび増分シーケンスまたはインデックスです。 列のコンテキスト メニューから、このフィールドのみを使用して降順でテーブルを並べ替えます。
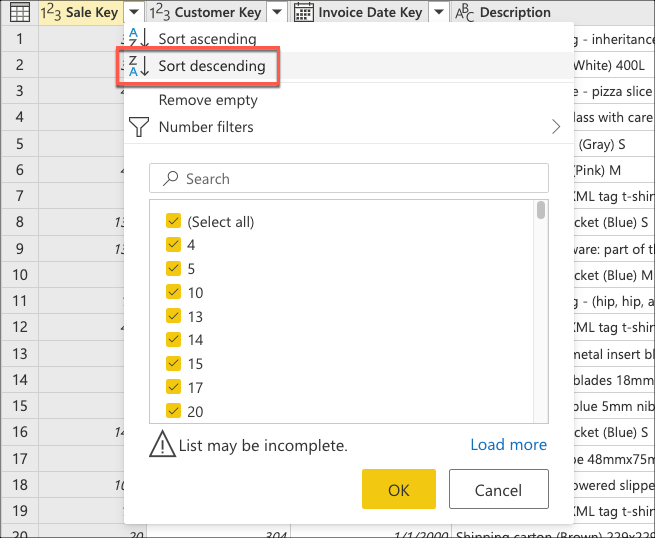
次に、テーブルのコンテキスト メニューを選択し、[上位の行を保持] 変換を選択します。
![テーブルのコンテキスト メニュー内の [上位の行を保持] オプション。](media/query-folding-basics/full-folding-keep-top-rows.png)
[上位の行を保持] で、値 10 を入力して [OK] を選択します。
![テーブルの先頭 10 行のみを保持するために入力値として値 10 を入力した [上位の行を保持] ダイアログ。](media/query-folding-basics/full-folding-keep-top-rows-dialog.png)
次のコード サンプルは、作成したクエリの完全な M スクリプトです。
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
完全クエリ フォールディングの例: クエリの評価について理解する
適用されたステップ ペインを確認すると、追加した変換、列の選択、並べ替えられた行、上位行の維持がクエリ折りたたみインジケーターに表示されていることがわかります。 は、データ ソースで評価されるステップとしてマークされています。

クエリの最後のステップである [上位の行を保持] を右クリックして [クエリ プラン] オプションを選択できます。
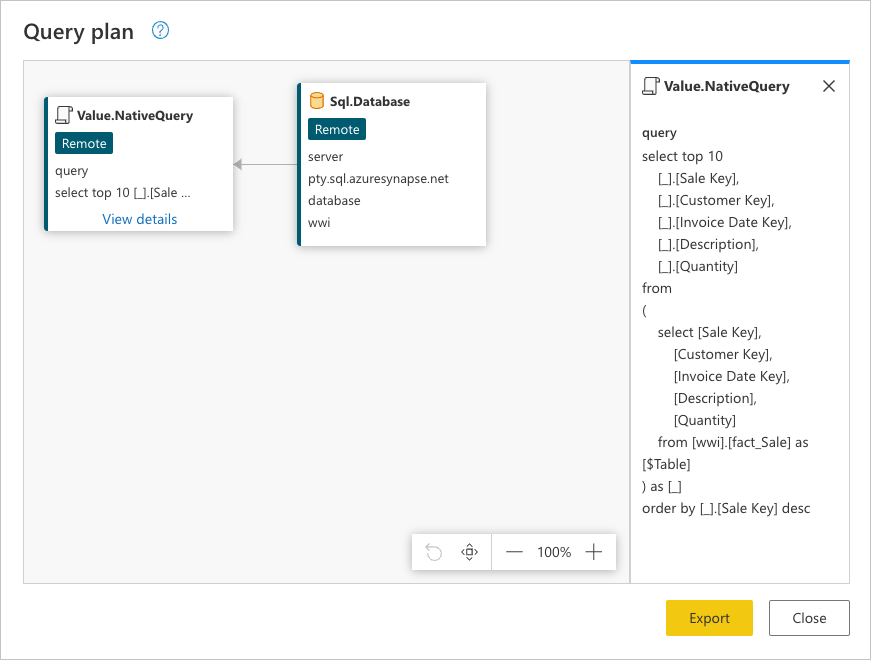
この要求は、データ ソースのネイティブ言語で行われます。 この場合、その言語は SQL であり、このステートメントは fact_Sale テーブルのすべての行とフィールドに対する要求を表します。
このデータ ソース クエリを調べると、クエリ プラン全体が伝えようとしているストーリーをより深く理解できます。
Sql.Database: データベースに接続し、メタデータ要求を送信してその機能を理解します。Value.NativeQuery: クエリを満たすために Power Query によって生成された要求を表します。 Power Query では、データ要求をネイティブ SQL ステートメントでデータ ソースに送信します。 この場合、fact_Saleテーブルの上位 10 レコードのみ (必要なフィールドのみを含み、Sale Keyフィールドを使用して降順で並べ替えた後のもの) に対する要求を表します。
Note
T-SQL 言語には、テーブルの末尾行を SELECT するために使用できる句はありませんが、テーブルの先頭行を取得する TOP 句があります。
その評価のために、このクエリでは 10 行のみと、要求されたフィールドのみを fact_Sale テーブルからダウンロードします。 Power BI データフローの標準インスタンスでこのクエリを処理するのに、(評価と、データフローへのデータの読み込みを含めて) 平均で 31 秒かかりました。
パフォーマンスの比較
クエリ フォールディングがこれらのクエリに及ぼす影響について理解を深めるために、クエリを更新し、各クエリの完全更新にかかる時間を記録して、それらを比較することができます。 わかりやすくするために、この記事では、サービス レベルとして DW2000c を使用して専用の Azure Synapse Analytics 環境に接続している状態で、Power BI データフロー更新メカニズムを使用してキャプチャした平均更新時間を示します。
各クエリの更新時間は次のとおりです。
| 例 | Label | 時間 (秒) |
|---|---|---|
| クエリ フォールディングなし | なし | 361 |
| 部分的クエリ フォールディング | Partial | 184 |
| 完全クエリ フォールディング | 完全 | 31 |
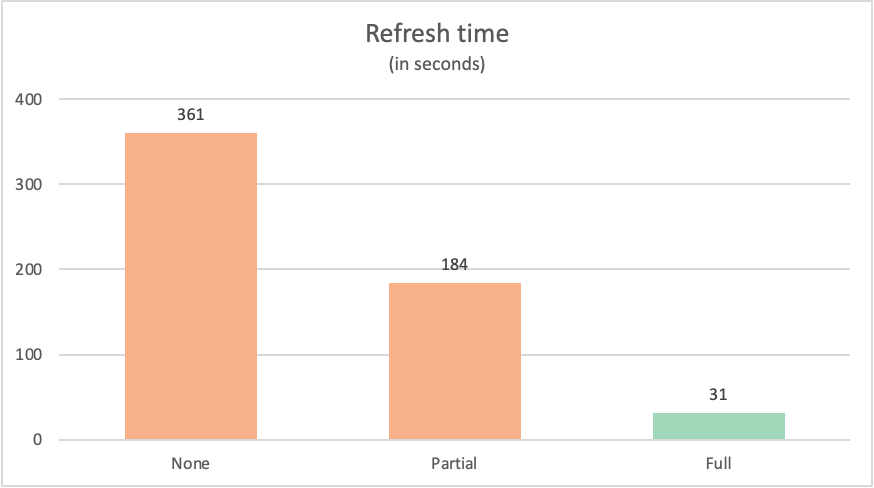
多くの場合、データ ソースに完全にフォールドバックするクエリは、データ ソースに完全にフォールドバックしない同様のクエリをパフォーマンスで上回ります。 これには多くの理由が考えられます。 クエリで実行する変換の複雑さから、データ ソースで実装されているクエリ最適化 (インデックスや専用コンピューティングなど)、ネットワーク リソースに至るまで、理由は多岐にわたります。 それでも、クエリ フォールディングが使おうとする特定の重要なプロセスが 2 つあり、Power Query を使用して、これら両方のプロセスが及ぼす影響を最小限に抑えます。
- 転送中のデータ
- Power Query エンジンによって実行される変換
以下のセクションでは、これら 2 つのプロセスが前述したクエリに及ぼす影響について説明します。
転送中のデータ
クエリが実行されると、クエリはその最初のステップの 1 つとしてデータ ソースからデータを取り込もうとします。 どのようなデータがデータ ソースから取り込まれるかは、クエリ フォールディング メカニズムによって定義されます。 このメカニズムにより、データ ソースにオフロードできるクエリのステップが識別されます。
次の表に、データベースの fact_Sale テーブルから要求された行数の一覧を示します。 表では、当該データをデータ ソースから要求するために送信される SQL ステートメントの簡単な説明も示しています。
| 例 | Label | 要求された行数 | 説明 |
|---|---|---|---|
| クエリ フォールディングなし | なし | 3644356 | fact_Sale テーブルのすべてのフィールドとすべてのレコードを要求 |
| 部分的クエリ フォールディング | Partial | 3644356 | fact_Sale テーブルのすべてのレコード (ただし、必要なフィールドのみ) を Sale Key フィールドで並べ替えたものを要求 |
| 完全クエリ フォールディング | 完全 | 10 | fact_Sale テーブルの必要なフィールドと上位 10 レコードのみを Sale Key フィールドの降順で並べ替えたものを要求 |
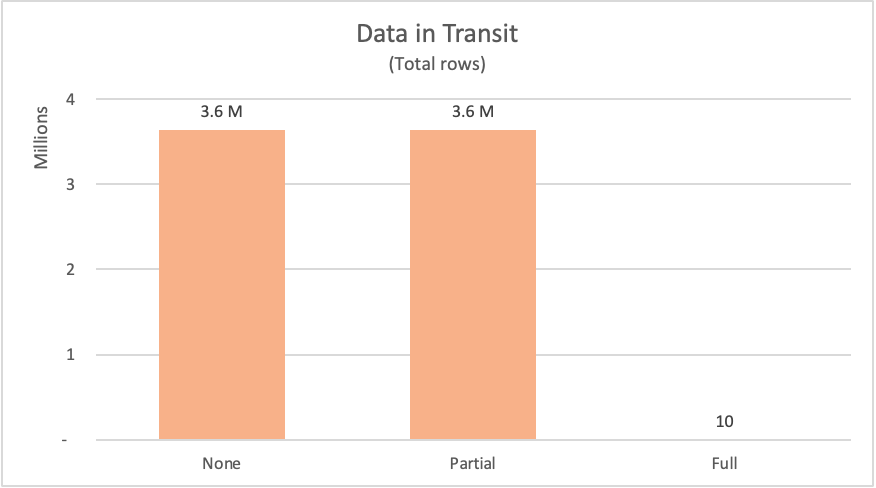
データ ソースからデータを要求するとき、データ ソースでは要求の結果を計算してから、要求元にデータを送信する必要があります。 コンピューティング リソースについては既に言及しましたが、データ ソースから Power Query にデータを移動するネットワーク リソースの部分で、またそれに続いて、Power Query でデータを効率的に受信し、ローカルで実行される変換のためにデータを準備できるまでに、データのサイズによっては、ある程度の時間がかかる場合があります。
紹介した例のうち、クエリ フォールディングなしと部分的クエリ フォールディングの例では、Power Query は 360 万行以上をデータ ソースから要求する必要がありました。 完全クエリ フォールディングの例では、要求したのは 10 行だけです。 要求されたフィールドに関しては、クエリ フォールディングなしの例では、テーブルのすべての使用可能なフィールドを要求しました。 部分的クエリ フォールディングと完全クエリ フォールディングの例ではどちらも、厳密に必要なフィールドの要求のみを送信しました。
注意
大量のデータを含むクエリまたはテーブルに対しては、クエリの折りたたみを利用する増分更新ソリューションを実装することをお勧めします。 Power Query のさまざまな製品統合には、実行時間の長いクエリを終了するためのタイムアウトが実装されています。 一部のデータ ソースでは、実行時間の長いセッションのタイムアウトが実装されており、そのサーバーに対してコストの高いクエリを実行しようとします。 詳細情報: データフローでの増分更新の使用、セマンティック モデルの増分更新
Power Query エンジンによって実行される変換
この記事では、クエリがどのように評価されるかについて、クエリ プランを使用して理解を深める方法を説明しました。 クエリ プラン内で、Power Query エンジンによって実行される変換操作の正確なノードを確認できます。
次の表は、以前のクエリのクエリ プランのノードで、Power Query エンジンによって評価されたものを示しています。
| 例 | Label | Power Query エンジン変換ノード |
|---|---|---|
| クエリ フォールディングなし | なし | Table.LastN, Table.SelectColumns |
| 部分的クエリ フォールディング | Partial | Table.LastN |
| 完全クエリ フォールディング | 完全 | — |
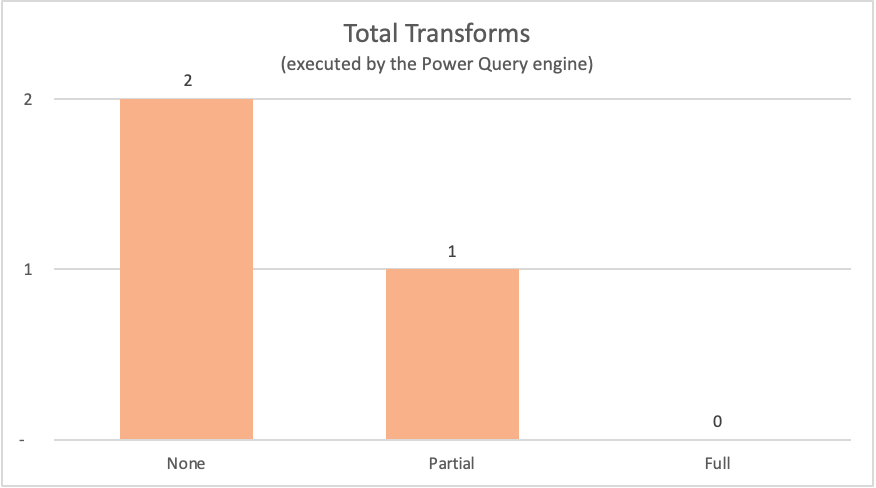
この記事で紹介した例のうち、完全クエリ フォールディングの例では、必要な出力テーブルはデータ ソースから直接取得されるため、Power Query エンジン内ではどのような変換も発生する必要がありません。 一方、他の 2 つのクエリでは、多少の計算が Power Query エンジンで発生する必要がありました。 これら 2 つのクエリによる処理が必要なデータの量が原因で、これらの例のプロセスには、完全クエリ フォールディングの例よりも時間がかかります。
変換は次のカテゴリに分類できます。
| 演算子の種類 | 説明 |
|---|---|
| リモート | データ ソース ノードである演算子。 これらの演算子の評価は、Power Query の外部で発生します。 |
| ストリーミング | 演算子はパススルー演算子です。 たとえば、単純フィルター付きの Table.SelectRows は通常、演算子を通過するときに結果をフィルター処理でき、データを移動する前にすべての行を収集する必要はありません。 Table.SelectColumns と Table.ReorderColumns は、このような種類の演算子のその他の例です。 |
| フル スキャン | データがチェーン内の次の演算子に移動する前に、すべての行を収集する必要がある演算子。 たとえば、データを並べ替えるために、Power Query はすべてのデータを収集する必要があります。 フル スキャン演算子のその他の例は、Table.Group、Table.NestedJoin、Table.Pivot です。 |
ヒント
パフォーマンスの観点からすべての変換が同じであるとは限りませんが、ほとんどの場合、変換が少ないほうが通常は有利です。
考慮事項と提案
- 新しいクエリを作成するときは、Power Query のベスト プラクティスに関するページで説明されているベスト プラクティスに従ってください。
- クエリ フォールディング インジケーター を使用して、どのステップがクエリのフォールディングを妨げているかを確認します。 フォールディングを増やすために、必要に応じてステップの順序を変更します。
- クエリ プランを使用して、特定のステップに関してどの変換が Power Query エンジンで発生しているかを特定します。 ステップを再配置することによって、既存のクエリを修正することを検討してください。 次に、クエリの最後のステップのクエリ プランをもう一度チェックし、前のものよりもクエリ プランが良く見えるかどうかを確認します。 たとえば、新しいクエリ プランは以前のものよりノードが少なく、ほとんどのノードは "フル スキャン" ではなく "ストリーミング" ノードです。 フォールディングをサポートするデータ ソースの場合、クエリ プラン内の
Value.NativeQuery以外のノードと、データ ソース アクセス ノードは、フォールドされなかった変換を表します。 - 使用可能な場合、[ネイティブ クエリを表示] (または [データ ソース クエリの表示]) オプションを使用して、クエリをデータ ソースにフォールドバックできることの確認ができます。 ステップでこのオプションが無効であり、通常であればそれを有効にするソースを使用している場合、クエリ フォールディングを停止するステップを作成したことになります。 このオプションをサポートしていないソースを使用している場合は、クエリ フォールディング インジケーターとクエリ プランを利用できます。
- コネクタでクエリ フォールディング機能が使用できる場合にデータ ソースに送信される要求について、クエリ診断ツールを使用して理解を深めます。
- 複数のコネクタを使用してデータ ソースを組み合わせる場合、Power Query では、それぞれのデータ ソースに対して定義されたプライバシーレベルに準拠しつつ、できるだけ多くの処理を両方のデータ ソースにプッシュしようとします。
- クエリでデータ プライバシー ファイアウォール エラーが発生しないよう、プライバシー レベルに関する記事をお読みください。
- 他のツールを使用して、データ ソースが受信する要求の観点からクエリ フォールディングを確認します。 この記事の例に基づき、Microsoft SQL Server プロファイラーを使用して、Power Query から送信され Microsoft SQL Server が受信する要求をチェックできます。
- 完全にフォールドされたクエリに新しいステップを追加し、新しいステップもフォールドする場合、Power Query では、前の結果のキャッシュ バージョンを使用する代わりに、データ ソースに新しい要求を送信することがあります。 実際には、このプロセスの結果として、少量のデータに対する一見して単純な操作が、プレビューでの更新に予想よりも時間がかかる可能性があります。 このように更新が長引くのは、Power Query でデータのローカル コピーを再利用せずにデータ ソースをもう一度クエリすることが原因です。