Google BigQuery のデータ品質 (プレビュー)
サポートされている機能
Google BigQuery ソースをスキャンする場合、Microsoft Purview では次の処理がサポートされます。
- 以下を含む技術的なメタデータの抽出:
- プロジェクトとデータセット
- 列を含むテーブル
- 列を含むビュー
- テーブルとビュー間の資産リレーションシップに対する静的系列のフェッチ。
スキャンを設定するときに、Google BigQuery プロジェクト全体をスキャンすることを選択できます。 また、指定された名前または名前パターンに一致するデータセットのサブセットにスキャンのスコープを設定することもできます。
既知の制限
- 現在、Microsoft Purview では、米国の複数リージョンの場所での Google BigQuery データセットのスキャンのみがサポートされています。 指定したデータセットが us-east1 や EU などの他の場所にある場合は、スキャンが完了したが、Microsoft Purview に資産は表示されません。
- オブジェクトがデータ ソースから削除された場合、現在、後続のスキャンでは、Microsoft Purview の対応する資産は自動的に削除されません。
Microsoft Purview で Google BigQuery データをカタログ化するようにデータマップ スキャンを構成する
Google BigQuery プロジェクトを登録する
- Microsoft Purview を開き、左側のナビゲーションで [データ マップ] を選択します。
- [登録] を選択します。
- [ソースの登録] で、[Google BigQuery] を選択します。 [続行] を選択します。
- カタログ内にデータ ソースが一覧表示される名前を入力します。
- ProjectID を入力します。 これは完全修飾プロジェクト ID である必要があります。 たとえば、mydomain.com: myProject
- 一覧からコレクションを選択します。
- [登録] を選択します。
Google BigQuery プロジェクトのデータマップ スキャンを設定する
- セルフホステッド統合ランタイムが設定されていることを確認します。 セットアップされていない場合は、「前提条件」で説明されている手順を使用 します
- [ソース] に移動します。
- 登録済みの BigQuery プロジェクトを選択します。
- [+ 新しいスキャン] を選択します。
- 以下の詳細を指定します。
- 名前: スキャンの名前
- 統合ランタイム経由で接続する: 構成済みのセルフホステッド統合ランタイムを選択します
- 資格情報: BigQuery 資格情報の構成中に、次のことを確認します。
- 認証方法として [基本認証] を選択します
- [ユーザー名] フィールドにサービス アカウントの電子メール ID を指定します。 たとえば、xyz@developer.gserviceaccount.com のように指定します。
- 秘密キーを生成するには、次の手順に従います。 JSON キー ファイル全体をコピーし、Key Vault シークレットの値として格納します。
- Google のクラウド プラットフォームから新しい秘密キーを作成するには:
- ナビゲーション メニューで [IAM (Identity Access Management)] を選択し、[管理 --> サービス アカウント] --> [プロジェクトの選択] を選択します。>
- キーを作成するサービス アカウントのメール アドレスを選択します。
- [キー] タブを選択します。
- [キーの追加] ドロップダウン メニューを選択し、[新しいキーの作成] を選択します。
- [JSON 形式] を選択します。
- セルフホスト統合ランタイムが実行されているマシン内の JDBC (Java Database Connectivity) ドライバーの場所へのパスを指定します。 たとえば、D:\Drivers\GoogleBigQuery です。
- インポートする BigQuery データセットの一覧を指定します。 たとえば、dataset1 です。dataset2。 リストが空の場合、使用可能なすべてのデータセットがインポートされます。
- プロセスのスキャンによって使用される VM (仮想マシン) で使用できる最大メモリ (GB 単位)。 これは、スキャンする Google BigQuery プロジェクトのサイズによって異なります。
- [接続のテスト] を選択します。
- [続行] を選択します。
- スキャン トリガーを選択します。 スケジュールを設定することも、スキャンを 1 回実行することもできます。
- スキャンを確認し、[ 保存して実行] を選択します。
スキャンすると、Google BigQuery プロジェクトのデータ資産が統合カタログ検索で利用できるようになります。 Microsoft Purview で Google BigQuery を接続および管理する方法の詳細については、 こちらのドキュメントを参照してください。
重要
スキャンを削除しても、以前のスキャンから作成されたカタログ資産は削除されません。
データ品質スキャンのために Google BigQuery プロジェクトへの接続を設定する
この時点で、スキャンされた資産をカタログ化およびガバナンスの準備ができました。 スキャンした資産をガバナンス ドメインのデータ製品に関連付けて、データ品質スキャンを設定します。
[データ品質] > [ガバナンス ドメイン] > [管理] タブを選択して接続を作成します。
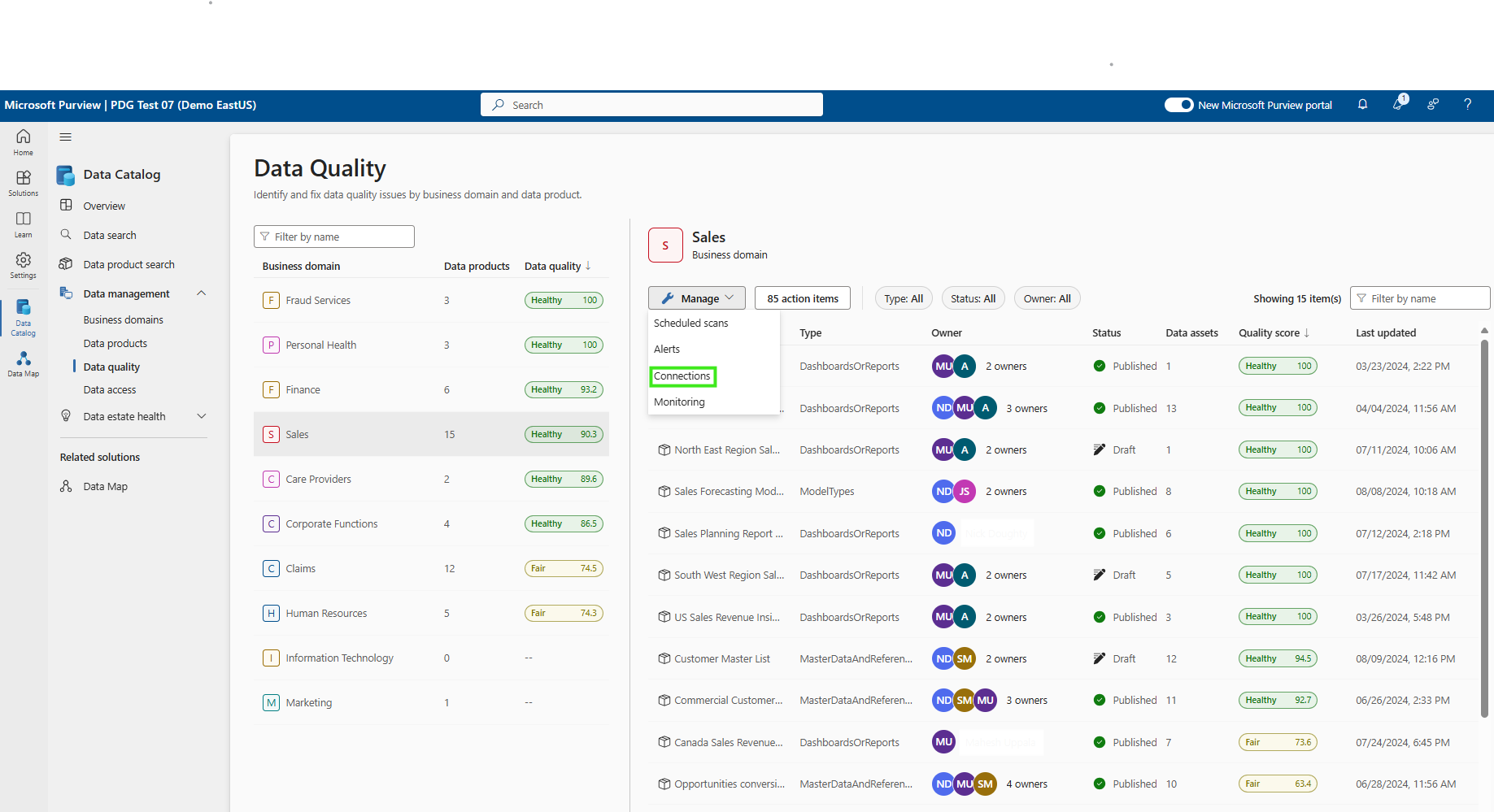
接続の構成
- 接続名と説明を追加する
- ソースの種類 Google BigQuery を選択する
- プロジェクト ID、データセット名、テーブル名を追加する
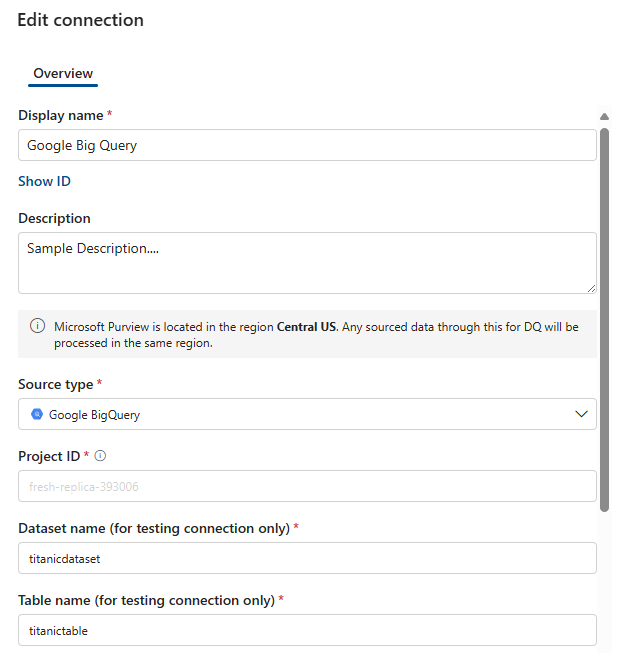
- [サービス アカウントの秘密キー] を選択します
- Azure サブスクリプションを追加する
- キー コンテナー接続
- シークレット名
- シークレットのバージョン
データ ソース接続が正常に構成されるように接続をテストします。

重要
データ品質スチュワードは、データ品質接続を設定するために、Google BigQuery への 読み取り専用アクセス権 を必要とします。 vNet とプライベート エンド ポイントは、データ品質スキャン サービスではまだ Google BigQuery データ ソースではサポートされていません。
Google BigQuery でのデータのプロファイリングとデータ品質スキャン
接続のセットアップが正常に完了したら、Google BigQuery でデータのプロファイリング、作成、適用、データ品質スキャンを実行できます。 以下のドキュメントで説明されているステップバイステップのガイドラインに従ってください。